

神经网络权重初始化–容易忽视的细节
禁止转载!!
为什么要初始化
神经网络要优化一个非常复杂的非线性模型,而且基本没有全局最优解,初始化在其中扮演着非常重要的作用,尤其在没有BN等技术的早期,它直接影响模型能否收敛。 其本质是初始参数的选择应使得objective function便于被优化,如果随机初始化就只能看命了,但至少可以人为的选择一个较为合适的值,不一定最好但一定是稳定的。
好的初始化应该满足以下两个条件:
(1) 让神经元各层激活值不会出现饱和现象;
(2) 各层激活值也不能为0。
也就是激活值不要太大,也不要太小,应该刚刚好,当然这还只是最基本的要求。
权重初始化的目的是防止在深度神经网络的正向(前向)传播过程中层激活函数的输出损失梯度出现爆炸或消失。如果发生任何一种情况,损失梯度太大或太小,就无法有效地向后传播,并且即便可以向后传播,网络也需要花更长时间来达到收敛。然而,随机初始化就是搞一些很小的值进行初始化,实验表明大了就容易饱和,小的就激活不动。
并且Xavier等人之前发现,在学习的时候,当神经网络的层数增多时,会发现越往后面的层的激活函数的输出值几乎都接近于0,这显然是不合理的,因为网络的最后输出是要实现分类等任务,想必必须有一定的方差才能实现有差别的输出结果。因此,做实验在保证输入输出方差大致相同的时候,即满足的方差一致性的情况下,训练的收敛速度会更快,结果会更好一些。
此处有图文:https://zhuanlan.zhihu.com/p/25110150
kaiming初始化方法由来
建议可以看看这个论文:《Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification》
Xavier初始化的基本思想是保持输入和输出的方差一致,这样就避免了所有输出值都趋向于0。将每层的输出和梯度都看作是随机变量,将输入 假设为独立同分布的,先在没有激活函数的简化情况下进行推断:
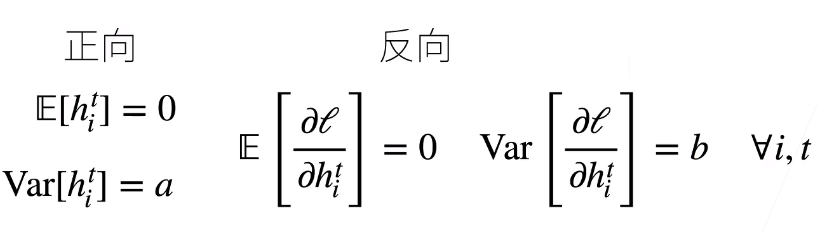

有点概率统计知识的可以很容易从求输出变量和梯度变量的均值方差公式推导出来,这里给出结论:
满足 前向输出方差一致的条件:(nt-1是前一层的维度rt为该层所规定的输出方差)

满足 梯度方差一致的条件:(nt是本层的维度rt为该层梯度所规定的方差)

如果要同时满足输出方差和梯度方差一致的化,必须使得输入维度和输出维度一样,有些时候显然是不可能的,所以取了一个折中的办法:


Xavier初始化的推导过程是基于线性函数的,但是它在一些非线性神经元中也很有效。比如tanh( 泰勒展开 接近于线性y=x的函数,4(sigmiod-0.5)也能满足条件), 但对非线性函数并不具有普适性relu等*)。原因如下:
如果有线性激活函数,那么只有当激活函数为f=x才能够满足,这也就是为什么tanh是可以很好work的。


kaiming初始化:
以上方法对于非线性的激活函数并不是很适用, 因为RELU函数的输出均值并不等于0,何凯明针对此问题提出了改进。
He initialization的思想是:在ReLU网络中,假定每一层有一半的神经元被激活,另一半为0,所以,要保持方差不变,只需要在Xavier的基础上再除以2:
- Forward Propagation Case前向:

- Backward Propagation Case后向


维度nl就是卷积核大小乘以卷积核个数。值得注意的是,第一层输入没有激活函数,所以说第一层可以不用除2,但是作者说只有这第一层影响不大,方便起见就全都设为一样的0均值和方差。
另外,这里也有前向和后向传播方差一致不能同时满足的情况,作者说了,这里只要选择一个准则来初始化就可以达到效果,根本是要使梯度得到更新, 二选一已经足够了。
; 代码实现
pytorch中的实现方法:(pytorch默认使用 kaiming正态分布初始化卷积层参数。,所以不用自己去手动初始化,因此常被人所遗忘的知识点)权重是用的0均值高斯分布, 偏置是0均值0方差的均匀分布。
- kaiming正态分布
torch.nn.init.kaiming_normal_
(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu')
- kaiming均匀分布
torch.nn.init.kaiming_uniform_
(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu')
def reset_parameters(self) -> None:
init.kaiming_uniform_(self.weight, a=math.sqrt(5))
if self.bias is not None:
fan_in, _ = init._calculate_fan_in_and_fan_out(self.weight)
bound = 1 / math.sqrt(fan_in)
init.uniform_(self.bias, -bound, bound)
参数说明:
tensor: an n-dimensional torch.Tensor
a: the negative slope of the rectifier used after this layer (only
used with 'leaky_relu')
mode: either 'fan_in' (default) or 'fan_out'. Choosing 'fan_in'
preserves the magnitude of the variance of the weights in the
forward pass. Choosing 'fan_out' preserves the magnitudes in the
backwards pass.
nonlinearity: the non-linear function (nn.functional name),
recommended to use only with 'relu' or 'leaky_relu' (default).
自己手动去初始化的代码:
def __weight_init(self,net):
for m in net.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
PReLu的使用
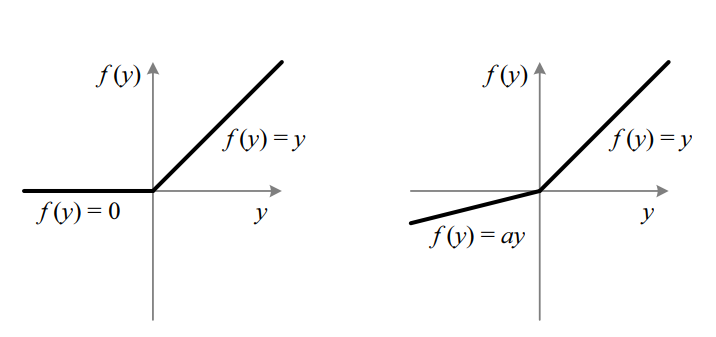
ReLu还是存在不足,其在负半轴全为零,还是会让较多的神经元失活,因此在负半轴加入了斜率来解决这个问题。

作者将ai作为一个可以学习的参数(这点参数的增加并不会带来过拟合问题),先初始化为0.25:


采用带动量的梯度下降算法:

作者没有采用正则化,因为发现加入的话,会使得a趋近于0。此外,作者发现对a的范围不受任何限制(意味着整个函数还可能是非单调的),最终结果是很少会有超过1的系数。所以这里没有采用任何正则化方法。
初始化方法:a=0就是relu,a=1就是接近线性激活函数

在使用的时候,每一层都固定成一个 固定值也是可以的,此时演变为Leaky ReLU,并且大多数网络使用的时候也是这样做的。
; 后话
当然, 如果使用了BatchNorm的话,不同的初始化方法结果差不多,说明使用BN可以使得初始化不那么敏感了。
此处有人做了实验对比,https://www.datalearner.com/blog/1051561108849107.
欢迎交流,禁止转载!!
Original: https://blog.csdn.net/qq_41917697/article/details/116033589
Author: 球场书生
Title: 神经网络权重初始化代码 init.kaiming_uniform_和kaiming_normal_
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/651358/
转载文章受原作者版权保护。转载请注明原作者出处!