

基于机器学习的垃圾分类监控系统
一、摘要 abstract
正确处理厨余垃圾,可以有效地保护环境,并带来不错的经济效益。本文将机器学习运用到厨余垃圾的分类监控中,以识别混入其中的非厨余垃圾。本文在人工收集到的数据集的基础上,共实验了模板匹配、模板匹配+SVM,HOG特征提取+SVM,VGG16迁移学习及迁移学习模型微调这五种方法,并对后两种方法进行了数据增强处理。对这五种方法从模型大小,训练时间,分类准确率等方面进行分析比较,最终选择了迁移学习模型微调作为项目的模型,准确率为88.9%,模型大小为64.1MB,训练时间为84.25min。将软件进行封装,并加入对投放人员是否在规定时间内投放垃圾的检测,制作成垃圾分类监控系统。建立的模型达到了提高厨余垃圾分类的准确率,减轻垃圾管理人员的劳动强度和人工成本的效果。
二、介绍introduction:
垃圾分类是当下的热点话题,正确的垃圾分类有利于保护环境,节省土地资源,提高民众价值观念等。在倡导绿色低碳生活的今天,垃圾分类对地球生态显得尤为重要。
在中国,垃圾分类政策近几年正在逐步开始实施。目前,上海、北京等城市已经开始严格地实施生活垃圾管理条例。在定点城市先行的基础上,在全国将全面推广垃圾分类。由此可见,垃圾分类将会逐渐变成中国的常态。[1]而对国外很多国家,经过了几十年不断地改进与发展,也已经有了一套很严格规范的垃圾分类政策。
在垃圾分类中,有一大类是厨余垃圾。厨余垃圾是一种生物降解垃圾,它的处理与利用备受人们关注。据调查数据显示,2020年8月份,仅北京市的家庭厨余垃圾日均分出量就高达3268吨,家庭厨余垃圾分出率达到15.41%。[2]对如此大量的厨余垃圾,若正确处理,则可用于堆肥、发电、用作生物气体或合成气原料等。不仅可以很好地保护生态环境,而且还能带来不错的经济效益。但是如果厨余垃圾处理不当,如混入其他塑料垃圾,有害垃圾等,效果会适得其反[3]。
如今国内对厨余垃圾的监控大多采用人工监督的方式,由专门的监管人员在回收站点旁对居民是否正确投放厨余垃圾的情况进行监督。但这种纯人工的方式会出现工作量大、效率低、成本高的问题,同时人工监督的准确率也不高。
我们的项目则将当下热门的人工智能与厨余垃圾的分类监控相结合,利用机器学习的方法,通过系统对厨余垃圾进行自动分类,并对投放垃圾的人员进行监测,判断其是否在规定的时间段内投放垃圾。这样不仅能减轻垃圾管理人员的劳动强度,降低人工成本,也能提高厨余垃圾的分类准确率,使厨余垃圾能得到更好的利用。


参考文献:
[1].我国自2019年起在全国地级及以上城市全面启动生活垃圾分类[J].大社会,2019(Z1):13.
[2].8月北京家庭厨余垃圾分出量较7月再增长1399吨[N/OL].北京商报,2020-09-03. https://baijiahao.baidu.com/s?id=1676795692302859756&wfr=spider&for=pc
[3]Gustavsson, J, Cederberg, C & Sonesson, U, 2011, Global Food Losses and Food Waste, Food And Agriculture Organization Of The United Nations, Gothenburg Sweden.
; 三、相关工作Related work:
现在已经有很多关于协助垃圾分类管理的研究,许多优秀的贡献者提出了许多创新性的方法来解决垃圾分类难题。其中一些没有采用人工智能的方式,[1]利用最近流行的射频识别技术(RFID),采用为各种物品附加射频识别标签的方式自动检索垃圾分类。这种方式不仅可以实现垃圾流的跟踪,还可以将垃圾的数字信息(种类、重量、日期和时间)和物理实体联系起来[2]。这种方式很方便且有效,但是将所有生活物品附上射频识别标签这样繁重的任务需要等待射频识别技术推广的未来。更多的方法是与人工智能技术相结合。[3]将物联网(loT)与深度学习相结合,将垃圾管理系统分为四个层(signal sensing and processing, network, intelligent user application and Internet of Things (IoT) web application layers)利用多种传感器(proximity sensor, gas sensor, temperature sensor)收集数据,在应用层使用深度学习进行分类。这对于传感器有很高的要求,对于密集散布的垃圾投放点来说成本较高。在[2]中,作者还为每个个体创建了账户,便于缴费、积分等相关应用,对于我国庞大人口基础,这样的个人账户运营和维护起来较为困难。
现有的许多人工智研究对于特定场景的应用卓有成效,[4]使用50层残差网络预处理(ResNet-50)卷积神经网络模型来分辨废旧材料,如玻璃、金属、纸张和塑料等,准确率可达87%;[5]使用图像处理和卷积神经网络(CNN)只专注于聚乙烯的检测;[6]使用胶囊神经网络(Capsule-Net)鉴别塑料和非塑料等等。本文将集中于使用图像处理和深度学习算法识别厨余垃圾中的非厨余垃圾。
参考文献:
[1]Glouche Y, Couderc P. A smart waste management with self-describing objects[C]//The Second International Conference on Smart Systems, Devices and Technologies (SMART’13). 2013.
[2]Reis P, Caetano F, Pitarma R, et al. iEcoSys–an intelligent waste management system[M]//New Contributions in Information Systems and Technologies. Springer, Cham, 2015: 843-853.
[3]Adeyemo J O, Olugbara O O, Adetiba E. Development of a Prototype Smart City System for Refuse Disposal Management[J]. Mathematics and Computer Science, 2019, 4(1): 6.
[4]Adedeji O, Wang Z. Intelligent waste classification system using deep learning convolutional neural network[J]. Procedia Manufacturing, 2019, 35: 607-612.
[5]Bobulski J, Kubanek M. Waste classification system using image processing and convolutional neural networks[C]//International Work-Conference on Artificial Neural Networks. Springer, Cham, 2019: 350-361.
[6]K. Sreelakshmi, S. Akarsh, R. Vinayakumar, K.P. Soman
March). Capsule Networks and Visualization for Segregation of Plastic and Non-Plastic Wastes, IEEE (2019), pp. 631-636
四、方法原理method:
1、传统模板匹配

图像模板匹配方法用于找到图像中与模板图像最相似的区域。是一种最原始、最基本的模式识别方法。研究某一特定对象物体的图案位于图像的什么地方,进而识别对象物体,这就是一个匹配问题。它是图像处理中最基本、最常用的匹配方法。
图像模板匹配方法通过图像模板T在图像I上从上到下、从左到右移动并匹配所有潜在的目标区域,计算T与潜在目标的相似度。与T高度相似的区域被认为是所检测目标的可疑区域
模板匹配具有自身的局限性,主要表现在它只能进行平行移动。图像模板匹配方法以一定顺序将图像模板应用于图像,以处理所有图像块,并测量图像模板与这些块之间的欧氏距离。图像模板和图像块之间的欧式距离可以表示为 [3]

其中D(i,j)是图像模板和重心位于(i,j)的图像块之间的欧几里得距离。M和N分别是图像模板的宽度和高度。P(m,n)和T(m,n)分别是图像模板和重心位于(m,n)的图像块的像素值。
; 2.、机器学习(特征+SVM)
计算机可以识别的描述一张图片的特征可以是Harrs角点检测、HOG、Haar、LBP等的特征,而方向梯度直方图(HOG)是一个特征描述符中使用计算机视觉处理为目的对象检测。该技术对图像的局部部分中梯度取向的出现进行计数。该方法类似于边缘方向直方图,尺度不变特征变换描述符和形状上下文,HOG是计算机视觉和模式识别中用于对象检测的描述方法[38,39]。主要用于静态图像和视频中的行人检测[40]。HOG要求检测到的物体形状用光强梯度或边缘方向的分布来描述,通过计算和统计分析图像梯度方向来构造特征。HOG算法利用块滑块提取图像特征。块包含单元格,该单元格包含目标的特征[2]
SVM是用于分类和回归分析的监督机器学习算法。SVM在高维或无限维空间中构造超平面或超平面集,可用于分类或回归[1]。给定一组训练实例,每个训练实例被标记为属于两个类别中的一个或另一个,SVM训练算法创建一个将新的实例分配给两个类别之一的模型,使其成为非概率二元线性分类器 ,SVM算法试图找到一个最优的超平面来分离数据,并根据类别对它们进行聚类。由于过程的动态性,数据通常不能线性分离。因此,SVM通过非线性映射将数据映射到高维特征空间。在这个空间中,构造了一个能够分离数据的最优超平面。此外,SVM使用另一个特征,它通过仅依赖于输入空间变量的核函数来模拟分类。SVM所描述的重要核函数是线性、多项式、高斯或径向基函数[1]



训练数据样本集( x i , y i ) , i = 1 , 2 , … , l , x ∈ R n , y ∈ { ± 1 } , l \left(x_{i}, y_{i}\right), i=1,2, \ldots, l, x \in R^{n}, y \in{\pm 1},l (x i ,y i ),i =1 ,2 ,…,l ,x ∈R n ,y ∈{±1 },l是训练样本的总数。
超平面为( w ⋅ x ) + b = 0 (w \cdot x)+b=0 (w ⋅x )+b =0。为了正确地对所有样本进行分类,应该满足以下约束条件:
y i [ ( w ⋅ x i ) + b ] ≥ 1 , i = 1 , 2 … , l y_{i}\left[\left(w \cdot x_{i}\right)+b\right] \geq 1, i=1,2 \ldots, l y i [(w ⋅x i )+b ]≥1 ,i =1 ,2 …,l
可计算的分类间隔是2 l ∥ w ∥ 2 l\|w\|2 l ∥w ∥。构造最优超平面的问题转化为在约束:min Φ ( w ) = 1 2 ∥ w ∥ 2 = 1 2 ( w ′ ⋅ w ) \min \Phi(\mathrm{w})=\frac{1}{2}\|w\|^{2}=\frac{1}{2}\left(w^{\prime} \cdot w\right)min Φ(w )=2 1 ∥w ∥2 =2 1 (w ′⋅w )条件下求min Φ ( w ) \min \Phi(\mathrm{w})min Φ(w )。引入拉格朗日函数求解约束优化问题:
L ( w , a , b ) = 1 2 ∥ w ∥ − a ( y ( ( w ⋅ x ) + b ) − 1 ) L(w, a, b)=\frac{1}{2}\|w\|-a(y((w \cdot x)+b)-1)L (w ,a ,b )=2 1 ∥w ∥−a (y ((w ⋅x )+b )−1 )
公式中a i ( a i > 0 ) a_{i}\left(a_{i}>0\right)a i (a i >0 )为拉格朗日乘数。约束优化的解由拉格朗日函数的鞍点决定。当w和b的偏导数在鞍点为0时,问题就变成了对偶问题:
max Q ( a ) = ∑ j = 1 l a j − 1 2 ∑ i = 1 l ∑ j = 1 l a i a j y i y j ( x i ⋅ x j ) \max Q(a)=\sum_{j=1}^{l} a_{j}-\frac{1}{2} \sum_{i=1}^{l} \sum_{j=1}^{l} a_{i} a_{j} y_{i} y_{j}\left(x_{i} \cdot x_{j}\right)max Q (a )=j =1 ∑l a j −2 1 i =1 ∑l j =1 ∑l a i a j y i y j (x i ⋅x j )
其中
∑ j = 1 l a j y j = 0 , j = 1 , 2 , … , l , a j > 0 \sum_{j=1}^{l} a_{j} y_{j}=0, j=1,2, \ldots, l, a_{j}>0 j =1 ∑l a j y j =0 ,j =1 ,2 ,…,l ,a j >0
最优解是
a ∗ = ( a 1 ∗ , a 2 ∗ , … , a j ∗ ) T a^{}=\left(a_{1}^{}, a_{2}^{}, \ldots, a_{j}^{}\right)^{T}a ∗=(a 1 ∗,a 2 ∗,…,a j ∗)T
计算最优权向量w 和最优偏置b
w ∗ = ∑ j = 1 l a j ∗ y i y j ; b ∗ = y i − ∑ j = 1 l a j ∗ a j ( x i ⋅ x j ) w^{}=\sum_{j=1}^{l} a_{j}^{} y_{i} y_{j} ; b^{}=y_{i}-\sum_{j=1}^{l} a_{j}^{} a_{j}\left(x_{i} \cdot x_{j}\right)w ∗=j =1 ∑l a j ∗y i y j ;b ∗=y i −j =1 ∑l a j ∗a j (x i ⋅x j )
公式中,下标j ∈ ( j ∣ a j > 0 ) j \in\left(j \mid a_{j}>0\right)j ∈(j ∣a j >0 )。然后最优分类超平面为( w ∗ ⋅ x ) + b ∗ = 0 \left(w^{} \cdot x\right)+b^{}=0 (w ∗⋅x )+b ∗=0。最佳分类函数如下:
f ( x ) = sgn { ( w ∗ ⋅ x ) + b ∗ } = sgn { ( ∑ j = 1 l a j ∗ y j ( x i ⋅ x j ) + b ∗ } , x ∈ R n f(x)=\operatorname{sgn}\left{\left(w^{} \cdot x\right)+b^{}\right}=\operatorname{sgn}\left{\left(\sum_{j=1}^{l} a_{j}^{} y_{j}\left(x_{i} \cdot x_{j}\right)+b^{}\right}, x \in R^{n}\right.f (x )=s g n {(w ∗⋅x )+b ∗}=s g n {(j =1 ∑l a j ∗y j (x i ⋅x j )+b ∗},x ∈R n
x从输入空间R n R^{n}R n到特征空间H的变换为Φ:
x → Φ ( x ) = ( Φ 1 ( x ) , Φ 2 ( x ) , … , Φ l ( x ) ) T x \rightarrow \Phi(\mathrm{x})=\left(\Phi_{1}(x), \Phi_{2}(x), \ldots, \Phi_{l}(x)\right)^{T}x →Φ(x )=(Φ1 (x ),Φ2 (x ),…,Φl (x ))T
特征向量Φ(x)代替输入向量x,可以得到最优分类函数:
f ( x ) = sgn { w ∗ ⋅ Φ ( x ) + b } = sgn { ( ∑ i = 1 l a i y i Φ ( x i ) Φ ( x ) + b } f(x)=\operatorname{sgn}\left{w^{*} \cdot \Phi(\mathrm{x})+b\right}=\operatorname{sgn}\left{\left(\sum_{i=1}^{l} a_{i} y_{i} \Phi\left(x_{i}\right) \Phi(\mathrm{x})+b\right}\right.f (x )=s g n {w ∗⋅Φ(x )+b }=s g n {(i =1 ∑l a i y i Φ(x i )Φ(x )+b }
获得分类函数后,我们可以对厨余垃圾测试数据进行分类。通过提取图像的特征向量,并输入该分类函数可以得到分类结果(合格或者不合格)
参考文献:
1.Classification and Prediction of Driving Behaviour at a Traffic
Intersection Using SVM and KNN
2.Shedding Damage Detection of Metal Underwater Pipeline
External Anticorrosive Coating by Ultrasonic Imaging Based on
HOG + SVM
3. Breast Mass Detection in Mammography Based on Image Template Matching and CNN
38. Hongpu, F.; Beiji, Z. Histogram of Oriented Gradient and Its Extension. Comput. Eng. 2013, 39, 212–217.
- Tian, S.; Bhattacharya, U.; Lu, S.; Su, B.; Wang, Q.; Wei, X.; Lu, Y .; Tan, C.L. Multilingual Scene Character Recognition with
Co-occurrence of Histogram of Oriented Gradients. Pattern Recognit. 2016, 51, 125–134. [CrossRef]
40.
V okhmintcev , A.V .; Sochenkov , I.V .; Kuznetsov , V .V .; Tikhonkikh, D.V . Face recognition based on a matching algorithm with
recursive calculation of oriented gradient histograms. Dokl. Math. 2016, 93, 37–41. [CrossRef]
3、深度学习(VGG16迁移学习)
如今AI技术迅猛发展,DL的模型训练和学习变得更为方便和快速[13]。DL在计算机视觉(computer vision,CV)、自然语言处理和语音处理等许多领域都取得了显著的成功
虽然DL有效解决了一些非线性问题的模型拟合,但是DL模型的实现需要大量的训练数据[13]。DL的成功很大程度上依赖于大量的训练数据,以避免过度拟合。DL是典型的数据驱动技术,其能够利用大量的数据训练模型,通过学习发现规律,提取数据特征,完全避免了基于物理特性建模的局限性[19]
当前在工业界取得突破的基于机器学习或DL的AI应用对训练样本都有着数量上的要求。而训练模型所必须的海量训练数据样本的难以获取已经成为阻碍DL技术进一步推广的一个普遍性难题。数据扩充作为提高训练数据量和质量的有效工具,对DL模型的成功应用至关重要。数据扩充的基本思想是在保持正确的标签的同时生成覆盖未探测输入空间的合成数据集。数据扩充在许多应用中都显示了它的有效性,例如AlexNet用于ImageNet分类[22]。数据扩充又称为数据生成或数据增强(数据增广)。
迁移学习是一种利用在特定数据集上训练的模型的技术或方法。该模型再次用于解决其他类似问题,方法是将其作为起点,修改和更新其参数,使其与新给定的数据集相匹配[17,18],迁移学习旨在通过使用之前已经进行的其他模型的学习结果来找到适合于训练数据集的模型[34-35]。
今天,迁移学习技术已经成功地应用于许多现实世界的应用中,文献[24]将DL技术与迁移学习相结合,先在相关领域的大数据集中对卷积神经网络模型进行预训练,提取出预训练模型的权重和样本特征,用于目标小数据集中对模型进行初始化,以帮助模型对目标小数据集展开训练。为此,本项目提出了使用VGG16模型的迁移学习技术来进行厨余垃圾合格性检测。
本研究中使用的学习迁移类别是使用ImageNet加权VGG16模型的归纳迁移学习。从VGG16模型传递来的知识是VGG16模型从生成模型的1400万张图像上的1000分类所拥有的权重
像机器学习一样,过拟合问题也是经常出现的问题。在形成具有迁移学习的深度CNN模型的过程中,必须避免过拟合问题[23]。为了减少机器学习和深度学习中的过拟合,可以使用数据增强、缺失、正则化、提前停止和批处理规范化来完成[27]

参考文献:
[17] K. Weiss, T.M. Khoshgoftaar, and D.D.Wang, “A survey of transfer learning”, Journal of Big Data, vol. 3, no.9, 2016.
[18] S. J. Pan and Q. Yang, “A Survey on Transfer Learning”, IEEE Transactions on Knowledge and Data Engineering, Volume 22 Issue 10, October 2010, Pages 1345-1359, 2010.
[34] C. Tan, F. Sun, T. Kong, W. Zhang et al., “A Survey on Deep Transfer Learning”, Machine Learning, arXiv: 1808.01974, 2018.
[35] Z. Huang, Z. Pan, and B. Lei, “Transfer Learning with Deep Convolutional Neural Network for SAR Target Classification with
Limited Labeled Data”, remote sensing, vol. 9, no. 8, 2017
[23] X. Ying, “An Overview of Overfitting and its Solutions”, Journal of Physics: Conference Series, Intelligent system and control
technology, vol. 1168, no. 2, 2019.
[27] Implementation of Transfer Learning Using VGG16 on Fruit Ripeness Detection
[13].徐勇军. 基于少量样本的深度学习图像修复算法研究[D]. 2020
[19].陈伟宏,安吉尧,李仁发,等.深度学习认知计算综述[J].自动化学 报,2017,43(11):1886-1897.
[22]. Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In NeurIPS 2012, 88 pages 1097–1105, 2012.
[24]. 段萌,王功鹏,牛常勇.基于卷积神经网络的小样本图像识别方法[J].计 算机工程与设计,2018,39(1) : 224-229.
; 五、实验experiments:
1、模板匹配
本研究经过调查分析发现大部分厨余垃圾里混入的主要异物是纸巾和塑料,于是我们制作了如下纸巾和塑料模板来匹配检测厨余垃圾里的异物:


综合对比各大模板匹配算法和编程语言的适用性,我们采用Python-OpenCV这个编程库来完成相关算法的设计并开展实验。通过实验我们对比了OpenCV中的几种模板匹配算法的差异性:

随着从简单的测量(平方差)到更复杂的测量(相关系数),我们可获得越来越准确的匹配(同时也意味着越来越大的计算代价)。针对我们的项目特点及要达到的目标效果,我们选择TM_CCOEFF_NORMED也就是是标准相关性系数匹配来进行实验。
本研究收集并自建数据集,train数据集中含50张合格厨余垃圾图片,50张不合格垃圾图片,对train数据集进行训练,寻找阈值,并将该阈值用于测试集进行测试并评估模型性能。
对训练集的厨余垃圾图片进行模版匹配算法得到模版匹配值,匹配值如下图,可见,选择阈值为0.39比较合适

; 2、模板匹配+SVM
我们在Python-OpenCV的基础上设计构建SVM算法,以一张图片的9个模板匹配的匹配值作为特征值并输入构建的SVM模型算法进行训练以求得特征向量。通过实验我们发现,由于特征值过少,维度不够,SVM算法训练出来的支持向量不足以将有无垃圾异物的图片给划分开来,于是我们着手增加特征值的维度,将匹配值增加到200000个左右。结果较为理想。
在模板匹配特征值加svm中,我们将训练集图片扩充到402张,测试集图片扩充到185张,将模板匹配输出的特征值送入构建的SVM算法进行训练得到模型,用测试集对该模型进行评估,正确率达到77.29%。
但是我们经研究发现模板匹配的匹配值作为描述一张图片的特征还是有点差强人意,于是我们转而寻求更好的图片描述特征。我们知道描述一张图片的特征可以是图片的Harrs角点检测、HOG、Haar、LBP等。我们最终选择图片的HOG这种比较好的可以较完整地描述图片的特征。
3、HOG特征+SVM
我们设计相关算法提取图片的HOG特征向量,参数为:winSize = (128,128)、blockSize = (64,64)、blockStride = (8,8)、cellSize = (16,16)、nbins = 9、winStride = (8,8)、padding = (8,8);经过规范处理的厨余垃圾图片大小为(200,200),由此可以得到图片的HOG特征维数为1679616
构建并设计SVM模型,由于本研究是分类问题,所以我们选择SVM中经典的C_SVC模型,通过实验发现选择INTER核函数比较好,该核函数表述如下:
在HOG加SVM中,我们将提取训练集图片的HOG特征并送入SVM进行训练,得到模型大小为3.95GB,并在测试集中进行测试,得到的图片分类正确率为90.27%
4、VGG16迁移学习及微调
在模型训练的过程中,我们使用自己收集的厨余垃圾图像数据,我们首先通过人工标注的方式对数据集中的图像按照”是否含有纸制品与塑料制品”的标准进行分类,从而将图像分为 warn 与 pass 两大类。
人工标注后的数据集信息如表一所示

不难发现,原始数据集中包含的可用样本数量较少,且类间不平衡的现象较为严重。显然,如果我们期望在方案中部署基于深度学习的模型,基于现有的数据集进行训练,不太可能获得可以接受的性能。为了改善数据集的样本数量及分布,我们将目光转向了数据增强 (Data Augmentation) 的相关方法。考虑到在本项目背景下,图像信息具有平移、旋转与翻转后的语义不变性,我们尝试对已有的图像数据集进行数据增强的操作。 具体地,我们采用了旋转 (rotation) 、缩放 (zoom and scale) 、错切(shear) 、水平及垂直 翻转 (horizontal and vertical flip) 、水平及垂直平移 (width and height shift) 的方案对图像进行处理以大量生成人工合成的图像样本。我们使用Keras库的带有自定义参数的图像数据生成器来执行数据增强,设置rotation_range = 135, shear_range = 0.3, horizontal_flip = true, width_shift_range = 0.2, height_shift_range = 0.2, zoom_range = 0.5, and fill_mode = ‘wrap’。在此过程中,我们确保对两种不同类别的样本数据应用不同的扩增次数,以使扩增后的样本数量大体平衡。扩增之后的数据集信息如下表所示。
在深度学习中,我们很好地把数据图片进行了增强,但在实际的训练过程中,我们留意到,利用该网络对增强后的数据集进行拟合时,训练集上的准确率 (accuracy) 上升得很快,但验证集上的准确率却一直处于较低的水平,模型的泛化能力较低,出现了过拟合的现象。经过分析,我们认为这是因为虽然数据集经过了一定的增强,在原始数据的数量较为受限的情况下,其含有的数据量并不足以支撑从零开始训练深层网络。但是实际上,为了能够从图像中提取必要的微小细节,网络的深度并不适合进行缩减。基于已有的数据集,使用该网络进行厨余垃圾异物检测的任务并不能提供可以接受的性能。基于以上的考虑,我们将目光转向了依赖已有的预训练模型进行迁移学习 (transfer learning) 的方向。
具体地,我们去除在ImageNet 上预训练过的VGG16的全连接层,将剩下的卷积基用于图片的特征提取,并用提取的特征训练我们自定义的全连接层,增加一个droupuot以减小过拟合,根据实验得出,在本项目图片数据上使用Dropout 0.5表现最好。

在基于VGG16的迁移模型中,我们进行了100epoch


epoch=100
loss: 0.0604 – acc: 0.9856 – val_loss: 0.5067 – val_acc: 0.8543
test_loss: 0.5144659558526785
tess_accuracy: 0.8469072855448189
time:7s 329us/step
为了使得该模型对本项目的图片提取的特征在本项目下更能代表该图片,进而提高图片分类正确率,我们将对该模型进行微调。具体地,我们将微调最后三个卷积层,也就是说,直到 block4_pool 的所有层都应该被冻结,而 block5_conv1、block5_conv2 和 block5_conv3 三层应该是可训练的。



epoch=50
loss: 0.0286 – acc: 0.9905 – val_loss: 0.4402 – val_acc: 0.8717
test_loss: 0.373294844339089
tess_accuracy: 0.8885012701039792
time:101s 1s/step
; 5、结果Result

传统的模板匹配方法由于模板数量有限、模板类别单一等因素,获得的准确率较低,而对于多种多样的垃圾种类和垃圾形态来说增加模板数量和类别是一项难以实现的任务。而求助于机器学习的方式可以获得更高的准确率,在SVM分类器中模板匹配作为特征值来源的方案得到了最低的准确率,是因为只利用了相关性这唯一的特征,特征单一且精度不够,使用HOG特征后,效果大幅提升,但是模型过大,不方便推广使用。使用深度学习可以通过增加层数得到更多特征,模型效果也会比机器学习更好,而实验中VGG16迁移模型效果要略逊于HOG+SVM,微调后的模型效果稍好一些。原因在于我们使用的数据数量仍旧过少,未来更多的数据补充会充分发挥深度学习的优势。加之考虑到深度学习有更好的泛化能力,我们的系统模型选择微调后的迁移模型。
六、Demo界面开发:
在建立完我们的分类模型后,为了更好地进行人机交互,我们设计了系统使用界面,来模拟日常投放垃圾场景。这个界面主要具备三种功能:
- 获得输入垃圾图片
- 后端进行分类判别
- 现实合格结果和不合格警示
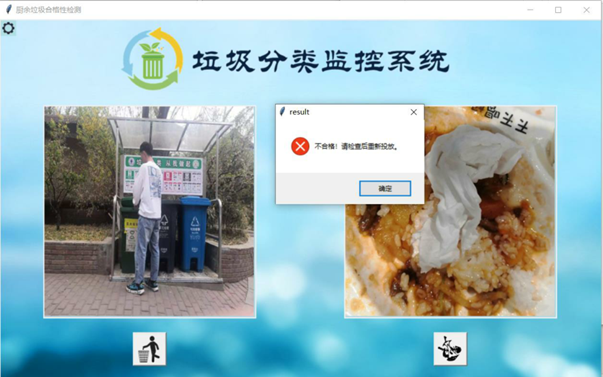
除此之外,为了更好地还原系统使用场景和系统的功能,我们还在demo中加入了投放时间控制模块和管理员修改参数模块(需要密钥)。



; 七、结论conclusion:
我们提出了一个基于深度学习算法的厨余垃圾判别系统,我们的系统设计符合现在的社会需求,可以解决厨余垃圾回收的困难,减少人力成本。在各地的垃圾分类政策多样的情况下,我们的方案立足于垃圾分类方向中的一类,规避了许多政策不统一的缺点,且成本低廉,而背后带来的厨余垃圾回收的效益显著。从结果来看,当我们对垃圾数据集进行测试时,得到了88.9%的准确率。未来我们会丰富数据集,系统的精度和泛化能力可以进一步提高。

八、代码:
1、模板匹配
(1)Train:
import cv2
import os
import matplotlib.pyplot as plt
import numpy as np
Files=os.listdir("train")
img_nums=len(Files)-4
flag=[]
templet1 = cv2.imread("train\\moban1.jpg")
templet2 = cv2.imread("train\\moban2.jpg")
templet3 = cv2.imread("train\\moban3.jpg")
templet4 = cv2.imread("train\\moban4.jpg")
temp=[templet1,templet2,templet3,templet4]
for i in range(0,img_nums):
flag.append(Files[i].split("-")[0])
def template_matching(temp):
temp_num = len(temp)
m=0
n=0
con10=np.zeros((temp_num, 50), dtype=float)
con11=np.zeros((temp_num, 50), dtype=float)
con20= np.zeros((temp_num, 50), dtype=float)
con21= np.zeros((temp_num, 50), dtype=float)
for i in range(0,temp_num):
for j in range(0, img_nums):
img = cv2.imread("train\\" + Files[j])
result = cv2.matchTemplate(img, temp[i],cv2.TM_CCOEFF_NORMED)
min_val, max_val, _, _ = cv2.minMaxLoc(result)
if flag[j] == '0':
con10[i,m]=min_val
con20[i,m] = max_val
m+=1
if m==50:
m=0
else:
con11[i,n] = min_val
con21[i,n] = max_val
n+=1
if n==50:
n=0
return con10,con11,con20,con21
def datansys(con0,con1):
for i in range(0,len(temp)):
pot1=plt.scatter(np.arange(50), con0[i,:],s=5,c='b')
pot2=plt.scatter(np.arange(50), con1[i,:], s=5, c='r')
plt.legend(handles=[pot1, pot2],
labels=['unqualified', 'qualified'],
loc='best')
plt.text(0,0.1,'moban'+str(i+1))
plt.show()
con10,con11,con20,con21=template_matching(temp)
datansys(con20,con21)
(2)Test:
import cv2
import os
import numpy as np
Files=os.listdir("shujuji")
img_nums=len(Files)-2
flag=[]
templet1 = cv2.imread("shujuji\\moban1.jpg")
templet2 = cv2.imread("shujuji\\moban2.jpg")
temp=[templet1,templet2]
mod=np.array([0.39,0.39])
for i in range(0,img_nums):
flag.append(Files[i].split("-")[0])
def template_matching(temp):
temp_num = len(temp)
con1=np.zeros((temp_num, img_nums), dtype=float)
con2=np.zeros((temp_num, img_nums), dtype=float)
for i in range(0,temp_num):
temp[i] = cv2.resize(temp[i], None, fx=0.43, fy=0.43)
for j in range(0, img_nums):
img = cv2.imread("shujuji\\" + Files[j])
result = cv2.matchTemplate(img, temp[i],cv2.TM_CCOEFF_NORMED)
min_val, max_val, _, _ = cv2.minMaxLoc(result)
con1[i,j]=min_val
con2[i,j]=max_val
return con1,con2
def judge(mod,con1,con2):
acc = 0
err = 0
judge_flag=np.zeros(img_nums)
for i in range(0,len(mod)):
for j in range(0, img_nums):
if con1[i,j]<mod[i]: con1[i,j]="0" else: if con2[i,j]>mod[i]:
con2[i,j]=0
else:
con2[i,j]=1
judge_flag[j]+=con2[i,j]
for i in range(0, img_nums):
if judge_flag[i]==len(mod) and flag[i] == '1':
print("垃圾图片" + Files[i] + "合格,判断正确")
acc += 1
elif judge_flag[i]<len(mod) and flag[i]="=" '1': print("垃圾图片" + files[i] "不合格,判断不正确") err elif judge_flag[i]<len(mod) '0': "不合格,判断正确") acc else: "合格,判断不正确") print("总共有{}张图片,有{}张图片判断正确,{}张图片判断不正确,正确率为{}".format(img_nums, acc, err, img_nums)) con1,con2="template_matching(temp)" judge(mod,con1,con2) < code></len(mod)></mod[i]:>
2、模板匹配+SVM
(1)Train
import cv2
import os
import numpy as np
path="zituan"
Files=os.listdir(path)
img_nums=len(Files)-1
templet1 = cv2.resize(cv2.imread(path+"\\moban1.jpg"),(250,181))
print(Files)
#训练数据标签
flag=[]
for i in range(0,img_nums):
flag.append(Files[i].split("-")[0])
train_label=np.array(flag, dtype='int32')
#训练数据值
train_data=np.zeros(shape=(img_nums,520*451))
for i in range(0,img_nums):
img = cv2.imread(path+"\\" + Files[i])
img=cv2.resize(img,(700,700))
result = cv2.matchTemplate(img, templet1, cv2.TM_CCOEFF_NORMED)
print(Files[i],result.shape)
result=np.array(result,dtype='float32')
train_data[i,:]=result.flatten()
train_data=np.array(train_data,dtype='float32')
#SVM
svm = cv2.ml.SVM_create() #创建SVM model
#属性设置
svm.setType(cv2.ml.SVM_C_SVC)
svm.setKernel(cv2.ml.SVM_INTER)
svm.setC(0.01)
#训练
res = svm.train(train_data,cv2.ml.ROW_SAMPLE,train_label)
print("11111")
test_data=np.zeros(shape=(1,520*451))
acc=0
for i in range(0,img_nums):
test = cv2.imread(path+"\\" + Files[i])
test = cv2.resize(test, (700, 700))
result = cv2.matchTemplate(test, templet1, cv2.TM_CCOEFF_NORMED)
result = np.array(result, dtype='float32')
test_data[0,:]=result.flatten()
test_data=np.array(test_data,dtype="float32")
(par1,par2) = svm.predict(test_data)
print(par2[0,0])
if par2[0,0]==train_label[i]:
acc+=1
print(acc,acc/img_nums)
#print(svm.getSupportVectors())
svm.save(path+"_svm_data.dat")
(2)Test
import cv2
import os
import numpy as np
templet1 = cv2.resize(cv2.imread("suliao\\moban1.jpg"),(250,181))
templet2 = cv2.resize(cv2.imread("zituan\\moban1.jpg"),(250,181))
size = (700,700)
svm1=cv2.ml.SVM_load("suliao_svm_data.dat")
svm2=cv2.ml.SVM_load("zituan_svm_data.dat")
Files=os.listdir("new-photos\\test")
img_nums=len(Files)
#训练数据标签
flag=[]
for i in range(0,img_nums):
flag.append(Files[i].split("-")[0])
test_label=np.array(flag, dtype='int32')
acc=0
test_data1=np.zeros(shape=(1,520*451))
test_data2=np.zeros(shape=(1,520*451))
for i in range(0,img_nums):
img = cv2.imread("new-photos\\test\\"+Files[i])
img = cv2.resize(img, (700, 700))
result1 = cv2.matchTemplate(img, templet1, cv2.TM_CCOEFF_NORMED)
result2 = cv2.matchTemplate(img, templet2, cv2.TM_CCOEFF_NORMED)
result1 = np.array(result1, dtype='float32')
result2 = np.array(result2, dtype='float32')
test_data1[0, :] = result1.flatten()
test_data2[0, :] = result2.flatten()
test_data1 = np.array(test_data1, dtype='float32')
test_data2= np.array(test_data2, dtype='float32')
(par1, par2) = svm1.predict(test_data1)
(par3, par4) = svm2.predict(test_data2)
if (par2[0, 0] == test_label[i]) and par2[0, 0] == 0:
acc += 1
print(Files[i], "有塑料,判断正确")
continue
elif (par4[0, 0] == test_label[i]) and par4[0, 0] == 0:
acc += 1
print(Files[i], "有纸团,判断正确")
continue
elif par4[0, 0] == test_label[i] or par2[0, 0] == test_label[i]:
acc += 1
print(Files[i], "无纸团,无塑料,判断正确")
else:
print(Files[i], "判断错误")
print(img_nums, acc, acc / img_nums)
3、HOG特征+SVM
(1)Train
import cv2
import os
import numpy as np
path='suliao'
size = (200,200)
Files=os.listdir(path)
img_nums=len(Files)
print(Files)
#训练数据标签
flag=[]
for i in range(0,img_nums):
flag.append(Files[i].split("-")[0])
train_label=np.array(flag, dtype='int32')
#训练数据值
winSize = (128,128)
blockSize = (64,64)
blockStride = (8,8)
cellSize = (16,16)
nbins = 9
winStride = (8,8)
padding = (8,8)
train_data=np.zeros(shape=(img_nums,1679616))
for i in range(0,img_nums):
img = cv2.imread(path + "\\"+Files[i])
img = cv2.resize(img, size)
#定义对象hog,同时输入定义的参数,剩下的默认即可
hog = cv2.HOGDescriptor(winSize,blockSize,blockStride,cellSize,nbins)
train_hog = hog.compute(img, winStride, padding).reshape((-1,))
train_data[i,:]=train_hog
train_data=np.array(train_data,dtype='float32')
svm = cv2.ml.SVM_create() #创建SVM model
#属性设置
svm.setType(cv2.ml.SVM_C_SVC)
svm.setKernel(cv2.ml.SVM_INTER)
svm.setC(0.1)
#训练
res = svm.train(train_data,cv2.ml.ROW_SAMPLE,train_label)
acc=0
test_data=np.zeros(shape=(1,1679616))
for i in range(0, img_nums):
img = cv2.imread(path + "\\"+Files[i])
img = cv2.resize(img, size)
# 定义对象hog,同时输入定义的参数,剩下的默认即可
hog = cv2.HOGDescriptor(winSize, blockSize, blockStride, cellSize, nbins)
test_data[0,:] = hog.compute(img, winStride, padding).reshape((-1,))
test_data=np.array(test_data,dtype='float32')
(par1,par2) = svm.predict(test_data)
if par2[0,0]==train_label[i]:
acc+=1
print(par2)
print(acc,acc/10)
svm.save(path+"_hog_svm_data.dat")
(2)Test
import cv2
import os
import numpy as np
size=(200,200)
svm1=cv2.ml.SVM_load("F:\\xuexiwenjian\\dc\\svm-model\\suliao_hog_svm_data_base.dat")
svm2=cv2.ml.SVM_load("F:\\xuexiwenjian\\dc\\svm-model\\zituan_hog_svm_data_base.dat")
Files=os.listdir("new-photos\\test")
img_nums=len(Files)
winSize = (128,128)
blockSize = (64,64)
blockStride = (8,8)
cellSize = (16,16)
nbins = 9
winStride = (8,8)
padding = (8,8)
#训练数据标签
flag=[]
for i in range(0,img_nums):
flag.append(Files[i].split("-")[0])
test_label=np.array(flag, dtype='int32')
acc=0
for i in range(0,1):
img = cv2.imread("new-photos\\test\\"+Files[i])
img = cv2.resize(img, size)
test_data=np.zeros(shape=(1,1679616))
#定义对象hog,同时输入定义的参数,剩下的默认即可
hog = cv2.HOGDescriptor(winSize,blockSize,blockStride,cellSize,nbins)
test_data[0,:] = hog.compute(img, winStride, padding).reshape((-1,))
test_data=np.array(test_data,dtype='float32')
(par1, par2) = svm1.predict(test_data)
(par3, par4) = svm2.predict(test_data)
if (par2[0,0]==test_label[i]) and par2[0,0]==0:
acc+=1
print(Files[i],"有塑料,判断正确")
continue
elif (par4[0,0]==test_label[i]) and par4[0,0]==0:
acc += 1
print(Files[i], "有纸团,判断正确")
continue
elif par4[0,0]==test_label[i] or par2[0,0]==test_label[i]:
acc+=1
print(Files[i], "无纸团,无塑料,判断正确")
else:
print(Files[i],"判断错误")
print(img_nums,acc,acc/img_nums)
4、VGG16迁移学习及微调
(1)图片增强image_augmentation


from keras.preprocessing import image as imageGenerator
CUR_PATH='F:/xuexiwenjian/dc/ssss'
SAVE_PATH='F:/xuexiwenjian/dc/gen'
datagen = imageGenerator.ImageDataGenerator(rotation_range=135,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.3,
zoom_range=0.5,
horizontal_flip=True,
vertical_flip=True,
fill_mode='wrap'
)
gen_data = datagen.flow_from_directory(CUR_PATH,
batch_size=40,
shuffle=False,
save_to_dir=SAVE_PATH,
save_prefix='gen',
save_format='jpeg',
)
#生成x张图
for i in range(40):
gen_data.next()
(2)图片名称处理image_data progress
import os
import numpy as np
import cv2
path = input('请输入文件路径(结尾加上/):')
获取该目录下所有文件,存入列表中
imgList = os.listdir(path)
index = [i for i in range(len(imgList))]
np.random.seed(1)
np.random.shuffle(index)
for i in range(0,len(imgList)):
# 设置旧文件名(就是路径+文件名)
oldname = path + os.sep + imgList[i] # os.sep添加系统分隔符
# 设置新文件名
if i<len(imglist)*0.1: newname="path" + os.sep 'valid_pass_' str(i 1) '.jpeg' else: 'train_pass' 1-round(0.1*len(imglist))) os.rename(oldname, newname) # 用os模块中的rename方法对文件改名 print(oldname, '="=====">', newname)
</len(imglist)*0.1:>
(3)Train
import numpy as np
import cv2
import os
from keras.preprocessing.image import ImageDataGenerator
from keras import models
from keras import layers
from keras import optimizers
import matplotlib.pyplot as plt
from keras.applications import VGG16
epochs = 50
batch_size = 20
#
#
#
train_data_path="F:\\xuexiwenjian\\dc\\image_data\\train"
valid_data_path="F:\\xuexiwenjian\\dc\\image_data\\valid"
test_data_path="F:\\xuexiwenjian\\dc\\image_data\\test"
#
#
conv_base = VGG16(weights='imagenet', include_top=True, input_shape=(224, 224, 3))
train_datagen = ImageDataGenerator(rescale=1. / 255)
valid_datagen=ImageDataGenerator(rescale=1. / 255)
conv_base.summary()
#
conv_base.trainable = True
set_trainable = False
for layer in conv_base.layers:
if layer.name == 'block5_conv1':
set_trainable = True
if set_trainable:
layer.trainable = True
else:
layer.trainable = False
def extract_features(directory, sample_count):
features = np.zeros(shape=(sample_count, 4, 4, 512))
labels = np.zeros(shape=(sample_count))
generator = datagen.flow_from_directory(directory, target_size=(150, 150), batch_size=batch_size, class_mode='binary')
i = 0
for inputs_batch, labels_batch in generator:
features_batch = conv_base.predict(inputs_batch)
features[i * batch_size: (i + 1) * batch_size] = features_batch
labels[i * batch_size: (i + 1) * batch_size] = labels_batch
i += 1
if i * batch_size >= sample_count:
break
return features, labels
def plot_image(history):
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
#
train_features, train_labels = extract_features(train_data_path, 20125)
train_features = np.reshape(train_features, (20125, 4 * 4 * 512))
np.save('train_features.npy',train_features)
np.save('train_labels.npy',train_labels)
validation_features, validation_labels = extract_features(valid_data_path, 2238)
validation_features = np.reshape(validation_features, (2238, 4 * 4 * 512))
np.save('validation_features.npy',validation_features)
np.save('validation_labels.npy',validation_labels)
test_features, test_labels = extract_features(test_data_path, 7453)
test_features = np.reshape(test_features, (7453, 4 * 4 * 512))
np.save('test_features.npy',test_features)
np.save('test_labels.npy',test_labels )
train_features=np.load("F:\\xuexiwenjian\\dc\\nurel-network\\train_features.npy")
train_labels=np.load("F:\\xuexiwenjian\\dc\\nurel-network\\train_labels.npy")
validation_features=np.load("F:\\xuexiwenjian\\dc\\nurel-network\\validation_features.npy")
validation_labels=np.load("F:\\xuexiwenjian\\dc\\nurel-network\\validation_labels.npy")
top_model = models.Sequential()
#
top_model.add(layers.Dense(256, activation='relu',input_dim=4 * 4 * 512))
top_model.add(layers.Dropout(0.5))
top_model.add(layers.Dense(1, activation='sigmoid'))
top_model.summary()
note that it is necessary to start with a fully-trained
classifier, including the top classifier,
in order to successfully do fine-tuning
#top_model.load_weights("F:\\xuexiwenjian\\dc\\nurel-network\\VGG\\VGG_100epoch.h5")
add the model on top of the convolutional base
model=models.Sequential()
model.add(conv_base)
model.add(layers.Flatten())
model.add(top_model)
model.load_weights("F:\\xuexiwenjian\\dc\\nurel-network\\VGG\\VGG50epoch_fine_.h5")
model=models.load_model("F:\\xuexiwenjian\\dc\\nurel-network\\VGG\\VGG50epoch_fine_network.h5")
compile the model with a SGD/momentum optimizer
and a very slow learning rate.
model.compile(loss='binary_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
#
train_generator = train_datagen.flow_from_directory(
train_data_path,
target_size=(150, 150),
batch_size=batch_size,
class_mode='binary')
#
validation_generator = valid_datagen.flow_from_directory(
test_data_path,
target_size=(150, 150),
batch_size=batch_size,
class_mode='binary')
val=model.predict_generator(validation_generator)
print(val)
model.compile(optimizer=optimizers.RMSprop(lr=2e-5), loss='binary_crossentropy', metrics=['acc'])
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=epochs,
validation_data=validation_generator,
validation_steps=50)
#
model.save_weights('VGG_.h5')
plot_image(history)
val=np.load("test_warn_val.npy")
np.save("test_pass_val.npy",val)
pot1=np.load("test_warn_val.npy")
pot2=np.load("test_pass_val.npy")
for i in val:
if i>0.5:
pot1.append(i)
else:
pot2.append(i)
pot1 = plt.scatter(np.arange(4207), pot1, s=1, c='b')
pot2 = plt.scatter(np.arange(3246), pot2, s=1, c='r')
plt.legend(handles=[pot1, pot2],
labels=['warn', 'pass'],
loc='best')
#
plt.show()
(4)Test
from keras.models import load_model
import numpy as np
import cv2
from matplotlib.pyplot import plot
from keras import models
from keras import layers
from keras import optimizers
from keras.preprocessing.image import ImageDataGenerator
from keras.applications import VGG16
img_path="F:\\xuexiwenjian\\dc\\image_data\\test\\warn\\test_warn_732.jpeg"
model =models.Sequential()
model.add(layers.Dense(256, activation='relu', input_dim=4 * 4 * 512))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid'))
#
model.compile(optimizer=optimizers.RMSprop(lr=2e-5), loss='binary_crossentropy', metrics=['acc'])
#
model.load_weights('F:\\xuexiwenjian\\dc\\nurel-network\\VGG\\VGG_100epoch.h5')
# x_test=np.load("F:\\xuexiwenjian\\dc\\nurel-network\\test_features.npy")
# y_test=np.load("F:\\xuexiwenjian\\dc\\nurel-network\\test_labels.npy")
#
conv_base = VGG16(weights='imagenet', include_top=False, input_shape=(150, 150, 3))
# datagen = ImageDataGenerator(rescale=1. / 255)
# inputs=datagen.flow(img_path)
#
inputs=cv2.resize(cv2.imread(img_path),(150,150))/255
inputs=np.reshape(inputs,(1,150,150,3))
features= conv_base.predict(inputs)
features = np.reshape(features, (1, 4 * 4 * 512))
top_model = models.Sequential()
#
top_model.add(layers.Dense(256, activation='relu',input_dim=4 * 4 * 512))
top_model.add(layers.Dropout(0.5))
top_model.add(layers.Dense(1, activation='sigmoid'))
#
conv_base = VGG16(weights='imagenet', include_top=False, input_shape=(150, 150, 3))
#
conv_base.trainable = True
set_trainable = False
for layer in conv_base.layers:
if layer.name == 'block5_conv1':
set_trainable = True
if set_trainable:
layer.trainable = True
else:
layer.trainable = False
#
model=models.Sequential()
model.add(conv_base)
model.add(layers.Flatten())
model.add(top_model)
model.load_weights("F:\\xuexiwenjian\\dc\\nurel-network\\VGG\\VGG50epoch_fine_.h5")
model=models.load_model("F:\\xuexiwenjian\\dc\\nurel-network\\VGG\\VGG50epoch_fine_network.h5")
con=model.predict_generator(inputs)
print(con)
img=cv2.resize(cv2.imread(img_path),(500,500))
#
if con[0][0]>0.5:
cv2.putText(img, "warn", (30,30),cv2.FONT_HERSHEY_COMPLEX,1, (0,255,0))
else:
cv2.putText(img, "pass", (30, 30), cv2.FONT_HERSHEY_COMPLEX,1,(0, 255, 0))
cv2.imshow("img",img)
cv2.waitKey()
cv2.destroyWindow()
loss,accuracy = model.evaluate(x_test,y_test)
print('\ntest_loss:',loss)
print('tess_accuracy:',accuracy)
九、视频演示:
基于机器学习的垃圾分类监控系统设计与实现
Original: https://blog.csdn.net/xia_hua_yan/article/details/124125475
Author: summer_夏-_-
Title: 【基于机器学习的垃圾分类监控系统】
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/662777/
转载文章受原作者版权保护。转载请注明原作者出处!