

贝叶斯判别规则是把某特征矢量(x) 落入某类集群的条件概率当成分类判别函数(概率判别函数),x落入某集群的条件概率最大的类为X的类别,这种判决规则就是贝叶斯判别规则。贝叶斯判别规则是以错分概率或风险最小为准则的判别规则。
这是百度百科的解释,乍一看,有点不清楚,其实就是用贝叶斯公式,判别他属于某一个类别的概率。
贝叶斯公式
P(A∩B) = P(A) P(B|A) = P(B) P(A|B)
在此公式为:
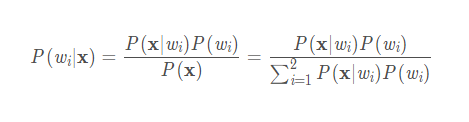

P(W|X)即为后验概率。
P(X|W),统计在W类中,发生X的概率,可以从概率密度函数理解
P(W)为先验概率,即不管其他的条件,统计出每个类发生的概率,可以是经验,也可以根据类别的个数比,比如去或者不去这个概率可能是一样的都为0.5,又比如人得癌症的概率,医学统计每一万个人中才会有一个人得癌症(好像是),所以根据经验,概率为万分之一,而不可能为二分之一
; 一般讨论
G1,G2为两个p维的总体,密度分别为f1(x),f2(x)
各总体的先验概率为p1=P(G1),p2=P(G2) ,p1+p2=1
样本X=(x1,x2,x3 …,xp),属于G1,G2的后验概率为:
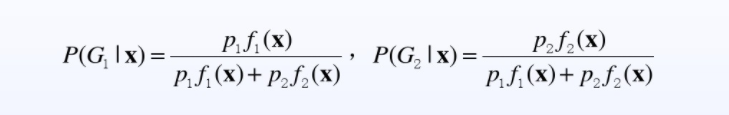
由于分母都是一样的,所以比较大小的话,只比较分子就可以。

两正态总体的贝叶斯判别
讨论两个分类的情况,并且这两个分类服从正态分布的总体
那么密度函数就为正态分布的概率密度函数
注意这里不是一维。两分类,对于每一个分类都可能有很多个特征,所以这里是协方差。
公式里p就是特征数,p如果等于1,那么协方差就变成方差,式子就是一维的概率密度函数。
图1
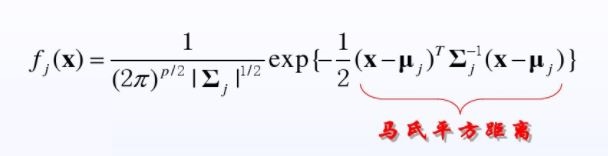
上面说过,分母一样,分子比较大小,那么前面的分子:
图2

注意大小相反,计算出来比较的是最小值。
对于两分类问题,比较d(x)的大小,那么当d1(x)和d2(x)相等的时候,就是他们的分离边界。
我们令d1(x) = d2(x)。
图3

- 由于这个式子左边是马氏距离,如果非黄色部分不看(假设协方差相等和先验概率相等,那么后面为常数),那么他就是距离判别分析。
- 假设两个类别的协方差相等,那么黄色部分的 二次型展开以后,d1和d2二次项系数相等,可以消去,这时候就是线性判别分析。只含有一次项。
- 如果两个类别的协方差不相等,那么左边黄色部分是一个 二次型,展开以后有二次项不能消去,那么就是非线性判别分析。
所以从贝叶斯角度理解这三种判别分析,也很简单明了。
问题:
那么首先就有个问题,判断协方差矩阵的相等问题,我搜了很多资料,但都没有把这个问题说的很详细,所以我也是一知半解,我们知道对于方差的检验有方差齐性检验,方法很多,但是对于协方差,包括在Python中都我都没有找到这种检验的方法。
但是在spss中有一个box’M检验,可以给出协方差等同性的概率值。这方面的资料的确太少。
在本文的最后会给出这种协方差检验的函数,至于为什么,我也是照着公式写的,不知道为什么。
下面分类讨论,主要讨论的是协方差相等时的算法,协方差不相等时,算法差不多,就不过于赘述
; 两总体协方差矩阵相同时
图4

因为d(x)与原判别大小相反,并且图2中有一个 -1/2的系数,
-1/2(d2(x)-d1(x)) = w2(x)-w1(x) 得到:
d2(x)-d1(x) =2( w1(x)-w2(x) )
而这个w(x)与原判别大小相同,所以我们用w(x)来计算,并且可以看出w(x)是线性的。
注意: 由于协方差相等,所以用联合协方差带入计算,减的时候很多都可以消去,所以可以转换成w(x),而协方差不相等的时候就不能转换,也不能用w(x)计算。之所以用w(x)计算,是因为可以计算斜率和截距比较方便,因为一眼就看出他是线性的。
公式中黄色之外的 ln|Σ| 是行列式的对数,因为协方差相等,所以减的时候消去了。
举个例子
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(font="Simhei")
sns.set_style("darkgrid")
from sklearn.datasets import make_classification
x,y = make_classification(n_samples=500,n_features=2,n_informative=1, n_redundant=0, n_classes=2, n_clusters_per_class=1)
plt.scatter(x[:,0],x[:,1],c=y,cmap=plt.cm.BrBG_r)
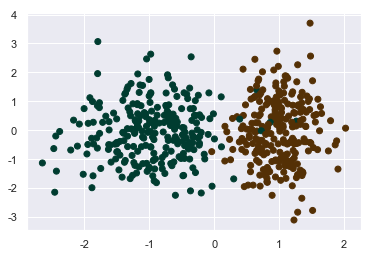
用函数生成两类随机的点,只有两个类别。但是他们太正规了,我们稍微旋转一下。
x1 = x.dot(np.array([[10,2],[1,2]]))
plt.scatter(x1[:,0],x1[:,1],c=y,cmap=plt.cm.BrBG)
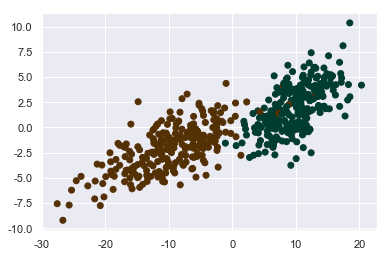
可以看出有很多的重合点,不用管它,现实里也不会有那么完美的数据。
这个分类是1和0,1是上面的绿色点,0是下面的灰色点。
arr1 = x1[y==1]
arr2 = x1[y==0]
n1 = arr1.shape[0]
n2 = arr2.shape[0]
arr1_mean = arr1.mean(axis=0)
arr2_mean = arr2.mean(axis=0)
s1 = np.cov(arr1,rowvar=False)
s2 = np.cov(arr2,rowvar=False)
s = ((n1-1)*s1 + (n2-1)*s2)/(n1+n2-2)
def pre(x):
C1_arr1 = np.array(arr1_mean).reshape(1,2).dot(np.linalg.inv(s)).dot(x.T)
C2_arr1 = np.array(arr1_mean).reshape(1,2).dot(np.linalg.inv(s)).dot(np.array(arr1_mean).reshape(2,1))
de1 = C1_arr1-1/2*C2_arr1 + np.log(0.5)
C1_arr2 = np.array(arr2_mean).reshape(1,2).dot(np.linalg.inv(s)).dot(x.T)
C2_arr2 = np.array(arr2_mean).reshape(1,2).dot(np.linalg.inv(s)).dot(np.array(arr2_mean).reshape(2,1))
de2 = C1_arr2-1/2*C2_arr2 + np.log(0.5)
pre = np.array(de1>de2,dtype=np.float32)
return pre.ravel()
对于这个公式其实代码中C1_arr1和C1_arr2中含有未知数,所以假定de1和de2相等的话,他们的差值就是系数。其他的就是截距项。
这样就可以算出他们的分离边界线性方程了。
用de1-de2
np.array(arr1_mean).reshape(1,2).dot(np.linalg.inv(s))-
np.array(arr2_mean).reshape(1,2).dot(np.linalg.inv(s))
array([[ 0.86513196, -0.50598163]])
-1/2*C2_arr1-(-1/2*C2_arr2)
array([[-0.15689298]])
最终方程为:0.86513196 * x1 + -0.50598163 * x2 + -0.15689298
x1为X轴,x2为Y轴,我们画出这个方程。
并计算面里所有点的分类情况
k1 = 0.86513196/0.50598163
xx,yy = np.meshgrid(np.linspace(-30,30,200),np.linspace(-30,30,200))
d = np.c_[xx.ravel(),yy.ravel()]
plt.figure(figsize=(12,9))
plt.scatter(d[:,0],d[:,1],c=lda.predict(d),cmap=plt.cm.Dark2,alpha=0.8)
a11 = np.linspace(-20,20,20)
a3 = k1*a11 - (0.15689298/0.50598163)
plt.plot(a11,a3,"r")
plt.scatter(x1[:,0],x1[:,1],c=y,cmap=plt.cm.Blues)
plt.show()
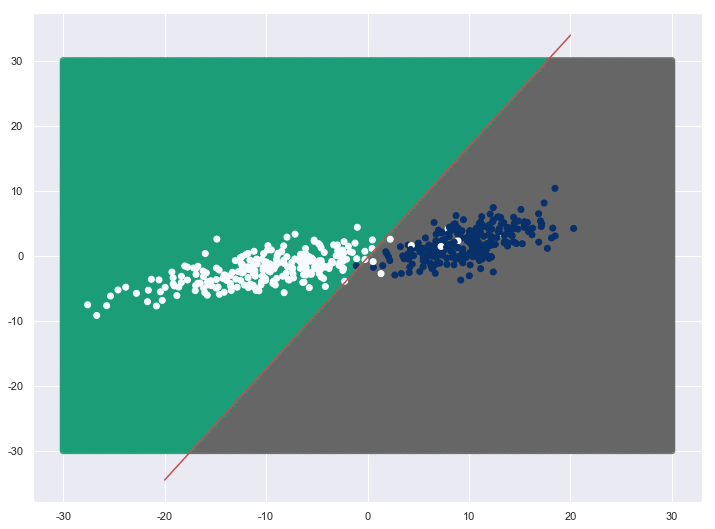
红色线即为分离边界。并是线性的。
方差相等时线性判别和Fisher线性判别的比较
上一篇文章说过Fisher判别分析,这个也是线性判别分析,那么他们有关系吗?
上一篇Fisher判别直接拿过来用,得到Fisher映射投影的直线方向
s1 = np.matrix(arr1 - arr1.mean(axis=0)).T.dot(arr1 - arr1.mean(axis=0))
s2 = np.matrix(arr2 - arr2.mean(axis=0)).T.dot(arr2 - arr2.mean(axis=0))
sw = s1+s2
mean_ = arr1.mean(axis=0) - arr2.mean(axis=0)
sb = np.array(mean_).reshape(-1,1).dot(np.array(mean_).reshape(1,-1))
np.linalg.eig(np.linalg.inv(sw).dot(sb))
(array([2.98412120e-02, 8.67361738e-19]),
matrix([[ 0.86320454, -0.19913463],
[-0.50485436, 0.97997214]]))
得到最大特征根的特征向量为 [0.86320454,-0.50485436](第一列的)
这个直线的斜率为-0.50485436/0.86320454 = -0.584860640329811
我们作图:
k2 = -0.50485436/0.86320454
a1 = np.linspace(-1.5,1.5,20)
a2 = k2*a1
a11 = np.linspace(-20,20,20)
a3 = k1*a11 - (0.15689298/0.50598163)
plt.figure(figsize=(9,9))
plt.scatter(x1[:,0],x1[:,1],c=y,cmap=plt.cm.BrBG)
plt.plot(a1,a2,'r')
plt.plot(a11,a3)
plt.ylim(-30,30)
plt.xlim(-30,30)
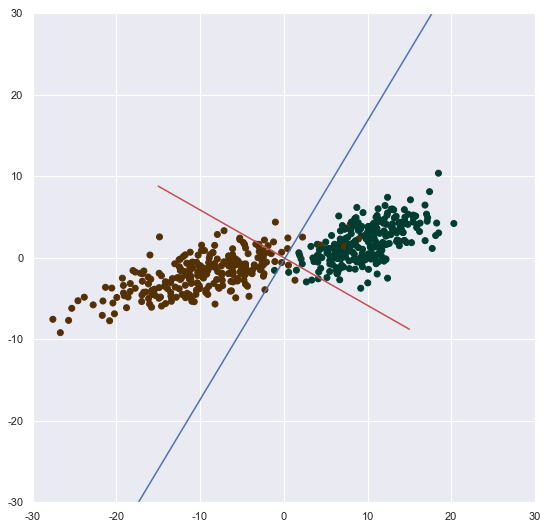
并且 k1 * k2 = 0.9999999
红色的线为Fisher投影的那条线,他和贝叶斯判别的线垂直,所以我们得到,贝叶斯判别的线,也就是Fisher线性判别的分界线,因为在这条线的两边,投影到红色直线上,都会被判为不同类别。
所以Fisher和贝叶斯这两个 线性判别,从不同的角度,相互印证,琴瑟和弦。当然前提是协方差齐性。
两总体协方差矩阵不同时
如上图3,贴过来用
协方差矩阵不相等,那么这个公式就是一个二次的,因为黄色部分的二次型,由于协方差不一样,系数消不掉。所以不是线性,而是曲线。
注意观察一下这个d(x)公式,x是要判断属于哪个类别的数据。
Σ 是 i 类别的协方差,μ 就是 i 类别下均值向量。
对于这个式子存在的问题,就是计算量,假设x只有一个数据n个特征,维度为(1,n)
那么最后得到的d的结果就是维度为(1,1)的一个值,所以每一个数据都会对应一个单一的结果,当然这是肯定的。
如果x是m个数据,维度是(m,n)呢?最后得到的 d(x) 就是(m,m)的矩阵,感兴趣可以计算一下,而我们只要m个数据,却得到一个方阵,其实我们要的m个数值,都在正对角线上,当数据量很大时,在做预测或者带入原始数据进行计算容易内存溢出,或者计算复杂,最后还要取对角线的值。所以比较麻烦。
那么解决办法就是改成普通的乘法即可。相同位置乘,最后求和。
def q_bda(x):
x1_2 = (np.array((x - arr2_mean).dot(np.linalg.inv(s2)))*(x - arr2_mean)).sum(axis=1) +
np.log(np.linalg.det(s2)) - 2*np.log(0.5)
x1_1 = (np.array((x - arr1_mean).dot(np.linalg.inv(s1)))*(x - arr1_mean)).sum(axis=1) +
np.log(np.linalg.det(s1)) - 2*np.log(0.5)
res = [(1 if x1_2[i]>x1_1[i] else 0)for i in range(x.shape[0])]
return res
plt.figure(figsize=(9,9))
plt.scatter(d[:,0],d[:,1],c=q_bda(d),alpha=0.5,cmap=plt.cm.BrBG)
a11 = np.linspace(-20,20,20)
a3 = k1*a11 - (0.15689298/0.50598163)
plt.plot(a11,a3)
plt.scatter(x1[:,0],x1[:,1],c=y,cmap=plt.cm.Dark2)
plt.show()
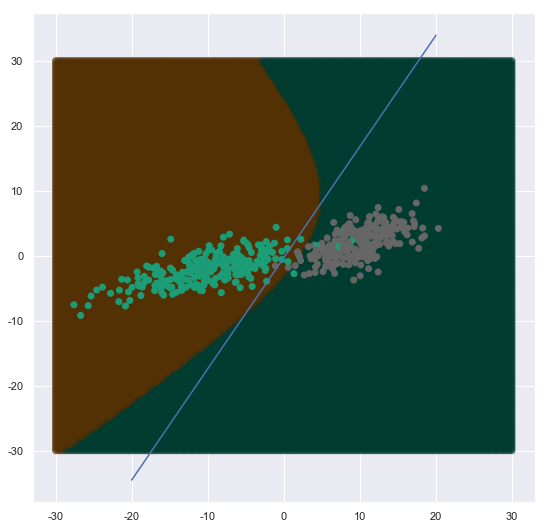
可以看到这里的判别,由于协方差不一样,所以他是曲线,不再是直线。
最后附一张图:
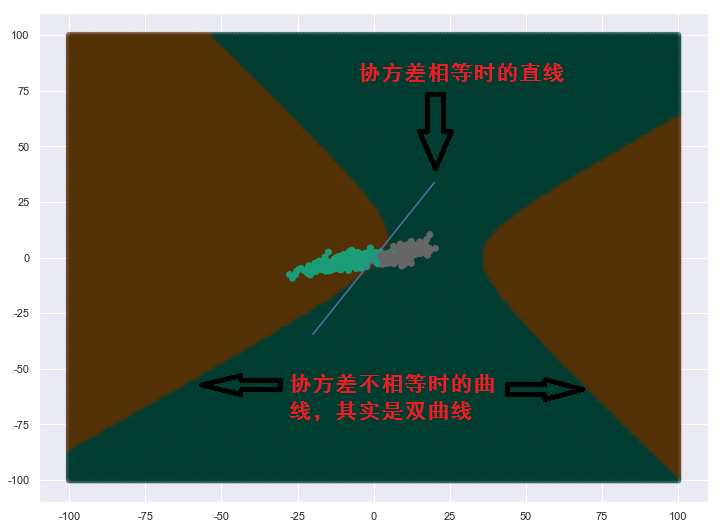
—– Python中现有的库
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis,
QuadraticDiscriminantAnalysis
LinearDiscriminantAnalysis,线性判别,可以得到上面的判别直线,默认是协方差相等。符合正态分布
QuadraticDiscriminantAnalysis,二次曲线判别,同样可以得到上面的曲线。最终结果都是一样的。
至于可以降到几维,最多降到类别数-1维,即n-1维。注意是类别数。
对于多类别来说,也是一样的计算方式,两类别的会了,多类别的也就会了。
文章写得太长,就没有看下去的兴趣了,也写累了,剩下的下一篇写。
判断两总体协方差的同质性检验
*扩展,判断多总体协方差同质性检验
Original: https://blog.csdn.net/PY_smallH/article/details/121684148
Author: PY_smallH
Title: 贝叶斯判别分析,Python代码分类讲解
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/662249/
转载文章受原作者版权保护。转载请注明原作者出处!