

目录
- 1 快速搭建运行环境
- 2 快速构建项目
* - 2.1 导入训练集
- 2.2 安装函数库
– - 2.3 构建特征集和标签
- 2.4 导入数据集拆分工具sklearn
- 2.5 导入线性回归算法模型
- 2.6 进行预测
- 2.7 精准度计算
- 3 导入matplotlib画图库
- 4 作图时遇到的错误
1 快速搭建运行环境
我这里比较懒是全是一键安装的直接使用vscode插件进行部署,没有去搭建jupyter notebook,不过也比较简单后续我会出相关文章进行搭建。

; 2 快速构建项目
2.1 导入训练集
https://raw.githubusercontent.com/huangjia2019/house/master/house.csv
import pandas as pd
df_housing = pd.read_csv("https://raw.githubusercontent.com/huangjia2019/house/master/house.csv")
df_housing.head
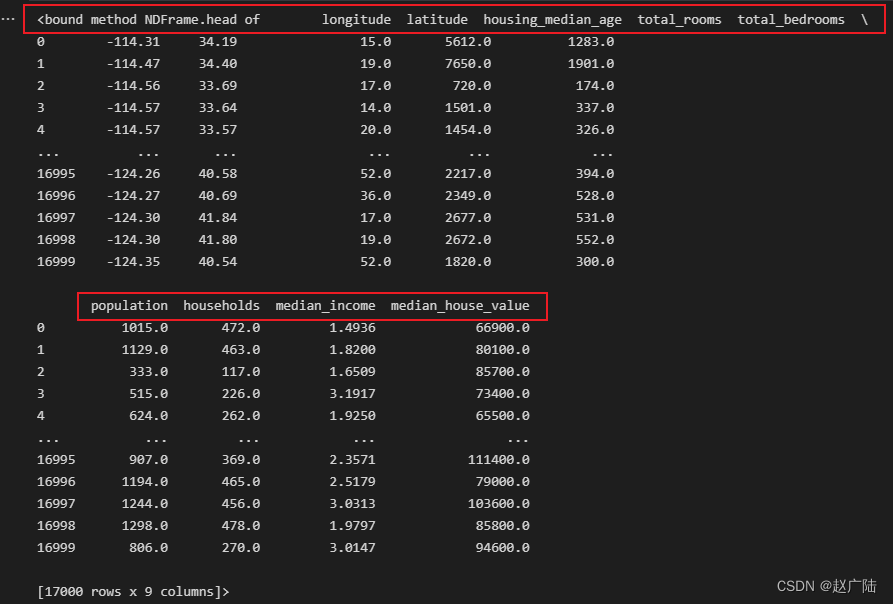
数据集介绍:经度(longitude)、纬度(latitude)、房屋的平均年龄(housing_median_age)、房屋数量(total_rooms)、家庭收入中位数(median_income)等信息,这些信息都是加州地区房价的特征。数据集最后一列”房价中位数”(median_house_value)是标签。这个机器学习项目的目标,就是根据已有的数据样本,对其特征进行推理归纳,得到一个函数模型后,就可以用它推断加州其他地区的房价中位数。
2.2 安装函数库
由于导入了Pandas,这是一个常见的Python数据处理函数库,如果没有这个库是不能运行的
使用vscode安装非常简单。
2.2.1 安装numpy
pip install numpy

输入这行代码不会报错就安装成功了
import numpy as np
array = np.array([[1,2,3],
[2,3,4]])
print(array)
2.2.2 安装pandas
pip install pandas
输入这行代码不会报错就安装成功了
2.3 构建特征集和标签
X = df_housing.drop("median_house_value",axis = 1)
y = df_housing.median_house_value
上面的代码使用drop方法,把最后一列median_house_value字段去掉,其他所有字段都保留下来作为特征集
2.4 导入数据集拆分工具sklearn
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2, random_state=0)
现在要把数据集一分为二,80%用于机器训练(训练数据集),剩下的留着做测试(测试数据集)如下段代码所示。这也就是告诉机器:你看,拥有这些特征的地方,房价是这样的,等一会儿你想个办法给我猜猜另外20%的地区的房价。
另外20%的地区的房价数据,本来就有了,但是我们假装不知道,故意让机器用自己学到的模型去预测。所以,之后通过比较预测值和真值,才知道机器”猜”得准不准,给模型打分。
2.5 导入线性回归算法模型
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_train, y_train)
下面这段代码就开始训练机器:首先选择LinearRegression(线性回归)作为这个机器学习的模型,这是选定了模型的类型,也就是算法;然后通过其中的fit方法来训练机器,进行函数的拟合。拟合意味着找到最优的函数去模拟训练集中的输入(特征)和目标(标签)的关系,这是确定模型的参数
运行完成,此时已经成功运行完fit方法,学习到的函数也已经存在机器中了,现在就可以用model(模型)的predict方法对测试集的房价进行预测,如下段代码所示。(当然,等会儿我们也可以偷偷瞅一瞅这个函数是什么样……)
2.6 进行预测
y_pred = model.predict(X_test)
print ('房价的真值(测试集)',y_test)
print ('预测的房价(测试集)',y_pred)
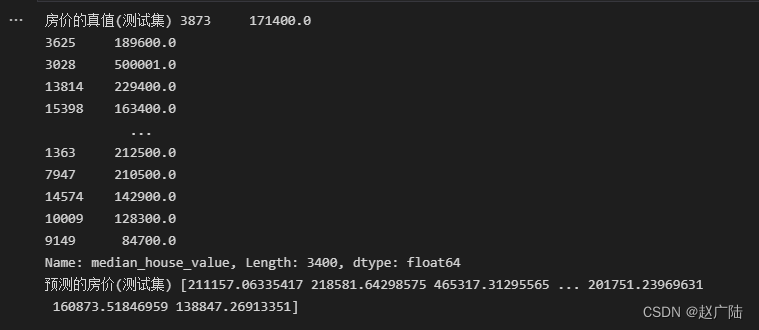

对应起来看着趋势是没什么问题
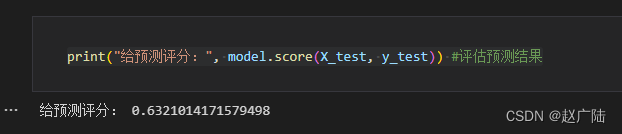
2.7 精准度计算
print("给预测评分:", model.score(X_test, y_test))
3 导入matplotlib画图库
import matplotlib.pyplot as plt
plt.scatter(X_test.median_income, y_test, color='brown')
plt.plot(X_test.median_income, y_pred, color='green', linewidth=1)
plt.xlabel('Median Income')
plt.ylabel('Median House Value')
plt.show()

绿色为机器学习所得函数图形,可以看出加州各个地区的平均房价中位数有随着该地区家庭收入中位数的上升而增加的趋势,而机器学习到的函数也同样体现了这一点。说明富人区就肯定都是收入高的。
4 作图时遇到的错误
VS Code错误 “preloads: Could not find renderer” ,只需禁用 “Jupyter Notebook Renderers” 即可。
Original: https://blog.csdn.net/ZGL_cyy/article/details/125345121
Author: 赵广陆
Title: 机器学习入门实战加州房价预测
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/651214/
转载文章受原作者版权保护。转载请注明原作者出处!