

先总结一下之前的内容
我们学习HTTP,主要是学习HTTP的报文格式
HTTP的报文格式分为两部分,分别是 请求和响应两部分
请求:
(1)首行: 方法 URL 版本号
(2)请求头header:多个键值对,每个键值对独占一行,键和值之间使用:空格来分割
(3)空行:header的结束标记
(4)正文body: 格式多种,常见的是json
响应:
(1)首行: 版本号 状态码 状态码描述
(2)响应头header:多个键值对,每个键值对独占一行,键和值之间使用:空格来分割
(3)空行:header的结束标记
(4)正文body: 格式多种,常见的是json html css js 图片等
我们在前面已经学习了请求的首行中的 URL和方法
URL
(1)ip + 端口
(2)带层次的路径
(3)查询字符串 query string
(4)url encode/decode
方法
(1)GET
(2)POST
GET和POST没有本质区别:
1)语义不同:一个表示获取,一个表示提交
2)GET一般把数据放到 query string中,POST通常放在body中
3)GET建议实现成幂等的,POST无要求
4)GET如果是幂等的,那就可以缓存,POST无要求
接下来开始接着往下讲,也就是本文章的主要内容,咱们一个一个来~
认识请求报头(header)
我们知道header部分里的内容都是键值对,这里的键值对,几乎都是由标准规定的,当然也可以我们自己做一些自定义的键值对
咱们下面来认识几个header里面键值对的含义
(1)Host
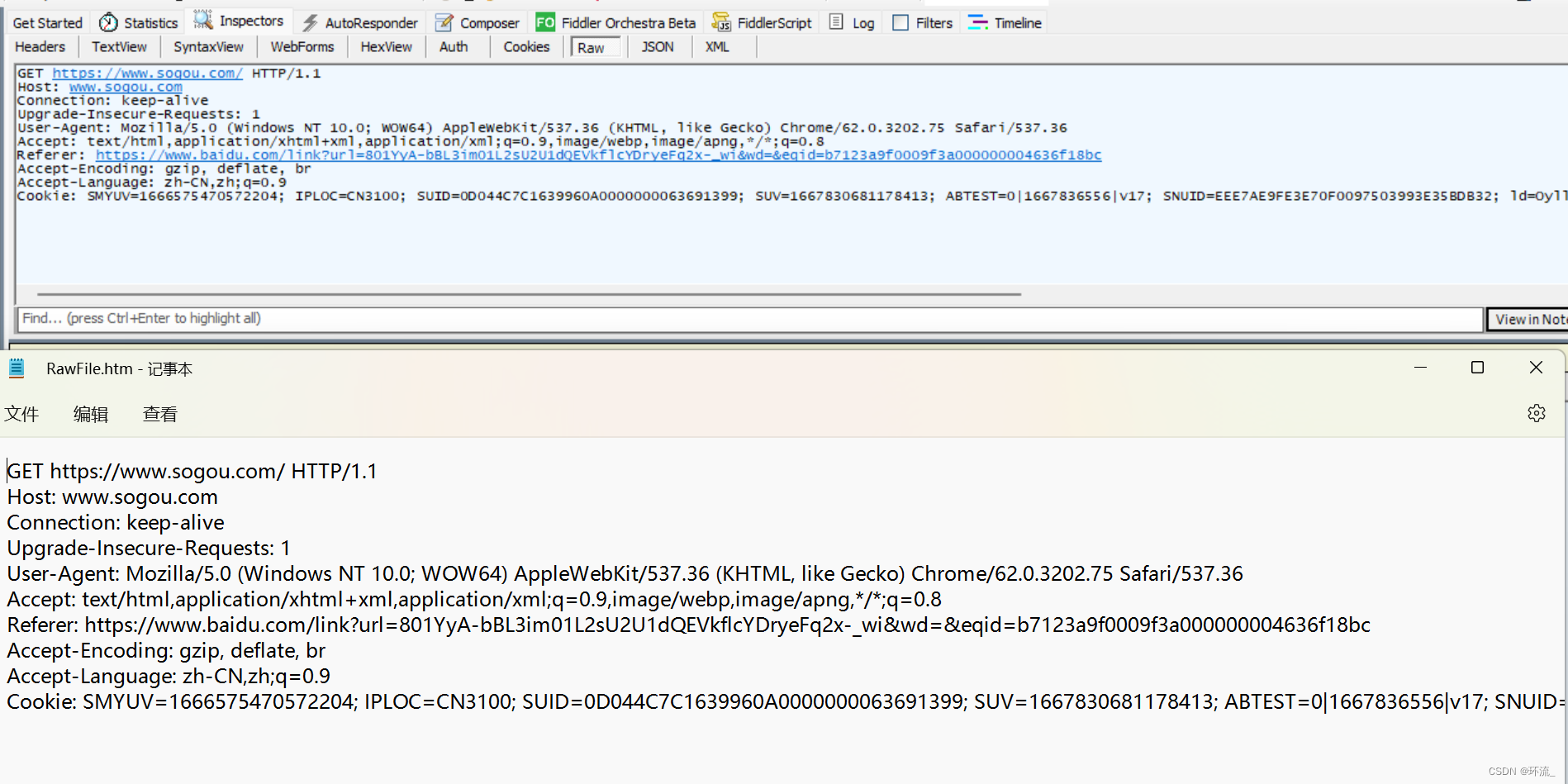

咱们先用抓包工具抓包,我们浏览了搜狗官网,捕获到相关内容,找到Host键值对
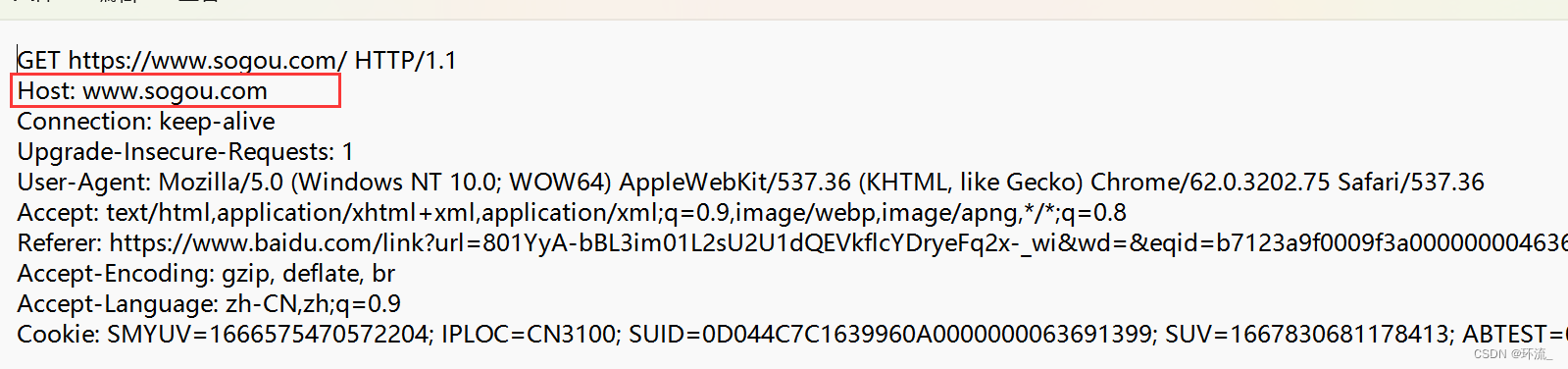
红色框部分就是Host
Host:表示服务区主机的地址和端口(意思就是要去哪里找到服务器)
但目前的Host里面,你只看到了地址,并没有看到端口,那是因为端口被省略了,Host放进去的就是IP+端口,这里的端口被省略后,省略就是默认值,http端口默认值为80,https默认值为443~
这里就产生了一个问题:URL里面不是已经有这个服务器的IP和端口了嘛,为什么还要在Host里面出现?
事实上,URL的IP和端口跟Host的IP和端口是有可能是完全不一样的,为什么这么说呢?
假如你要是通过代理的话,就可能会产生差异(但这个差异在fiddler没体现出来而已)
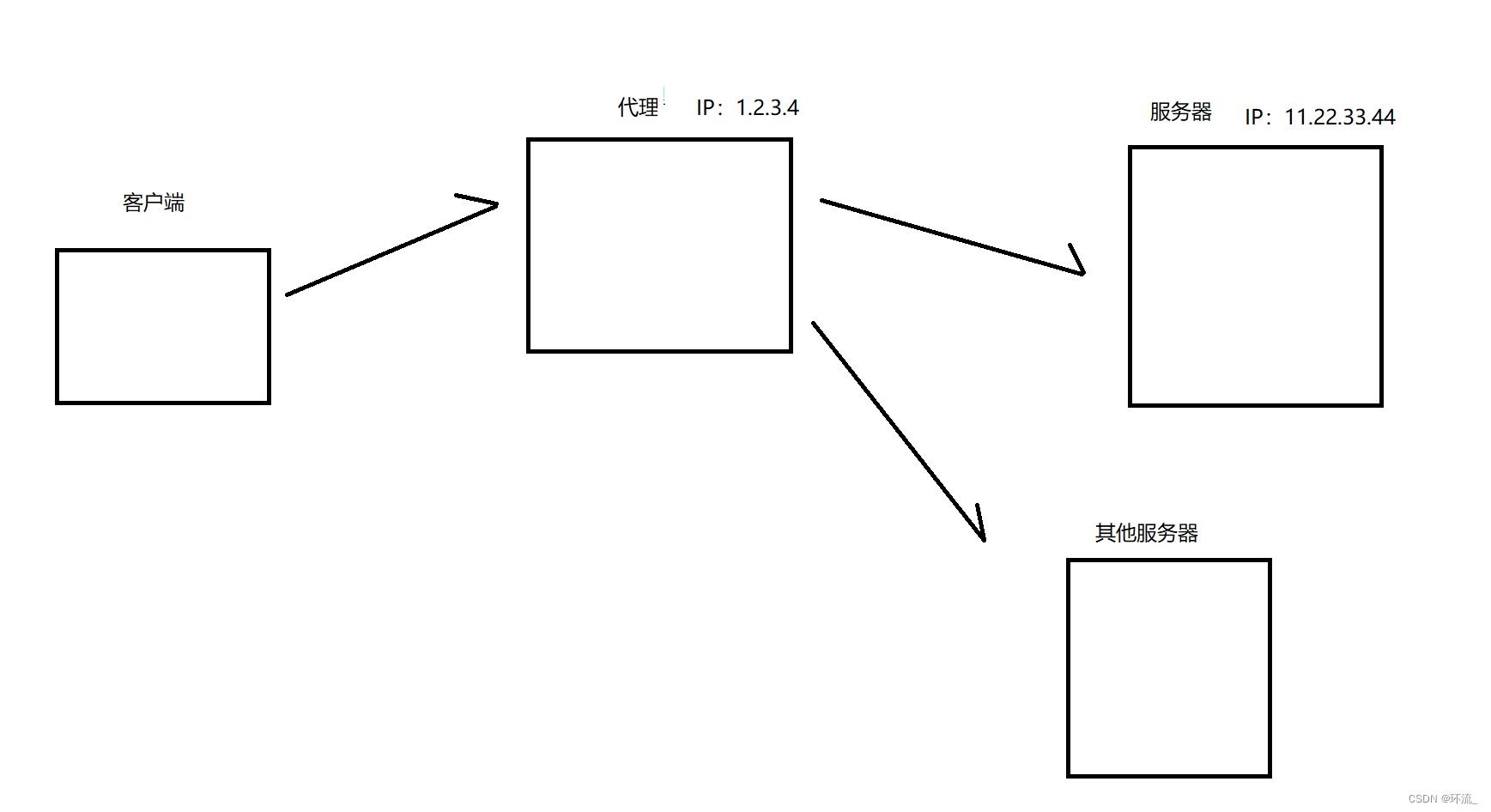
我们的浏览器真正要访问的是目标服务器:11.22.33.44 但要经过代理
所以请求中的URL可能就会是1.2.3.4 然后Host里面是11.22.33.44
把请求给代理,代理根据你的Host去帮你找到对应的服务器
(2)Content-Length & Content-Type
Content-Length表示body中的数据长度
Content-Type表示请求的body中的数据格式
这两个字段,不一定会出现,但是如果出现其中一个。那么另外一个也必然会出现
如果请求中没有body(GET),就没有这两个字段
如果请求中有body(POST),一定会有这两个字段
1)Content-Length存在的意义是什么呢?HTTP协议在传输层是基于TCP
TCP是面向字节流的,就有可能会出现粘包问题(粘包:一个一个字节放在TCP接收缓冲区中,应用程序从哪里到哪里读出一个完整的数据报是一个问题)
解决粘包问题有两个个解决方法:一个是约定一个分隔符,也就是空行;另外一个就是约定报文的长度
约定好报文长度后,就能分辨多个请求了,通常多个请求,比如说多个GET连在一起,后一个GET会连着上一个请求的body结尾,空格分割header部分后,在根据报文长度拿到对应GET的body部分,避免取到下一个GET内容~

2)Content-Type:body中的数据可以有很多种格式,存在不同的格式,对于接收方来说,解析的方式也是不同的~

(3)User-Agent(简称UA)

第一个框表示一个组织,MDN就是这个组织搞的
第二个框是你主机信息,window10,64位主机
第二个框表示的是当前浏览器的内核
第四个框表示使用的浏览器
小结:UA主要包含的信息,就是操作系统信息和浏览器信息,描述了用户在使用啥样的设备上网~
(4)Referer 这个不一定会在请求中出现
它表示,当前这个页面,是从哪个页面跳转过来的(也就是上级页面是啥)
比如说现在我们从百度去搜索搜狗的官网
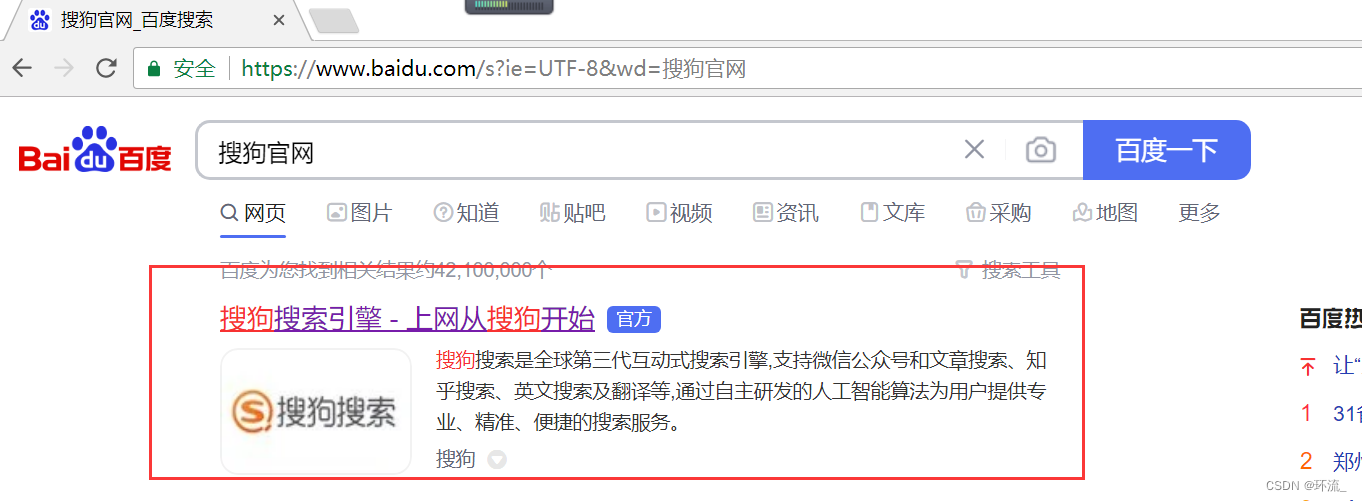
上图,此时的页面是百度,我点击进入搜狗官网后,就跳转到了下图页面

然后我们抓包看看搜狗里面的referer
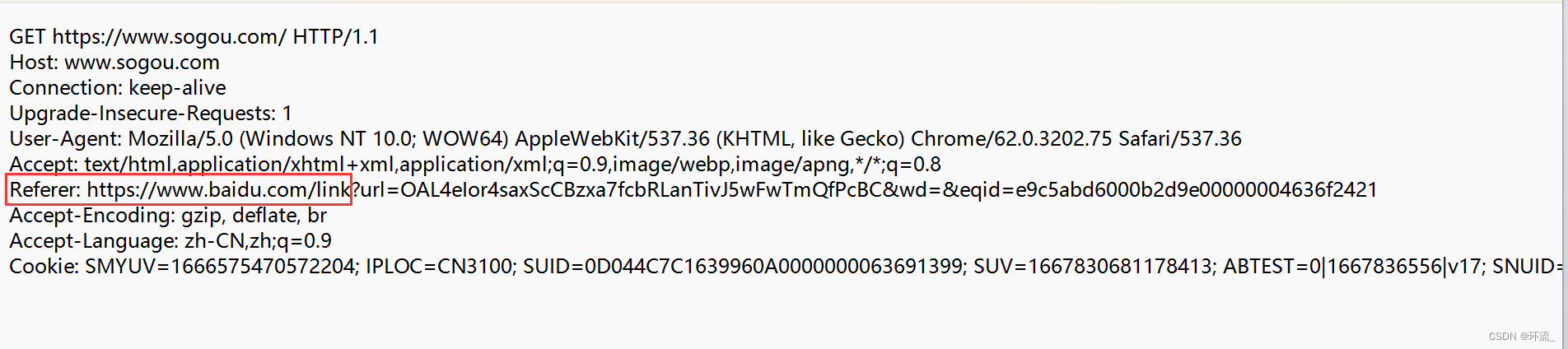
我们根据上图很明显看到,我们跳转到的搜狗官网的上级页面是百度,所以referer就显示了上一级的网址~
你要是在浏览器中直接输入一个地址是没有referer的,点击收藏夹也没有,必须要经过一个网页的跳转才行~
本文先讲解这些~结束
Original: https://blog.csdn.net/qq_61862008/article/details/127818343
Author: 环流_
Title: 【后端】HTTP3
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/655370/
转载文章受原作者版权保护。转载请注明原作者出处!