

目标:识别猫和狗
文章目录
*
– 一、猫狗数据集
– 二、训练环境
– 三、数据处理
– 四、建立模型
– 五、图像处理
– 六、训练模型
– 七、模型评估
– 八、可视化
– 九、保存模型
– 十、参考
– 十一、感悟
一、猫狗数据集
数据集下载:


搜索关注后,回复:猫狗数据集
训练数据集(每一张图片都有dog和cat标签):
测试集(图片没有标签):

; 二、训练环境
- kaggle
- tenslrflow2.6
三、数据处理
import numpy as np
import pandas as pd
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
如下:

导入相关模块:
import os
import zipfile
import pandas as pd
from tqdm import tqdm
import tensorflow as tf
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
from tensorflow.keras.optimizers import RMSprop
创建一个主文件夹:
work_path = './cats_and_dogs_filtered'
if not os.path.exists(work_path):
os.mkdir(work_path)
把训练集和测试集的图片解压到主文件夹下面:
local_zip = '../input/dogs-vs-cats/test1.zip'
zip_ref = zipfile.ZipFile(local_zip,'r')
zip_ref.extractall(work_path)
local_zip = '../input/dogs-vs-cats/train.zip'
zip_ref = zipfile.ZipFile(local_zip,'r')
zip_ref.extractall(work_path)
zip_ref.close()
把训练集的数据读出来:
train_path = os.path.join(work_path, 'train')
test_path = os.path.join(work_path, 'test1')
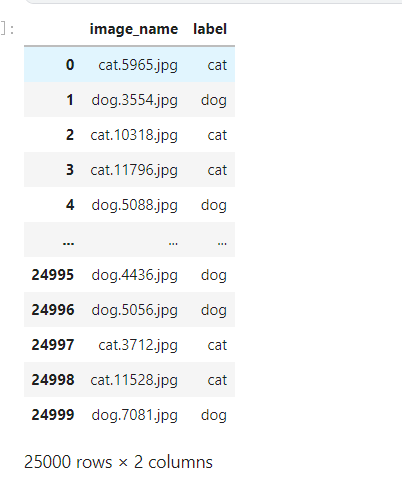
train_df = pd.DataFrame({'image_name':os.listdir(train_path)})
train_df['label'] =train_df['image_name'].apply(lambda x: x.split('.')[0])
train_df
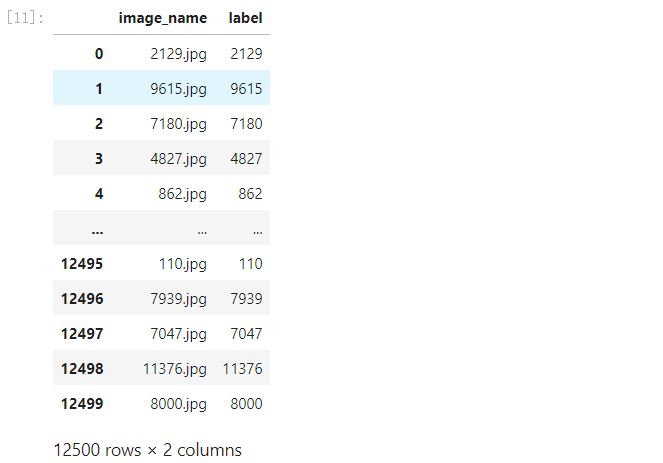
同理把测试集的数据读取出来:
test_df = pd.DataFrame({'image_name':os.listdir(test_path)})
test_df['label'] =test_df['image_name'].apply(lambda x: x.split('.')[0])
test_df
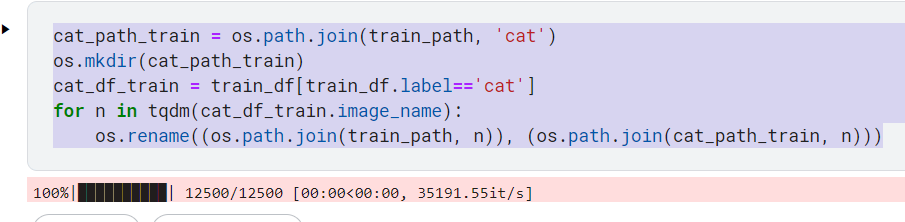
把所有狗的图片单独放在一个文件夹:
dog_path_train = os.path.join(train_path, 'dog')
os.mkdir(dog_path_train)
dog_df_train = train_df[train_df.label=='dog']
for n in tqdm(dog_df_train.image_name):
os.rename((os.path.join(train_path, n)), (os.path.join(dog_path_train, n)))

同理把猫的数据放在一个文件夹:
cat_path_train = os.path.join(train_path, 'cat')
os.mkdir(cat_path_train)
cat_df_train = train_df[train_df.label=='cat']
for n in tqdm(cat_df_train.image_name):
os.rename((os.path.join(train_path, n)), (os.path.join(cat_path_train, n)))
现在简单的检测一下目录的基本结构,当然这不是必须的部分:
base_dir = './cats_and_dogs_filtered'
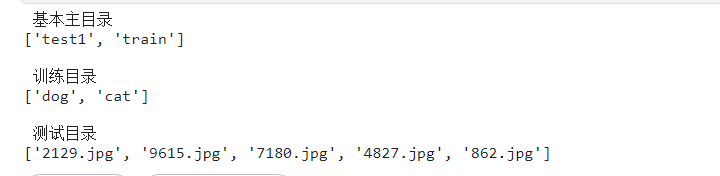
print(' 基本主目录')
print(os.listdir(base_dir))
print('\n 训练目录')
train_path = f'{base_dir}/train'
print(os.listdir(train_path))
print('\n 测试目录')
print(os.listdir(test_path)[:5])
如图:
再继续检查目录:
train_dir = os.path.join(base_dir,'train')
validation_dir = os.path.join(base_dir,'test1')
train_cats_dir = os.path.join(train_dir,'cat')
train_dogs_dir = os.path.join(train_dir,'dog')
train_cats_names = os.listdir(train_cats_dir)
train_dogs_names = os.listdir(train_dogs_dir)
print(train_cats_names[:5])
print(train_dogs_names[:5])
输出:
['cat.5965.jpg', 'cat.10318.jpg', 'cat.11796.jpg', 'cat.10908.jpg', 'cat.7301.jpg']
['dog.3554.jpg', 'dog.5088.jpg', 'dog.7240.jpg', 'dog.2206.jpg', 'dog.7740.jpg']
查看训练集测试集等数量:
print(f'训练集猫数量 = {len(train_cats_names)}')
print(f'训练集狗数量 = {len(train_dogs_names)}')
print(f'测试集猫和狗数量= {len(os.listdir(validation_dir))}')
输出:
训练集猫数量 = 12500
训练集狗数量 = 12500
测试集猫和狗数量= 12500
四、建立模型
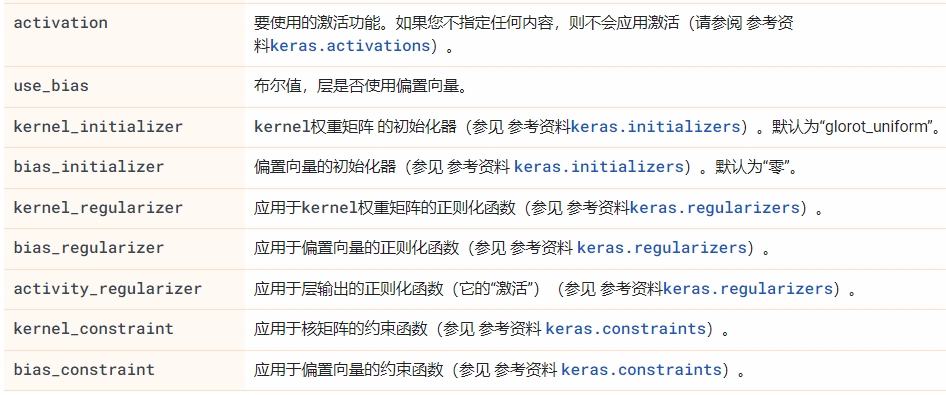
首先普及一点基本,卷积层语法如下:
tf.keras.layers.Conv2D(
filters,
kernel_size,
strides=(1, 1),
padding='valid',
data_format=None,
dilation_rate=(1, 1),
groups=1,
activation=None,
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs
)
相关参数如下:

池化层语法如下:
tf.keras.layers.MaxPool2D(
pool_size=(2, 2),
strides=None,
padding='valid',
data_format=None,
**kwargs
)
参数说明:

Flatten语法:
tf.keras.layers.Flatten(
data_format=None, **kwargs
)
参数说明:一般默认即可

连接层语法如下:
tf.keras.layers.Dense(
units,
activation=None,
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs
)
编译(配置模型进行训练)语法:
compile(
optimizer='rmsprop',
loss=None,
metrics=None,
loss_weights=None,
sample_weight_mode=None,
weighted_metrics=None,
target_tensors=None,
distribute=None,
**kwargs
)
参数说明:
编写代码模型函数如下:
def create_model():
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16,(3,3), activation = 'relu', input_shape=(150,150,3)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(32,(3,3), activation = 'relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64,(3,3), activation = 'relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation = 'relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer=RMSprop(learning_rate=0.001),
loss='binary_crossentropy',
metrics=['accuracy'])
return model
执行模型:
model = create_model()
model.summary()
如图:

五、图像处理
from tensorflow.keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest',
validation_split=0.2
)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150,150),
batch_size=50,
class_mode='binary',
subset='training'
)
validation_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150, 150),
batch_size=50,
class_mode='binary',
subset='validation')
构建回调:
class mycallback(tf.keras.callbacks.Callback):
def on_epoch_end(self,epoch,logs={}):
if(logs.get('val_accuracy')>=0.90):
self.model.stop_training = True
callback = mycallback()
六、训练模型
参数说明:
fit(
x=None,
y=None,
batch_size=None,
epochs=1,
verbose=1,
callbacks=None,
validation_split=0.0,
validation_data=None,
shuffle=True,
class_weight=None,
sample_weight=None,
initial_epoch=0,
steps_per_epoch=None,
validation_steps=None,
validation_freq=1,
max_queue_size=10,
workers=1,
use_multiprocessing=False,
**kwargs
)
因此代码如下:
history = model.fit(
train_generator,
steps_per_epoch = train_generator.samples//50,
epochs = 30,
verbose=1,
validation_data = validation_generator,
validation_steps = validation_generator.samples//50,
callbacks=[callback]
)
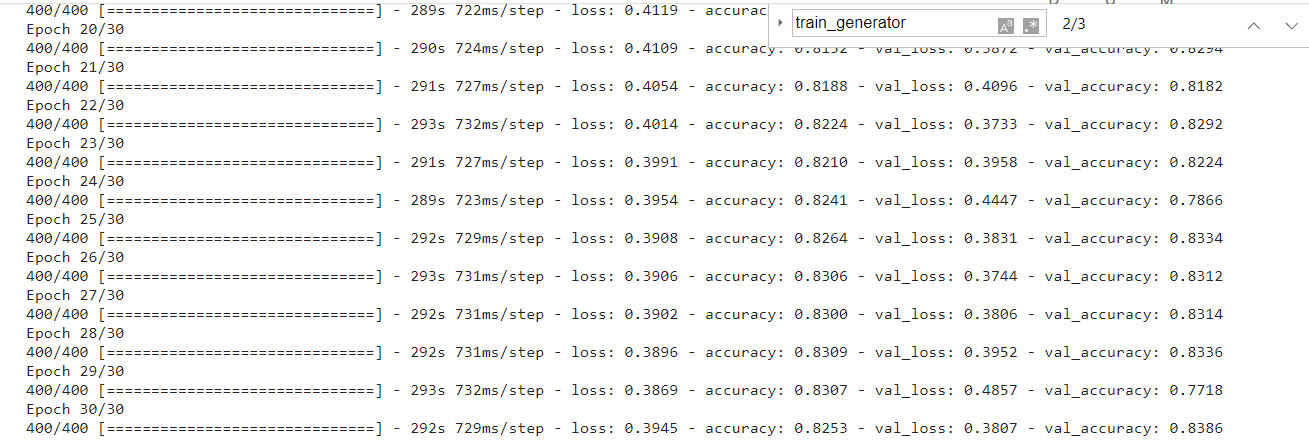
训练两个小时候,得到如下:
七、模型评估
打印准确度:
print("最大准确度: {}%".format(round(100*max(history.history['val_accuracy']), 2)))
输出:
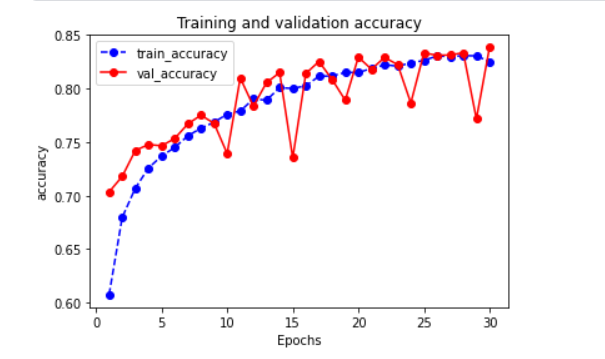
最大准确度: 83.86%
八、可视化
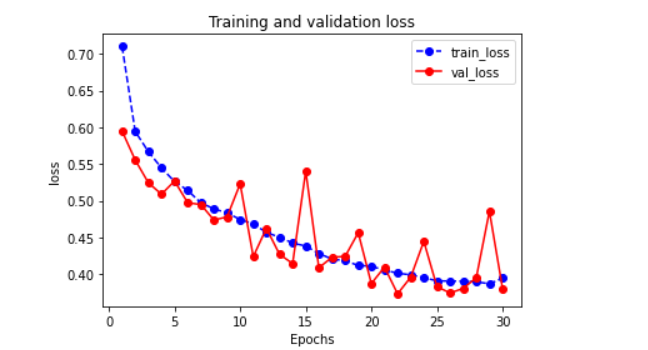
打印loss变化:
import matplotlib.pyplot as plt
def plot_metric(history, metric):
train_metrics = history.history[metric]
val_metrics = history.history['val_'+metric]
epochs = range(1, len(train_metrics) + 1)
plt.plot(epochs, train_metrics, 'bo--')
plt.plot(epochs, val_metrics, 'ro-')
plt.title('训练集和验证集 '+ metric)
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend(["train_"+metric, 'val_'+metric])
plt.show()
plot_metric(history,"loss")
如图:
打印准确度变化:
plot_metric(history,"accuracy")
如图:
九、保存模型
model.save('./tf_model_savedmodel', save_format="tf")
print('保存的模型成功..')
输出:
保存的模型成功..
十、参考
tensorflow官方API文档:
https://www.tensorflow.org/api_docs/python/tf_overview
十一、感悟
这是我第一次尝试搭建神经网络,猫狗分类是一个非常经典的案例了,在这整个学习中花了很长时间,比如:模型的搭建流程,模型的参数设置。开始我在本机训练模型,发现训练很久,自己电脑受不住,因此不得不转向kaggle上训练,经过了长达两个小时多的训练,最终识别率为83.86%。虽然不是很好,但也是经过一次很大的尝试。希望在后续中继续探索图片的分类,实际上我认为其它的图片分类与猫狗分类是类似的,因此有了迁移学习的概念,当然具体我还不了解,还在学习中。
tensorflow的模型搭建流程可以总结为:
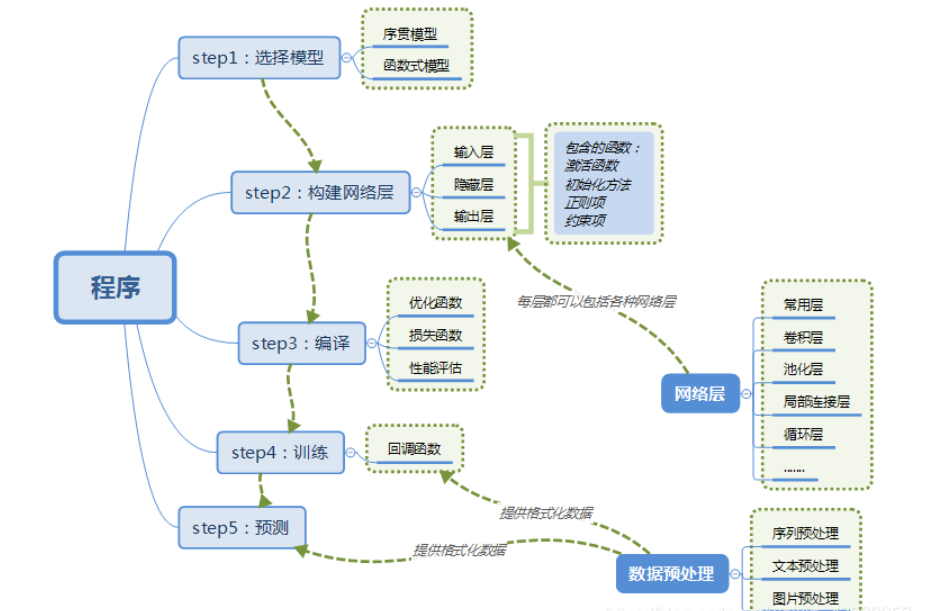
我的安排是:先学习一些经典案例,然后再深入学习这些基本的原理知识,这样学习对我来说更加高效。当然我希望您读这篇文章已经掌握机器学习大部分内容,为此我花了半个月的时间研读和实践了机器学习。
欢迎关注我的个人公众号:

Original: https://blog.csdn.net/weixin_46211269/article/details/125835345
Author: 川川菜鸟
Title: 【tensorflow2.6】图片数据建模流程:猫狗分类,83.6%识别率
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/662003/
转载文章受原作者版权保护。转载请注明原作者出处!