

用自建kinetics-skeleton行为识别数据集训练st-gcn网络流程记录
*
–
+
* 0. 准备工作
* 1. 下载/裁剪视频
* 2. 利用OpenPose提取骨骼点数据,制作kinetics-skeleton数据集
* 3. 训练st-gcn网络
* 4. 用自己训练的st-gcn网络跑demo,并可视化
0. 准备工作
首先就是把st-gcn网络的运行环境完全配置好了,并且可以正常进行行为识别
配置环境参考:
1. 复现旧版STGCN GPU版 (win10+openpose1.5.0)
2. 复现st-gcn(win10+openpose1.5.1+VS2017+cuda10+cudnn7.6.4)
对于准备自己的数据集,作者有提到具体的做法,如下所示
we first resized all videos to the resolution of 340x256 and converted the frame rate to 30 fps
we extracted skeletons from each frame in Kinetics by Openpose
rebuild the database by this command:
python tools/kinetics_gendata.py --data_path <path to kinetics-skeleton>
To train a new ST-GCN model, run
python main.py recognition -c config/st_gcn/<dataset>/train.yaml [--work_dir <work folder>]
</work></dataset></path>
1. 下载/裁剪视频
把准备好的视频裁剪成5-8s的视频,用剪映可能比较方便简单
再把裁剪好的视频,利用脚本左右镜像翻转一下,扩充一下数据集,脚本:
import os
import skvideo.io
import cv2
if __name__ == '__main__':
type_number = 12
typename_list = []
for type_index in range(type_number):
type_filename = typename_list[type_index]
originvideo_file = './mydata/裁剪/{}/'.format(type_filename)
videos_file_names = os.listdir(originvideo_file)
for file_name in videos_file_names:
video_path = '{}{}'.format(originvideo_file, file_name)
name_without_suffix = file_name.split('.')[0]
outvideo_path = '{}{}_mirror.mp4'.format(originvideo_file, name_without_suffix)
writer = skvideo.io.FFmpegWriter(outvideo_path,
outputdict={'-f': 'mp4', '-vcodec': 'libx264', '-r':'30'})
reader = skvideo.io.FFmpegReader(video_path)
for frame in reader.nextFrame():
frame_mirror = cv2.flip(frame, 1)
writer.writeFrame(frame_mirror)
writer.close()
print('{} mirror success'.format(file_name))
print('the video in {} are all mirrored'.format(type_filename))
print('-------------------------------------------------------')
2. 利用OpenPose提取骨骼点数据,制作kinetics-skeleton数据集
这一步主要的目的是把自己的视频数据集创建成kinetics-skeleton数据集一样的格式,格式大致如下图
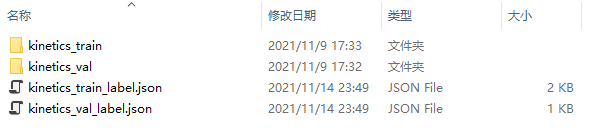

st-gcn作者有提供他们整理好并使用的kinetics-skeleton数据集,GoogleDrive,不过是谷歌网盘,需要翻墙才能下载。我这里上传到了百度网盘,提取码:sqpx,仅供参考
首先就是按照类别,把自己的视频分门别类,放在不同的文件夹下,然后主要通过两个脚本来提取数据。
第一个自己写的脚本的主要部分如下所示。这个脚本可以说是st-gcn源代码的./processor/demo_old.py中的一部分。主要先对视频数据进行resize至340×256的大小,30fps的帧率。然后调用openpose的进行骨骼点数据的检测和输出。我在其基础上加了一些批量处理各个文件夹下的视频数据的操作。
import os
import argparse
import json
import shutil
import numpy as np
import torch
import skvideo.io
from .io import IO
import tools
import tools.utils as utils
class PreProcess(IO):
"""
利用openpose提取自建数据集的骨骼点数据
"""
def start(self):
work_dir = './st-gcn-master'
type_number = 12
gongfu_filename_list = ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12']
for process_index in range(type_number):
gongfu_filename = gongfu_filename_list[process_index]
labelgongfu_name = 'xxx_{}'.format(process_index)
label_no = process_index
originvideo_file = './mydata/裁剪/{}/'.format(gongfu_filename)
resizedvideo_file = './mydata/裁剪/resized/{}/'.format(gongfu_filename)
videos_file_names = os.listdir(originvideo_file)
for file_name in videos_file_names:
video_path = '{}{}'.format(originvideo_file, file_name)
outvideo_path = '{}{}'.format(resizedvideo_file, file_name)
writer = skvideo.io.FFmpegWriter(outvideo_path,
outputdict={'-f': 'mp4', '-vcodec': 'libx264', '-s': '340x256', '-r':'30'})
reader = skvideo.io.FFmpegReader(video_path)
for frame in reader.nextFrame():
writer.writeFrame(frame)
writer.close()
print('{} resize success'.format(file_name))
resizedvideos_file_names = os.listdir(resizedvideo_file)
for file_name in resizedvideos_file_names:
outvideo_path = '{}{}'.format(resizedvideo_file, file_name)
openpose = '{}/OpenPoseDemo.exe'.format(self.arg.openpose)
video_name = file_name.split('.')[0]
output_snippets_dir = './mydata/裁剪/resized/snippets/{}'.format(video_name)
output_sequence_dir = './mydata/裁剪/resized/data'
output_sequence_path = '{}/{}.json'.format(output_sequence_dir, video_name)
label_name_path = '{}/resource/kinetics_skeleton/label_name_gongfu.txt'.format(work_dir)
with open(label_name_path) as f:
label_name = f.readlines()
label_name = [line.rstrip() for line in label_name]
openpose_args = dict(
video=outvideo_path,
write_json=output_snippets_dir,
display=0,
render_pose=0,
model_pose='COCO')
command_line = openpose + ' '
command_line += ' '.join(['--{} {}'.format(k, v) for k, v in openpose_args.items()])
shutil.rmtree(output_snippets_dir, ignore_errors=True)
os.makedirs(output_snippets_dir)
os.system(command_line)
video = utils.video.get_video_frames(outvideo_path)
height, width, _ = video[0].shape
video_info = utils.openpose.json_pack(
output_snippets_dir, video_name, width, height, labelgongfu_name, label_no)
if not os.path.exists(output_sequence_dir):
os.makedirs(output_sequence_dir)
with open(output_sequence_path, 'w') as outfile:
json.dump(video_info, outfile)
if len(video_info['data']) == 0:
print('{} Can not find pose estimation results.'.format(file_name))
return
else:
print('{} pose estimation complete.'.format(file_name))
之后就是把提取得到的骨骼点数据的json文件做一下整理,按照上面图中的kinetics-skeleton数据集的格式。kinetics_train文件夹保存训练数据,kinetics_val文件夹保存验证数据。文件夹外两个json文件主要包含了对应文件夹中所有的文件名称、行为标签名和行为标签索引。这两个json文件的生成脚本可以参考如下所示
import json
import os
if __name__ == '__main__':
train_json_path = './mydata/kinetics-skeleton/kinetics_train'
val_json_path = './mydata/kinetics-skeleton/kinetics_val'
output_train_json_path = './mydata/kinetics-skeleton/kinetics_train_label.json'
output_val_json_path = './mydata/kinetics-skeleton/kinetics_val_label.json'
train_json_names = os.listdir(train_json_path)
val_json_names = os.listdir(val_json_path)
train_label_json = dict()
val_label_json = dict()
for file_name in train_json_names:
name = file_name.split('.')[0]
json_file_path = '{}/{}'.format(train_json_path, file_name)
json_file = json.load(open(json_file_path))
file_label = dict()
if len(json_file['data']) == 0:
file_label['has_skeleton'] = False
else:
file_label['has_skeleton'] = True
file_label['label'] = json_file['label']
file_label['label_index'] = json_file['label_index']
train_label_json['{}'.format(name)] = file_label
print('{} success'.format(file_name))
with open(output_train_json_path, 'w') as outfile:
json.dump(train_label_json, outfile)
for file_name in val_json_names:
name = file_name.split('.')[0]
json_file_path = '{}/{}'.format(val_json_path, file_name)
json_file = json.load(open(json_file_path))
file_label = dict()
if len(json_file['data']) == 0:
file_label['has_skeleton'] = False
else:
file_label['has_skeleton'] = True
file_label['label'] = json_file['label']
file_label['label_index'] = json_file['label_index']
val_label_json['{}'.format(name)] = file_label
print('{} success'.format(file_name))
with open(output_val_json_path, 'w') as outfile:
json.dump(val_label_json, outfile)
3. 训练st-gcn网络
这一部分可以参考如下所示的博文中的 第三——第六 部分
4. 用自己训练的st-gcn网络跑demo,并可视化
这部分可以通过改写st-gcn源码中的./processor/demo_old.py脚本来实现。主要需要注意的是,记得修改读取的行为类别的标签文件名,以及修改对应的yaml配置文件中模型名称和类别数量等参数
Original: https://blog.csdn.net/Lujiahao98689/article/details/121447175
Author: trajectories
Title: 用自建kinetics-skeleton行为识别数据集训练st-gcn网络流程记录
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/662072/
转载文章受原作者版权保护。转载请注明原作者出处!