

在计算机视觉图像分类中,在实践过程中会经常遇到样本数量很少的情况。很少的样本可能是几百张图像或者几万张图像,在小样本上如何训练一个泛化能力强的模型是一个很值得探讨的问题,中间有不少过程需要我们进行优化。在这里使用通用的猫狗样本进行二分类模型的训练,在训练的过程中来研究怎样采取一些措施提高模型预测的准确率。
1 训练样本的下载
猫狗的分类样本采用kaggle上的猫狗样本,网址为:
https://www.kaggle.com/chetankv/dogs-cats-images

如果从官网上不方便下载该样本集,可以在我的csdn上资源里下载:猫狗样本集下载地址。
该数据集包含了4000张猫、狗的训练样本,1000张猫、狗的测试样本。
猫狗图片如下所示:
我们从训练样本中training_set目录下各取出800张猫和狗的图片移动到新建的验证集validation_set目录下的cats目录以及dogs目录,作为验证集。

; 2 猫狗二分类模型的训练
训练代码如下所示:
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from PIL import Image
from tensorflow.keras import layers
from tensorflow.keras import models
from tensorflow.keras import optimizers
import matplotlib.pyplot as plt
'''
ImageDataGenerator可完成读取图像数据
读取图像文件
将jpeg图像解码为RGB像素网络
将这些像素转换到为浮点型张量并缩放到0~1之间
'''
train_dir='./dataset/training_set/'
validation_dir='./dataset/validation_set/'
test_dir='./dataset/test_set/'
train_datagen=ImageDataGenerator(rescale=1./255)
train_generator=train_datagen.flow_from_directory(
directory=train_dir,
target_size=(150,150),
class_mode='binary',
batch_size=20
)
validation_datagen=ImageDataGenerator(rescale=1./255)
validation_generator=train_datagen.flow_from_directory(
directory=validation_dir,
target_size=(150,150),
class_mode='binary',
batch_size=20
)
test_datagen=ImageDataGenerator(rescale=1./255)
test_generator=train_datagen.flow_from_directory(
directory=test_dir,
target_size=(150,150),
class_mode='binary',
batch_size=20
)
if __name__=='__main__':
data,lables=next(train_generator)
print(data.shape)
print(lables.shape)
img_test=Image.fromarray((255*data[0]).astype('uint8'))
model=models.Sequential()
model.add(layers.Conv2D(filters=32,kernel_size=(3,3),activation='relu',input_shape=(150,150,3)))
model.add(layers.MaxPooling2D(pool_size=(2,2)))
model.add(layers.Conv2D(filters=64,kernel_size=(3,3),activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2,2)))
model.add(layers.Conv2D(filters=128,kernel_size=(3,3),activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2,2)))
model.add(layers.Conv2D(filters=128,kernel_size=(3,3),activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2,2)))
model.add(layers.Flatten())
model.add(layers.Dense(units=512,activation='relu'))
model.add(layers.Dense(units=1,activation='sigmoid'))
model.compile(optimizer=optimizers.RMSprop(learning_rate=1e-4),
loss='binary_crossentropy',
metrics=['acc'])
model.summary()
history=model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50
)
test_eval=model.evaluate_generator(test_generator)
print(test_eval)
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
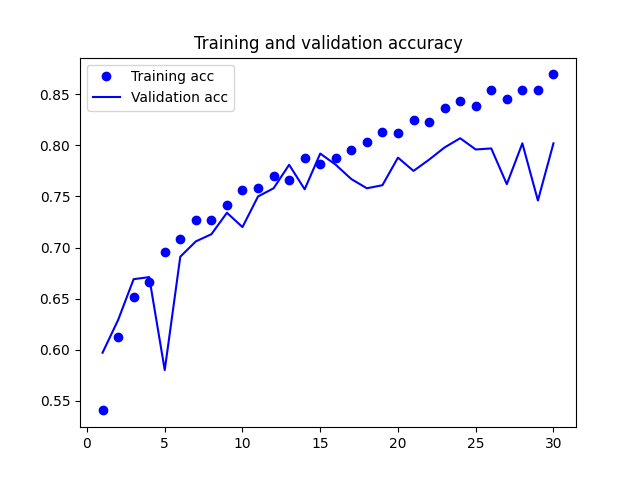
训练的准确率图像如下所示:
训练的损失函数变化图像如下所示:
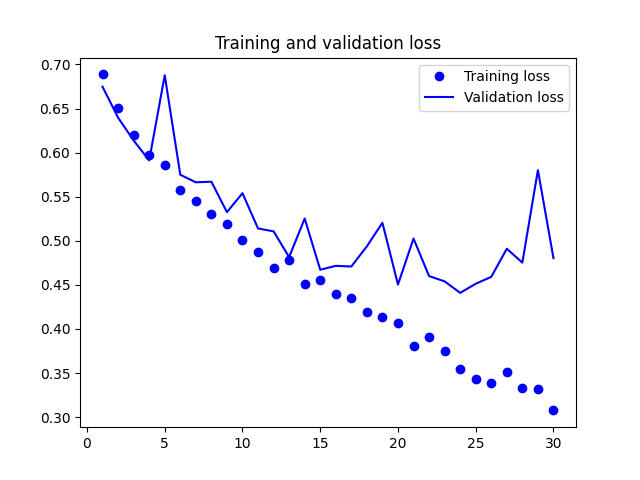
从上图可以看到,模型在训练15批次后,验证集的准确率不再增加,此后的训练模型发生了过拟合,并且在测试集·的准确率为79.15%。
在下一篇博客里将采用一些方法来提高识别率。
Original: https://blog.csdn.net/qq_37781464/article/details/122836936
Author: Keras深度学习
Title: keras深度学习之猫狗分类一
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/662404/
转载文章受原作者版权保护。转载请注明原作者出处!