

如果你对Python中的字典和集合的使用还不是很熟悉,这两篇文章或许能提供一些帮助:
Python数据容器之字典(dict)
Python数据容器之集合(set)
7-1 sdut-查验身份证
一个合法的身份证号码由17位地区、日期编号和顺序编号加1位校验码组成。校验码的计算规则如下:
首先对前17位数字加权求和,权重分配为:
{7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2};然后将计算的和对11取模得到值Z;最后按照以下关系对应Z值与校验码M的值:
Z:0 1 2 3 4 5 6 7 8 9 10
M:1 0 X 9 8 7 6 5 4 3 2
现在给定一些身份证号码,请你验证校验码的有效性,并输出有问题的号码。
验证身份证合法性的规则:(1)前17位是否全为数字;(2)最后1位校验码计算准确。
输入格式:
输入第一行给出正整数N(≤100)表示:输入的身份证号码的个数。
随后N行,每行给出1个18位身份证号码。
输出格式:
按照输入的顺序每行输出1个有问题的身份证号码。
如果所有号码都正常,则输出 All passed。
输入样例1:
4
320124198808240056
12010X198901011234
110108196711301866
37070419881216001X
输出样例1:
12010X198901011234
110108196711301866
37070419881216001X
输入样例2:
2
320124198808240056
110108196711301862
输出样例2:
All passed
代码:
W = [7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2]
Z = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
M = ['1', '0', 'X', '9', '8', '7', '6', '5', '4', '3', '2']
dic = dict(zip(Z, M))
flag = 1
n = int(input())
for i in range(n):
id = input()
if not id[0: 17].isdigit():
print(id)
flag = 0
else:
cnt = 0
for i in range(17):
cnt += int(id[i])*W[i]
if dic[cnt % 11] != id[-1]:
print(id)
flag = 0
if flag == 1:
print("All passed")
7-2 sdut-统计两个字符串中相同的字符个数
输入字符串A、字符串B,求在字符串A、字符串B中相同的字符个数。
输入格式:
第一行输入,表示字符串A。
第二行输入,表示字符串B。
输出格式:
在一行内,输出字符串A、B中相同字符的个数。
输入样例:
AEIOU
HELLO World!
输出样例:
在这里给出相应的输出。例如:
2
代码:
st1 = set(input())
st2 = set(input())
print(len(st1 & st2))
7-3 sdut-图的字典表示
现在用PYTHON的数据结构表示图。图中有若干个顶点,每个顶点的表示方式为:顶点名称和该顶点相连的所有的其他顶点的名称,所组成的边的长度。
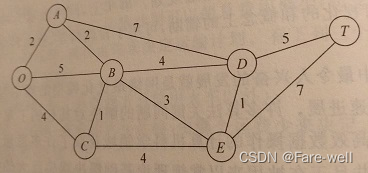

例如,图中O点表示方式为:{‘O’:{‘A’:2,’B’:5,’C’:4}}。
提示:用eval函数处理输入,eval函数具体用法见第8章函数(下)常建的内置函数。
输入格式:
输入多行字符串,每行表示一个顶点。
输出格式:
输出图中所有的顶点数量,边的数量,边的总长度。数值之间有1个空格。
输入样例:
4
{'a':{'b':10,'c':6}}
{'b':{'c':2,'d':7}}
{'c':{'d':10}}
{'d':{}}
输出样例:
4 5 35
代码:
s1, s2 = 0, 0
n = int(input())
for i in range(n):
lis = [v2 for v2 in [v1 for v1 in eval(input()).values()][0].values()]
s1 += len(lis)
s2 += sum(lis)
print(n, s1, s2)
7-4 sdut-分析每队活动投票情况
利用集合分析活动投票情况。
第一小队有五名队员,序号是1,2,3,4,5; 第二小队也有五名队员,序号6,7,8,9,10。
输入一个得票队员的编号的字符串,求第一、二小队没有得票的队员。在一行中输入得票的队员的序列号,用逗号隔开。
输入格式:
在一行中输入得票的队员的序列号,用逗号隔开。
输出格式:
在第一行中输出第一小队没有得票的队员序号,用空格分开;
在第二行中输出第二小队没有得票的队员序号,用空格分开。
输入样例:
1,5,9,3,9,1,1,7,5,7,7,3,3,1,5,7,4,4,5,4,9,5,10,9
输出样例:
2
6 8
代码:
ls = list(map(int, input().split(',')))
s1, s2 = [], []
for i in range(1, 11):
if i not in ls:
if 1 i 5:
s1.append(i)
else:
s2.append(i)
print(*s1, sep=' ')
print(*s2, sep=' ')
7-5 sdut-统计字符在字符串中出现的次数
统计并输出某给定字符在给定字符串中出现的次数。
输入格式:
第一行给出一个以回车结束的字符串(一行少于80个字符);
第二行输入一个字符。
输出格式:
在一行中输出给定字符在给定字符串中出现的次数。(如果未出现,则输出0)
输入样例:
programming is More fun!
m
输出样例:
2
代码:
s = input()
c = input()
print(s.count(c))
7-6 sdut-输出N天后星期几缩写
已知,今天是星期一。输入一个正整数n,输出n天之后对应的星期几的名称缩写。
星期日 Sun
星期一 Mon
星期二 Tue
星期三 Wed
星期四 Thu
星期五 Fri
星期六 Sat
输入格式:
在一行内输入一个正整数n。
输出格式:
输出n天之后对应的星期几的名称缩写。
输入样例:
1
输出样例:
Tue
代码:
ls1 = [6, 0, 1, 2, 3, 4, 5]
ls2 = ["Sun", "Mon", "Tue", "Wed", "Thu", "Fri", "Sat"]
dic = dict(zip(ls1, ls2))
n = int(input()) % 7
print(dic[n])
7-7 sdut-四则运算(用字典实现)
根据输入信息进行四则运算(用字典实现)。
(与c语言的switch语句相比较。)
输入格式:
第1行中输入一个数字a;
第2行中输入一个四帜运算符(+ , – , * , / ) op,
在第3行中输入一个数字b。
输出格式:
在一行中输出 a op b 的运算结果(保留2位小数)。
输入样例1:
7
/
3
输出样例1:
2.33
输入样例2:
10
/
0
输出样例2:
divided by zero
代码:
dic = {'+': 'x+y', '-': 'x-y', '*': 'x*y', '/': "x/y if y!=0 else 'divided by zero'"}
x = int(input())
opt = input()
y = int(input())
ans = eval(dic[opt])
if type(ans) is not str:
print("%.2f" % ans)
else:
print(ans)
7-8 sdut-统计工龄
给定公司N名员工的工龄,按工龄增序输出每个工龄段有多少员工。
输入格式:
首先给出正整数N(≤10^5),即员工总人数;随后给出N个整数,即每个员工的工龄,范围在 [0, 50]。
输出格式:
按工龄的递增顺序输出每个工龄的员工个数,格式为:”工龄:人数”。
每项占一行。
输入样例:
8
10 2 0 5 7 2 5 2
输出样例:
在这里给出相应的输出。例如:
0:1
2:3
5:2
7:1
10:1
代码:
n = int(input())
ls1 = list(map(int, input().split()))
dic = {}
for it in ls1:
dic[it] = dic.get(it, 0) + 1
ls2 = sorted(dic.keys())
for i in ls2:
print("%d:%d" % (i, dic[i]))
7-9 sdut-字典合并
输入用字符串表示两个字典,输出合并后的字典。字典的键用一个字母或数字表示。
注意:1和’1’是不同的关键字!
输入格式:
在第一行中输入第一个字典字符串;
在第二行中输入第二个字典字符串。
输出格式:
在一行中输出合并的字典,输出按字典序。
“1” 的 ASCII 码为 49,大于 1,排序时 1 在前,”1″ 在后。其它的字符同理。
输入样例1:
{1:3,2:5}
{1:5,3:7}
输出样例1:
1:8
2:5
3:7
输入样例2:
{"1":3,1:4}
{"a":5,"1":6}
输出样例2:
1:4
'1':9
'a':5
代码:
a = dict(eval(input()))
b = dict(eval(input()))
for it in b.keys():
a[it] = a.get(it, 0) + b[it]
ls1 = list(a.items())
ls1.sort(key=lambda x: ord(x[0]) if type(x[0]) == str else x[0])
ls2 = list(str(dict(ls1)).strip('{}').replace(' ', '').replace('"', "'").split(','))
for it in ls2:
print(it)
7-10 sdut-两数之和
给定一组整数,还有一个目标数,在给定的一组整数中找到2个数字,使其和为目标数。
如找到,解是唯一的。找不到则显示 “no answer”。
PYTHON实现提示:用一重循环加字典实现。
输入格式:
第1行中给出一组整数。 在第2行输入目标数。
输出格式:
在一行中输出这2个数的下标,用一个空格分开。输出的下标按从小到大排序。
如果找不到,则显示 “no answer”。
输入样例1:
2 7 11 15
9
输出样例1:
0 1
输入样例2:
3 6 9 8 19
10
输出样例2:
no answer
代码:
ls = list(map(int, input().split()))
n = int(input())
flag = 0
for it in ls:
if n - it in ls:
print(ls.index(it), ls.index(n - it))
flag = 1
break
if flag == 0:
print("no answer")
7-11 sdut-能同时被3、5、7整除的数的个数
求指定区间[a,b]内能同时被3、5、7整除的数的个数。
提示:用集合实现。
输入格式:
在一行中从键盘输入2个正整数a,b(1
Original: https://blog.csdn.net/qq_51774501/article/details/127813303
Author: Fare-well
Title: SDUT—Python程序设计实验六(字典与集合)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/654493/
转载文章受原作者版权保护。转载请注明原作者出处!