

该数据集(douyin.csv)主要截取了200000条抖音电商平台上的商品销售情况。本文的分析将先根据数据集的结构选取分析目标,再通过可视化来展示各项分析目标的结果,从而挖掘出影响销售各个指标的因素及程度、进行商业预测。
一、表结构观察,确立分析目标
import pandas as pd
import numpy as np
import os
import matplotlib as plt
import pyecharts
from chart_studio import plotly as py
df=pd.read_csv('D:/CCCCCC/KDD/douyin.csv',encoding='utf-8')
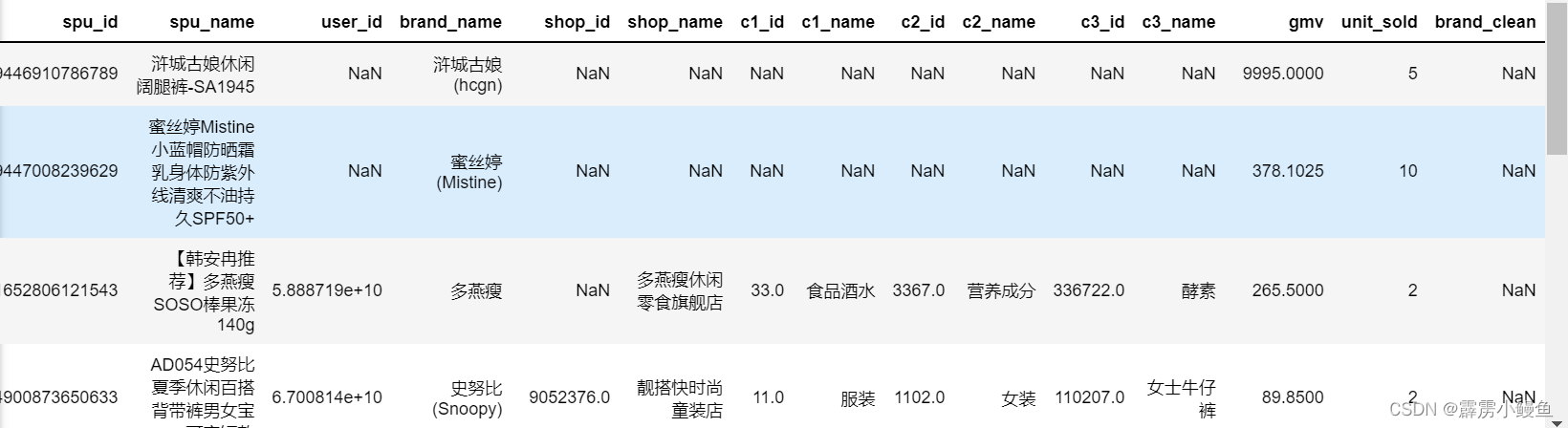

print(df.info())
df.isnull().any()

如图所示 ,商品id和名称、品牌、成交总额(gmv)、单位销量的数据是几乎齐全的;c1到c3的字段指的是商品分类的三个层次,依次为上一个的子层次;brand_clean相当于从数据集的所有品牌中精选出知名品牌;而店铺信息在该数据表中缺失值较多。
根据以上的结构分析,本文将从三个方面做分析处理:使用c1到c3字段中有的16万多条数据进行商品分类的销量分析;用品牌忠诚度、消费额、消费频率作用户价值分析;最后作出知名品牌带来效益的商业预测。
二、分类指标可视化
from pyecharts.charts import Page,TreeMap
from pyecharts import options as opts
import math
df1=df.copy()
df1=df1.dropna(subset=['c1_id'])
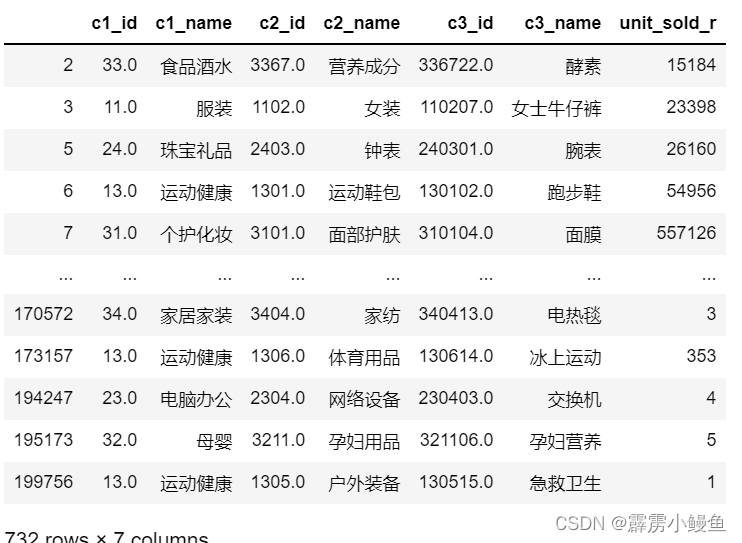
df5=df1[["c1_id","c1_name","c2_id","c2_name","c3_id","c3_name","unit_sold"]]
df6=df5.copy()
df6=df6.join(df6.groupby('c3_name')['unit_sold'].sum(), on='c3_name', rsuffix='_r')
df6=df6.drop('unit_sold',axis=1)
df6=df6.drop_duplicates()
df6.sort_values("c3_id")
writer = pd.ExcelWriter("D:/CCCCCC/KDD/df6.xls")
df6.to_excel(writer)
writer.save()

3. 在进行矩形树图的构造时,我分别构造了前一、二、三层分类的图表,发现如果将前三层全部放入的话可视化效果并不好,故只给出前两层分类的效果图,以及前三层分类的代码;构造矩形树图最关键的一步是建立字典,表现出树的枝叶结构。
df8=pd.read_csv('D:/CCCCCC/KDD/df6.csv',encoding='gb18030')
df8=df8.dropna(axis=0,how='all')
df8.fillna(0, inplace=True)
tree = []
name = [df8['c1'][i]+'\n'+str(df8['v1'][i]) for i in range(len(df8))]
for i in range(len(df8)):
dic = {}
dic["value"],dic["name"] = int(df8['v1'][i]),name[i]
if math.isnan(df8['v1-1'][i]) ==0:
dic["children"] = [
{"name":df8['c1'][i]+"-"+str(df8['c1-1'][i])+'\n'+str(df8['v1-1'][i]),"value":int(df8['v1-1'][i])},
{"name":df8['c1'][i]+"-"+str(df8['c1-2'][i])+'\n'+str(df8['v1-2'][i]),"value":int(df8['v1-2'][i])},
#为了代码的美观,并未将第二层分类全部列出,根据需要扩写即可
]
#若需要呈现第三层分类的效果,加入如下代码:
"""
if math.isnan(df8['v1-1-1'][i]) ==0:
dic["children"][0]["children"] = [
{"name":df8['c1'][i]+"-"+str(df8['c1-1'][i])+"-"+str(df8['c1-1-1'][i])+'\n'+str(df8['v1-1-1'][i]),"value":int(df8['v1-1-1'][i])},
{"name":df8['c1'][i]+"-"+str(df8['c1-1'][i])+"-"+str(df8['c1-1-2'][i])+'\n'+str(df8['v1-1-2'][i]),"value":int(df8['v1-1-2'][i])}
]
"""
tree.append(dic)
#绘图
tm=(
TreeMap()
.add("c1",tree)
.set_series_opts(label_opts=opts.LabelOpts(position='inside'))
.set_global_opts(title_opts=opts.TitleOpts(title = 'sales_treemap',subtitle = '2022/8/1-pili_unagi'))
)
tm.render('treemap3.html')
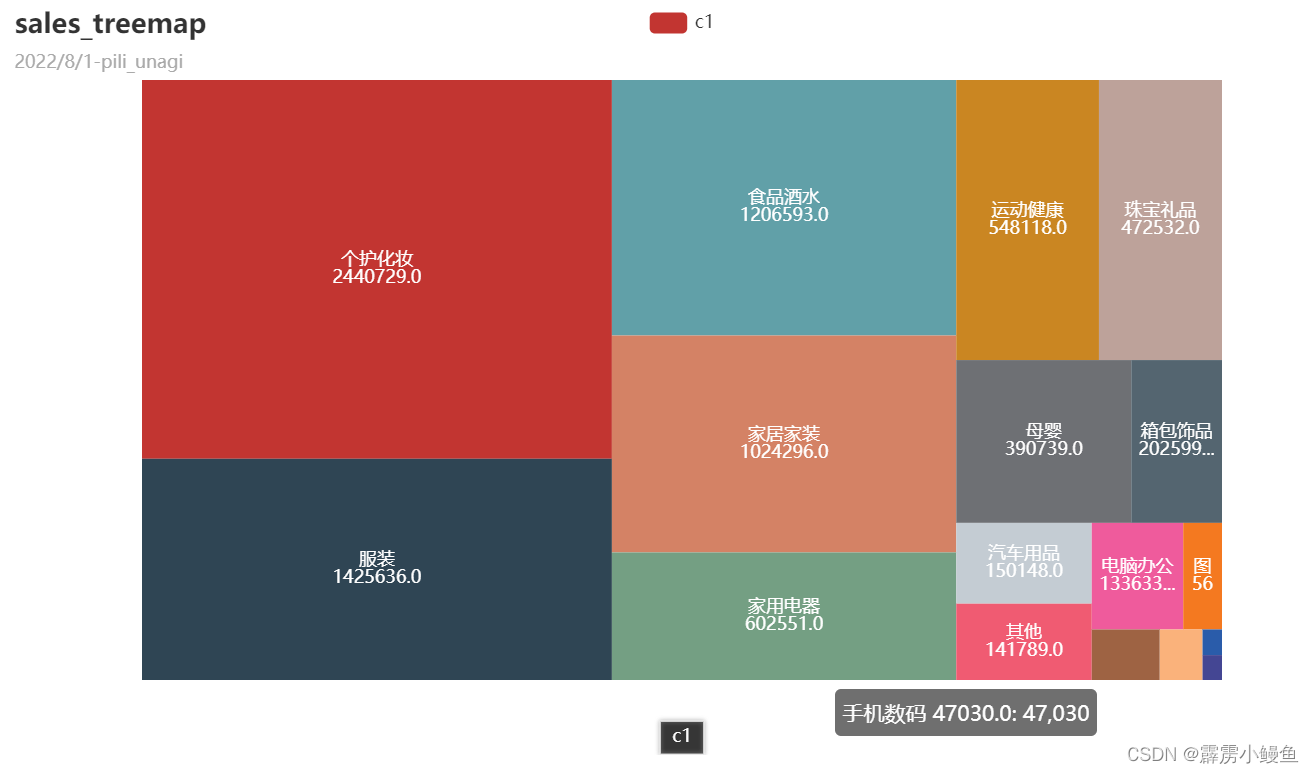
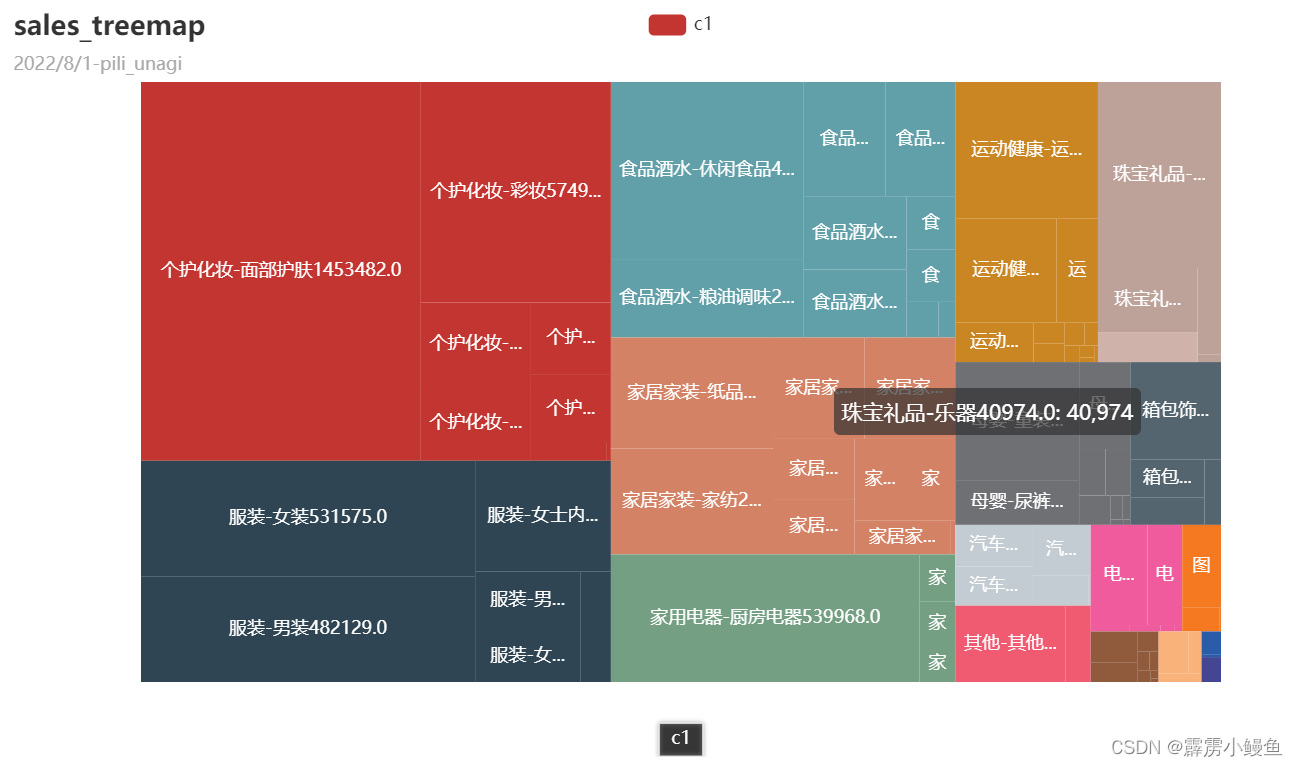
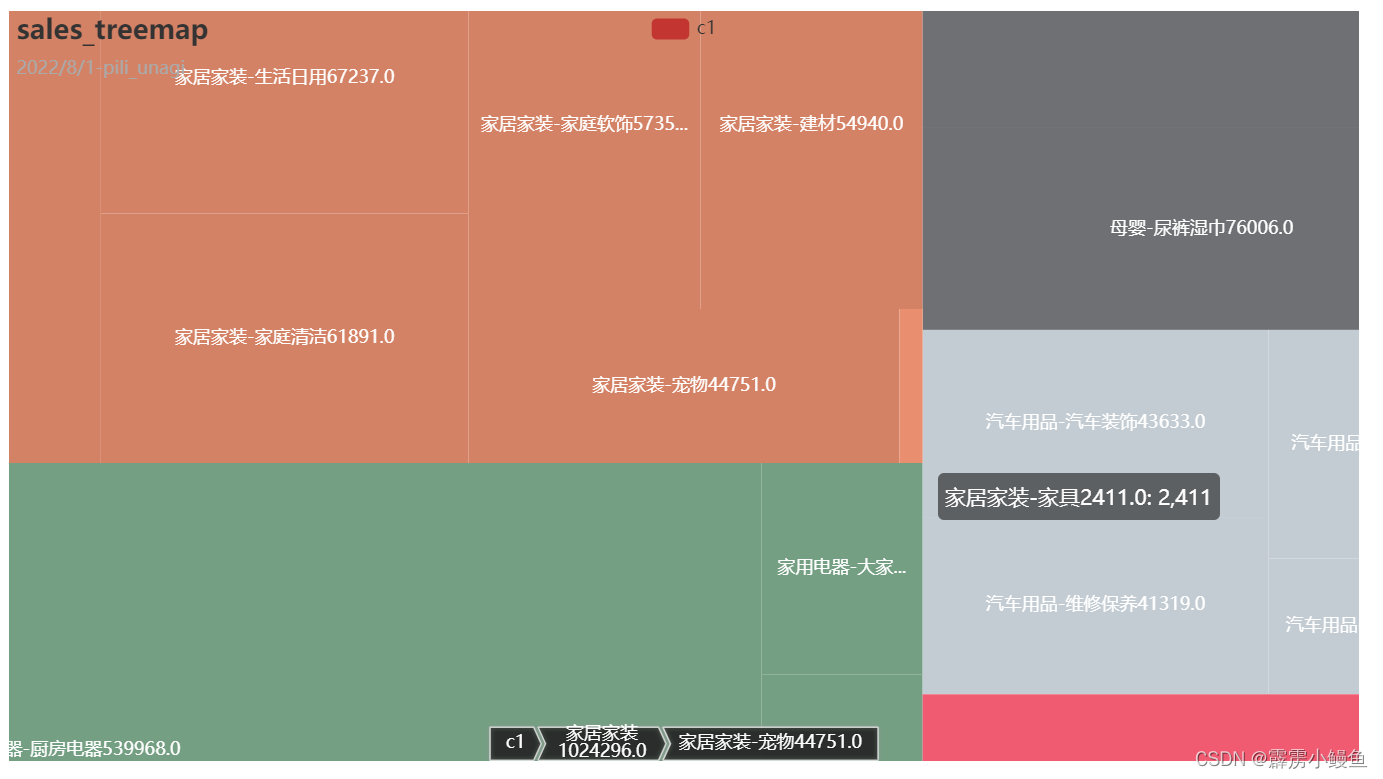
三、用户价值分析
- 从现有字段里选取三个能够表现客户消费意愿、消费能力和习惯的属性。
df4=df.copy()
df4=df4.dropna(subset=['user_id'])
df4["brand_clean"].where(df4["brand_clean"].isnull(),1, inplace=True)
df4["brand_clean"].fillna(0, inplace=True)
#属性规约
df4=df4[['gmv','unit_sold','brand_clean']]
- 将表格数据标准化,便于使用k-means聚类分析用户群。
def zsnorm(df_input):
return df_input.apply(lambda x: (x-x.mean())/ x.std(), axis=0)
zs_df4=zsnorm(df4)
zs_df4.columns=['ZG','ZU','ZB']
- 开始用k-means算法进行聚类。
from sklearn.cluster import KMeans
from sklearn import metrics
import matplotlib.pyplot as plt
#模型训练
k_means=KMeans(n_clusters=5)
k_means.fit(zs_df4)
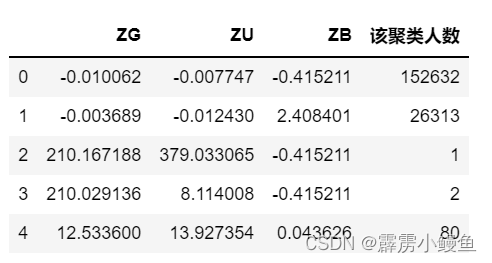
k_means.cluster_centers_ #聚类中心
k_means.labels_ #各样本的类别
r1 = pd.Series(k_means.labels_).value_counts() #各类别频数
r2 = pd.DataFrame(k_means.cluster_centers_)
r = pd.concat([r2,r1],axis=1)
r.columns = list(zs_df4.columns) + ['该聚类人数']
4. 若要求可视化,可绘制雷达图,但考虑到此次归约的属性较少,雷达图效果一般,下面给出代码:
fig=plt.figure(figsize=(10, 10))
ax = fig.add_subplot(111, polar=True)
center_num = r.values
feature = ["gmv", "unit_sold", "brand_clean"]
N =len(feature)
lab = []
for i, v in enumerate(center_num):
angles=np.linspace(0, 2*np.pi, N, endpoint=False)#等分圆面
center = np.concatenate((v[:-1],[v[0]]))
angles=np.concatenate((angles,[angles[0]]))
ax.plot(angles, center, 'o-', linewidth=2, label = "the%dcluster,%dpeople"%(i+1,v[-1]))
ax.fill(angles, center, alpha=0.25)
ax.set_thetagrids(angles * 180/np.pi, feature + [feature[0]], fontsize=15)
ax.set_ylim(-5,200)
plt.title('Customer Characteristics Analysis Chart', fontsize=20)
ax.grid(True)
lab.append("the{}cluster: {:>7}people".format(i+1, int(v[-1])))
plt.legend(lab, loc='upper right', bbox_to_anchor=(1.3,1.0),ncol=1,fancybox=True,shadow=True)
plt.savefig("D:/CCCCCC/KDD/TTUVA.jpg")
plt.show()
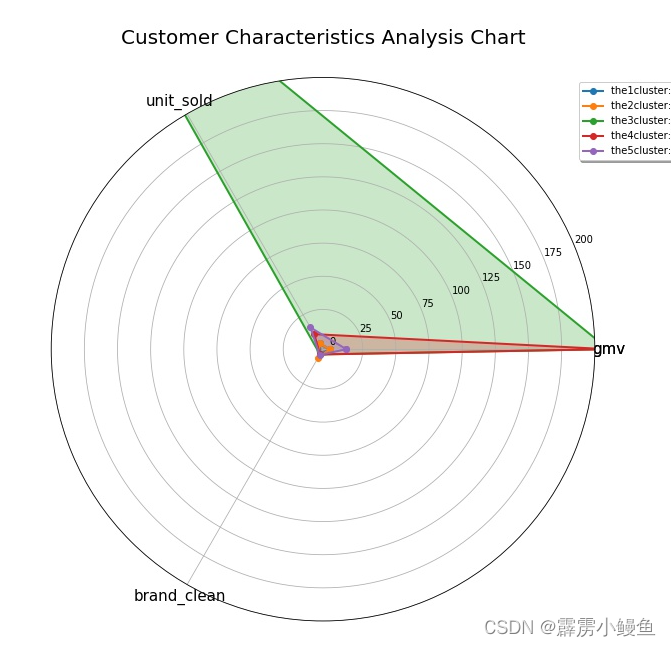
5. 简要分析用户群:聚类①没有品牌要求,消费额和消费量都不高,属于普通百姓的消费水平;聚类②消费额和消费量都不高,但消费品大多都是名牌,通常属于生活质量较高、消费思想较前的人群;聚类③消费量巨大,且非知名品牌,人数也少,该用户群很有可能是批发商(图中绿色);聚类④在低消费量的同时金额很高,且消费的是大品牌,说明该人群收入高,生活富足(图中红色);聚类⑤属于消费中位,各方面特征不突出。
四、 品牌效应与商业预测
- 想要体现出消费数据中品牌到底有多大的力量,可以先将知名品牌商品筛选出来,计算出相关指标。
df3=df.copy()
df3=df3.dropna(subset=['brand_clean'])
df3['gmv'].sum()
df['gmv'].sum()
df3['unit_sold'].sum()
df['unit_sold'].sum()
- 20万条消费数据中,知名品牌的占比是14.52%;成交额gmv占比15.41%;销量占比13.25%;这个数据说明,由于其特殊的产品属性和用户群体,抖音平台并非品牌效应表现最明显之地。
Original: https://blog.csdn.net/qq_56907734/article/details/126058060
Author: 霹雳小鳗鱼
Title: 【数据分析】分类指标、用户价值与预测—抖音电商数据集
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/661674/
转载文章受原作者版权保护。转载请注明原作者出处!