

关注公众号 【 离心计划】呀,一起逃离地球表面

前言
上一节我们讲了Redis作为一个旁路缓存的基本工作模式以及旁路缓存的意义所在,也提到了Redis相比于简单的hashmap的get/set模式有更强大的支撑,其中Redis丰富的数据组织结构与巧妙的数据存储结构是Redis广受欢迎的原因之一,这一节我们就来看看Redis花样的数据结构。
数据组织结构
细心的读者可以留意到前面我说了数据组织结构和数据存储结构,这是我自己的说法,是为了区分Redis给使用者用的结构和Redis自己内存底层结构,我们由浅入深,先了解Redis提供了哪些组织结构给我们使用。
String类型
String类型的数据通过set/get命令进行数据存取,这是单条数据的操作,如果批量还有mset与mget的操作,具体可参考:https://redis.io/docs/data-types/strings/
List类型
Redis列表是简单的字符串列表,按照插入顺序排序。可以添加一个元素到列表的头部(左边)或者尾部(右边),对应的操作lpush/lpop、rpush/rpop。另外也有根据索引获取列表元素的操作lindex,具体可参考:https://redis.io/docs/data-types/lists/
Set类型
Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据,对应存取操作sadd/spop,另外还有sinter可以返回指定集合之间的交集,sunion返回指定集合的并集,具体可参考:https://redis.io/docs/data-types/sets/
Sorted Set类型
有序集合和集合一样也是 string 类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个 double 类型的分数。redis 通过分数来对集合中的成员进行从小到大的排序。对应存储操作zadd,可以获取指定位次区间的元素zrange,也可以获取指定分数区间的元素zrangebyscore,具体可参考:https://redis.io/docs/data-types/sorted-sets/
> ZADD sugela 1 one
(integer) 1
> ZADD sugela 2 two
(integer) 1
> ZADD sugela 3 three
(integer) 1
> ZRANGE runoobkey 0 5 WITHSCORES
1) "one"
2) "1"
3) "two"
4) "2"
5) "three"
6) "3"
Hash类型
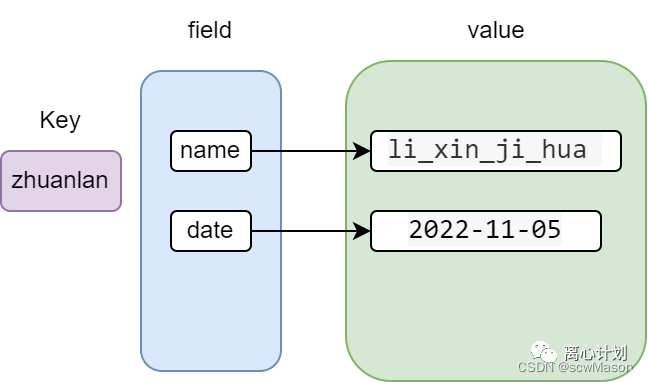
Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。Redis 中每个 hash 可以存储 232 – 1 键值对(40多亿)。通过hset可存储多个field,也可以通过hget获取多个field。下面就是一个key为zhuanlan且有两个field分别为name和date的一个hash结构
> HMSET zhuanlan name li_xin_ji_hua date 2022-11-05
OK
> HGETALL zhuanlan
1) "name"
2) "li_xin_ji_hua"
3) "date"
4) "2022-11-05"
以上五种是Redis提供给使用者的最最基本的数据组织结构,除了这些Redis在发展的过程中还提供了BitMap、HyperLogLog和GEO三种拓展结构,感兴趣的同学可以课外拓展。
数据存储结构
了解了数据组织结构后,我们来看下这些组织结构在Redis中是如何被存储的
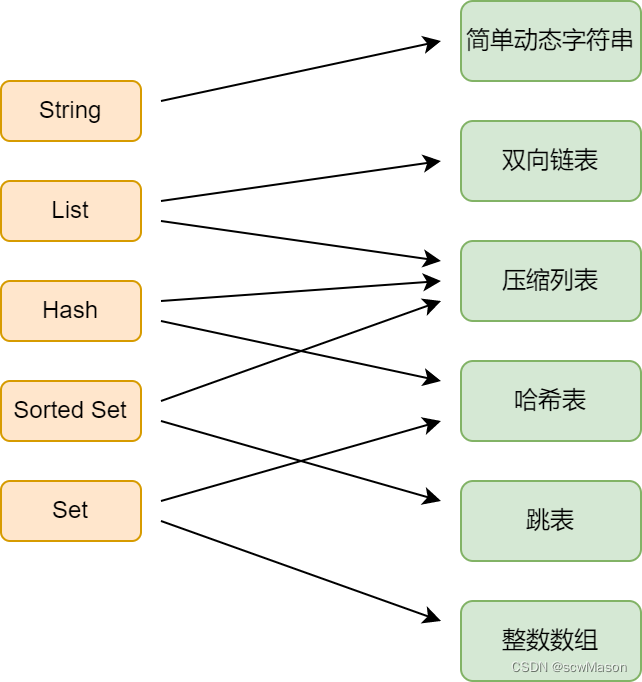
简单动态字符串(SDS,Simple Dynamic String)
先放下Redis源码链接:https://github.com/redis/redis,我们就参考Redis6.x版本。
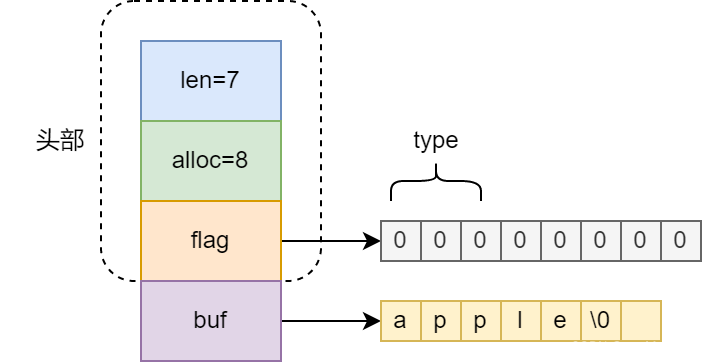
不知道大家还记得大学学习的C语言,C语言中表示字符串没有Java中现成的String给我们用,都是用char[] 来装字符,以空字符’\0’结尾作为一个字符串,而Redis基于C语言开发必然也会使用char[]来作为容器,但是Redis额外定义了一个结构体(redis/redis/src/sds.h),我们拿单字节存储来看:
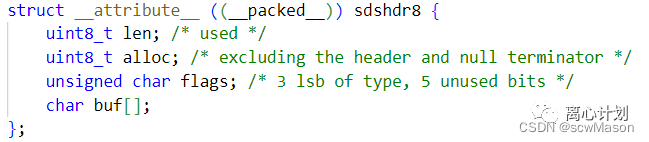
额外存储了几个属性:
- len 已使用的长度
- alloc 数组除了头部和/0的总长度
- flag 标识位,低三位存储类型,高五位留空
- buf 存储具体字符
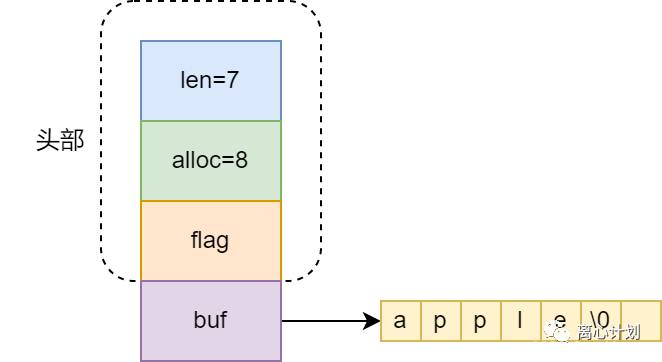
len、alloc与flag组成SDS的header。知道了这个结构,那为什么要这样设计呢,首先直接用char[]不行么?非要封装一层?这有很多原因,比如由于char[]在做获取长度时遍历的,而维护len可以直接拿到。
另外char[]在做字符串拼接时char strcat(char dest,const char *src),如果dest长度没有预先分配那么就会溢出,而SDS通过总长度和使用长度就知道剩余长度,可以在拼接之前就判断好是否需要扩容,下面的sdsMakeRoomFor 就是用来判断并决定是否会扩容的方法(redis/redis/src/sds.c)
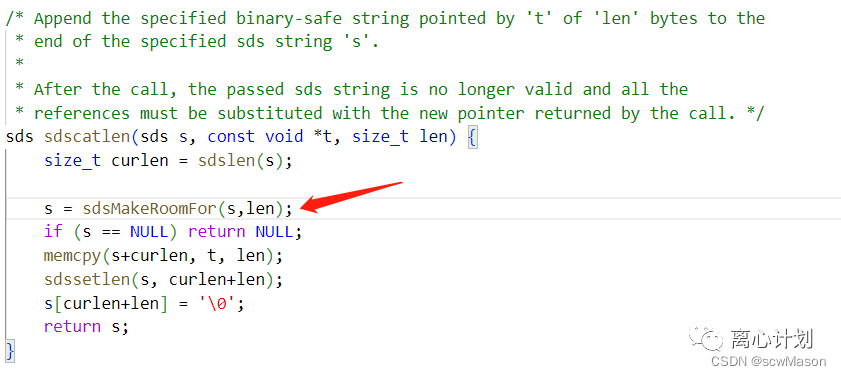
还有二进制安全问题,由于char[]原生使用’\0’作为结束符,但是许多二进制数据本身就含有’\0’字符,这就造成了意外分割,而SDS本身存储了len,因此不需要通过特殊字符判断字符串结束。
其中flag中的存储类型是由于,如果你看了源码就能看到,除了我们上面贴的用uint8_t来存储之外,还有16、32、64,这是为了满足短中长以及巨长字符串的存储要求,如果都用64位的八字节存储,那么小字符串的头部的所占空间比数据长度还长,有点浪费,所以定义了这几种,而flag前3位存储的type就是代表这个SDS是用的什么类型结构
压缩列表
压缩列表是一个特殊处理过的双向链表,我们先看它的设计然后再看为什么要这么设计。从源码的注解可以看到ziplist的组成结构:(redis/redis/src/ziplist.c)
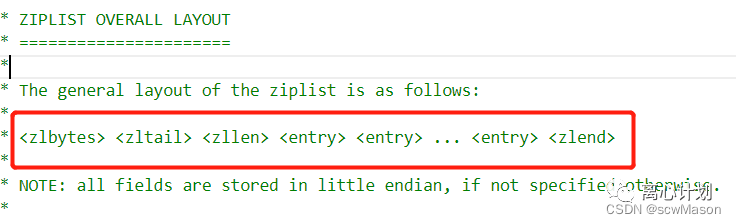
由五部分组成,分别是:
- zlbytes 四个字节,表示ziplist总字节数
- zltail 四个字节,表示尾节点距离起始位置的offset
- zllen 两个字节,表示ziplist中的节点数量
- entry ziplist存放数据的基本结构,叫做节点
- zlend 单字节,特殊值表示ziplist的结束
这些可以看作是ziplist的基本属性,有了总节点数方便统计列表长度,有了尾部位移方便快速定位尾部节点并快速插入。
而entry的结构也很特殊,源码中的注解如下:
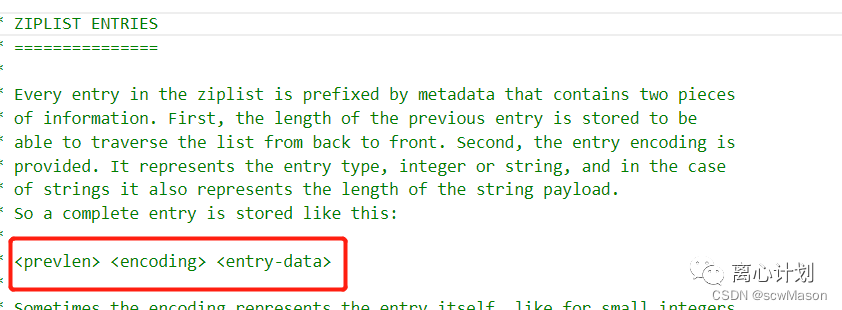
由三部分组成:
- prelen 前一个节点的长度,源码中注释如下:
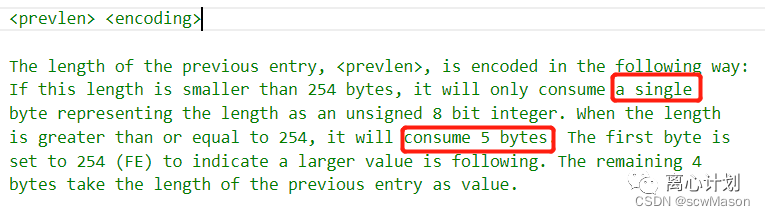
- encoding 用于记录entry-data中存放数据的类型和长度,针对不同大小entry和prelen一样处理成了1、2、5三种字节长度模式,前两位用来表示数据类型,后面的位用来放entry-data的长度

- entry-data 表示具体存放的数据
另外,如果我们简单使用双向链表来组织,那么每个节点都需要有两个前后指针指向前后节点就是八个字节,双向链表可以方便从前往后或者从后往前遍历,而Redis的ziplist有了上面的五部分和entry里的信息,从前往后遍历不用说,从后往前,可以先定位到尾节点的offset,然后offset减去尾节点存放的prelen就是倒数第二个节点,依次往前就实现了遍历,效率上可能没有直接指针快,但是减少了双向链表的前后指针的空间开销,因此 压缩列表是一种时间换空间的结构。
再回顾下使用了ziplist的结构是list、hash以及sorted set,hash结构和java中的hashmap一样,需要用数组对应哈希索引的,而由于时间换空间的性质,压缩列表并不是一直被使用,只有在集合元素较少的情况下才会使用,元素集合超过阙值就会转换成hashtable类型,同时满足以下条件:
-
哈希对象保存的所有键值的字符串长度小于64字节;
-
哈希对象保存的键值对数量小于512个;
那么这里我们引出一个问题,Redis是怎么解决hash冲突的?这个问题我们放到和Redis的键值对的存储方式一起说。
哈希表
我们上面的压缩列表和简单字符串,都是Redis插入key/value中的value的数据存储结构,那么key和value又是怎么存放,我们拿上面hash结构的操作举例:
HMSET zhuanlan name li_xin_ji_hua date 2022-11-05
也就是说name 和 li_xin_ji_hua整个对于zhuanlan来说就是value,这两者是怎么存储的呢?其实就是哈希表,只不过Redis为了存储键值对,用了一个全局哈希表:
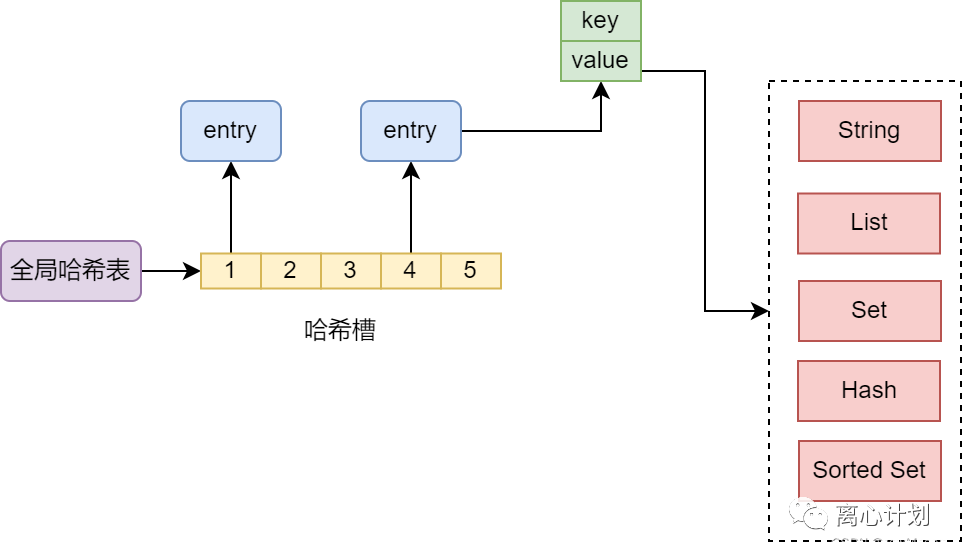
Redis处理哈希冲突的方式是拉链法,也就是将多个entry链接起来,对于哈希冲突的常见解决方式我就不展开了,像开放寻址、重哈希等。而当这个链表长度过长后,为了避免遍历链表的时间太长,就会触发Redis的rehash操作,具体表现为Redis会有一个全局哈希表2,然后将哈希表1中的key搬到哈希表2中去,这个搬运的过程是 渐进式哈希的过程,因为如果一次性把全部的key搬过去就会很耗时,如果采用渐进式那么每次只会把操作的槽对应的整条链表的entry搬过去。而且除了扩容,Redis在key变少的时候还会进行缩容。
Original: https://blog.csdn.net/scwMason/article/details/127814721
Author: scwMason
Title: 【专栏】基础篇03| Redis 花样的数据结构
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/653464/
转载文章受原作者版权保护。转载请注明原作者出处!