

一文详细介绍情绪识别常用的数据集
本文详细介绍了脑机接口情绪识别常用的数据集,主要有SEED, SEED-IV, SEED-V, DEAP, CIAIC。
SEED
SEED数据集下载地址
SEED数据集不开放给个人使用,若想使用必须写申请。
采集情况
- 每组实验有15个trials,每个trial的实验过程如下图所示


图1 一个trial的实验过程
每一个trail的设置过程分为,开始前的5s暗示,4min的电影片段,45s的自我评估,15s的休息过程。
- 一共有15个subject,7个男生,8个女生。
; 文件介绍
在官网得到许可后下载的文件夹包括两部分:”Preprocessed_EEG” 和 “Extracted_Features”
- Preprocessed_EEG文件介绍
已经采用了一些预处理过程:降采样到200hz,使用了0-75Hz的低通滤波器,已经提取了电影期间的脑电图片段,也就是4min左右的脑电图。一共有45个.mat文件,分别代表15个受试者的每人3次实验。还有一个label.mat代表15次实验的标签,SEED数据集的情绪标签有三类,(negative, neutral, positive),其中标签是(-1 ,0 ,1)。一次实验的数据如图所示: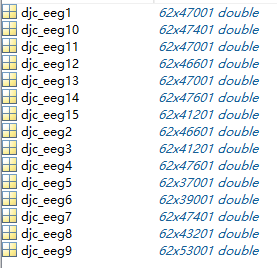 图2 一个experiment的文件内容(channel × data)
图2 一个experiment的文件内容(channel × data) - Extracted_Features文件介绍
这个文件提供了所有经过特征提取之后的数据,包扣DE(differential entropy)特征,DASM(differential asymmetry)特征,rational asymmetry(RASM)特征。所有特征经过传统的移动平均或者线性动态系统(LDS)进一步平滑。

图3 Extracted_Features文件部分内容
SEED-IV
以下内容翻译自官网介绍https://bcmi.sjtu.edu.cn/~seed/seed-iv.html
采集情况
- 依然是15个subject,每个subject在不同天做3个session,每个session包括24个trials,一共有72个电影片段,所以每个受试者做的3个session看的电影片段都是不同的。

图4 一个trial的实验过程
- 但是与SEED数据集不同的一点在于,SEED-IV采集了眼部运动的数据
; 文件介绍
- eeg_raw_data
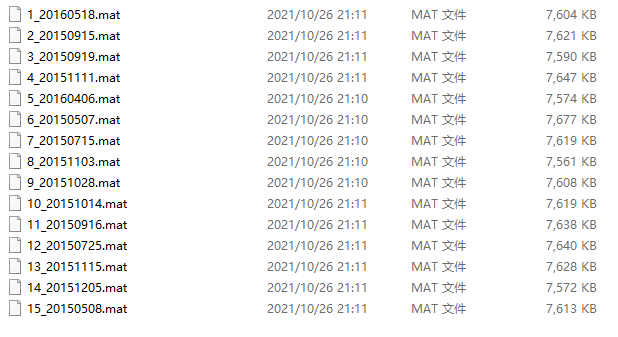
文件夹里包含三个文件”1″,”2″,”3″,分别代表每个受试者的3个session,每个文件夹里包含15个.mat文件,命名方式为:
{Subject}_{Date}.mat。

2. eeg_feature_smooth
这个文件夹和eeg_raw_data文件夹的结构一样,现在对每一个具体的.mat文件介绍:

有两种特征提取方式(PSD,DE),两种数据平滑方式(LDS, movingAve),组合一下就是4种方式。在每种方式下,进行数据处理,提取的是4s片段,所以2min左右的视频,一个trial大概有30个左右的sample,每组数据的的shape代表:(channel_number × sample_number × frequency_bands)
- eye_raw_data
这个文件夹包含了眼部移动信息,每个session包含5个文件(blink, event, fixation, pupil, saccade)。

blink文件内容如下图所示:

24:一个session有24个实验或者24个电影片段 ,n×1:n代表眨眼次数,n位置的数值代表眨眼时间。
event文件内容如下图所示:

24:一个session有24个实验或者24个电影片段, 28:28种与眼部有关的事件,位置上的数值代表该事件发生的一个度量。
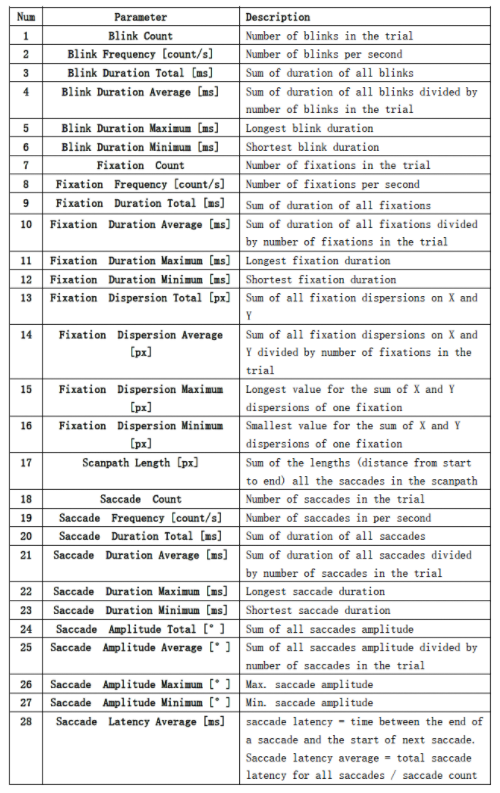
fixation文件内容如下图所示:

24:一个session有24个实验或者24个电影片段, n×1:n眼部固定不动的次数,n位置上的数值代表本次固定不动的时间
pupil文件内容如下图所示:

24:一个session有24个实验或者24个电影片段, n×4:n代表记录瞳孔信息的次数,4代表与瞳孔度量相关的4种属性
saccade文件内容如下图所示:

24: 一个session有24个实验或者24个电影片段, n×2:n代表记录扫视的次数,2代表扫视的时间与角度
- channel Order and Readme
分别介绍了62通道顺序和72个电影片段的label信息。
CIAIC多模态情感识别数据
数据下载http://challenge.xfyun.cn/topic/info?type=eeg
该数据集是由西北工业大学智能声学与临境通信研究中心提供消声室低噪声环境下的情绪数据库,其中包括在四种不同情绪唤起刺激条件下的脑电(EEG)数据。相比其他数据库,该数据提供了高质量、丰富的数据库。挑战赛数据库包括60名受试者在理想低噪声环境下,在平和、开心、愤怒、伤心四种情绪唤起刺激材料下的脑电数据,数据时长约为40小时。低噪声理想环境数据采集于西北工业大学消声暗室环境,大幅降低噪声以及电磁干扰。
采集情况
目标情绪包含:开心,伤心,愤怒,平和。 在预实验阶段,共选出8个能够诱发目标情绪的电影片段,每个情绪包含两个诱发影片。实验过程中,8个视频随机播放,被试先观看一个诱发视频,调动出单一的目标情绪,然后在此种情绪的影响下带有感情地朗读事先准备好的30句文本,接着填写自我情绪评价表,完成后休息片刻,继续下一个影片的播放。实验设备安放及流程图如下图所示:

实验过程
; 文件介绍
竞赛数据包含60个被试者的脑电数据,数据名称为subject.mat。每一个subject.mat文件包含四种数据:channel_location, data, fs, name.
其中channel_location为68个脑电通道的名称及坐标位置。68通道包含:62通道的脑电数据,M1, M2两通道为双耳后突起处的电极点,4通道的眼电信号。眼电电极的安放位置如图所示:

眼电电极安装位置
data 为161维的cell数据格式,是采集到的68通道脑电信号。name 是161维cell数据,为data对应的标签信号。

name中,sad表示悲伤, neu为平和情绪,hap代表开心,ang为愤怒。各单元格的元素意义为:sad_1_per 为被试观看第一个(1)影片时,感受(perceive)到的悲伤(sad)情绪,sad_1_exp 为被试观看第一个(1)影片后,在第一个影片情绪的影响下,表达(express)出来的悲伤(sad)情绪 … ang_2_per为被试观看第二个(2)影片时,感受(perceive)到的愤怒(angry)的情绪,ang_2_exp为被试在第二个愤怒影片的影响下,表达(express)出的愤怒(angry)情绪。data 中各单元格中的数据为”通道数*时长”,通道:68维脑电通道, 时长:被试观看影片的时长或者是被试有感情地表达文本的时长。fs 为脑电信号采样率,为1000Hz。本次竞赛共60个被试的脑电数据,训练数据为前48个被试的脑电数据,标签为: ‘sad’= 1, ‘neu’ = 2, ‘hap’ = 3, ‘ang’ = 4. 测试数据为10个被试者的脑电数据, 其中一个样本长度为1秒,进行预测。
DEAP
与上面几个数据集相比,DEAP算是比较早的一个研究情感的数据集。
DEAP(Database for Emotion Analysis using Physiological Signals), 该数据库是由来自英国伦敦玛丽皇后大学,荷兰特温特大学,瑞士日内瓦大学,瑞士联邦理工学院的Koelstra等人通过实验采集得到的,用来研究人类情感状态的多通道数据,可以公开免费获取。
采集情况
可以参考脑机接口社区博客
文件情况
一般可以采用官方经过python预处理之后的脑电数据做分析,他们把原始数据下采样至128Hz,去除了EOG伪像,并且应用4.0-45.0Hz的带通频率滤波器,数据取平均值作为通用参考,并将数据分为60秒钟的实验(需要自己删除前3s的实验准备过程的数据)。
data_preprocessed_python里面包含了s01~s32的32个.dat文件,每个文件包含两个数组:


; SEED-V
SEED-V数据集下载https://bcmi.sjtu.edu.cn/~seed/downloads.html#seed-v-access-anchor

实验过程

目标情绪
; 采集情况
为了研究情绪识别的稳定性以及确保刺激的有效性,每一个受试者要参加三次实验。每次实验需要看15个电影片段(目标情绪有:happy, sad, disgust, neutral, fear五种,15个片段每种情绪3个片段),一次实验总的时间被控制在50min左右。采集设备为62通道的ESI NeuroScan System 和SMI eye-tracking glasses
在播放每个电影片段之前会有15s的时间告诉受试者本次实验希望激发的目标情绪以及电影片段的一个背景。每段影片播放之后会有15s或30s的自我评估加休息时间,如果影片是激发恐惧情绪或厌恶情绪的,则有30s。如果是剩下的3种情绪,则有15s。
在自测部分,要求被试根据电影片段的刺激效果进行评分。 评分范围为0-5分,其中5分表示刺激效果最好,0分表示最差。 如果参与者在观看快乐视频后感到快乐,应该给他们 4-5 分,如果他们没有任何感觉,应该给他们 0 分。 需要注意的是,如果正在观看平静情绪的电影片段 ,如果被试情绪波动,得分应为0分,自然状态为5分。
这是我个人认为这几个数据集中自我评估非常合理的一种方式,必须让受试者评价电影片段是否可以诱导出我们想要的情绪,这样的采集的数据集才比较准确。
文件情况
- 文件夹 EEG_DE_features
这个文件夹包括16个受试者的DE特征,和一个用来加载数据的样例代码,数据被命名的方式为”subjectID_sessionID.npz”。例如文件”1_123″意味着这个文件是第一个受试者三个session的DE特征合集。 - 文件夹EEG_raw
这个文件夹包括从Neuroscan设备上采集的原始数据和一个用来加载数据的样例代码。数据被命名的方式为”subjectID_sessionID.cnt”。例如文件”1_1_20180804.cnt”代表第一个受试者一个session的数据。注意:session的序号是基于刺激材料而不是基于时间。 - 文件夹Eye_movement_features
这个文件夹包含了提取的眼部移动特征数据 - 文件夹Eye_raw
这个文件夹包含了eye tracking device提取的原始数据 -
文件夹src:
这个文件夹包含了两个子文件夹,有两个模型,模型来源于paper
Wei Liu, Jie-Lin Qiu, Wei-Long Zheng and Bao-Liang Lu, Comparing Recognition Performance and Robustness of Multimodal Deep Learning Models for Multimodal Emotion Recognition, IEEE Transactions on Cognitive and Developmental Systems, 2021. -
文件 trial_start_end_timestamp.txt:
这个文件包含了电影的开始和终止的时间 - 文件emotion_label_and_stimuli_order.xlsx
这个文件包含了情绪标签和刺激序号 - 文件Participants_info.xlsx
这个文件包含了被试的元信息 - 文件Scores.xlsx
这个文件包含了被试的反馈信息(打分)
Original: https://blog.csdn.net/zhsmkxy/article/details/120975272
Author: 丶夜未央丶
Title: 一文详细介绍情绪识别常用的数据集
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/662454/
转载文章受原作者版权保护。转载请注明原作者出处!