

1.数据集介绍
1.1 概念
机器学习所用数据集一般分为训练集、验证集、测试集。
- 训练集:用于训练的样本集合,主要用来训练神经网络中的参数。
- 验证集:用于验证模型性能的样本集合.不同神经网络在训练集上训练结束后,通过验证集来比较判断各个模型的性能.这里的不同模型主要是指对应不同超参数的神经网络,也可以指完全不同结构的神经网络。
- 测试集:对于训练完成的神经网络,测试集用于检验最终选择最优的模型性能。
打个比方,从前有个本科生(机器学习)刚开始啥也不会,但是他想考上研究生,于是他就通过大量刷题(训练集)来学习新知识,刷的题都是带有答案(训练集label)的。每做一题对一下答案(label),就这样不断地学习新知识,当他学习一轮之后,他想知道自己能考多少分,于是他给自己来了一个模拟考试(验证集),再对一下答案(验证集label),然后得知自己的得分(评估指标),发现自己得分不是很高,平时刷题表现好,一到模拟考试就表现不好(过拟合)。于是他调整自己的学习方式(调参),…就这样通过几轮复习之后他走上了考场开始考试(测试集),得分很高,终于考上了研究生。
1.2 数据集结构
常见的数据集结构
Dataset/
train/
class1/
a1.jpg
a2.jpg
a3.jpg
...
class2/
b1.jpg
b2.jpg
b3.jpg
...
class3/
c1.jpg
c2.jpg
c3.jpg
...
val/
test/
Dataset/
train/
1.jpg
2.jpg
3.jpg
...
val/
test/
Dataset/
1.jpg
2.jpg
3.jpg
...
- 数据集划分及生成label
2.1 结构一
如果是第一种结构的数据集,它已经根据训练、验证、测试和类别划分好了数据集,只需生成label即可。
根据二级目录(class)生成label,可写入csv文件或者txt文件(实际使用,用txt文件就好,csv自己写着玩玩的)。
import os
import os.path
def write_txt(content, filename, mode='w'):
"""保存txt数据
:param content:需要保存的数据,type->list
:param filename:文件名
"""
with open(filename, mode) as f:
for line in content:
str_line = ""
for col, data in enumerate(line):
if not col == len(line) - 1:
str_line = str_line + str(data) + " "
else:
str_line = str_line + str(data) + "\n"
f.write(str_line)
def get_files_list(dir):
'''
实现遍历dir目录下,所有文件(包含子文件夹的文件)
:param dir:指定文件夹目录
:return:包含所有文件的列表->list
'''
files_list = []
for parent, dirnames, filenames in os.walk(dir):
for filename in filenames:
print("parent is: " + parent)
print("filename is: " + filename)
print(os.path.join(parent, filename).replace('\\','/'))
curr_file = parent.split(os.sep)[-1]
if curr_file == "class1":
labels = 0
elif curr_file == "class1":
labels = 1
elif curr_file == "class1":
labels = 2
dir_path = parent.replace('\\', '/').split('/')[-2]
curr_file = os.path.join(dir_path, curr_file)
files_list.append([os.path.join(curr_file, filename).replace('\\','/'), labels])
path = "%s" % os.path.join(curr_file, filename).replace('\\','/')
label = "%d" % labels
list = [path, label]
data = pd.DataFrame([list])
if dir == './Dataset/train':
data.to_csv("./Dataset/train.csv", mode='a', header=False, index=False)
elif dir == './Dataset/val':
data.to_csv("./Dataset/val.csv", mode='a', header=False, index=False)
return files_list
if __name__ == '__main__':
import pandas as pd
df = pd.DataFrame(columns=['path', 'label'])
df.to_csv("./Dataset/train.csv", index=False)
df2 = pd.DataFrame(columns=['path', 'label'])
df2.to_csv("./Dataset/val.csv", index=False)
train_dir = './Dataset/train'
train_txt = './Dataset/train.txt'
train_data = get_files_list(train_dir)
write_txt(train_data, train_txt, mode='w')
val_dir = './Dataset/val'
val_txt = './Dataset/val.txt'
val_data = get_files_list(val_dir)
write_txt(val_data, val_txt, mode='w')
2.2 结构二
这种结构也划分好了数据集,但无法通过类名生成label了,数据集一般都会自带带有label的文件,直接葱里面提取文件名(路径)和label即可。
2.3 结构三
这种数据及所有图片都放在一个文件夹,一般也自带一个带有label的文件,训练集验证集测试集需要自己去划分。
下面举个栗子(ODIR-5k数据集,包含6398个图)对数据集进行划分和label生成:
6398张图片全放在第一个文件夹,full_df_csv是label数据

preprocessed_images文件夹
full_df_csv文件label部分(共8个不同的label)

新建一个项目文件夹,将full_df_csv文件放进去
- 提取csv文件的图片文件名和label信息保存到txt文件
label_extraction.py
import pandas as pd
def csv_to_txt(csv_path, txt_path):
data = pd.read_csv(csv_path, encoding='utf-8')
with open(txt_path, 'w', encoding='utf-8') as f:
for line in data.values:
file_name = str(line[18])
if str(line[16]) == "['N']":
labels = 0
elif str(line[16]) == "['D']":
labels = 1
elif str(line[16]) == "['G']":
labels = 2
elif str(line[16]) == "['C']":
labels = 3
elif str(line[16]) == "['A']":
labels = 4
elif str(line[16]) == "['H']":
labels = 5
elif str(line[16]) == "['M']":
labels = 6
elif str(line[16]) == "['O']":
labels = 7
labels = "%s" % labels
f.write(file_name+ ' ' + labels + '\n')
if __name__ == '__main__':
csv_to_txt('./full_df.csv', './label.txt')
生成label.txt
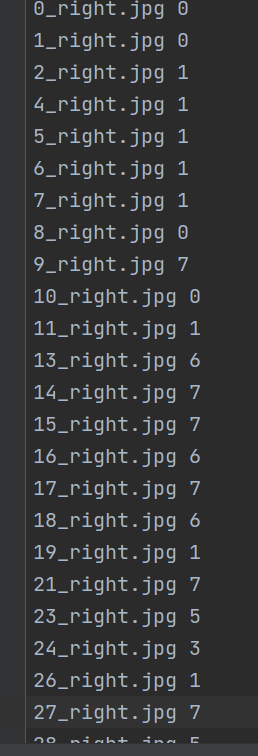
如果不需要那么多数据,只需要提取想要的label的图片(比如只要label为N和D的),可以这样设置:
def csv_to_txt(csv_path, txt_path):
data = pd.read_csv(csv_path, encoding='utf-8')
with open(txt_path, 'w', encoding='utf-8') as f:
for line in data.values:
file_name = str(line[18])
if str(line[16]) == "['N']":
labels = 0
elif str(line[16]) == "['D']":
labels = 1
elif str(line[16]) == "['G']":
labels = -1
elif str(line[16]) == "['C']":
labels = -1
elif str(line[16]) == "['A']":
labels = -1
elif str(line[16]) == "['H']":
labels = -1
elif str(line[16]) == "['M']":
labels = -1
elif str(line[16]) == "['O']":
labels = -1
if labels >= 0:
labels = "%s" % labels
f.write(file_name+ ' ' + labels + '\n')
if __name__ == '__main__':
csv_to_txt('./full_df.csv', './label.txt')
- 将label.txt打乱顺序并写入到新的txt文件
disrupt order.py
import random
def ReadFileDatas(original_filename):
FileNameList = []
file = open(original_filename, 'r+', encoding='utf-8')
for line in file:
FileNameList.append(line)
print('数据集总量:', len(FileNameList))
file.close()
return FileNameList
def WriteDatasToFile(listInfo, new_filename):
f = open(new_filename, mode='w', encoding='utf-8')
for idx in range(len(listInfo)):
str = listInfo[idx]
f.write(str)
f.close()
print('写入 %s 文件成功.' % new_filename)
if __name__ == "__main__":
listFileInfo = ReadFileDatas('./label.txt')
random.shuffle(listFileInfo)
WriteDatasToFile(listFileInfo,'./new_data.txt')
new_data.txt
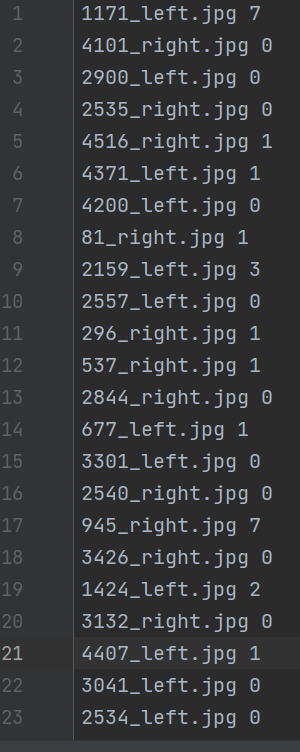
- 随机划分数据集(train:val:test=7:2:1)
divide.py
L_train = []
L_val = []
L_test = []
def TrainValTestFile(new_filename):
file_divide = open(new_filename, 'r', encoding='utf-8')
lines = file_divide.readlines()
i = 0
j = len(lines)
for line in lines:
if i < (j *0.7):
i += 1
L_train.append(line)
elif i < (j*0.9):
i += 1
L_val.append(line)
elif i < j:
i += 1
L_test.append(line)
print("总数据量:%d , 此时创建train, val, test数据集" % i)
return L_train, L_val, L_test
def text_save(filename, data):
f = open(filename, 'w', encoding='utf-8')
for i in range(len(data)):
f.write(data[i])
f.close()
print("保存数据集(路径)成功:%s" % filename)
if __name__ == "__main__":
TrainValTestFile('./new_data.txt')
text_save('./t_train.txt', L_train)
text_save('./t_val.txt', L_val)
text_save('./t_test.txt', L_test)
按7:2:1划分好后,t_train.txt有4475条数据,t_val.txt有1278条数据,t_test.txt有639条数据
其中:t_train.txt
4.接下来按t_train.txt、t_val.txt、t_test.txt里的图片名称,给preprocessed_images文件夹里的图片分别复制到对应的文件夹。
(1)先分别读取t_train.txt、t_val.txt、t_test.txt的图片名并保存到相应txt文件
readpath.py
def write_txt(content, filename, mode='w'):
"""保存txt数据
:param content:需要保存的数据,type->list
:param filename:文件名
"""
with open(filename, mode) as f:
for line in content:
str_line = ""
for col, data in enumerate(line):
if not col == len(line) - 1:
str_line = str_line + str(data)
else:
str_line = str_line + str(data) + "\n"
f.write(str_line)
def get_data(txt_path):
fh = open(txt_path, 'r', encoding='utf-8')
lines = fh.readlines()
data = []
for line in lines:
line = line.strip('\n')
line = line.rstrip()
words = line.split()
imgs_path = words[0]
print(imgs_path)
data.append(imgs_path)
return data
if __name__ == '__main__':
data_train = get_data('./t_train.txt')
write_txt(data_train, './img_path_train.txt', mode='w')
data_val = get_data('./t_val.txt')
write_txt(data_val, './img_path_val.txt', mode='w')
data_test = get_data('./t_test.txt')
write_txt(data_test, './img_path_test.txt', mode='w')
其中img_path_train.txt
(2)将前面生成的img_path_train.txt、img_path_val.txt、img_path_test.txt文件也一起放到preprocessed_images文件夹

(3)复制文件
copyfile.py
import shutil
import os
def copy(txt_pth,save_path):
with open(txt_pth, 'r', encoding='utf-8') as fh:
savepath = save_path
lines = fh.readlines()
for line in lines:
img_name = line.replace("\n", "")
srcpath = './' + img_name
print(srcpath)
shutil.copy(srcpath, savepath)
if __name__ == '__main__':
label = ["train", "val", "test"]
for i in label:
os.mkdir(i)
train_txt_path = './img_path_train.txt'
train_save_path = './train'
copy(train_txt_path, train_save_path)
print("copy trainset successfully!")
val_txt_path = './img_path_val.txt'
val_save_path = './val'
copy(val_txt_path, val_save_path)
print("copy valset successfully!")
test_txt_path = './img_path_test.txt'
test_save_path = './test'
copy(test_txt_path, test_save_path)
print("copy testset successfully!")
将copyfile.py文件也放到preprocessed_images文件夹。
(4)在preprocessed_images目录打开命令行窗口,直接运行copyfile.py即可。会自动创建train、val、test文件夹,并将图片分别复制到相关文件夹。

之后就可以看到图片已经按文件名复制到相应文件夹了,
train效果:
(5)文件已经按训练集、验证集、测试集划分好了,接下来可以剪切放到Dataset目录
我们可以给他们创建包含图片路径和label的txt文件
回到divide.py改一部分就行
import os
import random
L_train = []
L_val = []
L_test = []
def TrainValTestFile(new_filename):
file_divide = open(new_filename, 'r', encoding='utf-8')
lines = file_divide.readlines()
i = 0
j = len(lines)
for line in lines:
if i < (j *0.7):
i += 1
line = './Dataset/train/'+line
L_train.append(line)
elif i < (j*0.9):
i += 1
line = './Dataset/val/' + line
L_val.append(line)
elif i < j:
i += 1
line = './Dataset/test/' + line
L_test.append(line)
print("总数据量:%d , 此时创建train, val, test数据集" % i)
return L_train, L_val, L_test
def text_save(filename, data):
f = open(filename, 'w', encoding='utf-8')
for i in range(len(data)):
f.write(data[i])
f.close()
print("保存数据集(路径)成功:%s" % filename)
if __name__ == "__main__":
TrainValTestFile('new_data.txt')
text_save('./train.txt', L_train)
text_save('./val.txt', L_val)
text_save('./test.txt', L_test)
只是在文件名前面加了路径,方便读取
train.txt
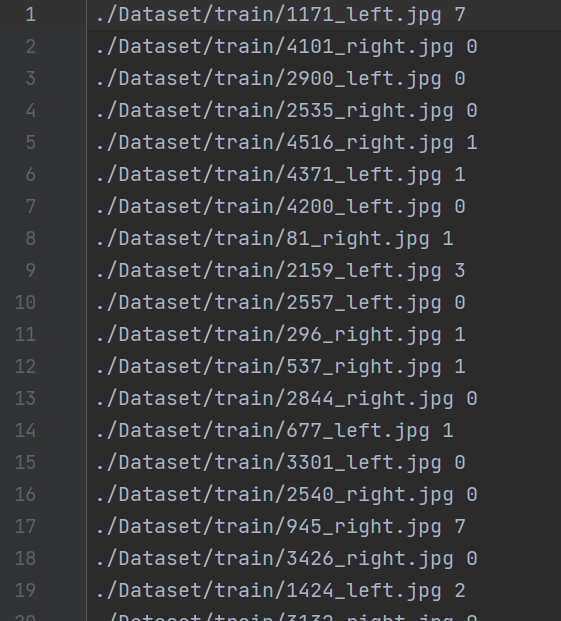
生成的train.txt、val.txt、test.txt放到Dataset文件夹、这样,Dataset就包括以下内容了
一个数据集划分完成。
-
数据集按label分类到不同文件夹
-
获取图片名和label
新建一个项目,将带有label信息的full_df.csv文件放进去,生成带label的txt文件
label_extraction.py
import pandas as pd
def csv_to_txt(csv_path, txt_path):
n = 0
d = 0
g = 0
c = 0
a = 0
h = 0
m = 0
o = 0
data = pd.read_csv(csv_path, encoding='utf-8')
with open(txt_path, 'w', encoding='utf-8') as f:
for line in data.values:
file_name = str(line[18])
if str(line[16]) == "['N']":
labels = 0
n = n +1
elif str(line[16]) == "['D']":
d = d + 1
labels = 1
elif str(line[16]) == "['G']":
labels = 2
g = g + 1
elif str(line[16]) == "['C']":
labels = 3
c = c +1
elif str(line[16]) == "['A']":
labels = 4
a = a + 1
elif str(line[16]) == "['H']":
labels = 5
h = h + 1
print("remove "+file_name)
elif str(line[16]) == "['M']":
labels = 6
m = m + 1
print("remove "+file_name)
elif str(line[16]) == "['O']":
labels = 7
o = o + 1
print("remove "+file_name)
if labels >= 0:
labels = "%s" % labels
f.write(file_name+ ' ' + labels + '\n')
print("N&C:%d"%n)
print("D:%d" % d)
print("G:%d" % g)
print("C:%d" % c)
print("A:%d" % a)
print("H:%d" % h)
print("M:%d" % m)
print("O:%d" % o)
sum = n+d+g+c+a+h+m+o
print("sum = %d"%sum)
return sum
if __name__ == '__main__':
sum = csv_to_txt('./full_df.csv', './label.txt')
label.txt
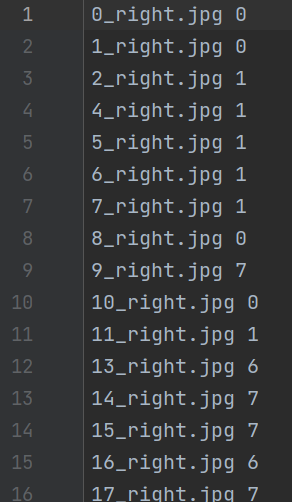
- 按label名给图片分类到不同文件夹
copy.py
import shutil
import os
def classify_data(txt_path,labels):
fh = open(txt_path, 'r', encoding='utf-8')
lines = fh.readlines()
for line in lines:
line = line.strip('\n')
line = line.rstrip()
words = line.split()
imgs_name = words[0]
srcfile = './'+imgs_name
imgs_label = int(words[1])
print(srcfile)
if imgs_label ==0:
shutil.copy(srcfile, './'+labels[0])
elif imgs_label ==1:
shutil.copy(srcfile, './'+labels[1])
elif imgs_label ==2:
shutil.copy(srcfile, './'+labels[2])
elif imgs_label ==3:
shutil.copy(srcfile, './'+labels[3])
elif imgs_label ==4:
shutil.copy(srcfile, './'+labels[4])
elif imgs_label ==5:
shutil.copy(srcfile, './'+labels[5])
elif imgs_label ==6:
shutil.copy(srcfile, './'+labels[6])
elif imgs_label ==7:
shutil.copy(srcfile, './'+labels[7])
print("Copy files Successfully!")
if __name__ == '__main__':
label = ["Normal(N)", "DR(D)", "Glaucoma(G)", "Cataract(C)", "AMD(A)", "Hypertension(H)", "Myopia(M)", "Others(O)"]
for i in label:
os.mkdir(i)
classify_data('./label.txt',label)
- 将label.txt文件和copy.py文件放进存放数据集的文件夹下面
- 打开命令行窗口,直接运行copy.py即可完成分类复制。
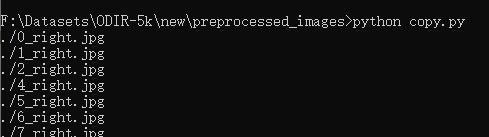
总结:以上都是以一个数据集为例的操作,不同的数据集会略有差异、其实都差不多稍微修改就好,这样可以制作自己想要的的数据集。
Original: https://blog.csdn.net/weixin_43760844/article/details/113944260
Author: 蠕动的爬虫
Title: 数据集划分、label生成及按label将图片分类到不同文件夹
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/662257/
转载文章受原作者版权保护。转载请注明原作者出处!