

Privacy Preserving Probabilistic Record Linkage Without Trusted Third Party论文总结
- Abstract
- I. INTRODUCTION
- II. RELATED WORK AND BACKGROUND
* - 不经意传输OT(Oblivious transfer)
- 混淆电路Garbled Circuit
- A. Deterministic and Probabilistic PPRL
- B. Bloom Filter and Dice Coefficient
- III. PROBABILISTIC PPRL PROTOCOL OVERVIEW
- IV. COMPUTATION METHODS
* - A. Garbled Circuit to Compute and Compare DC
- B. Optimizing the computation
- V. EXPERIMENTATION AND RESULTS
* - A. Implementation
- B. Evaluation Metrics
– - C. Results
- ANALYSIS AND OBSERVATIONS
- CONCLUSIONS
Without Trusted Third Party论文总结)
Abstract
提出了一个协议,它不要求两个记录在标识属性上有精确的匹配才能被声明为属于同一个人。
其次,我们研究了在 不借助任何TTP的情况下,两方环境下的概率PPRL。 我们使用Bloom滤波器进行概率匹配,使用 Yao乱码电路对加密数据进行匹配所需的计算。
I. INTRODUCTION
大多数工作遵循集中式链接方法,需要可信第三方(TTP)或半可信第三方(STP)的参与[3]。 然而,TTP或STP容易受到攻击[4],导致信息泄漏。
我们的工作是基于Bloom过滤器的概率PPRL[5]和Yao[6]提出的乱码电路的概念,该概念允许双方安全地计算任意函数f(x,y),而不共享x和y值。
在我们的方法中,联系是根据bloom过滤器之间的近似相似性来确定的,通过骰子系数(DC)来衡量。
姚的乱码电路(GC)用于计算每对记录的直流,并以安全的方式将其与预先设置的阈值进行比较。 各方不必交换他们的Bloom过滤器,甚至不必共享DC值。 如果可以链接两条记录,计算的输出为”true”,否则为”false”。
由于骰子系数值可能会泄漏一些信息,我们设置了一个阈值。 我们有一个乱码电路,将计算出的骰子系数与阈值进行比较,如果计算值大于或等于阈值,则返回”true”,从而减少信息泄漏。
我们的协议改进了Schnell等的方法。 AL在[5]中针对记录链接,通过移除TTP,并采用优化的乱码电路设计,将各方的数据保存在其站点上,以防止Bloom Filters的密码分析。
II. RELATED WORK AND BACKGROUND
不经意传输OT(Oblivious transfer)
参考来源:【隐私计算笔谈】MPC系列专题(三):不经意传输与混淆电路


在双方参与的不经意传输中,一方”Bob”输入一组数据,另一方”Alice”输入一个选择,从Bob输入的数据中选取一个。Alice只获得其所选择的数据,无法得知 Bob输入的其他数据。Bob无法知道Alice选择获得了哪个数据。如有一个2选1的不经意传输协议,Bob输入{𝑎0,𝑎1},Alice输入𝑟∈{0,1} 计算结束后Alice获得𝑎𝑟,但是无法获得𝑎1-𝑟,Bob无法得知Alice输入的𝑟的值。若Alice输入的𝑟=0,则Alice获得𝑎0,无法获得𝑎1;若Alice输入的𝑟=1,则Alice获得𝑎1,无法获得𝑎0。Bob无法得知Alice具体获得的是𝑎0还是𝑎1。
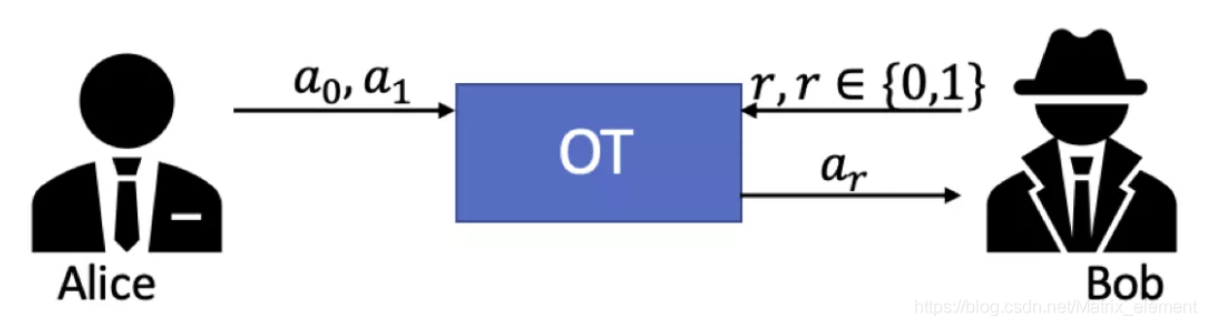
; 混淆电路Garbled Circuit
对于布尔电路而言,电路实现与或非即可实现完备,可以模拟任意的函数。混淆电路是实现安全多方计算的另一种方式,通过对电路进行加密来掩盖电路的输入和电路的结构,以此来实现对各个参与者的隐私信息的保密,再通过电路计算来实现安全多方计算的目标函数的计算。

如上图所示,里面我们的两个老朋友Alice和Bob想要搞点事情,还是比较谁更富有,但是不希望互相公布自己的财富值。这次我们不适用秘密分享、不经意传输来解决,我们将问题转化为数字电路来解决(比如比较电路,或者emmmm什么电路)。电路里面有一些门,每个门包括输入线(input wire)和输出线(output wire)。混淆电路就是通过加密和调整序列的值来掩盖信息的。在最经典的混淆电路中,加密和扰乱是以门为单位的。每个门都有一张真值表。
第一阶段将安全计算函数转换为电路,称之为电路产生阶段;
第二阶段,利用OT、加密等密码学原语等执行电路,称之为执行阶段。
每一阶段由参与运算的一方来负责,直至电路执行完毕输出运算后的结果。针对参与运算的双方,从参与者的视角,又可以将参与安全运算的双方分为电路的产生者(circuit generator)与电路的执行者(circuit evaluator)。示意图如下所示:
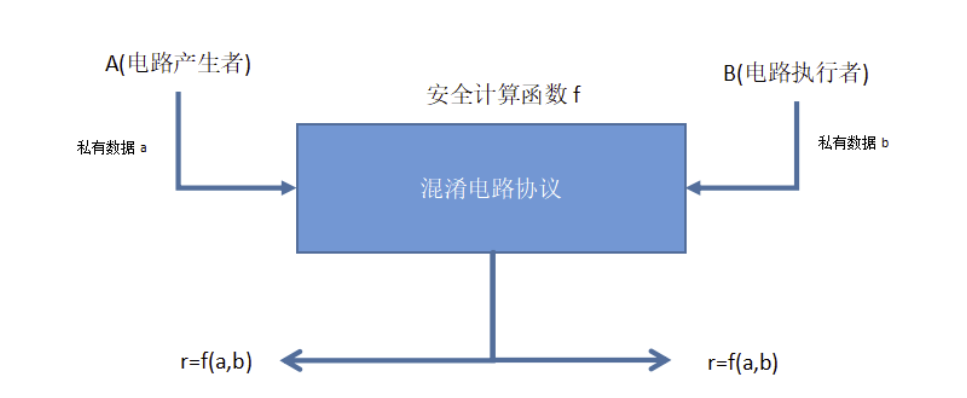
步骤一:电路产生阶段
参与运算的双方先就需要安全计算的目的依靠专有编程语言(DSL)或相关编程语言扩展等进行编程,然后针对实现计算的程序进行编译,生成布尔电路文件;
然后针对双方输入值以及中间输出结果随机产生映射label,再利用这些label做为key对每个对应的电路输出真值表采用分组密码方式进行加密,并对真值表值进行打乱操作,这一步就是混淆电路的概念。
步骤二:电路执行阶段
电路执行者针对布尔电路文件进行执行,执行时电路生成者需要将自己的输入所对应的label发给电路执行者;电路执行者依据自己所有信息通过OT方式选择自己对应的label,这样电路生成者与执行者均不到对方的输入数据;电路执行者此时获取双方输入对应的label,作为key的相关信息对真值表进行解密,即可获取真值表的内容,循环往复,直至所有电路执行完毕,输出执行结果。
举例
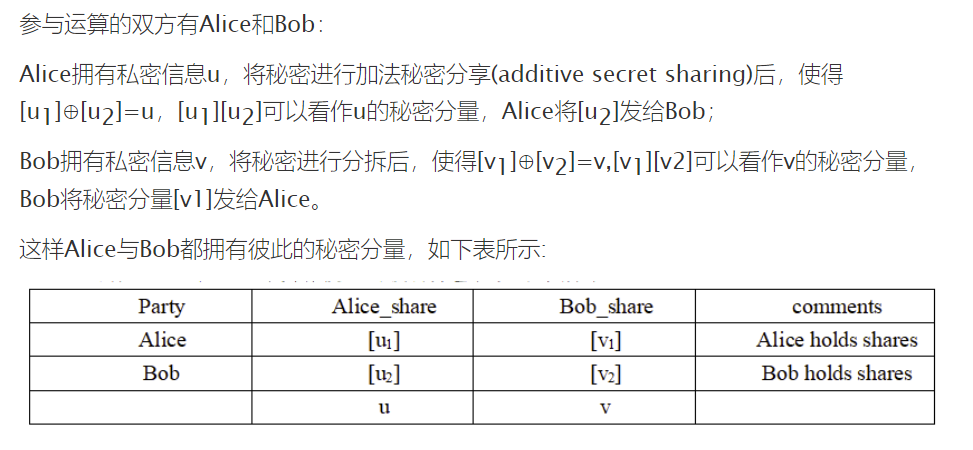
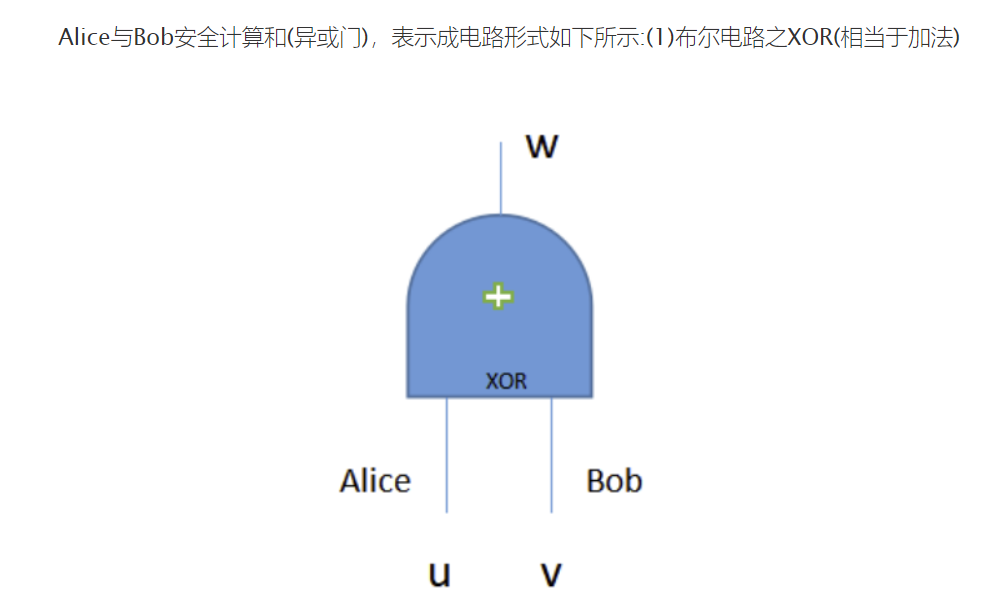
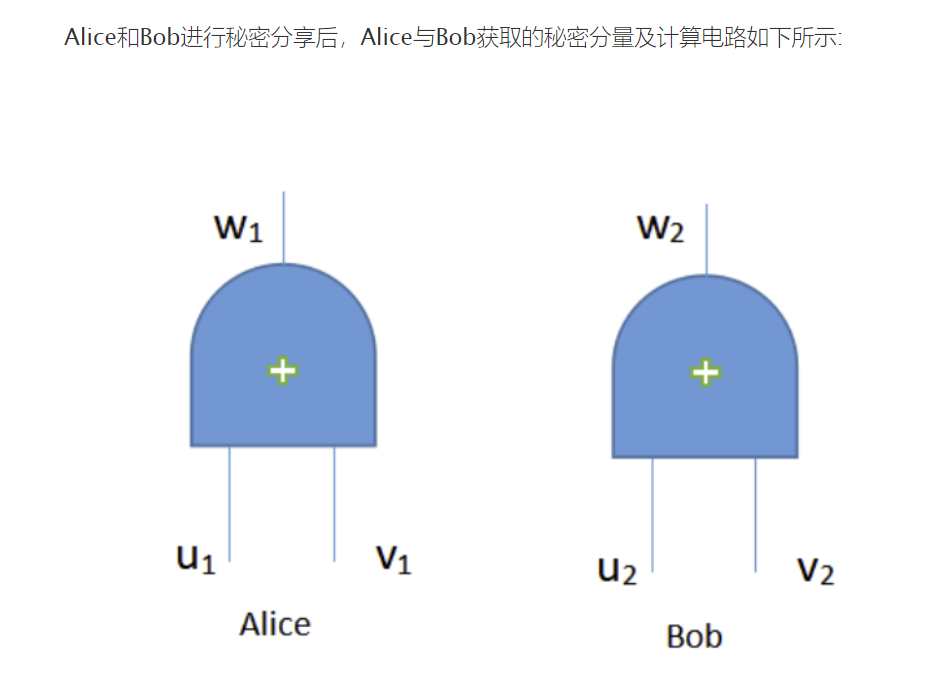

A. Deterministic and Probabilistic PPRL

一种基于安全多方计算的PPRL。 首先使用公共可用的标识符阻塞数据(索引或分组到块中,以便每个块中的记录在其某些属性中具有相似的值),然后使用第三方(TP)的公钥和Paillier加密方案,甲方加密他的编码数据并将其发送给乙方。乙方然后使用他的数据和TP的公钥对A的加密数据执行一些同态操作,并将加密结果发送给TP。 然后TP使用其私钥来计算记录对之间的最终相似度值。 虽然这项工作使用了安全计算,这在计算上是昂贵的(10K数据集的处理大约需要23.3小时)
我们的链接方案不需要TP
我们使用一组Bloom过滤器对不同的链接标识符组合进行编码,并使用DICE系数作为相似性度量。
由于我们不使用TP协议,因此在我们的方案中不可能危及TP协议或其公钥,导致信息泄漏。
; B. Bloom Filter and Dice Coefficient
以Bloom Filter位向量形式出现的散列值容易受到基于频率的攻击,这些攻击可能会泄露原始的明文值[3]。 为了防止此类攻击,我们使用Bloom Filter位向量作为安全的双方计算机制的输入,称为Yao的乱码电路协议。 Yao的方法在计算过程中使用了不经意传输(OT)协议[27],[28],使得任何一方都无法访问对方的输入。
III. PROBABILISTIC PPRL PROTOCOL OVERVIEW
我们的协议包括两个步骤:(i)Bloom Filter的生成和(ii)使用DICE系数匹配记录。 我们在下面描述每个步骤的细节。
- Bloom Filter Generation
- Matching using Dice Coefficient
IV. COMPUTATION METHODS
A. Garbled Circuit to Compute and Compare DC
计算和比较直流的乱码电路
可以构造一个garbled circuits (GC)乱码电路,例如算法1中所示的电路,以将计算出的DC返回给双方。 但是,DC值可以揭示有关比较记录的信息。 例如,当DC接近1时,各方可以推断出另一方的匹配属性。 当某些记录具有与所有其他记录匹配的较小的DC值时,可以将其挑出为具有较少频繁属性的记录。
另一种方法是将计算出的DC与预先设置的匹配骰子系数阈值DCT进行比较,并返回”true”或”false”来表示匹配或不匹配判决。 如果使用阈值来过滤结果,则需要比较器电路来比较阈值和DC的浮点值(参见算法中的步骤4)。
为了提高效率,我们使用整数而不是浮点表示,并在不损失任何准确性的情况下实现了这种比较。 常阈值DCT表示为128的分数而不是100的分数(使用左移7次而不是乘法); 也就是说,新分数的新分子是整数值ti=int(dct×128),分母是128。 比较器电路CMP(comparator circuit cmp)如下:
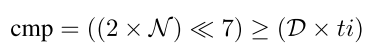
其中,如果DC大于或等于阈值,比较器电路将返回真。 图1显示了由甲方生成的DC-computation,并以GC的形式与阈值进行了比较。我们假设甲方是生成器,乙方是评估器。
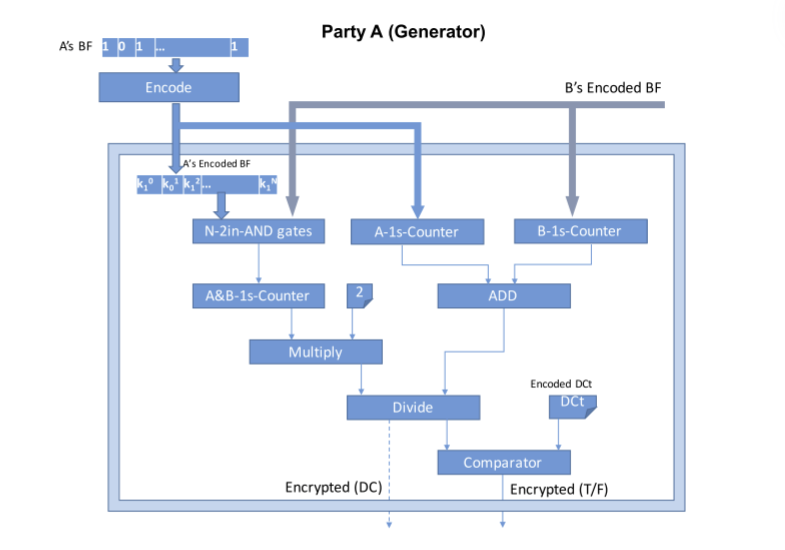
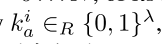
2. 甲方将GC及其编码的Bloom Filter发送给乙方。
3. 乙方从甲方获得其Bloom Filter B的位到其密钥的映射,而不通过OT协议将B的位透露给甲方。 对于每一位bi∈{0,1},i=0。
4. 乙方使用其编码的Bloom Filter(在步骤3中获得)的密钥作为其对GC的输入来评估GC,并从GC评估中获得加密的结果。
5. 乙方将得到的结果发送给甲方解密。
6. 甲方将结果解密后发送给乙方,双方均可输出匹配过程的结果。
7. 甲乙双方需要对他们创建的每一对Bloom过滤器重复这些步骤。
; B. Optimizing the computation
在记录链接过程结束时,双方的输出将是满足匹配DC阈值的相应记录索引的列表。 双方将能够将这些索引映射到各自在两端维护的记录ID。
尽管GC结构得到了改进[28],但使用GC的综合(n到m)链接过程对于匹配大型数据集仍然是低效的。 由于每个记录都有k个编码的Bloom过滤器,匹配过程为处理的数据集中的每对记录计算k个DCS。 若要声明任何一对记录为匹配,它们中的至少一个DCS必须大于或等于预先设置的阈值DCT。 对于大小分别为m和n的两个数据集X和Y,每一个都有k个Bloom滤波器,匹配过程需要 m×n×k个DC计算。 使用GC和不经意的传输操作的DC计算需要大量的时间。 我们现在提出了两种启发式方法来减少问题的规模并使计算更加有效。
- Improvement using blocking:
在记录链接中,分块是将具有一定特征的记录分组在一起的过程。 通过分块,将匹配过程限制在具有相同特征的组中,从而减少了GC计算和OT操作的开销。 任何提供符合差异隐私的数据保护的安全阻塞方案,如[24]中提到的方案,都可以作为我们方案的预处理步骤。 分块将比较限制为具有相似链接变量值的块,并以B×S2比较结束,其中B是匹配块的数量,S是每个块中的平均记录数量。 - Improvement using partitioned Bloom filters:
在这一步中,每一方将他的BF划分成π个较小的部分。 然后,根据每个部分的个数,计算其对总DC的贡献。 随着计算的进行,我们依次确定是否值得继续对其他部分进行计算。 换句话说,我们的GC安全地依次计算双方分区Pi,1≤i≤π的贡献Ci,并检查它是否满足其对预设阈值DCT的贡献。 如果分区通过了贡献履行测试,则双方进行下一个分区; 否则,他们停止,不处理剩余的部分。
让我们将当事方A和B计算其DC的两个BFs表示为A和B,以及它们的部分,A={A1A2…Aπ}和B={B1B2…Bπ},其中是串联运算符。 在这种情况下,相应的分块(Ai,Bi)1≤i≤π对整个DCT的贡献Ci由下面给出的公式计算。 这里ai️bi表示使用按位AND运算计算的分区ai和bi的交集中1的个数。 a和b分别表示布卢姆过滤器a和b中1的个数。
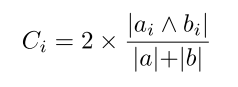
V. EXPERIMENTATION AND RESULTS
A. Implementation
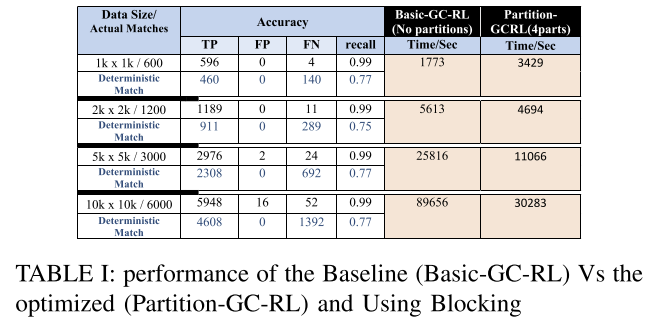
我们利用UCSD[29]开发的Java代码库来实现我们的概率乱码电路。 我们对现有UCSD代码库的补充包括1)骰子系数计算,2)分区Bloom过滤器和3)分块方案的实现。
在我们的实验中,我们在一个本地网络上运行了双方(生成器和计算器)Java代码,两台机器配备了4GB RAM和Intel i5处理器。 为了验证系统的可伸缩性,我们在一组机器上运行了系统的分布式版本,并报告了结果以供比较。
这些数据集是使用Mockaroo合成数据生成器(http://www.mockaroo.com)生成的,该生成器使用真实姓名和地址。 这两个数据集中包含的数据字段都是名字、姓氏、社会保障号码(SSN)、出生日期和身份证明(ID)。 这些数据集中每个字段的数据都被随机损坏,以模拟基本的排印错误(即插入、删除、替换和转置)。 对于每个领域,腐败率从10%到20%不等。 为了验证结果,我们为每个记录使用一个标识号(ID),这样属于同一个人的所有记录都有相同的标识号。 每个数据集包含10k条记录,两个数据集共有6k条记录。 两个数据集中的记录在ID字段中的值相同。 因此,ID字段的值被用作验证链接性能的真实答案。
B. Evaluation Metrics
Accuracy:
匹配过程的准确性由真阳性率TPR或召回值来衡量
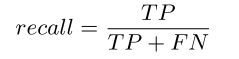
为了说明使用概率PPRL相对于确定性PPRL的优势,我们将使用Bloom Filters的概率PPRL和使用数据哈希的确定性PPRL进行了比较。
; Runtime Improvement:
我们执行测试来演示通过阻塞和分区方法对运行时的改进:
- Blocking Without BF-partitioning:
- Blocking with BF-partitioning:
- Effect of block size:
- Effect of BF Partitioning:
- Scalability ofour approach:
C. Results
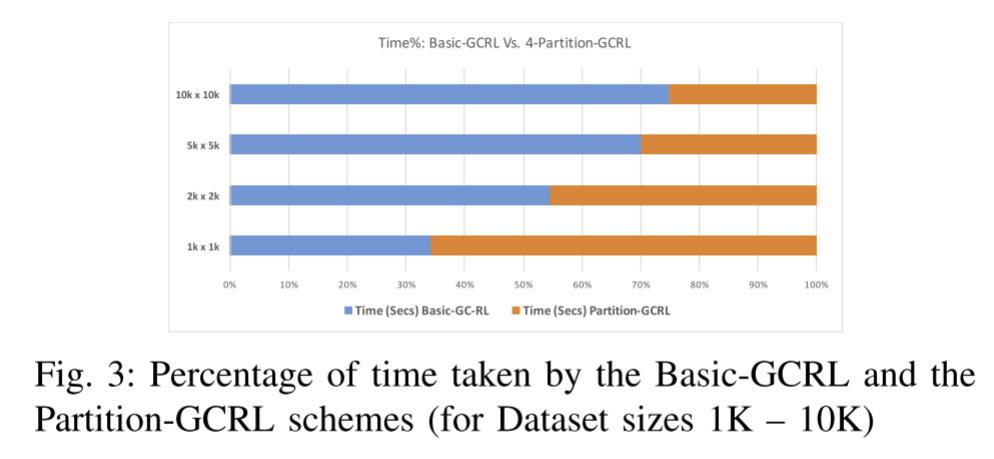
在每个测试中,具有相同数量记录的两个数据集被链接。 每个测试运行3次,并记录平均运行时。 数据集的每个记录由4个Bloom过滤器组成,这些过滤器使用第三节中解释的组合来构造,每个测试计算每对记录的相应BFS的4个DCS。 如果任何DC超过DCT=0.9阈值,则声明匹配。
; ANALYSIS AND OBSERVATIONS
CONCLUSIONS
我们提出了一种基于Bloom过滤器和乱码电路的概率PPRL算法,该算法避免了对TTP的需要。 本文利用分块技术提高了方案的效率,并给出了一些实验结果,分析了方案的准确性和保密性。 在将来,我们计划将该方法并行化,并在实际数据集中测试结果。 我们还计划看到使用不同的连锁变量组合的效果。
Original: https://blog.csdn.net/MashiroSakura/article/details/127787064
Author: 桐青冰蝶Kiyotaka
Title: Privacy Preserving Probabilistic Record Linkage Without Trusted Third Party论文总结
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/658173/
转载文章受原作者版权保护。转载请注明原作者出处!