

1、作用
聚类分析是一种基于中心的聚类算法(K 均值聚类),通过迭代,将样本分到 K 个类中,使得每个样本与其所属类的中心或均值的距离之和最小。与分层聚类等按照字段进行聚类的算法不同的是,快速聚类分析是按照样本进行聚类。
2、输入输出描述
输入:1 个或一个以上的定类变量(独热编码非必选)或者定量变量,预先设定类别个数。
输出:根据预先设定的类别个数,划分为其设定的类别。
3、案例示例
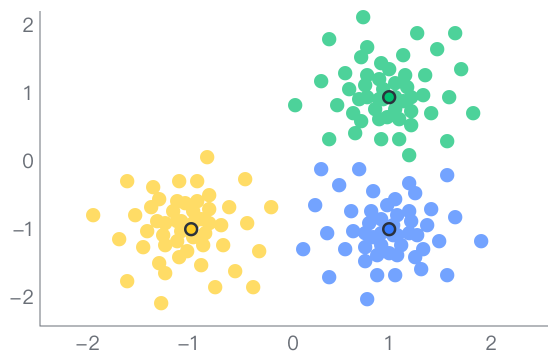
根据调研用户的收入、年龄、学历等变量进行聚类,分为高质量人类,精英人士与普通人3个类别。

4、matlab
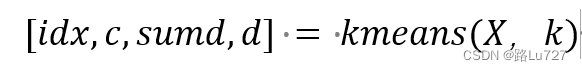
描述:
输入:X:原始数据矩阵;k:聚类数量
输出:idx:每个点的聚类标号;c:k个聚类质心位置;sumd:类间所有点与该类质心点距离之和;d:每个点与所有质心的距离
5、建模步骤
K-Means 算法是一种无监督学习,同时也是基于划分的聚类算法,一般用欧式距离作为衡量数据对象间相似度的指标,相似度与数据对象间的距离成反比,相似度越大,距离越小。算法需要预先指定初始聚类数目 k 以及 k 个初始聚类中心,根据数据对象与聚类中心之间的相似度,不断更新聚类中心的位置,不断降低类簇的误差平方和(Sum of Squared Error,SSE),当 SSE 不再变化或目标函数收敛时,聚类结束,得到最终结果。
其核心思想是:
首先从数据集中随机选取 k 个初始聚类中心 Ci(1 ≤ i ≤ k) ,计算其余数据对象与聚类中心 Ci 的欧氏距离,找出离目标数据对象最近的聚类中心 Ci ,并将数据对象分配到聚类中心 Ci 所对应的簇中。然后计算每个簇中数据对象的平均值作为新的聚类中心,进行下一次迭代,直到聚类中心不再变化或达到最大的迭代次数停止。
空间中数据对象与聚类中心间的欧式距离计算公式为:
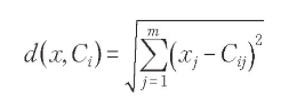
其中,x 为数据对象,Ci 为第 i 个聚类中心,m 为数据对象的维度,xj,Cij 为 x 和 Ci 的第 j 个属性值。
整个数据集的误差平方和 SSE 计算公式为:
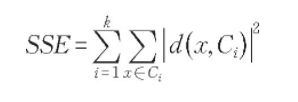
其中,SSE 的大小表示聚类结果的好坏,k 为簇的个数。
Original: https://blog.csdn.net/weixin_60466670/article/details/125765856
Author: 路Lu727
Title: 分类——K-Means聚类分析
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/662321/
转载文章受原作者版权保护。转载请注明原作者出处!