

1. 理论基础
1.1卷积神经网络(CNN)
卷积神经网络(CNN)是典型的前馈神经网络,由输入层,隐藏层和输出层组成。隐藏层由卷积层,池化层和全连接层组成。卷积模拟单个神经元对视觉刺激的反应。它使用卷积层卷积输入数据,然后将结果传输到下一层。卷积层由一组卷积核组成。尽管这些内核具有较小的感知视野,但是内核延伸到输入数据的整个深度。卷积运算可以提取输入数据的深层特征。
1.1.1 卷积神经网络概述
卷积神经网络(CNN)是神经网络的一种,是深度学习的代表算法之一,卷积神经网络通过卷积、池化等操作可以实现特征的自动提取,再通过全连接层实现分类。
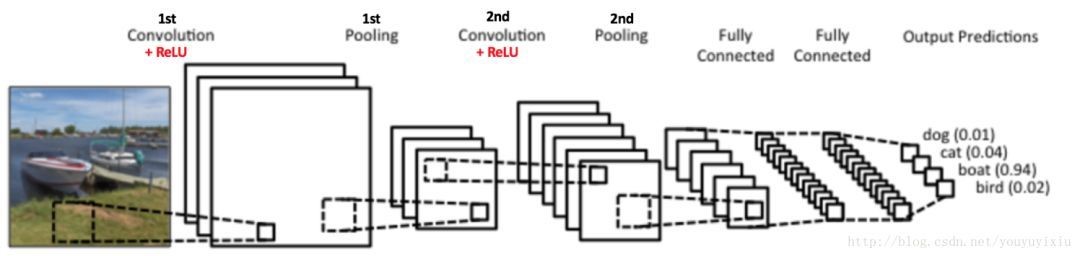

图 1 卷积神经网络结构图
1.1.2.卷积神经网络的结构
一般地,卷积神经网络由输入层、卷积层、RELU层、池化层和全连接层构成,通过梯度下降的方式训练网络模型的参数,从而实现分类。下面将对每类层进行介绍。
(1)卷积层
卷积神经网络的核心功能(特征提取)由卷积层完成。卷积层由许多可学习的卷积核(滤波器)构成,滤波器按照一定的步长对输入的张量进行遍历,当遇到某些类型的形状特征时就激活。
(2) 池化层
池化层又可称为下采样层,通过池化操作可以减少特征图的参数量,减少运算量。池化层对每个通道的特征图进行操作,不改变通道数,但减少每个通道的特征图的大小。常用的池化操作有均值池化和最大池化。
(3)全连接层
全连接层的主要作用是通过将特征向量映射到样本标记空间对经卷积、池化等操作后形成的特征向量进行分类。
1.2支持向量机(SVM)
支持向量机最早由Cortes和Vapnik等人于1995年基于统计学理论提出。
支持向量机进行多分类的算法原是通过某个核函数将输入样本投射到高维空间,然后在这个高维空间中求出最大边距超平面以使各类样本在高维空间线性可分。
假设n维空间中的样本集D={(xi,yi),i=1,2,3…l},xi为输入变量,yi为分类标记,样本对于超平面wx+b=0线性可分,w为权重向量,b为偏置变量,则分类间隔可表示为 ,为得到最优超平面,应使得超平面到两类样本的间隔尽可能远,因此需要求解如下凸二次规划问题:
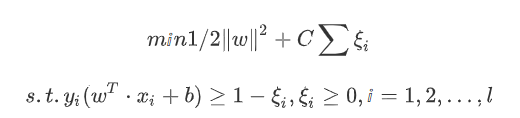
其中, 为松弛变量,表示允许错误分类的程度, 为错误分类惩罚参数,通过调整其大小可实现在最大化分类间隔与最小化错误分类之间的权衡。采用拉格朗日乘子法求解,得到如下拉格朗日函数:
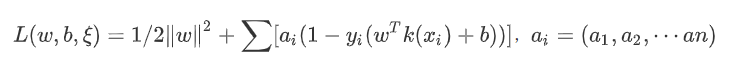
非线性SVM利用核函数的思想,寻求函数K,使向量P与Q满足K (P,Q)=(φ(P)⋅φ(Q)),从而无需知道φ的具体表达式,大大简化了算法难度。此时,特征空间的最优超平面决策函数y表示为
式中: 和 分别为支持向量xi对应的拉格朗日乘子和阈值。
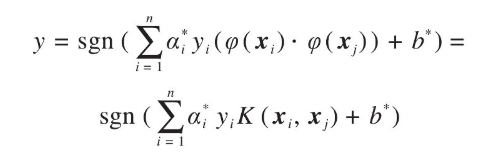
1.3遗传算法
遗传算法(GA)是基于生物界规律和自然遗传机制[[i]]的一种群智能算法,遗传算法来源于自然界的自然选择过程,故可以从达尔文的生物进化理论对遗传算法有一个基本的理解。遗传算法可通过模拟生物个体染色体的选择、交叉、变异实现全局寻优[[ii]]。就是在模拟自然界自然选择的过程,对于一个优化问题,我们通过编码,将实际问题抽象为遗传算法可”识别”的基因串,用适应值表示解的优秀程度,同时适应值不仅表示这个解的优秀程度,也代表着这个个体对环境的适应能力,适应值越高(或低,根据具体问题而定)表示这个个体越容易存活下来并产生子代。通过模拟自然界的进化过程(选择、交叉、变异),相对不优秀的个体逐渐被淘汰,种群整体上向更高水平进化,最终进化出最适应环境的个体,即最优个体。
2.实验及分析
2.1数据集介绍
实验选用的CIFAR-10数据集包含60000张图片,其中有50000被划分为训练集,10000张划分为测试集,所有照片分属于10个类别,分别是飞机、电动车、鸟、猫、鹿、狗、青蛙、马、船、卡车。每张图片为32×32的三通道图像,像素点的数值范围为0-255。

图 2CIFAR数据集部分图片
由于算法耗时较长,为减少实验时间,实验中对数据集进行了缩小,只取了10000张图片作为训练集、1000张图片作为测试集。
2.2算法介绍
2.2.1卷积神经网络(CNN)
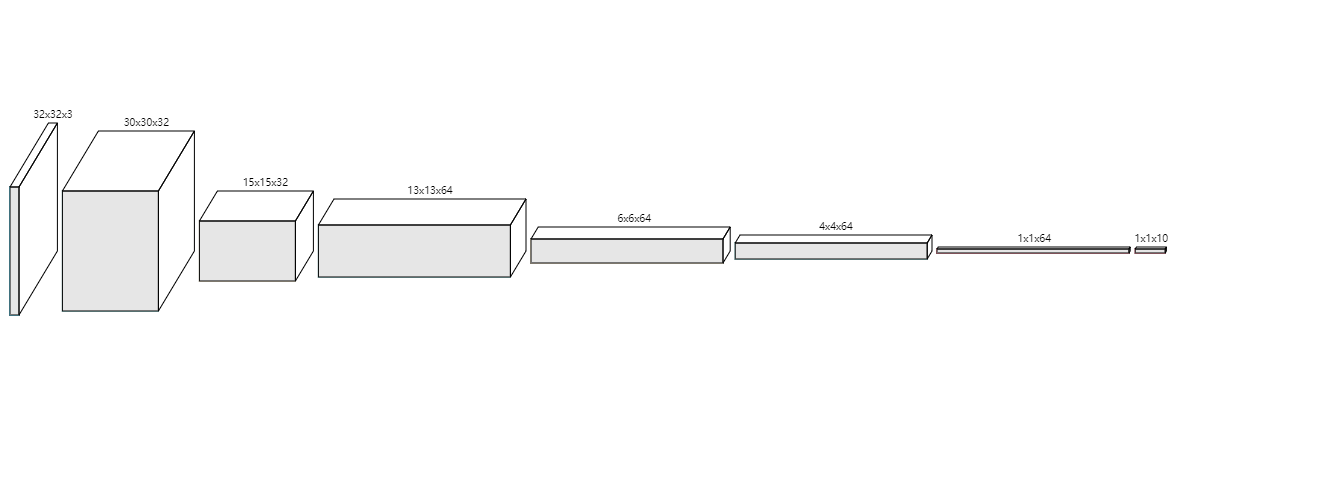
图 3卷积神经网络模型图
如图3所示,实验中采用的具体网络结构参数如表1所示:
表 1卷积神经网络结构
Kernel Input Size Output Size Active Function Convolution1 3×3×32 32×32×3 30×3032 Relu Pooling1 2×2 30×30×32 15×15×32 – Convolution2 3×3×64 15×15×32 13×13×64 Relu Pooling2 2×2 13×13×64 6×6×64 – Convolution3 3×3×64 6×6×64 4×4×64 Relu Flatten – 4×4×64 1024 – Full Connected1 – 1024 64 – Full Connected2 – 64 10 –
优化器选用Adam优化器,初始学习率设置为0.001;损失函数使用交叉熵损失函数。
2.2.2遗传算法(GA)
实验中以支持向量机的两个参数(惩罚因子c和核函数半径g)为个体基因基因进行编码,对应的支持向量机分类准确率为目标函数。遗传算法(GA)的选择策略采用轮盘赌策略,交叉率设为0.35,变异率设为0.1,种群规模设置为20,进化代数设置为3000代。
2.2.3支持向量机(SVM)
为了减少遗传算法优化的时间,支持向量机的核函数为径向基核函数(Radial Basis Function,RBF),遗传算法仅对惩罚因子c和核函数半径g两个参数进行优化。采用遗传算法求出的最优解解码作为支持向量机的参数,经PCA特征降维后的数据集作为训练集和测试集进行训练。
2.2.4 CNN-SVM-PSO算法流程

图 4基于CNN-SVM-GA的图像分类技术的算法流程图
基于CNN-SVM-GA的图像分类技术的算法流程如上图所示,具体步骤如下:
第一步:对图像数据集进行数据预处理,,并将数据集分为CIFAR-10数据集训练集和测试集;
第二步:建立卷积神经网络模型,用第一步的训练集和测试集对此模型进行训练;
第三步:提取第二步训练好的模型全连接层前的所有层构成一个新的模型,此模型输出的是一个特征向量;
第四步:对提取出的特征向量进行PCA特征降维,减少SVM的训练时间,形成新的训练集和测试集;
第五步:用第四步形成的训练集和测试集训练SVM模型,用遗传算法优化支持向量机的g和c参数。
2.3实验结果及分析
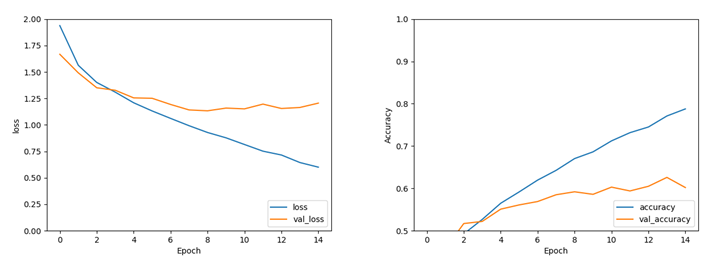
图 5 CNN训练过程图
图5为卷积神经网络模型训练过程中的损失函数和准确率变化图,可从中看出,训练集的损失函数不断下降,测试集的损失函数趋于不变,网络出现了过拟合的现象,这可能是由于实验为缩短训练时间并未使用CIFAR-10数据集的全部图片,而只是选取其中的10000张图片导致数据集过少,从而导致过拟合。经过训练,卷积神经网络的分类精度可达60.2%。
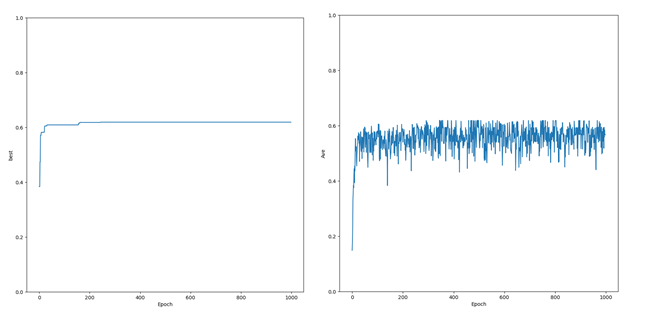
图 6 GA训练平均适应值及最优个体适应值变化图
图6为遗传算法训练过程中的平均适应值及最优个体适应值变化图,经过1000代训练后,最佳个体适应值为0.619,即以此个体解码后的参数为支持向量机的参数,支持向量机的准确率为61.9%
综上所述,遗传算法可以给SVM找出合适的参数,CNN-SVM的方法在此实验中可以将CNN的分类精度提高约1.7个百分点。
附完整代码:
CNN:
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
Normalize pixel values to be between 0 and 1
train_images, test_images = train_images / 255.0, test_images / 255.0
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i])
# The CIFAR labels happen to be arrays,
# which is why you need the extra index
plt.xlabel(class_names[train_labels[i][0]])
plt.show()
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10))
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
plt.show()
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
model.save('saved_model/MyCNNmodel')
train_features=[]
test_features=[]
GA对SVM寻优:
!/usr/bin/env Python
# coding=utf-8
import random
import math
import numpy as np
import matplotlib.pyplot as plt
import sklearn.svm as vm
from tensorflow.keras import datasets
from sklearn.metrics import accuracy_score
import tensorflow as tf
my_model=tf.keras.models.load_model('saved_model/MyCNNmodel')
sub_model=tf.keras.Model(inputs=my_model.input,
outputs=my_model.get_layer(index=6).output)
#输出1024维的特征向量
#加载数据集
(train_images,train_labels),(test_images,test_labels)=datasets.cifar10.load_data()
Normalize pixel values to be between 0 and 1
train_images, test_images = train_images / 255.0, test_images / 255.0
#data['x_train']=sub_model.predict(data['x_train'])
print(1)
train_images=train_images[0:10000]
train_labels=train_labels[0:10000]
test_images=test_images[0:1000]
test_labels=test_labels[0:1000]
train_features=[]
test_features=[]
train_features=sub_model.predict(train_images)
print(tf.shape(train_features.shape))
test_features=sub_model.predict(test_images)
train_x=[]
test_x=[]
print(1)
for pic in train_features:
for i in range(len(pic)):
if pic[i]!=0:
pic[i]=1
#else:
# pic[i]=0
train_x.append(pic)
for pic in test_features:
for i in range(len(pic)):
if pic[i]!=0:
pic[i]=1
#else:
# pic[i]=0
test_x.append(pic)
print(1)
def SVMfitness(cc,g):#计算例子适应度
#vv=vm.SVC(kernel="rbf")
vv=vm.SVC(kernel="rbf",gamma=g,C=cc)
#vv = vm.SVC(c=cc,kernel='rbf',gamma=g)
vv.fit(train_x, train_labels)
vvpredict = vv.predict((test_x))
single_value=accuracy_score(vvpredict, test_labels)
return single_value
#计算适应度
def calcfit(gene):
a=SVMfitness(gene[0],gene[1])
return a
#每个个体的类,方便根据基因计算适应度
class Person:
def __init__(self,gene):
self.gene=gene
self.fit=calcfit(gene)
class Group:
def __init__(self):
self.GroupSize=50 #种群规模
self.GeneSize=2 #基因数量
self.initGroup()
self.upDate()
#初始化种群,随机生成若干个体
def initGroup(self):
self.group=[]
i=0
while(i<self.groupsize): i+="1" #gene如果在for以外生成只会shuffle一次 gene="[]" for j in range(2): a="np.random.randint(0," 50) while gene.append(a) tmpperson="Person(gene)" self.group.append(tmpperson) #获取种群中适应度最高的个体 def getbest(self): bestfit="self.group[0].fit" best="self.group[0]" person self.group: if(person.fit>bestFit):
bestFit=person.fit
best=person
return best
#计算种群中所有个体的平均距离
def getAvg(self):
sum=0
for p in self.group:
sum+=1/p.fit
return sum/len(self.group)
#根据适应度,使用轮盘赌返回一个个体,用于遗传交叉
def getOne(self):
#section的简称,区间
sec=[0]
sumsec=0
for person in self.group:
sumsec+=person.fit
sec.append(sumsec)
p=random.random()*sumsec
for i in range(len(sec)):
if(p>sec[i] and p<sec[i+1]): #这里注意区间是比个体多一个0的 return self.group[i] #更新种群相关信息 def update(self): self.best="self.getBest()" #遗传算法的类,定义了遗传、交叉、变异等操作 class ga: __init__(self): self.group="Group()" self.pcross="0.35" #交叉率 self.pchange="0.1" #变异率 self.gen="1" #代数 #变异操作 change(self,gene): gee="[]" for i in range(2): a="np.random.randint(0," 50) while 0: gee.append(a) #交叉操作 cross(self,p1,p2): newgene="[]" newgene.append(p1.gene[0]) newgene.append(p2.gene[1]) #获取下一代 nextgen(self): self.gen+="1" #nextgen代表下一代的所有基因 nextgen="[]" #将最优秀的基因直接传递给下一代 nextgen.append(self.group.getbest().gene[:]) while(len(nextgen)<self.group.groupsize): pchange="random.random()" pcross="random.random()" p1="self.group.getOne()" if(pcross<self.pcross): p2="self.group.getOne()" else: if(pchange<self.pchange): nextgen.append(newgene) self.group.group="[]" gene nextgen: self.group.group.append(person(gene)) self.group.update() #打印当前种群的最优个体信息 showbest(self): print("第{}代\t当前最优{}\t当前平均{}\t".format(self.gen,1 self.group.getbest().fit,self.group.getavg())) #n代表代数,遗传算法的入口 run(self,n): while(i<n): self.nextgen() self.showbest() i+="1" ga="GA()" ga.run(3000) print("进行3000代后最优解:",1 ga.group.getbest().fit) #下面是进行若干次重复实验的代码 # res="[]" range(1,11): print("第{}次实验最优解{}".format(i,1 ga.group.getbest().fit)) res.append(1 sum="0" item res: sum+="item" print("10次实验的平均距离",sum len(res))< code></sec[i+1]):></self.groupsize):>
test:
import tensorflow as tf
import numpy as np
from tensorflow.keras import datasets, layers, models
import sklearn.svm as vm
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
import os
my_model=tf.keras.models.load_model('saved_model/MyCNNmodel')
sub_model=tf.keras.Model(inputs=my_model.input,
outputs=my_model.get_layer(index=6).output)
#输出1024维的特征向量
#加载数据集
(train_images,train_labels),(test_images,test_labels)=datasets.cifar10.load_data()
train_images=np.array(train_images)
test_images=np.array(test_images)
train_labels=np.array(train_labels)
train_labels=train_labels.reshape((-1,1))
test_labels=np.array(test_labels)
test_labels=test_labels.reshape((-1,1))
#data['x_train']=sub_model.predict(data['x_train'])
print(1)
train_features=[]
test_features=[]
train_features=sub_model.predict(train_images)
print(train_features)
test_features=sub_model.predict(test_images)
train_x=[]
test_x=[]
print(1)
for pic in train_features:
for i in range(len(pic)):
if pic[i]!=0:
pic[i]=1
#else:
# pic[i]=0
train_x.append(pic)
for pic in test_features:
for i in range(len(pic)):
if pic[i]!=0:
pic[i]=1
#else:
# pic[i]=0
test_x.append(pic)
print(1)
#vv=vm.SVC(kernel="rbf",gamma=g,C=cc)
vv = vm.SVC(kernel='rbf')
vv.fit(train_x, train_labels)
vvpredict = vv.predict((test_x))
single_value=accuracy_score(vvpredict, test_labels)
print(single_value)
Original: https://blog.csdn.net/qq_42935076/article/details/122411599
Author: deeplearning小学生
Title: 基于CNN-SVM-GA的图像分类技术
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/662432/
转载文章受原作者版权保护。转载请注明原作者出处!