

文章目录
- 0. 前言
- 1. 开散列
* - 1.1 开散列概念
- 2. 开散列的代码实现
* - 2.0 定义
- 2.1 插入实现–Insert
- 2.2 查找实现–Find
- 2.3 删除实现–Erase
- 2.4 仿函数
- 3. 完整代码实现
-
前言
-
我们上一章我们了解了哈希表闭散列线性探测实现方法
链接:哈希表闭散列线性探测实现 -
这一章我们谈谈哈希表开散列实现。
-
开散列
1.1 开散列概念
- 开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
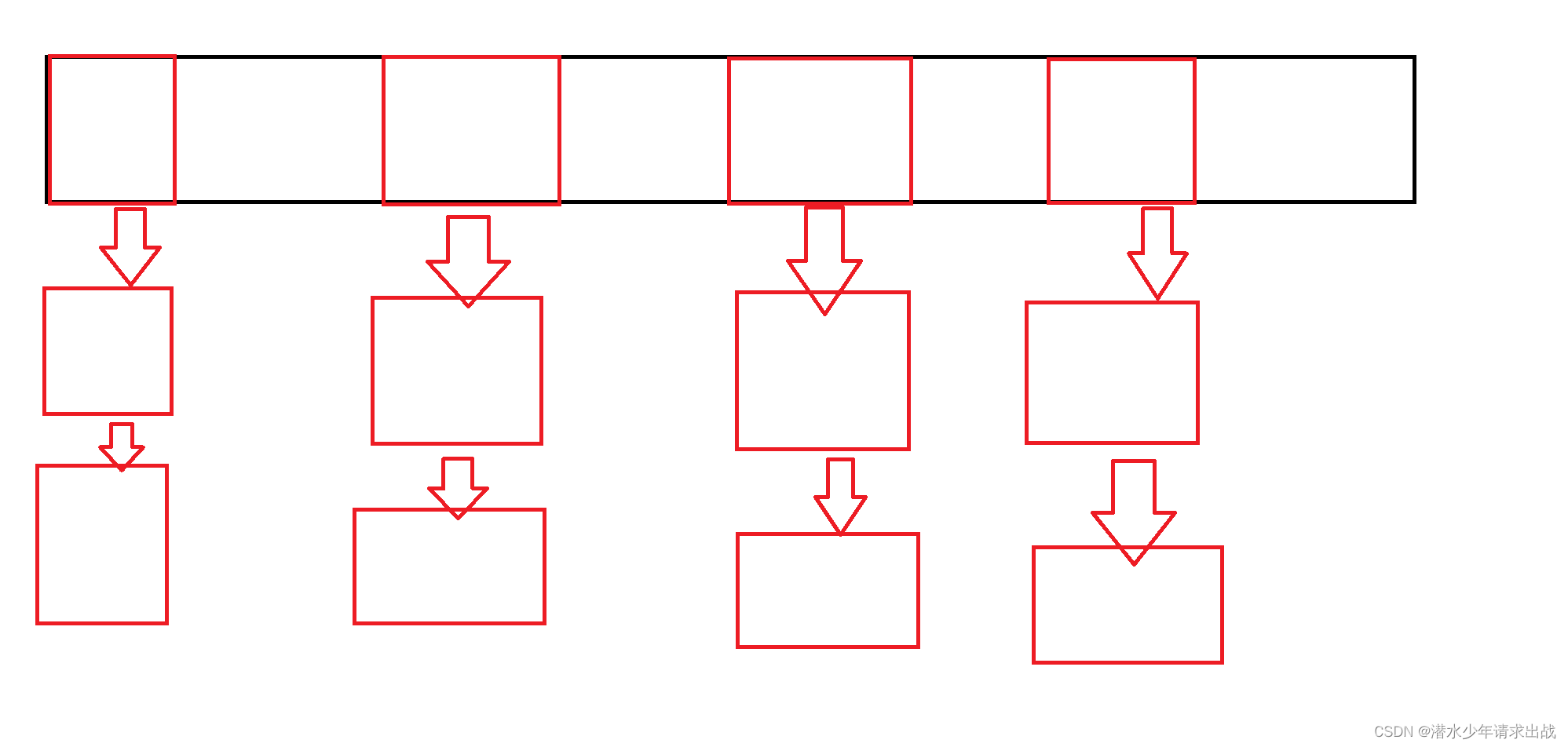

表中每个位置的元素像桶一样挂起来。
- 从上图可以看出, 开散列中每个桶中放的都是发生哈希冲突的元素。
- 上一章我们了解了哈希表闭散列线性探测冲突时往后找空位置填写,这样就会导致 空间利用率比较低。
; 2. 开散列的代码实现
2.0 定义
- 一张表中需要桶挂起来,我们就需要节点。
template<class K, class V>
struct HashNode
{
pair<K, V> _kv;
HashNode<K, V>* _next;
HashNode(const pair<K, V>& kv)
:_kv(kv)
,_next(nullptr)
{}
};
2.1 插入实现–Insert
- 插入的时候我们选择头插。
- 原因:
- 我们采用的是单链表头插效率高。
- 扩容方法:
- 这一次我们不能像哈希表闭散列线性探测复用的方尺扩容,可能里面一些节点后来就不冲突了,所以我们手动扩容;不过这些节点是可以再次利用的~。
- 桶的个数是一定的,随着元素的不断插入,每个桶中元素的个数不断增多,极端情况下,可能会导致一个桶中链表节点非常多,会影响的哈希表的性能 。扩容条件是负载因子到达也就是 *元素个数刚好等于桶的个数时,可以给哈希表增容。
具体实现代码如下:
bool Insert(const pair<K, V>& kv)
{
if (Find(kv.first))
{
return false;
}
if (_tables.size() == _size)
{
size_t newSize = _tables.size() == 0 ? 10 : 2 * _tables.size();
vector<Node*> newTables;
newTables.resize(newSize, nullptr);
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;
size_t hashi = cur->_kv.first % newTables.size();
cur->_next = newTables[hashi];
newTables[hashi] = cur;
cur = next;
}
_tables[i] = nullptr;
}
_tables.swap(newTables);
}
size_t hashi = kv.first % _tables.size();
Node* newNode = new Node(kv);
newNode->_next = _tables[hashi];
_tables[hashi] = newNode;
++_size;
return true;
}
- 这个时候uu们就会疑惑,为什么小丁实现的扩容跟库里面的思路不一样?库里面以素数作为扩容的大小会提高效率(大佬们研究表明的)
- 我们一起看看库里面怎么实现的~
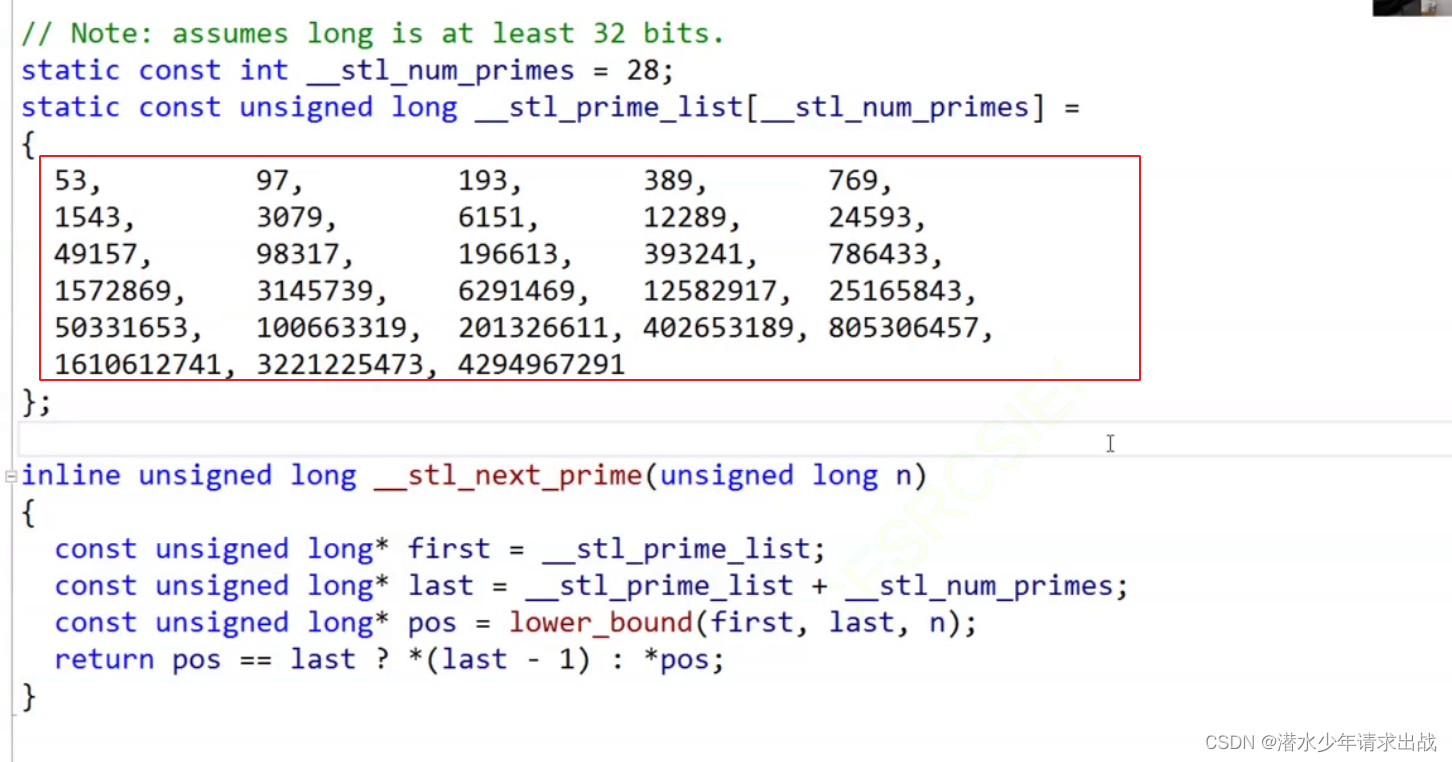
没错使用一个数组把类似二倍扩容的数都包括了;注意不会超出这个范围,超出就溢出来(算了一下走到最后光开空间就浪费了32G这怎么可能?)
加上后的代码如下:
inline size_t __stl_next_prime(size_t n)
{
static const size_t __stl_num_primes = 28;
static const size_t __stl_prime_list[__stl_num_primes] =
{
53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473, 4294967291
};
for (size_t i = 0; i < __stl_num_primes; ++i)
{
if (__stl_prime_list[i] > n)
{
return __stl_prime_list[i];
}
}
return -1;
}
bool Insert(const pair<K, V>& kv)
{
if (Find(kv.first))
{
return false;
}
if (_tables.size() == _size)
{
vector<Node*> newTables;
newTables.resize(__stl_next_prime(_tables.size()), nullptr);
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;
size_t hashi = cur->_kv.first % newTables.size();
cur->_next = newTables[hashi];
newTables[hashi] = cur;
cur = next;
}
_tables[i] = nullptr;
}
_tables.swap(newTables);
}
size_t hashi = kv.first % _tables.size();
Node* newNode = new Node(kv);
newNode->_next = _tables[hashi];
_tables[hashi] = newNode;
++_size;
return true;
}
2.2 查找实现–Find
- 查找思路:通过取模方式找到数值的映射位置(size_t hashi = key % _tables.size();)进行查询即可。
具体实现代码如下:
Node* Find(const K& key)
{
if (_tables.size() == 0)
{
return nullptr;
}
size_t hashi = key % _tables.size();
Node* cur = _tables[hashi];
while (cur)
{
if (cur->_kv.first == key)
{
return cur;
}
cur = cur->_next;
}
return nullptr;
}
2.3 删除实现–Erase
- 删除思路:我们需要prev来记录前一个节点(我们这是单链表)
- 删除情况分为头删和中间删(cur:当前要删除的节点)
- 头删:我们只需把头节点换一下就行了再把cur这个节点释放掉。
- 中间删:我们需要prev指向下一个后再把cur这个节点释放掉。
具体实现代码如下:
bool Erase(const K& key)
{
if (_tables.size() == 0)
{
return false;
}
int hashi = key % _tables.size();
Node* cur = _tables[hashi];
Node* prev = nullptr;
while (cur)
{
if (key == cur->_kv.first)
{
if (prev)
{
prev->_next = cur->_next;
}
else
{
_tables[hashi] = cur->_next;
}
delete cur;
--_size;
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}
2.4 仿函数
- 我们发现我们现在实现的哈希只能存数字,字符串等不行;这个时候我们需要借助仿函数。
- 代码实现思路跟上一章哈希表闭散列线性探测实现的仿函数一样。
不多说了,来看代码吧!
具体实现代码如下:
template<class k>
struct HashFunc
{
size_t operator()(const k& key)
{
return (size_t)key;
}
};
template<>
struct HashFunc<string>
{
size_t operator()(const string& s)
{
size_t val = 0;
for (const auto ch : s)
{
val *= 131;
val += ch;
}
return val;
}
};
- 完整代码实现
namespace HashBucket
{
template<class k>
struct HashFunc
{
size_t operator()(const k& key)
{
return (size_t)key;
}
};
template<>
struct HashFunc<string>
{
size_t operator()(const string& s)
{
size_t val = 0;
for (const auto ch : s)
{
val *= 131;
val += ch;
}
return val;
}
};
template<class K, class V>
struct HashNode
{
pair<K, V> _kv;
HashNode<K, V>* _next;
HashNode(const pair<K, V>& kv)
:_kv(kv)
,_next(nullptr)
{}
};
template<class K, class V, class Hash = HashFunc<K>>
class HashTable
{
typedef HashNode<K, V> Node;
public:
~HashTable()
{
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
_tables[i] = nullptr;
}
}
inline size_t __stl_next_prime(size_t n)
{
static const size_t __stl_num_primes = 28;
static const size_t __stl_prime_list[__stl_num_primes] =
{
53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473, 4294967291
};
for (size_t i = 0; i < __stl_num_primes; ++i)
{
if (__stl_prime_list[i] > n)
{
return __stl_prime_list[i];
}
}
return -1;
}
bool Insert(const pair<K, V>& kv)
{
if (Find(kv.first))
{
return false;
}
Hash hash;
if (_tables.size() == _size)
{
vector<Node*> newTables;
newTables.resize(__stl_next_prime(_tables.size()), nullptr);
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;
size_t hashi = hash(cur->_kv.first) % newTables.size();
cur->_next = newTables[hashi];
newTables[hashi] = cur;
cur = next;
}
_tables[i] = nullptr;
}
_tables.swap(newTables);
}
size_t hashi = hash(kv.first) % _tables.size();
Node* newNode = new Node(kv);
newNode->_next = _tables[hashi];
_tables[hashi] = newNode;
++_size;
return true;
}
Node* Find(const K& key)
{
if (Empty())
{
return nullptr;
}
Hash hash;
size_t hashi = hash(key) % _tables.size();
Node* cur = _tables[hashi];
while (cur)
{
if (cur->_kv.first == key)
{
return cur;
}
cur = cur->_next;
}
return nullptr;
}
bool Empty() const
{
return _size == 0;
}
bool Erase(const K& key)
{
if (Empty())
{
return false;
}
Hash hash;
int hashi = hash(key) % _tables.size();
Node* cur = _tables[hashi];
Node* prev = nullptr;
while (cur)
{
if (key == cur->_kv.first)
{
if (prev)
{
prev->_next = cur->_next;
}
else
{
_tables[hashi] = cur->_next;
}
delete cur;
--_size;
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}
size_t Size()
{
return _size;
}
size_t TablesSize()
{
return _tables.size();
}
size_t BucketNum()
{
size_t num = 0;
for (size_t i = 0; i < _tables.size(); ++i)
{
if (_tables[i])
{
++num;
}
}
return num;
}
size_t MaxBucketLenth()
{
size_t maxLen = 0;
for (size_t i = 0; i < _tables.size(); ++i)
{
size_t len = 0;
Node* cur = _tables[i];
while (cur)
{
++len;
cur = cur->_next;
}
if (len > maxLen)
{
maxLen = len;
}
}
return maxLen;
}
private:
vector<Node*> _tables;
size_t _size = 0;
};
void TestHT1()
{
int a[] = { 1, 11, 4, 15, 26, 7, 44,55,99,78, 4 };
HashTable<int, int> ht;
for (auto e : a)
{
ht.Insert(make_pair(e, e));
}
ht.Insert(make_pair(22, 22));
}
void TestHT2()
{
string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };
HashTable<string, int> countHT;
for (auto& str : arr)
{
auto ptr = countHT.Find(str);
if (ptr)
{
ptr->_kv.second++;
}
else
{
countHT.Insert(make_pair(str, 1));
}
}
}
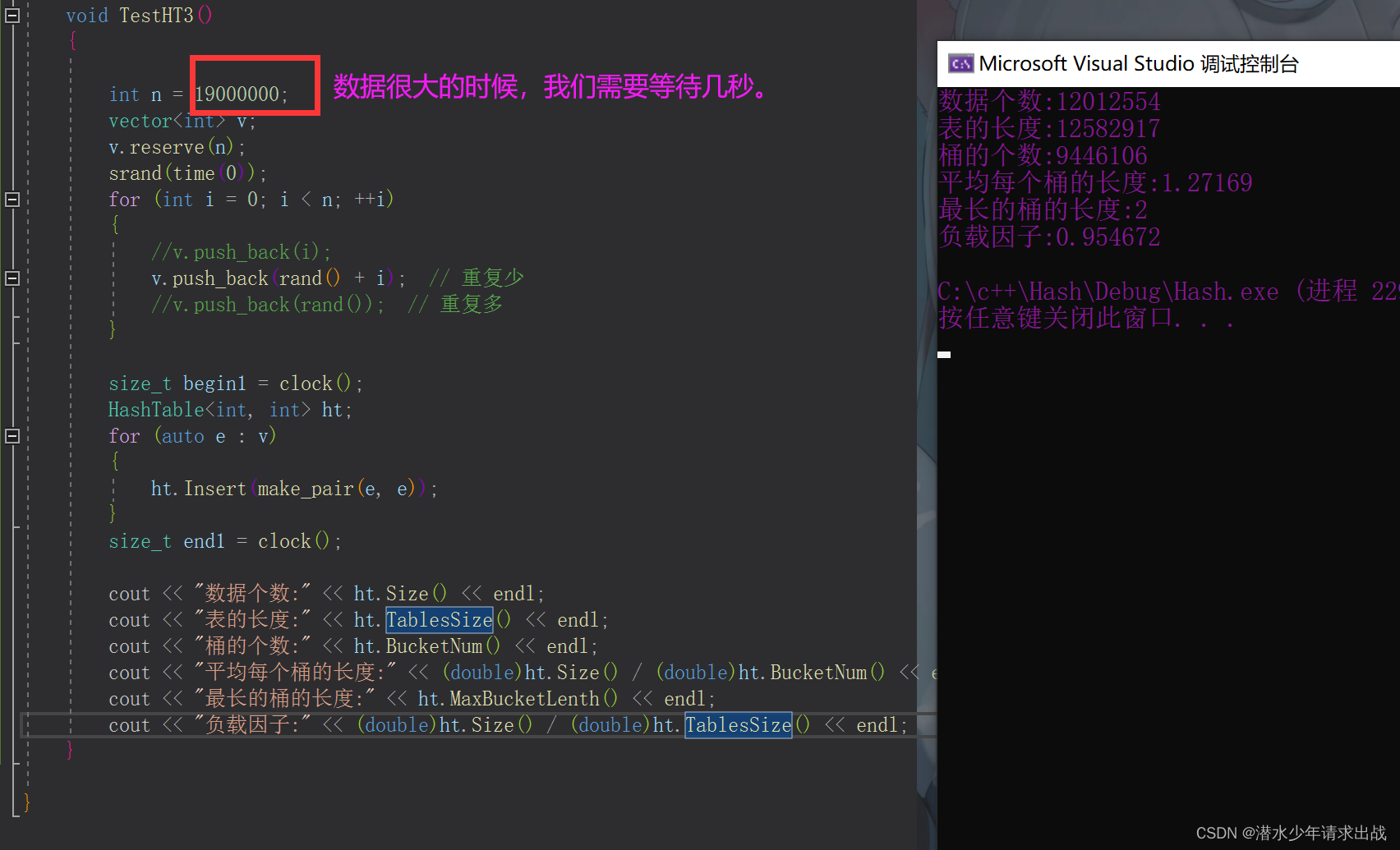
void TestHT3()
{
int n = 19000000;
vector<int> v;
v.reserve(n);
srand(time(0));
for (int i = 0; i < n; ++i)
{
v.push_back(rand() + i);
}
size_t begin1 = clock();
HashTable<int, int> ht;
for (auto e : v)
{
ht.Insert(make_pair(e, e));
}
size_t end1 = clock();
cout << "数据个数:" << ht.Size() << endl;
cout << "表的长度:" << ht.TablesSize() << endl;
cout << "桶的个数:" << ht.BucketNum() << endl;
cout << "平均每个桶的长度:" << (double)ht.Size() / (double)ht.BucketNum() << endl;
cout << "最长的桶的长度:" << ht.MaxBucketLenth() << endl;
cout << "负载因子:" << (double)ht.Size() / (double)ht.TablesSize() << endl;
}
}
- 代码测试并运行结果:
Original: https://blog.csdn.net/Dingyuan0/article/details/127810374
Author: 潜水少年请求出战
Title: c++哈希(哈希表开散列实现)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/656142/
转载文章受原作者版权保护。转载请注明原作者出处!