

系列文章目录
第1章 绪论
第2章 机器学习概述
第3章 线性模型
第4章 前馈神经网络
第5章 卷积神经网络
第6章 循环神经网络
第7章 网络优化与正则化
第8章 注意力机制与外部记忆
第9章 无监督学习
第10章 模型独立的学习方式
第11章 概率图模型
第12章 深度信念网络
第13章 深度生成模型
第14章 深度强化学习
第15章 序列生成模型
文章目录
- 系列文章目录
- 前言
- 4.1 神经元
* - 4.1.1 神经元
- 4.1.2 激活函数的性质
- 4.1.3 常用的激活函数
- 4.1.4 常见激活函数及其导数
- 4.2 神经网络
* - 4.2.1 人工神经网络
- 4.2.2 网络结构
- 4.3前馈神经网络
* - 4.3.1 前馈网络结构
- 4.3.2 信息传递过程
- 4.3.3 深层前馈神经网络
- 4.3.4通用近似定理
- 4.3.5 应用到机器学习
- 4.3.6 参数学习
- 4.4 计算梯度的方法
* - 4.4.1反向传播算法
– - 4.4.2 计算图与自动微分
- 4.5 优化问题
* - 4.5.1 难点
- 4.5.2 需求
- 总结
前言
本文对前馈神经网络进行了一个简要介绍。
4.1 神经元
4.1.1 神经元
生物神经元:


人工神经元:

; 4.1.2 激活函数的性质
- 连续并可导(允许少数点上不可导)的非线性函数。
可导的激活函数可以直接利用数值优化的方法来学习网络参数。 - 激活函数及其导函数要尽可能的简单
有利于提高网络计算效率。 - 激活函数的导函数的值域要在一个合适的区间内
不能太大也不能太小,否则会影响训练的效率和稳定性。
4.1.3 常用的激活函数
Logistic函数与Tanh函数
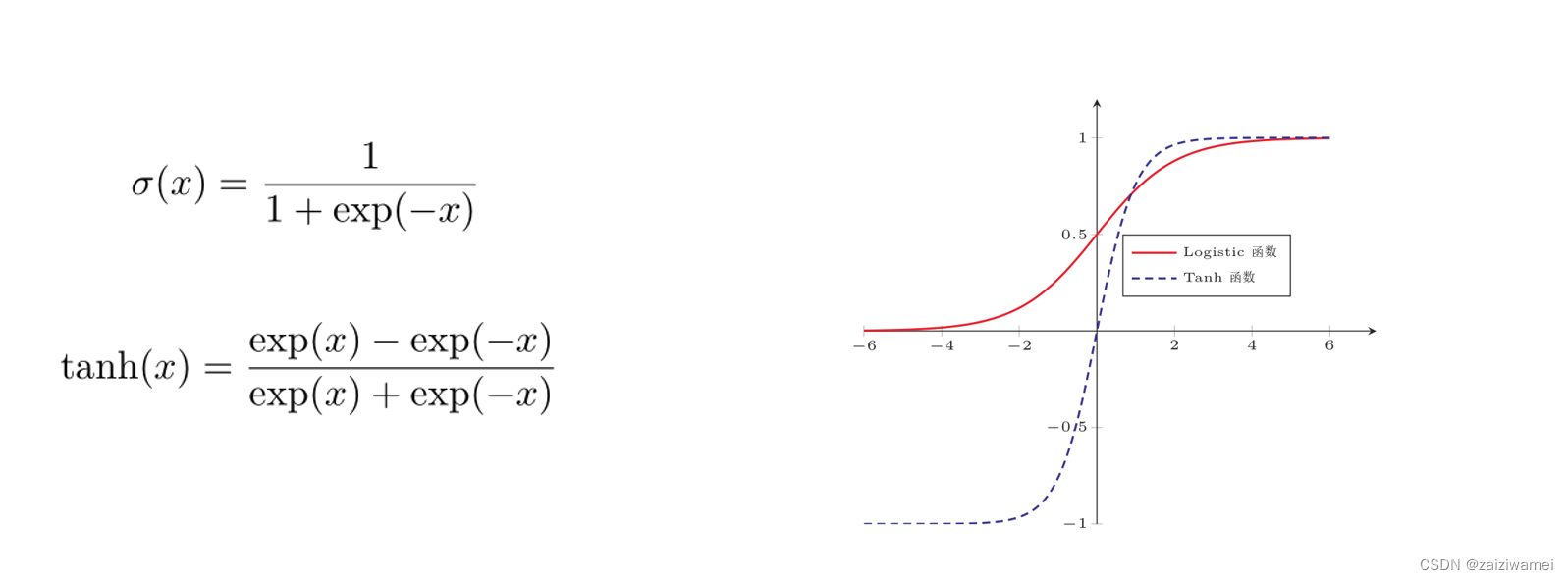
性质:
- 饱和函数:函数两边都趋近于固定值
- Tanh函数是零中心化的,而logistic函数的输出恒大于0
非零中心化的输出会使得其后一层的神经元的输入发生偏置偏移(bias shift),并进一步使得梯度下降的收敛速度变慢。
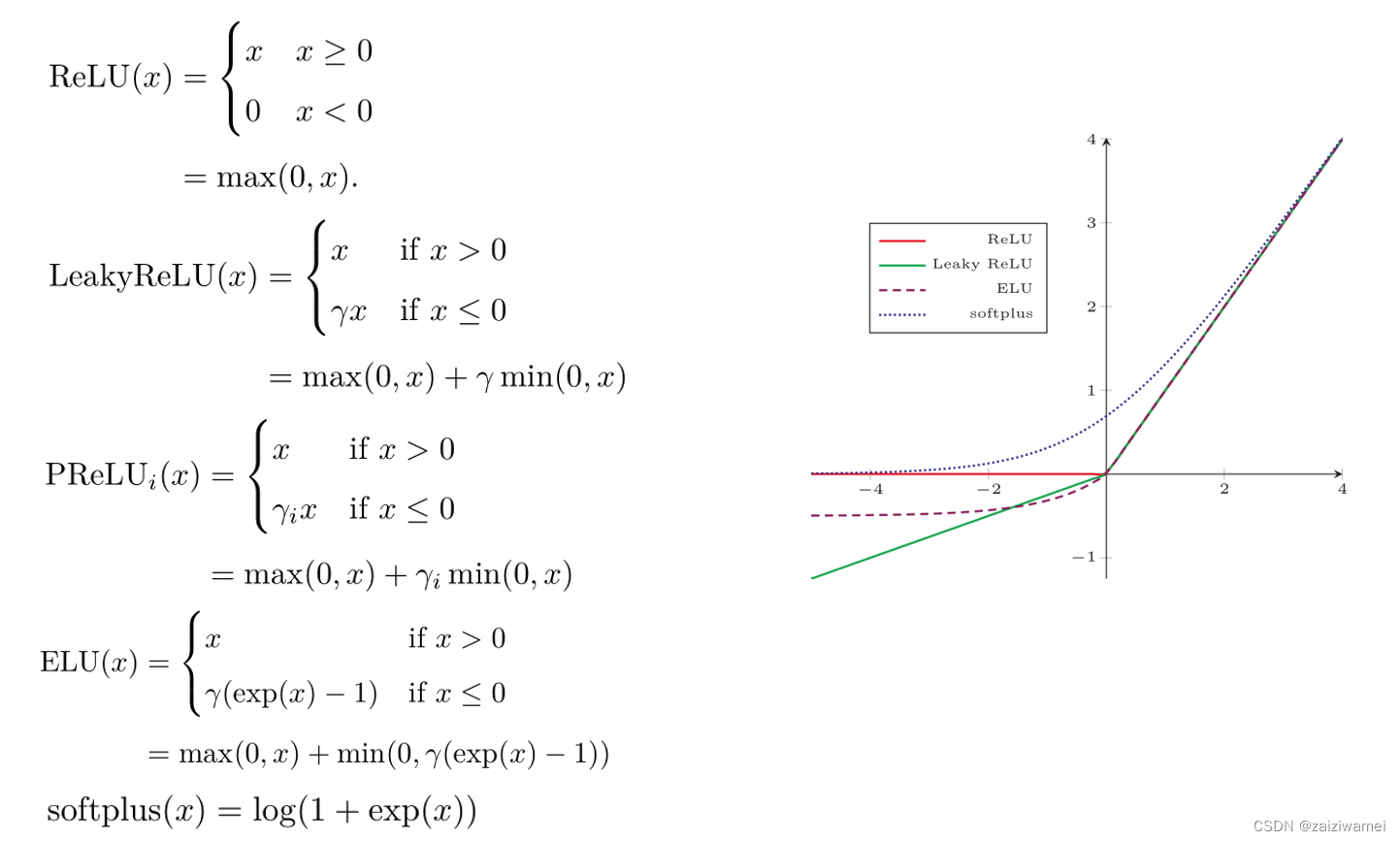
特点:
- 计算上更加高效
- 生物学合理性
单侧抑制、宽兴奋边界 - 在一定程度上缓解梯度消失问题
- *但无法进行梯度传播
Swish函数:

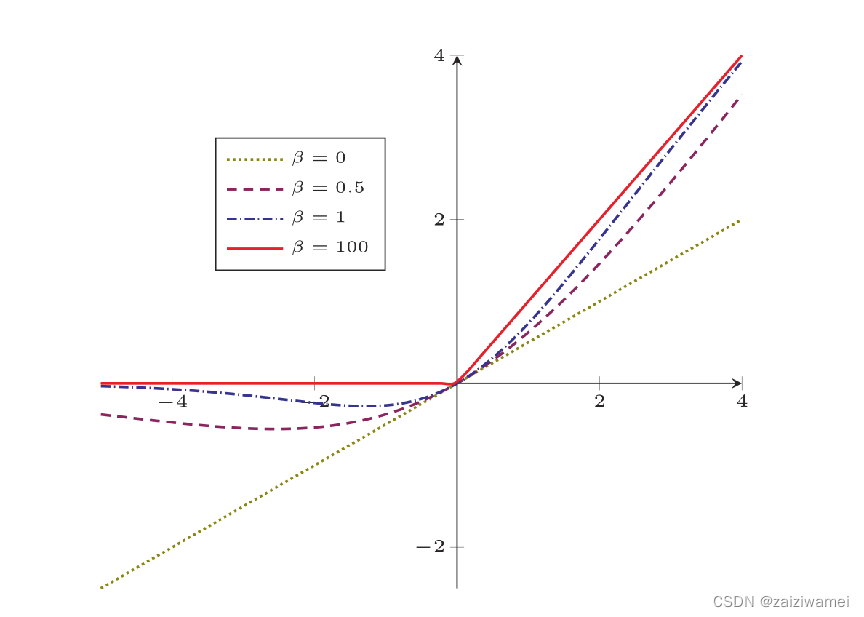
高斯误差线性单元
(Gaussian Error Linear Unit,GELU)

其中P(X ≤ x)是高斯分布N(µ,σ 2 )的累积分布函数,其中µ,σ为超参数,一般设µ = 0,σ = 1即可。
由于高斯分布的累积分布函数为S型函数,因此GELU可以用Tanh函数或Logistic函数来近似:

; 4.1.4 常见激活函数及其导数

4.2 神经网络
4.2.1 人工神经网络
神经元的激活规则:
主要是指神经元输入到输出之间的映射关系,一般为非线性函数。
网络的拓扑结构:
不同神经元之间的连接关系。
学习算法:
通过训练数据来学习神经网络的参数。
4.2.2 网络结构
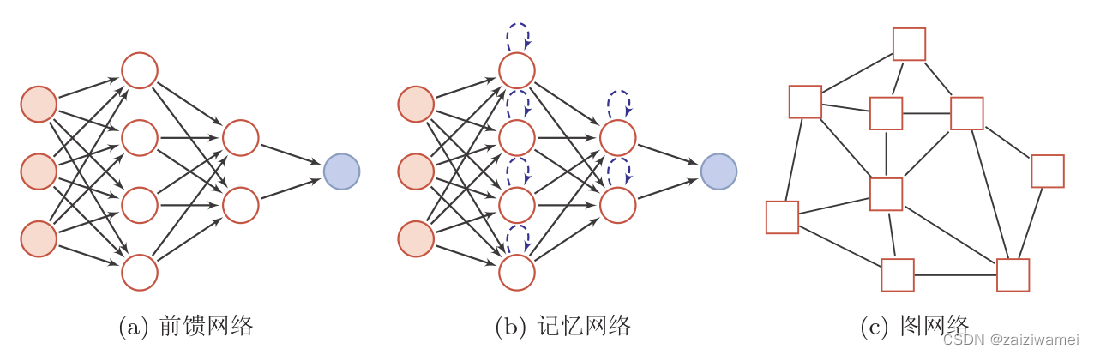
注:圆形节点表示一个神经元,方形节点表示一组神经元。
; 4.3前馈神经网络
4.3.1 前馈网络结构

给定一个前馈神经网络,用下面的记号来描述这样网络:

; 4.3.2 信息传递过程
前馈神经网络通过下面公式进行信息传播:

前馈计算:
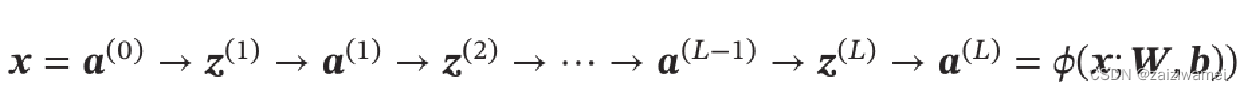
4.3.3 深层前馈神经网络

; 4.3.4通用近似定理

根据通用近似定理,对于具有线性输出层和至少一个使用”挤压”性质的激活函数的隐藏层组成的前馈神经网络,只要其隐藏层神经元的数量足够,它可以以任意的精度来近似任何从一个定义在实数空间中的有界闭集函数。
4.3.5 应用到机器学习
应用到机器学习
神经网络可以作为一个”万能”函数来使用,可以用来进行复杂的特征转换,或逼近一个复杂的条件分布。

如果g(⋅)为Logistic回归,那么Logistic回归分类器可以看成神经网络的最后一层。
对于多分类问题
如果使用Softmax回归分类器,相当于网络最后一层设置C 个神经元,其输出经过Softmax函数进行归一化后可以作为每个类的条件概率。

采用交叉熵损失函数,对于样本(x,y),其损失函数为

; 4.3.6 参数学习
参数学习
给定训练集为D = { ( x ( n ) , y ( n ) ) } n = 1 N D={(x^{(n)},y^{(n)})}^N_{n=1}D ={(x (n ),y (n ))}n =1 N ,将每个样本x ( n ) x^{(n)}x (n )入给前馈神经网络,得到网络输出为 y ^ ( n ) \hat y^{(n)}y ^(n ),其在数据集D上的结构化风险函数为:


4.4 计算梯度的方法
矩阵微分
矩阵微积分(Matrix Calculus)是多元微积分的一种表达方式,即使用矩阵和向量来表示因变量每个成分关于自变量每个成分的偏导数。
分母布局的矩阵微分
标量关于向量的偏导数

向量关于向量的偏导数

链式法则

矩阵微分的链式法则

注:本文的链式法则是由右向左列出分布求导的公式。
; 4.4.1反向传播算法
4.4.1.1反向传播算法的推导过程

分别计算以上三个偏导数:






从公式(4.63)可以看出,第𝑙 层的误差项可以通过第𝑙 + 1层的误差项计算得到,这就是误差的反向传播(BackPropagation,BP)。
反向传播算法的含义:
第 𝑙 层的一个神经元的误差项(或敏感性)是所有与该神经元相连的第 𝑙 + 1 层的神经元的误差项的权重和.然后,再乘上该神经元激活函数的梯度。
; 4.4.1.2反向传播算法的推训练过程

4.4.2 计算图与自动微分
自动微分含义:
自动微分是利用链式法则来自动计算一个复合函数的梯度。

计算图:

计算图计算流程:
- 绘制计算图


- 带值计算
当x = 1,w = 0,b = 0时,可以得到:

自动微分 - 前向模式:在正向传播计算结果的同时计算每一层的梯度并保存起来。
- 反向模式:先进行正向传播,计算出所有层的结果,再反向传播计算出每一层的梯度并保存起来。
- 如果函数和参数之间有多条路径,可以将这多条路径上的导数再进行相加,得到最终的梯度。
反向传播算法 (自动微分的反向模式)的流程
- 前向计算每一层的状态和激活值,直到最后一层;
- 反向计算每一层的参数的偏导数;
- 更新参数。
静态计算图和动态计算图
- 静态计算图是在编译时构建计算图,计算图构建好之后在程序运行时不能改变。
常用框架为:Theano和Tensorflow - 静态计算图是在编译时构建计算图,计算图构建好之后在程序运行时不能改变。
常用框架为:DyNet,Chainer和PyTorch - 静态计算图在构建时可以进行优化,并行能力强,但灵活性比较差低。动态计算图则不容易优化,当不同输入的网络结构不一致时,难以并行计算,但是灵活性比较高。
深度学习的三个步骤

; 4.5 优化问题
4.5.1 难点
- 参数过多,影响训练
- 非凸优化问题:即存在局部最优而非全局最优解,影响迭代 梯度消失问题。
- 下层参数比较难调 参数解释起来比较困难
减少层数,选择合理的激活函数(其导数在1附近) - 梯度爆炸或梯度消失
选取合理的激活函数
4.5.2 需求
- 计算资源要大
- 数据要多
- 算法效率要好:即收敛快
总结
Original: https://blog.csdn.net/qq_40940944/article/details/127791596
Author: zaiziwamei
Title: 第4章 前馈神经网络
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/656176/
转载文章受原作者版权保护。转载请注明原作者出处!