

简介:malloc对于大家来说应该都不陌生了,这是系统库给我们提供了申请指定大小内存的函数,之前介绍的伙伴系统,只能以页的方式申请内存,对于小块(小于一页)内存的申请我们就得通过自定义的库函数来实现相关需求,所以在用户空间层面诞生了诸如ptmalloc(glibc),tcmalloc(google),jemalloc(facebook)等优秀的内存分配库。但是这些库内核没法使用,且内核也有大量申请小块内存的需求,诸如管理dentry,inode,fs_struct,page,task_struct等等一系列内核对象。所以内核提出了slab分配器,用来管理内核中小块内存分配,而cpu cache也是配合slab使用的,有时候也把slab称为缓存。
内核中内存管理
对于内核来说,slab主要包括kmalloc及kfree两个函数来分配及释放小块内存:
kmalloc(size, flags):分配长度为size字节的一个内存区,并返回指向该内存区起始void指针,如果没有足够内存,返回NULL。
kfree(_ptr):释放_ptr指向的内存区。
对于内核开发者还可以通过kmem_cache_create创建一个缓存kmem_cache对象;
通过kmem_cache_alloc、kmem_cache_alloc_node提供特定类型的内核缓存对象申请。他们最终都会调用到slab_alloc。所以主要的slab操作都在slab_alloc函数中。
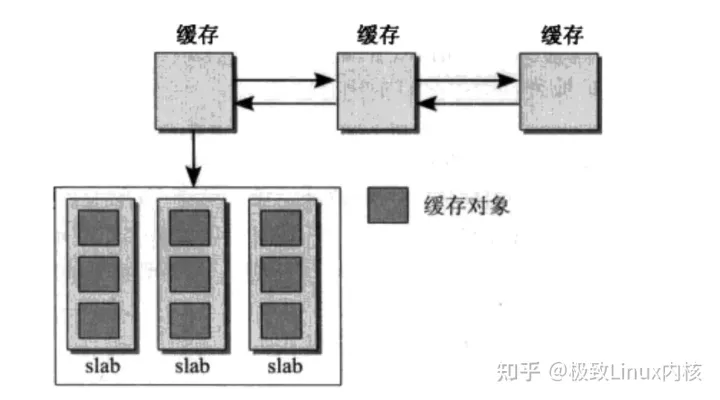
slab缓存由两部分组成:保存管理性数据的缓存对象和保存被管理对象的各个slab对象

【文章福利】小编推荐自己的Linux内核技术交流群:【977878001】整理一些个人觉得比较好得学习书籍、视频资料共享在群文件里面,有需要的可以自行添加哦!!!前100进群领取,额外赠送一份 价值699的内核资料包(含视频教程、电子书、实战项目及代码)

内核资料直通车: Linux内核源码技术学习路线+视频教程代码资料
学习直通车: Linux内核源码/内存调优/文件系统/进程管理/设备驱动/网络协议栈-学习视频教程-腾讯课堂
slab cache
上图中缓存即为kmem_cache,slab即为page页帧,缓存对象即为void指针。一个kmem_cache会在不同的内存节点管理很多页帧,这些页帧在各个内存节点被划分为3类:部分空闲,全部空闲以及全部分配。
每个缓存kmem_cache对象只负责一种slab对象类型的管理,各个kmem_cache缓存中slab对象大小各不相同,由创建的时候指定,而缓存会根据指定的slab对象大小根据cpu cacheline 或者void*指针大小进行对齐,然后根据一个公式计算一个合适的gfporder来确定每次申请的内存页帧的数量。其计算方法为:
依次递增gfporder,这样关联页数就为2^gfporder,对应的字节数为PAGE_SIZE << gfporder;
PAGE_SIZE << gfporder = head + num * size + left_over
当left_over * 8 <= page_size << gfporder 时就决定是这个gfporder,因为这是一个可以接受的碎片大小。 < code></=>
对应的计算函数为calculate_slab_order,相关代码如下:
/**
* calculate_slab_order - calculate size (page order) of slabs
* @cachep: pointer to the cache that is being created
* @size: size of objects to be created in this cache.
* @flags: slab allocation flags
*
* Also calculates the number of objects per slab.
*
* This could be made much more intelligent. For now, try to avoid using
* high order pages for slabs. When the gfp() functions are more friendly
* towards high-order requests, this should be changed.
*/
static size_t calculate_slab_order(struct kmem_cache *cachep,
size_t size, slab_flags_t flags)
{
size_t left_over = 0;
int gfporder;
for (gfporder = 0; gfporder <= kmalloc_max_order; gfporder++) { unsigned int num; size_t remainder; num="cache_estimate(gfporder," size, flags, &remainder); if (!num) continue; * can't handle number of objects more than slab_obj_max_num (num> SLAB_OBJ_MAX_NUM)
break;
if (flags & CFLGS_OFF_SLAB) {
struct kmem_cache *freelist_cache;
size_t freelist_size;
freelist_size = num * sizeof(freelist_idx_t);
freelist_cache = kmalloc_slab(freelist_size, 0u);
if (!freelist_cache)
continue;
/*
* Needed to avoid possible looping condition
* in cache_grow_begin()
*/
if (OFF_SLAB(freelist_cache))
continue;
/* check if off slab has enough benefit */
if (freelist_cache->size > cachep->size / 2)
continue;
}
/* Found something acceptable - save it away */
cachep->num = num;
cachep->gfporder = gfporder;
left_over = remainder;
/*
* A VFS-reclaimable slab tends to have most allocations
* as GFP_NOFS and we really don't want to have to be allocating
* higher-order pages when we are unable to shrink dcache.
*/
if (flags & SLAB_RECLAIM_ACCOUNT)
break;
/*
* Large number of objects is good, but very large slabs are
* currently bad for the gfp()s.
*/
if (gfporder >= slab_max_order)
break;
/*
* Acceptable internal fragmentation?
*/
if (left_over * 8 <= (page_size << gfporder)) break; } return left_over; * calculate the number of objects and left-over bytes for a given buffer size. static unsigned int cache_estimate(unsigned long gfporder, size_t buffer_size, slab_flags_t flags, *left_over) { num; slab_size="PAGE_SIZE" gfporder; slab management structure can be either off or on it. latter case, memory allocated is used for: - @buffer_size each object one freelist_idx_t we don't need to consider alignment freelist because will at end page. correct alignment. if slab, then already calculated into slabs are all pages aligned, when allocated. (flags & (cflgs_objfreelist_slab | cflgs_off_slab)) num="slab_size" buffer_size; *left_over="slab_size" % else (buffer_size + sizeof(freelist_idx_t)); < code></=></=>
系统中所有的缓存都保存在一个双链表中,这使得内核可以遍历所有的缓存,这主要用于缩减分配给内存的数量,常见的场景就是:dentry及inode slab缓存的回收,当机器物理内存不足时就会缩减这一部分内存占用(这一部分内存被称为SReclaimable,可以通过cat /proc/meminfo查看)。
基本结构
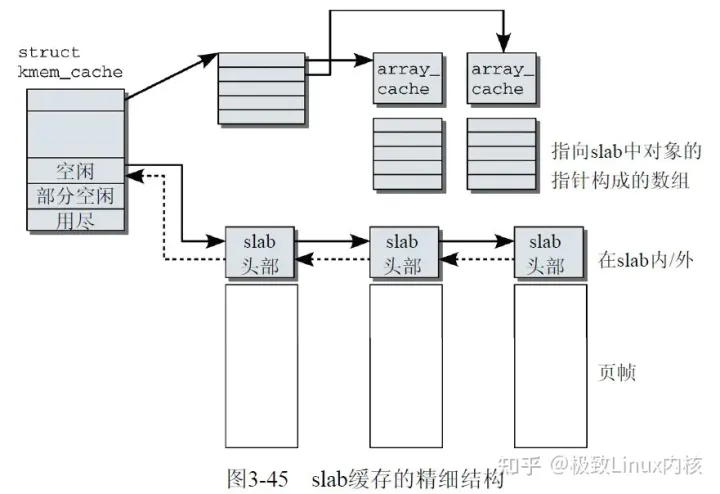

kmem_cache数据结构代表一个slab 缓存,其中有一些缓存元信息包括:缓存名,缓存对象大小,关联的内存页帧数,着色信息等等;还有一个__per_cpu array_cache用于表示该缓存在各个CPU中的slab对象;kmem_cache_node用于管理各个内存节点上slab对象的分配。
array_cache是一个per_cpu数组,所以访问不需要加锁,是与cpu cache打交道的直接数据结构,每次获取空闲slab对象时都是通过entry[avail–]去获取,当avail==0时,又从kmem_cache_node中获取batchcount个空闲对象到array_cache中。
kmem_cache_node用于管理slab(实际对象存储伙伴页帧),其会管理三个slab列表,部分空闲partial,全部空闲empty,全部占用full。array_cache获取batchcount空闲对象时,先尝试从partial分配,如果不够则再从empty分配剩余对象,如果都不够,则需要grow分配新的slab页帧
page页帧,这个就不必多说了,这是物理存储地址,是一个union结构,当被用作slab时,会初始化一下slab管理数据,诸如起始object地址s_mem,lru缓存节点,是否被激活active,关联到的kmem_cache以及freelist空闲对象数组(是一个void*指针,其实存的是char or short数组)。
具体数据结构如下:
struct kmem_cache {
/* 0) per-CPU数据,在每次分配/释放期间都会访问 */
struct array_cache __percpu *cpu_cache; // 每个cpu中的slab对象
/* 1) Cache tunables. Protected by slab_mutex */
unsigned int batchcount; // 当__percpu cpu_cache为空时,从缓存slab中获取的对象数目,它还表示缓存增长时分配的对象数目。初始时为1,后续会调整。
unsigned int limit; // __percpu cpu_cache中的对象数目上限,当slab free达到limit时,需要将array_caches中的部分obj返回到kmem_cache_node的页帧中。
unsigned int shared;
unsigned int size; // slab中的每个对象大小
struct reciprocal_value reciprocal_buffer_size;
/* 2) touched by every alloc & free from the backend */
slab_flags_t flags; /* constant flags */
unsigned int num; /* # of objs per slab */
/* 3) cache_grow/shrink */
/* order of pgs per slab (2^n) */
unsigned int gfporder; // slab关联页数
/* force GFP flags, e.g. GFP_DMA */
gfp_t allocflags;
size_t colour; /* cache colouring range */
unsigned int colour_off; /* colour offset */
struct kmem_cache *freelist_cache; // 空闲对象管理
unsigned int freelist_size; // 空闲对象数量
/* constructor func */
void (*ctor)(void *obj); // 这个在2.6之后已经废弃了
/* 4) cache creation/removal */
const char *name;
struct list_head list;
int refcount;
int object_size;
int align;
/* 5) statistics */
#ifdef CONFIG_DEBUG_SLAB
unsigned long num_active;
unsigned long num_allocations;
unsigned long high_mark;
unsigned long grown;
unsigned long reaped;
unsigned long errors;
unsigned long max_freeable;
unsigned long node_allocs;
unsigned long node_frees;
unsigned long node_overflow;
atomic_t allochit;
atomic_t allocmiss;
atomic_t freehit;
atomic_t freemiss;
#ifdef CONFIG_DEBUG_SLAB_LEAK
atomic_t store_user_clean;
#endif
/*
* If debugging is enabled, then the allocator can add additional
* fields and/or padding to every object. 'size' contains the total
* object size including these internal fields, while 'obj_offset'
* and 'object_size' contain the offset to the user object and its
* size.
*/
int obj_offset;
#endif /* CONFIG_DEBUG_SLAB */
#ifdef CONFIG_MEMCG
struct memcg_cache_params memcg_params;
#endif
#ifdef CONFIG_KASAN
struct kasan_cache kasan_info;
#endif
#ifdef CONFIG_SLAB_FREELIST_RANDOM
unsigned int *random_seq;
#endif
unsigned int useroffset; /* Usercopy region offset */
unsigned int usersize; /* Usercopy region size */
struct kmem_cache_node *node[MAX_NUMNODES]; // 每个内存节点上的slab对象信息,每个node上包括部分空闲,全满以及全部空闲三个队列
};
struct array_cache {
unsigned int avail; // 保存了当前array中的可用数目
unsigned int limit; // 同上
unsigned int batchcount; // 同上
unsigned int touched; // 缓存收缩时置0,缓存移除对象时置1,使得内核能确认在上一次收缩之后是否被访问过
void *entry[]; /*
* Must have this definition in here for the proper
* alignment of array_cache. Also simplifies accessing
* the entries.
*/
};
struct kmem_cache_node {
spinlock_t list_lock;
#ifdef CONFIG_SLAB
struct list_head slabs_partial; /* partial list first, better asm code */
struct list_head slabs_full;
struct list_head slabs_free;
unsigned long total_slabs; /* length of all slab lists */
unsigned long free_slabs; /* length of free slab list only */
unsigned long free_objects;
unsigned int free_limit;
unsigned int colour_next; /* Per-node cache coloring */
struct array_cache *shared; /* shared per node */
struct alien_cache **alien; /* on other nodes */
unsigned long next_reap; /* updated without locking */
int free_touched; /* updated without locking */
#endif
#ifdef CONFIG_SLUB
unsigned long nr_partial;
struct list_head partial;
#ifdef CONFIG_SLUB_DEBUG
atomic_long_t nr_slabs;
atomic_long_t total_objects;
struct list_head full;
#endif
#endif
};
kmalloc
kmalloc的基本调用结构如下:

主要包括两个操作:
- 从kmalloc_caches中获取kmem_cache(kmalloc_cache在slab初始化的时候已经生成好)。
- 通过slab_alloc从kmem_cache中分配一个slab对象,并返回。
具体细节我们后续详细讨论slab_alloc的详细实现。
kfree
kfree最终会调用到___cache_free,具体我们再 slab free中详细讨论。
初始化
内核的大部分管理数据结构都是通过kmalloc分配内存的,那么slab本身结构的内存管理就出现了一个鸡与蛋的问题,slab数据结构所需内存远小于一整页的内存块,这些最适合kmalloc分配,而kmalloc只有在slab初始化完之后才能使用。
所以就需要内核在启动时进行一些初始化操作,让内核在后续的数据结构能够找到对应的kmem_cache对象供kmalloc使用,而这一机制就是之前提到的kmalloc_caches。kernel启动时会先进行slab初始化,slab初始化时会先为kmalloc_caches分配内存,后续slab对象关联的kmem_cache可以从kmalloc_caches中获取,这样slab本身数据结构的内存分配就可以使用了,而这些内存会存在 kmem_cache_boot这个缓存中。
kmem_cache_init是初始化slab分配器的函数,其主要作用就是通过create_kmalloc_caches初始化kmalloc_caches。而kmalloc_caches数组中的kmem_cache对象本身则存储在kmem_cache_boot中,因为kmem_cache对象的大小是固定的,所以只需要一个kmem_cache就可以了,而该函数在start_kernel中被调用进行初始化,create_kmalloc_caches的实现如下:
struct kmem_cache *
kmalloc_caches[NR_KMALLOC_TYPES][KMALLOC_SHIFT_HIGH + 1] __ro_after_init;
EXPORT_SYMBOL(kmalloc_caches); /* [zone][index] */
/*
* Initialisation. Called after the page allocator have been initialised and
* before smp_init().
*/
void __init kmem_cache_init(void)
{
int I;
kmem_cache = &kmem_cache_boot;
if (!IS_ENABLED(CONFIG_NUMA) || num_possible_nodes() == 1)
use_alien_caches = 0;
for (i = 0; i < NUM_INIT_LISTS; I++)
kmem_cache_node_init(&init_kmem_cache_node[i]); // 初始化kmem_cache_boot关联的kmem_cache_node,用于管理slab相关数据结构内存分配的实际存储,具体关联是在__kmem_cache_create中调用set_up_node(kmem_cache, CACHE_CACHE);以及如下代码的第5)会兜底关联一次。
/*
* Fragmentation resistance on low memory - only use bigger
* page orders on machines with more than 32MB of memory if
* not overridden on the command line.
*/
if (!slab_max_order_set && totalram_pages() > (32 << 20) >> PAGE_SHIFT)
slab_max_order = SLAB_MAX_ORDER_HI; // 设置slab每次申请的最大伙伴页帧
/* Bootstrap is tricky, because several objects are allocated
* from caches that do not exist yet:
* 1) initialize the kmem_cache cache: it contains the struct
* kmem_cache structures of all caches, except kmem_cache itself:
* kmem_cache is statically allocated.
* Initially an __init data area is used for the head array and the
* kmem_cache_node structures, it's replaced with a kmalloc allocated
* array at the end of the bootstrap.
* 2) Create the first kmalloc cache.
* The struct kmem_cache for the new cache is allocated normally.
* An __init data area is used for the head array.
* 3) Create the remaining kmalloc caches, with minimally sized
* head arrays.
* 4) Replace the __init data head arrays for kmem_cache and the first
* kmalloc cache with kmalloc allocated arrays.
* 5) Replace the __init data for kmem_cache_node for kmem_cache and
* the other cache's with kmalloc allocated memory.
* 6) Resize the head arrays of the kmalloc caches to their final sizes.
*/
/* 1) create the kmem_cache */
/*
* struct kmem_cache size depends on nr_node_ids & nr_cpu_ids
*/
create_boot_cache(kmem_cache, "kmem_cache",
offsetof(struct kmem_cache, node) +
nr_node_ids * sizeof(struct kmem_cache_node *),
SLAB_HWCACHE_ALIGN, 0, 0);
list_add(&kmem_cache->list, &slab_caches);
memcg_link_cache(kmem_cache);
slab_state = PARTIAL;
/*
* Initialize the caches that provide memory for the kmem_cache_node
* structures first. Without this, further allocations will bug.
*/
kmalloc_caches[KMALLOC_NORMAL][INDEX_NODE] = create_kmalloc_cache(
kmalloc_info[INDEX_NODE].name,
kmalloc_size(INDEX_NODE), ARCH_KMALLOC_FLAGS,
0, kmalloc_size(INDEX_NODE));
slab_state = PARTIAL_NODE;
setup_kmalloc_cache_index_table();
slab_early_init = 0;
/* 5) Replace the bootstrap kmem_cache_node */
{
int nid;
for_each_online_node(nid) {
init_list(kmem_cache, &init_kmem_cache_node[CACHE_CACHE + nid], nid);
init_list(kmalloc_caches[KMALLOC_NORMAL][INDEX_NODE],
&init_kmem_cache_node[SIZE_NODE + nid], nid);
}
}
create_kmalloc_caches(ARCH_KMALLOC_FLAGS);
}
/*
* Create the kmalloc array. Some of the regular kmalloc arrays
* may already have been created because they were needed to
* enable allocations for slab creation.
*/
void __init create_kmalloc_caches(slab_flags_t flags)
{
int i, type;
// 从zone及size两个维度初始化kmalloc_caches
for (type = KMALLOC_NORMAL; type <= 6 7 kmalloc_reclaim; type++) { for (i="KMALLOC_SHIFT_LOW;" i <="KMALLOC_SHIFT_HIGH;" i++) if (!kmalloc_caches[type][i]) new_kmalloc_cache(i, type, flags); * caches that are not of the two-to-the-power-of size. these have to be created immediately after earlier power two (kmalloc_min_size && !kmalloc_caches[type][1]) new_kmalloc_cache(1, !kmalloc_caches[type][2]) new_kmalloc_cache(2, } kmalloc array is now usable slab_state="UP;" #ifdef config_zone_dma struct kmem_cache *s="kmalloc_caches[KMALLOC_NORMAL][i];" (s) unsigned int size="kmalloc_size(i);" const char *n="kmalloc_cache_name("dma-kmalloc"," size); bug_on(!n); kmalloc_caches[kmalloc_dma][i]="create_kmalloc_cache(" n, size, slab_cache_dma | flags, 0, 0); #endif static void __init new_kmalloc_cache(int idx, slab_flags_t flags) *name; (type="=" kmalloc_reclaim) flags name="kmalloc_cache_name("kmalloc-rcl"," kmalloc_info[idx].size); bug_on(!name); else kmalloc_caches[type][idx]="create_kmalloc_cache(name," kmalloc_info[idx].size, internal cache description objs kmem_cache_boot="{" .batchcount="1," .limit="BOOT_CPUCACHE_ENTRIES," .shared="1," .size="sizeof(struct" kmem_cache), .name="kmem_cache" , }; 通过kmem_cache_zalloc分配对象内存(分配指定大小的内存,并填充为0字节) 然后通过create_boot_cache填充数据 *__init create_kmalloc_cache(const *name, useroffset, usersize) gfp_nowait); (!s) panic("out memory when creating slab %s\n", name); create_boot_cache(s, name, usersize); 最终会调用到__kmem_cache_create初始化kmem_cache中的数据,这一块在后续的缓存创建中详细介绍。 list_add(&s->list, &slab_caches);
memcg_link_cache(s);
s->refcount = 1;
return s;
}
</=>
基本调用关系图如下:

slab 初始化主要是为了初始化kmem_cache_boot及kmalloc_caches数组,方便后续内核核心代码使用kmalloc,而不需要额外管理slab内存数据结构,这样slab本身的数据结构内存申请就可以直接使用上kmalloc了。 kmem_cache相关数据都是由kmem_cache_boot管理的,kmalloc调用时使用的kmem_cache都是在初始化时已经创建好的kmalloc_caches中的kmem_cache缓存对象,上述__kmem_cache_create就是创建kmem_cache对象的关键函数,这个我们在后续slab create中详细介绍。
在介绍slab 初始化的时候有提到__kmem_cache_create。其实kmem_cache_create最终也是通过__kmem_cache_create来初始化kmem_cache相关变量,具体调用关系图如下:
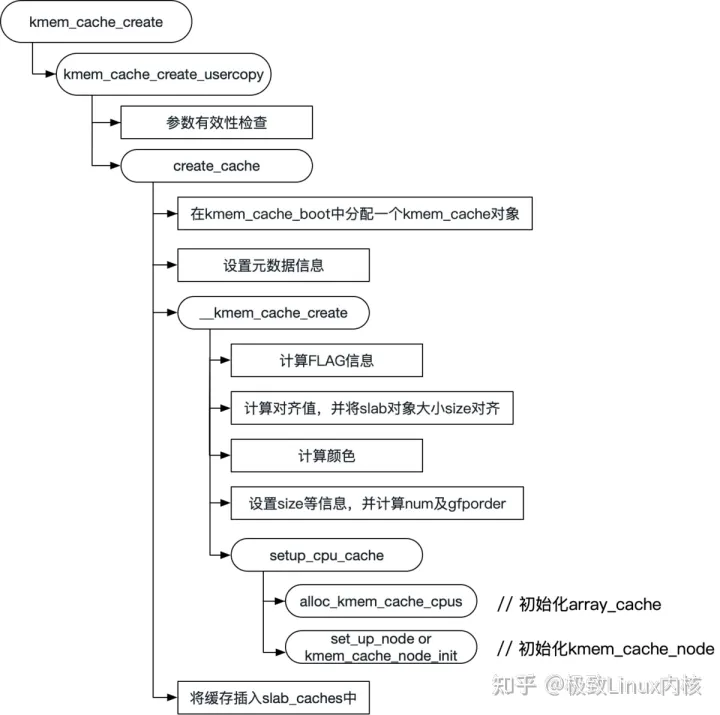
slab create的主要目的就是初始化一个kmem_cache缓存对象中的起始值,主要包括:batchcount,size,align,useroffset,usersize,flags,colour,num,gfporder等等。但是这里有特别需要注意的是:batchcount及limit在create的时候是设为1,且并没有分配相应的页帧来存储slab对象,这些都需要在slab alloc发现没有可用对象时进行grow分配。
slab create根据需要被管理的对象size,计算kmem_cache_node中管理的伙伴页帧阶gfporder大小,我们把这样一个伙伴页帧叫做slab,通过slab中的页数以及对象size就可以计算出一个slab中能存储的对象数量num = ((PAGE_SIZE << gfporder) – head) / size 下取整。
代码如下:
/**
* __kmem_cache_create - Create a cache.
* @cachep: cache management descriptor
* @flags: SLAB flags
*
* Returns a ptr to the cache on success, NULL on failure.
* Cannot be called within a int, but can be interrupted.
* The @ctor is run when new pages are allocated by the cache.
*
* The flags are
*
* %SLAB_POISON - Poison the slab with a known test pattern (a5a5a5a5)
* to catch references to uninitialised memory.
*
* %SLAB_RED_ZONE - Insert `Red' zones around the allocated memory to check
* for buffer overruns.
*
* %SLAB_HWCACHE_ALIGN - Align the objects in this cache to a hardware
* cacheline. This can be beneficial if you're counting cycles as closely
* as davem.
*/
int __kmem_cache_create(struct kmem_cache *cachep, slab_flags_t flags)
{
size_t ralign = BYTES_PER_WORD; // 按字对齐
gfp_t gfp;
int err;
unsigned int size = cachep->size;
... // debug info
/*
* Check that size is in terms of words. This is needed to avoid
* unaligned accesses for some archs when redzoning is used, and makes
* sure any on-slab bufctl's are also correctly aligned.
*/
size = ALIGN(size, BYTES_PER_WORD);
if (flags & SLAB_RED_ZONE) {
ralign = REDZONE_ALIGN;
/* If redzoning, ensure that the second redzone is suitably
* aligned, by adjusting the object size accordingly. */
// 危险区,在每个对象开始和结束处添加已知字节模式,方便程序员debug发现不正确的访问
size = ALIGN(size, REDZONE_ALIGN);
}
/* 3) caller mandated alignment */
if (ralign < cachep->align) {
ralign = cachep->align;
}
/* disable debug if necessary */
if (ralign > __alignof__(unsigned long long))
flags &= ~(SLAB_RED_ZONE | SLAB_STORE_USER);
/*
* 4) Store it.
*/
cachep->align = ralign;
cachep->colour_off = cache_line_size();
/* Offset must be a multiple of the alignment. */
if (cachep->colour_off < cachep->align)
cachep->colour_off = cachep->align;
if (slab_is_available())
gfp = GFP_KERNEL;
else
gfp = GFP_NOWAIT;
... // debug info
kasan_cache_create(cachep, &size, &flags);
size = ALIGN(size, cachep->align);
/*
* We should restrict the number of objects in a slab to implement
* byte sized index. Refer comment on SLAB_OBJ_MIN_SIZE definition.
*/
if (FREELIST_BYTE_INDEX && size < SLAB_OBJ_MIN_SIZE)
size = ALIGN(SLAB_OBJ_MIN_SIZE, cachep->align);
... // debug info
if (set_objfreelist_slab_cache(cachep, size, flags)) { // 计算gfporder and num
flags |= CFLGS_OBJFREELIST_SLAB;
goto done;
}
if (set_off_slab_cache(cachep, size, flags)) { // 计算gfporder and num
flags |= CFLGS_OFF_SLAB;
goto done;
}
if (set_on_slab_cache(cachep, size, flags)) // 计算gfporder and num
goto done;
return -E2BIG;
done:
cachep->freelist_size = cachep->num * sizeof(freelist_idx_t);
cachep->flags = flags;
cachep->allocflags = __GFP_COMP;
if (flags & SLAB_CACHE_DMA)
cachep->allocflags |= GFP_DMA;
if (flags & SLAB_CACHE_DMA32)
cachep->allocflags |= GFP_DMA32;
if (flags & SLAB_RECLAIM_ACCOUNT)
cachep->allocflags |= __GFP_RECLAIMABLE;
cachep->size = size;
cachep->reciprocal_buffer_size = reciprocal_value(size);
#if DEBUG
/*
* If we're going to use the generic kernel_map_pages()
* poisoning, then it's going to smash the contents of
* the redzone and userword anyhow, so switch them off.
*/
if (IS_ENABLED(CONFIG_PAGE_POISONING) &&
(cachep->flags & SLAB_POISON) &&
is_debug_pagealloc_cache(cachep))
cachep->flags &= ~(SLAB_RED_ZONE | SLAB_STORE_USER);
#endif
if (OFF_SLAB(cachep)) {
cachep->freelist_cache =
kmalloc_slab(cachep->freelist_size, 0u);
}
err = setup_cpu_cache(cachep, gfp); // 初始化array_caches及 kmem_cache_node
if (err) {
__kmem_cache_release(cachep);
return err;
}
return 0;
}
static int __ref setup_cpu_cache(struct kmem_cache *cachep, gfp_t gfp)
{
if (slab_state >= FULL)
return enable_cpucache(cachep, gfp);
cachep->cpu_cache = alloc_kmem_cache_cpus(cachep, 1, 1);
if (!cachep->cpu_cache)
return 1;
/* init kmem_cache_node*/
if (slab_state == DOWN) {
/* Creation of first cache (kmem_cache). */
set_up_node(kmem_cache, CACHE_CACHE);
} else if (slab_state == PARTIAL) {
/* For kmem_cache_node */
set_up_node(cachep, SIZE_NODE);
} else {
int node;
for_each_online_node(node) {
cachep->node[node] = kmalloc_node(
sizeof(struct kmem_cache_node), gfp, node);
BUG_ON(!cachep->node[node]);
kmem_cache_node_init(cachep->node[node]);
}
}
cachep->node[numa_mem_id()]->next_reap =
jiffies + REAPTIMEOUT_NODE +
((unsigned long)cachep) % REAPTIMEOUT_NODE;
/* init array_caches*/
cpu_cache_get(cachep)->avail = 0;
cpu_cache_get(cachep)->limit = BOOT_CPUCACHE_ENTRIES;
cpu_cache_get(cachep)->batchcount = 1;
cpu_cache_get(cachep)->touched = 0;
cachep->batchcount = 1;
cachep->limit = BOOT_CPUCACHE_ENTRIES;
return 0;
}
这里需要特别单独说一下的是kmalloc_node,这是分配kmem_cache_node的关键函数,相关函数调用如下:

相关代码如下:
static __always_inline void *kmalloc_node(size_t size, gfp_t flags, int node)
{
... // slob 先不考虑
return __kmalloc_node(size, flags, node);
}
void *__kmalloc_node(size_t size, gfp_t flags, int node)
{
return __do_kmalloc_node(size, flags, node, _RET_IP_);
}
static __always_inline void *
__do_kmalloc_node(size_t size, gfp_t flags, int node, unsigned long caller)
{
struct kmem_cache *cachep;
void *ret;
if (unlikely(size > KMALLOC_MAX_CACHE_SIZE))
return NULL;
cachep = kmalloc_slab(size, flags);
if (unlikely(ZERO_OR_NULL_PTR(cachep)))
return cachep;
ret = kmem_cache_alloc_node_trace(cachep, flags, node, size);
ret = kasan_kmalloc(cachep, ret, size, flags);
return ret;
}
void *kmem_cache_alloc_node_trace(struct kmem_cache *cachep,
gfp_t flags,
int nodeid,
size_t size)
{
void *ret;
ret = slab_alloc_node(cachep, flags, nodeid, _RET_IP_);
ret = kasan_kmalloc(cachep, ret, size, flags);
trace_kmalloc_node(_RET_IP_, ret,
size, cachep->size,
flags, nodeid);
return ret;
}
static __always_inline void *
slab_alloc_node(struct kmem_cache *cachep, gfp_t flags, int nodeid,
unsigned long caller)
{
unsigned long save_flags;
void *ptr;
int slab_node = numa_mem_id();
/* 参数及相关环境检查*/
flags &= gfp_allowed_mask;
cachep = slab_pre_alloc_hook(cachep, flags);
if (unlikely(!cachep))
return NULL;
cache_alloc_debugcheck_before(cachep, flags);
local_irq_save(save_flags);
if (nodeid == NUMA_NO_NODE)
nodeid = slab_node;
if (unlikely(!get_node(cachep, nodeid))) {
/* Node not bootstrapped yet */
ptr = fallback_alloc(cachep, flags);
goto out;
}
if (nodeid == slab_node) {
/*
* Use the locally cached objects if possible.
* However ____cache_alloc does not allow fallback
* to other nodes. It may fail while we still have
* objects on other nodes available.
*/
ptr = ____cache_alloc(cachep, flags); // 从本地array_cache中直接分配对应的slab obj去存储kmem_cache_node
if (ptr)
goto out;
}
/* ___cache_alloc_node can fall back to other nodes */
ptr = ____cache_alloc_node(cachep, flags, nodeid);
out:
local_irq_restore(save_flags);
ptr = cache_alloc_debugcheck_after(cachep, flags, ptr, caller);
if (unlikely(flags & __GFP_ZERO) && ptr)
memset(ptr, 0, cachep->object_size);
slab_post_alloc_hook(cachep, flags, 1, &ptr);
return ptr;
}
/*
* A interface to enable slab creation on nodeid
*/
static void *____cache_alloc_node(struct kmem_cache *cachep, gfp_t flags,
int nodeid)
{
struct page *page;
struct kmem_cache_node *n;
void *obj = NULL;
void *list = NULL;
VM_BUG_ON(nodeid < 0 || nodeid >= MAX_NUMNODES);
n = get_node(cachep, nodeid);
BUG_ON(!n);
check_irq_off();
spin_lock(&n->list_lock);
page = get_first_slab(n, false);
if (!page)
goto must_grow;
check_spinlock_acquired_node(cachep, nodeid);
STATS_INC_NODEALLOCS(cachep);
STATS_INC_ACTIVE(cachep);
STATS_SET_HIGH(cachep);
BUG_ON(page->active == cachep->num);
obj = slab_get_obj(cachep, page);
n->free_objects--;
fixup_slab_list(cachep, n, page, &list);
spin_unlock(&n->list_lock);
fixup_objfreelist_debug(cachep, &list);
return obj;
must_grow:
spin_unlock(&n->list_lock);
page = cache_grow_begin(cachep, gfp_exact_node(flags), nodeid);
if (page) {
/* This slab isn't counted yet so don't update free_objects */
obj = slab_get_obj(cachep, page);
}
cache_grow_end(cachep, page);
return obj ? obj : fallback_alloc(cachep, flags);
}
从上面的代码发现slab本身的管理对象也由slab对象直接管理。
slab alloc
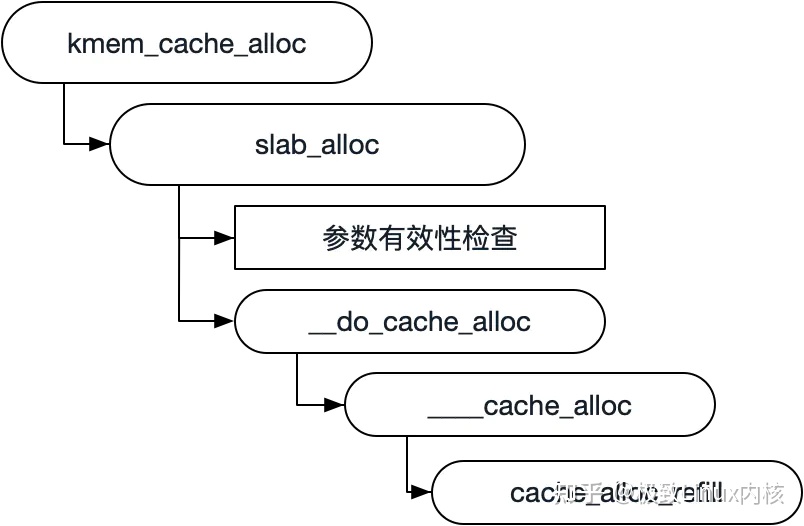
slab alloc的基本过程如下,最终会调用到____cache_alloc,如果在array_cache中能够找到的话,就直接返回否则通过cache_alloc_refill重新填充array_cache中的空闲对象。
相关代码如下:
static inline void *____cache_alloc(struct kmem_cache *cachep, gfp_t flags)
{
void *objp;
struct array_cache *ac;
check_irq_off();
ac = cpu_cache_get(cachep);
if (likely(ac->avail)) {
ac->touched = 1;
objp = ac->entry[--ac->avail];
STATS_INC_ALLOCHIT(cachep);
goto out;
}
STATS_INC_ALLOCMISS(cachep);
objp = cache_alloc_refill(cachep, flags);
/*
* the 'ac' may be updated by cache_alloc_refill(),
* and kmemleak_erase() requires its correct value.
*/
ac = cpu_cache_get(cachep);
out:
/*
* To avoid a false negative, if an object that is in one of the
* per-CPU caches is leaked, we need to make sure kmemleak doesn't
* treat the array pointers as a reference to the object.
*/
if (objp)
kmemleak_erase(&ac->entry[ac->avail]);
return objp;
}
static void *cache_alloc_refill(struct kmem_cache *cachep, gfp_t flags)
{
int batchcount;
struct kmem_cache_node *n;
struct array_cache *ac, *shared;
int node;
void *list = NULL;
struct page *page;
check_irq_off();
node = numa_mem_id();
ac = cpu_cache_get(cachep);
batchcount = ac->batchcount;
if (!ac->touched && batchcount > BATCHREFILL_LIMIT) {
/*
* If there was little recent activity on this cache, then
* perform only a partial refill. Otherwise we could generate
* refill bouncing.
*/
batchcount = BATCHREFILL_LIMIT; // 16
}
n = get_node(cachep, node);
BUG_ON(ac->avail > 0 || !n);
shared = READ_ONCE(n->shared);
if (!n->free_objects && (!shared || !shared->avail))
goto direct_grow;
spin_lock(&n->list_lock);
shared = READ_ONCE(n->shared);
/* See if we can refill from the shared array */
if (shared && transfer_objects(ac, shared, batchcount)) {
shared->touched = 1;
goto alloc_done;
}
while (batchcount > 0) {
/* Get slab alloc is to come from. */
page = get_first_slab(n, false);
if (!page)
goto must_grow;
check_spinlock_acquired(cachep);
batchcount = alloc_block(cachep, ac, page, batchcount);
fixup_slab_list(cachep, n, page, &list);
}
must_grow:
n->free_objects -= ac->avail;
alloc_done:
spin_unlock(&n->list_lock);
fixup_objfreelist_debug(cachep, &list);
direct_grow:
if (unlikely(!ac->avail)) {
/* Check if we can use obj in pfmemalloc slab */
if (sk_memalloc_socks()) {
void *obj = cache_alloc_pfmemalloc(cachep, n, flags);
if (obj)
return obj;
}
page = cache_grow_begin(cachep, gfp_exact_node(flags), node); // 分配一个gfporder伙伴页帧,并初始化伙伴页帧中的freelist
/*
* cache_grow_begin() can reenable interrupts,
* then ac could change.
*/
ac = cpu_cache_get(cachep);
if (!ac->avail && page)
alloc_block(cachep, ac, page, batchcount);
cache_grow_end(cachep, page);// 将新申请的伙伴页帧加入到kmem_cache_node中的free或者partial或者full列表中
if (!ac->avail)
return NULL;
}
ac->touched = 1;
return ac->entry[--ac->avail];
}
static struct page *get_first_slab(struct kmem_cache_node *n, bool pfmemalloc)
{
struct page *page;
assert_spin_locked(&n->list_lock);
page = list_first_entry_or_null(&n->slabs_partial, struct page, lru); // 尝试获取部分空闲的page
if (!page) {
n->free_touched = 1;
page = list_first_entry_or_null(&n->slabs_free, struct page, lru); // 尝试获取全部空闲的page
if (page)
n->free_slabs--;
}
if (sk_memalloc_socks()) // 这种优化方案目前不知道是怎么搞的
page = get_valid_first_slab(n, page, pfmemalloc);
return page;
}
/*
* Grow (by 1) the number of slabs within a cache. This is called by
* kmem_cache_alloc() when there are no active objs left in a cache.
*/
static struct page *cache_grow_begin(struct kmem_cache *cachep,
gfp_t flags, int nodeid)
{
...
/*
* Be lazy and only check for valid flags here, keeping it out of the
* critical path in kmem_cache_alloc().
*/
...
/*
* Get mem for the objs. Attempt to allocate a physical page from
* 'nodeid'.
*/
page = kmem_getpages(cachep, local_flags, nodeid); // 在对应的内存节点通过伙伴系统分配一个gfporder的连续页
if (!page)
goto failed;
page_node = page_to_nid(page);
n = get_node(cachep, page_node);
/* Get colour for the slab, and cal the next value. */
... // 着色
/*
* Call kasan_poison_slab() before calling alloc_slabmgmt(), so
* page_address() in the latter returns a non-tagged pointer,
* as it should be for slab pages.
*/
kasan_poison_slab(page); // 毒化,在建立和释放slab时,易于感知未授权访问
/* Get slab management. */
freelist = alloc_slabmgmt(cachep, page, offset,
local_flags & ~GFP_CONSTRAINT_MASK, page_node); // 获取第一个空闲对象地址,一般来说是在指定offset(着色偏移)之后的地址。
if (OFF_SLAB(cachep) && !freelist)
goto opps1;
slab_map_pages(cachep, page, freelist); // 初始化page slab信息
cache_init_objs(cachep, page); // 将页帧中所有slab对象起始地址随机打散到freelist列表中,
if (gfpflags_allow_blocking(local_flags))
local_irq_disable();
return page;
opps1:
kmem_freepages(cachep, page);
failed:
if (gfpflags_allow_blocking(local_flags))
local_irq_disable();
return NULL;
}
static void cache_init_objs(struct kmem_cache *cachep,
struct page *page)
{
int I;
void *objp;
bool shuffled;
cache_init_objs_debug(cachep, page);
/* Try to randomize the freelist if enabled */
shuffled = shuffle_freelist(cachep, page);
if (!shuffled && OBJFREELIST_SLAB(cachep)) {
page->freelist = index_to_obj(cachep, page, cachep->num - 1) +
obj_offset(cachep);
}
for (i = 0; i < cachep->num; i++) {
objp = index_to_obj(cachep, page, i);
objp = kasan_init_slab_obj(cachep, objp);
/* constructor could break poison info */
if (DEBUG == 0 && cachep->ctor) {
kasan_unpoison_object_data(cachep, objp);
cachep->ctor(objp);
kasan_poison_object_data(cachep, objp);
}
if (!shuffled)
set_free_obj(page, i, i);
}
}
/*
* Shuffle the freelist initialization state based on pre-computed lists.
* return true if the list was successfully shuffled, false otherwise.
*/
static bool shuffle_freelist(struct kmem_cache *cachep, struct page *page)
{
unsigned int objfreelist = 0, i, rand, count = cachep->num;
union freelist_init_state state;
bool precomputed;
if (count < 2)
return false;
precomputed = freelist_state_initialize(&state, cachep, count);
/* Take a random entry as the objfreelist */
if (OBJFREELIST_SLAB(cachep)) {
if (!precomputed)
objfreelist = count - 1;
else
objfreelist = next_random_slot(&state);
page->freelist = index_to_obj(cachep, page, objfreelist) +
obj_offset(cachep);
count--;
}
/*
* On early boot, generate the list dynamically.
* Later use a pre-computed list for speed.
*/
if (!precomputed) {
for (i = 0; i < count; I++)
set_free_obj(page, i, i);
/* Fisher-Yates shuffle */
for (i = count - 1; i > 0; i--) {
rand = prandom_u32_state(&state.rnd_state);
rand %= (i + 1);
swap_free_obj(page, i, rand);
}
} else {
for (i = 0; i < count; I++)
set_free_obj(page, i, next_random_slot(&state));
}
if (OBJFREELIST_SLAB(cachep))
set_free_obj(page, cachep->num - 1, objfreelist);
return true;
}
最终slab对象分配情况如下图:(起始freelist在实际场景中是随意的交叉错乱指向任意一块slab对象,不会像下面这样整齐)
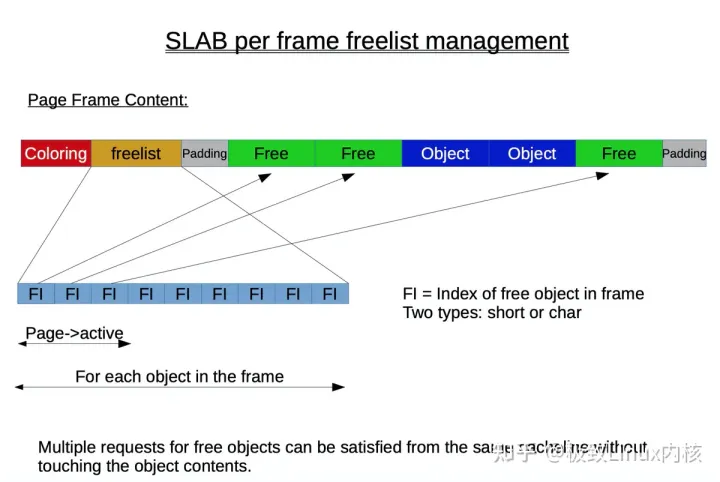
结合之前的slab data struct图,应该基本就对slab alloc有个比较清晰的理解了。
slab free
kmem_cache_free函数时释放slab对象的一个主要入口,函数调用图如下:

slab free
相关代码如下:
void ___cache_free(struct kmem_cache *cachep, void *objp,
unsigned long caller)
{
struct array_cache *ac = cpu_cache_get(cachep);
check_irq_off();
kmemleak_free_recursive(objp, cachep->flags);
objp = cache_free_debugcheck(cachep, objp, caller);
/*
* Skip calling cache_free_alien() when the platform is not numa.
* This will avoid cache misses that happen while accessing slabp (which
* is per page memory reference) to get nodeid. Instead use a global
* variable to skip the call, which is mostly likely to be present in
* the cache.
*/
if (nr_online_nodes > 1 && cache_free_alien(cachep, objp))
return;
if (ac->avail < ac->limit) {
STATS_INC_FREEHIT(cachep);
} else {
STATS_INC_FREEMISS(cachep);
cache_flusharray(cachep, ac); // 超出了array_caches limit,需要收缩
}
if (sk_memalloc_socks()) {
struct page *page = virt_to_head_page(objp);
if (unlikely(PageSlabPfmemalloc(page))) {
cache_free_pfmemalloc(cachep, page, objp);
return;
}
}
ac->entry[ac->avail++] = objp;
}
static void cache_flusharray(struct kmem_cache *cachep, struct array_cache *ac)
{
int batchcount;
struct kmem_cache_node *n;
int node = numa_mem_id();
LIST_HEAD(list);
batchcount = ac->batchcount;
check_irq_off();
n = get_node(cachep, node);
spin_lock(&n->list_lock);
if (n->shared) { // 优先放回shared区
struct array_cache *shared_array = n->shared;
int max = shared_array->limit - shared_array->avail;
if (max) {
if (batchcount > max)
batchcount = max;
memcpy(&(shared_array->entry[shared_array->avail]),
ac->entry, sizeof(void *) * batchcount);
shared_array->avail += batchcount;
goto free_done;
}
}
free_block(cachep, ac->entry, batchcount, node, &list); // 否则只能放回到kmem_cache_node的页帧中,并将可被回收的pages放到list链表中
free_done:
#if STATS
{
int i = 0;
struct page *page;
list_for_each_entry(page, &n->slabs_free, lru) {
BUG_ON(page->active);
I++;
}
STATS_SET_FREEABLE(cachep, i);
}
#endif
spin_unlock(&n->list_lock);
slabs_destroy(cachep, &list); // 将可回收的页帧释放回伙伴系统
ac->avail -= batchcount;
memmove(ac->entry, &(ac->entry[batchcount]), sizeof(void *)*ac->avail);
}
总结
简而言之,slab缓存的基本思想如下:
内核使用slab分配器时,主要包括两个步骤:
- 通过kmem_cache_create创建一个缓存。
- 通过kmem_cache_alloc在指定缓存中申请一个slab对象。
细分描述如下:
- 通过kmem_cache_create(size, flags)函数创建一个缓存对象,根据size计算缓存的gfporder,从而可以知道每次新分配管理页帧的数量,也就可以计算一个kmem_cache_node页帧中能管理的slab对象数目num。
- 当通过kmem_cache_create(*cachep, flags)函数申请slab对象分配时,首先查找cachep->array_caches[curr_cpu]中是否有可用空闲对象,有则直接返回,没有则执行步骤3。
- 从kmem_cache_node中一次导入batchcount数量的空闲对象到array_caches,导入规则是,先选择部分空闲页帧,然后是全部空闲页帧,将内存中对象装载到array_cache中,当没有可用页帧时执行grow,跳入步骤4,否则跳入步骤6。
- 通过伙伴系统申请2^gfporder数量的页,并初始化slab头部信息及空闲列表信息,就每个空闲对象的起始地址随机打散到page->freelist数组中,这样每次分配时指向的地址会比较随机。并将该页帧伙伴放入kmem_cache_node->slab_free中。
- 继续像步骤3一样继续装载空闲对象到array_cache,直至batchcount为0后跳入步骤6。
6.返回array_cache->entry[–array_cache->avail];
具体可以结合slab data struct图一起看,应该会有一个比较清晰的整体感观。
slab coloring:
在深入理解linux内核架构原文中,是这么描述的: 如果数据存储在伙伴系统直接提供的页中,那么其地址总是出现在2的幂次的整数倍附近。这对CPU高速缓存的利用有负面影响,由于这种地址分布,使得某些缓存行过度使用,而其他的则几乎为空。通过slab着色(slab coloring),slab分配器能够均匀的分布对象,以实现均匀的缓存利用,在看了slab coloring的实现原理后我百思不得其解,为啥通过对页内slab对象加一个偏移就可以让缓存命中均匀了呢,通过翻阅大量资料发现,其实这个slab coloring 好像并没有什么卵用。
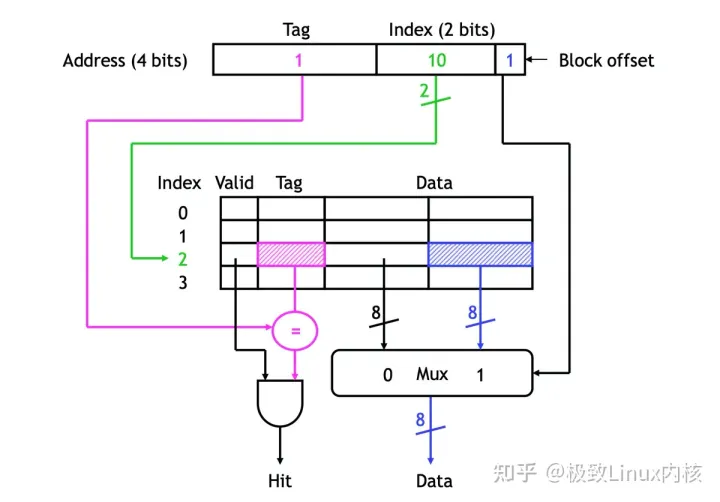
要理解slab着色并不能让缓存利用更均匀,首先得对cpu cache有一定了解:cpu cache将cache划分成固定大小的cache line,一般来说一个cache line的大小为64Byte,然后将cache line与内存地址映射。cpu cache目前主要有三种映射:1、直接映射;2、全相连映射;3、组相连映射。缓存行由三个部分组成 valid,tag,data;其中valid表示该缓存行中数据是否有效,tag用于判断对应cach行存储的确实是目标地址,data则是缓存行具体的64Byte数据。
我们以32位物理内存地址,1MB cache,64Byte cache line系统为例:
那么该系统缓存地址有20位(2^20 = 1MB),其中低6位用于定位缓存行内数据,高14位用于定位缓存行,而我们的物理内存地址有32位,那么同一缓存行中可能存储2^12种不同地址,所以就需要一个12位的TAG来确定缓存中存储的确实是指定物理地址的数据。比如0x000XXX和0x001XXX都会命中同一缓存行,而通过TAG中存储的值来确认存储的是0x000XXX还是0x001XXX的数据。
具体过程如下:
而缓存行的定位跟缓存与物理地址映射有关:
直接映射

直接映射中cache地址与内存地址是固定好的映射关系;因此可能会存在某些行过热的情况出现(某些倍数地址临时访问频繁,这种情况在大数据处理中很常见,hash shuffle的时候有时候很容易出现长尾)。
全相连映射
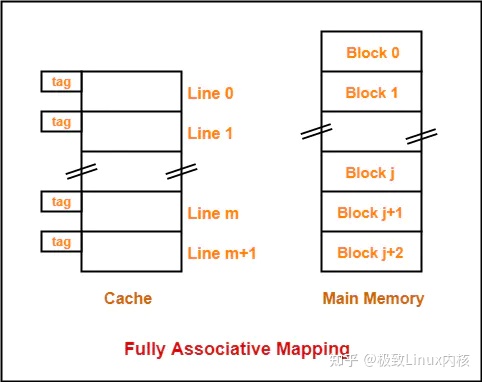
全相连映射中,每一个内存块可以随意的映射到任意一个cache line,由于可以随意映射,所以每次访问的时候要匹配每个cache line的tag来确认是否是对应的物理地址。
组相连映射

组相连映射是直接映射和全相连映射的折中,组间直接映射,组内全相连映射,这样一定程度上可以缓解热点问题,又能避免对比太多TAG。
经过上面的分析,对于CPU hardware cache有了大致的了解。那么slab coloring这种偏移页内一个cache line的做法对于避免缓存行有什么帮助呢?看上去并没有什么太多用,看下面的分析:
比如一个slab A分配的page起始地址为0X00000000,另一个slab B分配的page起始地址为0X00002000,cache的大小为1MB,每个缓存行大小为64Byte,一共有16384行。那么slab A对应的缓存行为0~63行,而slab B对应的缓存行为128~191行,他们本来就不会命中到同一缓存行,你页内再怎么偏移也没有任何关系。即使如果两个slab对应的page会命中到同一缓存行,页内的偏移也看上去不会有什么不同的改善,是不是?反而 组相连可以比较好的解决相同命中时的冲突问题。
但是仔细想一想kmem_cache_node中的slab页帧结构你会发现,如果没有着色偏移的话,那么每次对应的缓存行一般都是从一个固定值开始的,假如我们忽略slab head的大小,每次slab对象都从页的起始位置开始分配,由于slab对象与cache line 一般来说是不等的,那么每次映射的缓存行一般是0 ~ 61或者0 ~ 62这种,所以62,63这种缓存行就会有较低访问概率,所以就需要这个着色偏移, 让首尾缓存访问的概率趋于相同
Original: https://blog.csdn.net/m0_74282605/article/details/127819805
Author: Linux加油站
Title: 深入linux内核架构–slab分配器(建议收藏)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/657123/
转载文章受原作者版权保护。转载请注明原作者出处!