

系列文章链接:
AI艺术的背后:详解文本生成图像模型【基于 VQ-VAE】
AI艺术的背后:详解文本生成图像模型【基于GAN】
AI艺术的背后:详解文本生成图像模型【基于Diffusion Model】
导言
AI 艺术生成已经开始走进大众的视野中。在过去一年里,出现了大量的 文本生成图像模型,尤其是随着 Stable Diffusion 以及 Midjourney 的出现,带起了一股 AI 艺术创作热潮,甚至很多艺术家也开始尝试用 AI 来辅助艺术创作。在本文中,将会系统梳理近几年出现的文本生成图像算法,帮助大家深入了解其背后的原理。
基于 GAN
生成对抗网络(GAN,Generative Adversarial Networks)由两个主要的模块构成:生成器和判别器。生成器负责生成一张图片,而判别器则负责判断这张图片质量,也就是判断是真实样本还是生成的虚假样本,通过逐步的迭代,左右互博,最终生成器可以生成越来越逼真的图像,而判别器则可以更加精准的判断图片的真假。GAN 的最大优势是其不依赖于先验假设,而是通过迭代的方式逐渐学到数据的分布1。
最原始的GAN的定义为:
G ∗ = arg min G max D V ( G , D ) G^* = \arg \underset {G} \min \ \underset {D} \max V(G, D)G ∗=ar g G min D max V (G ,D )
其中,
V ( G , D ) = E x ∼ P d a t a s [ log D ( x ) ] + E x ∼ P G [ log ( 1 − D ( x ) ) ] V(G, D)=E_{x \sim P_{datas}}[\log D(x) ] + E_{x \sim P_{G}}[\log (1-D(x)) ]V (G ,D )=E x ∼P d a t a s [lo g D (x )]+E x ∼P G [lo g (1 −D (x ))]
当我们固定 G G G 的时候,最大化 V ( G , D ) V(G, D)V (G ,D ) 的含义是,数据如果来源于真实数据 P d a t a s P_{datas}P d a t a s ,我们需要 D ( x ) D(x)D (x ) 要接近于 1,而当数据来源于生成器 G G G 的时候,我们需要它接近于 0,也就是说,判别器 D D D 需要将真实数据判断为 1 而将生成数据判断为 0,这个时候,可以对判别器 D D D 进行优化。而当我们固定判别器 D D D 的时候,最小化 V ( G , D ) V(G, D)V (G ,D ) ,则需要生成器 G G G 生成的数据接近于真实数据。
简单来说, 一个 GAN 的训练流程如下:
- 初始化一个生成器 G G G 和一个判别器 D D D .
- 固定生成器 G G G 的参数, 只更新判别器 D D D 的参数。具体过程为:选择一部分真实样本,以及从生成器 G G G 得到一些生成的样本,送入到判别器 D D D 中,判别器 D D D 需要判断哪些样本为真实的,哪些样本为生成的,通过与真实结果的误差来优化判别器 D D D
- 固定判别器 D D D 的参数, 只更新生成器 G G G 的参数。具体过程为:使用生成器 G G G 生成一部分样本, 将生成的样本喂入到判别器 D D D 中,判别器会对进行判断,优化生成器 G G G 的参数,使得判别器将其判断为更加偏向于真实样本。
上文中介绍的 GAN 模型仅仅是最原始的 GAN,在后来的发展中,GAN 已经逐渐被用到各个领域,也产生了非常多的变种,接下来将会介绍一个非常知名的基于 GAN 的文本生成图像模型 VQGAN-CLIP。
VQGAN
上文中已经介绍了 GAN 的基本原理,而 VQGAN ( Vector Quantized Generative Adversarial Networks ) 则是一种 GAN 的变种(如下图所示)2,其受到 VQ-VAE 的启发,使用了 codebook 来学习离散表征。
具体来说,会预先定义 K K K 个向量作为离散的特征查询表,当一张图片被送入到 CNN Encoder 中后,会得到 n z n_z n z 个图像的中间表征 z ^ \hat z z ^ ,之后会在 Codebook 中去查询与其最相似的表征向量,得到 n z n_z n z 个表征 z q z_q z q ,其过程用公式可以描述为:
z q = q ( z ^ ) : = ( arg min z k ∈ Z ∣ ∣ z ^ i j − z k ∣ ∣ ) ∈ R h × w × n z z_q = q(\hat z) := (\underset {z_k\in \mathcal Z}\argmin||\hat z_{ij}-z_k||)\in \mathbb R^{h\times w\times n_z}z q =q (z ^):=(z k ∈Z arg min ∣∣z ^ij −z k ∣∣)∈R h ×w ×n z
紧接着,CNN Decoder 会根据得到的表征 去重建图像。
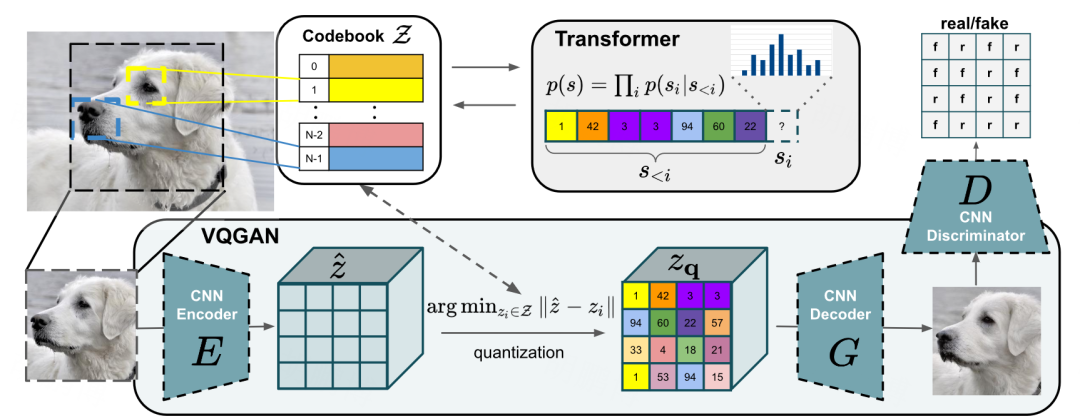

上述步骤跟 VQ-VAE 非常像,而 VQGAN 与之不同的是,上述步骤仅仅对应于 GAN 中的生成器,因此,这里还需要一个判别器 D D D ,来对生成的图像进行判断,而与传统 GAN 不同的是, 这里的判别器不是对每张图片进行判断,而是对每一个图片的 Patch 进行判断。
对于 VQGAN 中生成器的训练,其损失函数与 VQ-VAE 非常相似,其公式为:
L V Q ( E , G , Z ) = ∣ ∣ x − x ^ ∣ ∣ 2 + ∣ ∣ s g [ E ( x ) ] − z q ∣ ∣ 2 2 + ∣ ∣ s g [ z q ] − E ( x ) ∣ ∣ 2 2 \mathcal L_{VQ}(E, G, \mathcal Z) = ||x-\hat x||^2 + ||sg[E(x)]-z_q||_2^2 + ||sg[z_q]-E(x)||_2^2 L V Q (E ,G ,Z )=∣∣x −x ^∣∣2 +∣∣s g [E (x )]−z q ∣∣2 2 +∣∣s g [z q ]−E (x )∣∣2 2
VQGAN的训练损失函数定义为:
L V Q ( E , G , Z ) = [ log D ( x ) + log ( 1 − D ( x ^ ) ) ] \mathcal L_{VQ}(E, G, \mathcal Z) = [\log D(x)+ \log(1-D(\hat x))]L V Q (E ,G ,Z )=[lo g D (x )+lo g (1 −D (x ^))]
结合上述生成器的训练的损失函数,其完整公式可以表示为:
Q ∗ = arg min E , G , Z m D a x E x ∼ p ( x ) [ L V Q ( E , G , Z ) + λ L G A N ( { E , G , Z } , D ) ] \mathcal Q^* = \underset {E,G, \mathcal Z} \argmin\ \underset D max \ \mathbb E_{x\sim p(x) } [L_{VQ}(E, G, \mathcal Z) + \lambda L_{GAN}({E, G, \mathcal Z}, D) ]Q ∗=E ,G ,Z arg min D m a x E x ∼p (x )[L V Q (E ,G ,Z )+λL G A N ({E ,G ,Z },D )]
实际上,和 GAN 的损失函数还是非常一致的,不同的是, 这里的对于生成器部分的优化,需要使用与 VQ-VAE 一样的方法去进行。
在训练好 VQGAN 之后,在生成的时候,可以直接初始化一个 z q z_q z q 去生成,然而,为了能够得到稳定的 z q z_q z q ,需要使用一个模型对先验进行学习,这里使用了 Transformer 模型来学习 z q z_q z q 中离散表征的序列,可以简单的将其建模为自回归模型 p ( s ) = ∏ i p ( s i ∣ s < i ) p(s)=\prod ip(s_i|s{ ,这样,我们只需要给定一个初始的随机向量,就可以通过 Transfomer 模型生成完整的 z q z_q z q ,从而可以通过 CNN Decoder 模块生成最终的图像。
; VQGAN-CLIP
VQGAN-CLIP 也是一个非常流行的文本生成图像模型,一些开放的文本生成图像平台使用的就是 VQGAN-CLIP 3。
VQGAN-CLIP 通过文本描述信息来对 VQGAN 模型进行引导,使其最终生成与文本描述非常相似的图片,其具体过程如下图所示:
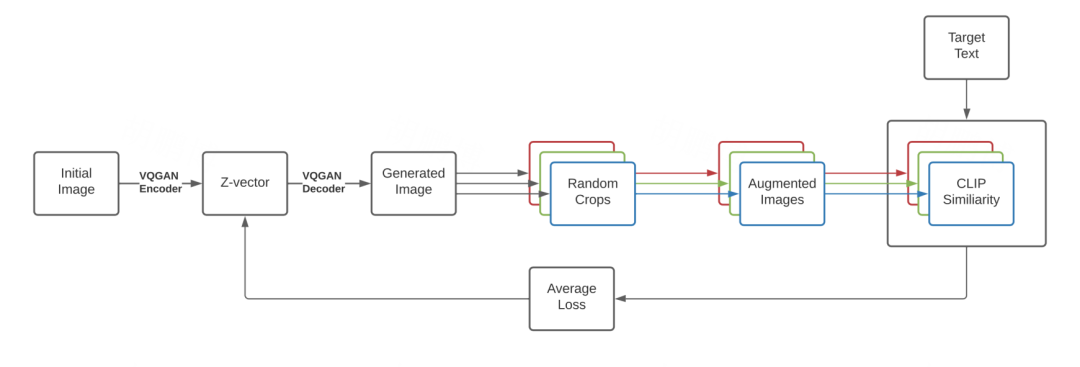
具体来说,在最开始,需要初始化一张图片,其像素为随机生成,这个时候,模型是从 0 开始迭代,也可以初始化一张绘制好的原始图片,这个时候,模型的迭代相当于对这张图片进行重绘。通过 VQGAN 的 Encoder 模块,可以得到中间表征离散 Z-vector,这个上文中 VQGAN 中的 z q z_q z q 是一样的。
通过 CLIP 模型,来对比生成的图像特征与指定文本的相似度,来调节中间表征向量 Z-vector,从而使得 VQGAN 模块生成与文本描述一致的图片,从上图中看出,除了 VQGAN 和 CLIP 模块,还有 Random Crops 以及 Augmented Images,这个操作是为了增加图片的稳定性,而且实验证明,加了这两个操作之后,更利于优化。
基于 VQGAN-CLIP 生成的模型如下图所示,通过设置复杂的描述,可以生成质量非常高的图片。

; DALL-E Mini
DALL-E Mini 是网友对 DALL-E 的复现版本3,不同的是,DALL-E Mini 并没有使用原始的 VQ-VAE,而是使用了 VQGAN, DALL-E-Mini 模型要远远小于原始 DALL-E 模型,使用的训练样本也相对较少 4。
DALL-E-Mini 首先使用 BART 模型(一种Sequence-to-Sequence模型)来学习文本到图像的映射,将文本转换为离散图像表征。
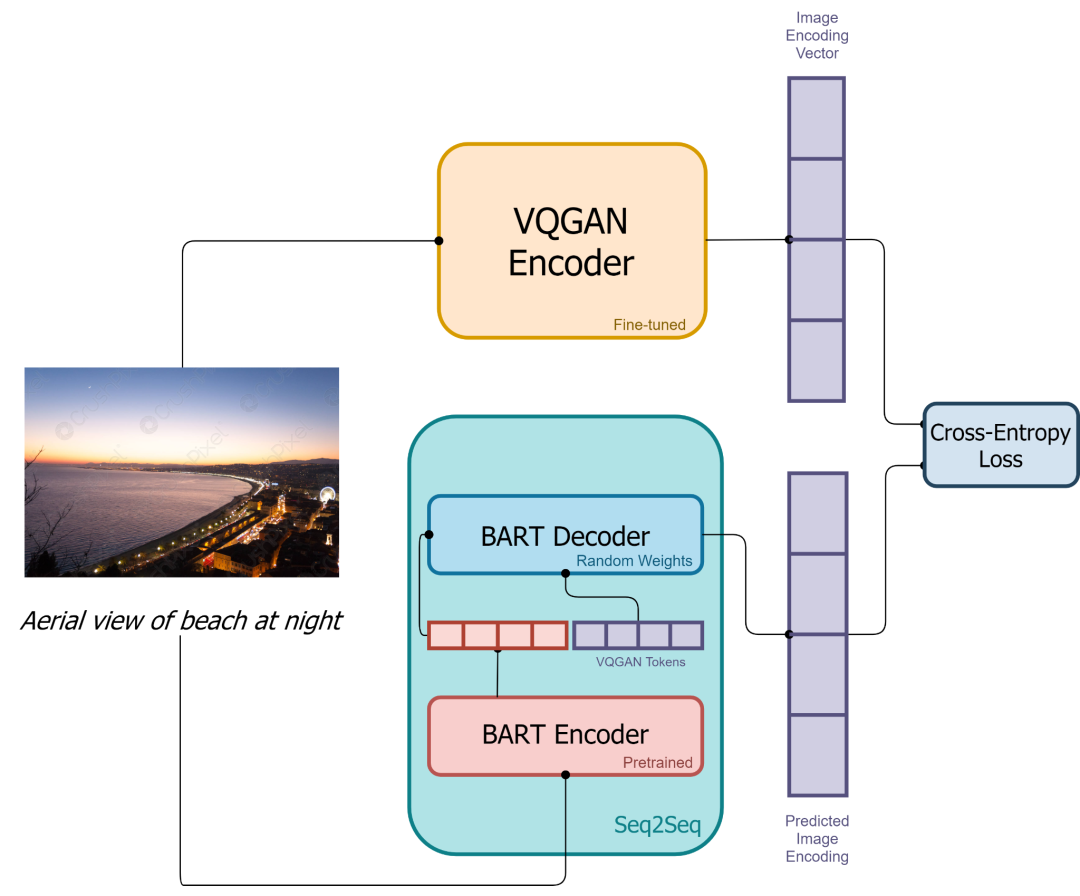
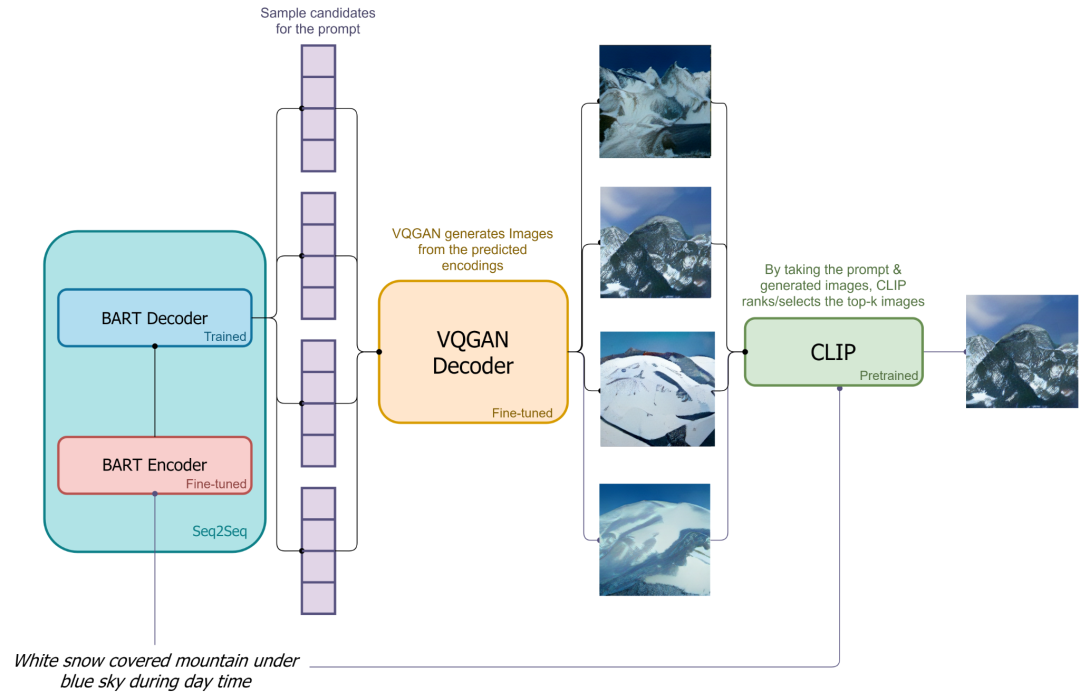
在图像生成步骤中,可以直接将文本输入到 BART 中,然后得到图片离散表征,紧接着使用 VQ-GAN Decoder 模块,将离散图像表征解码为完整图像,之后在使用 CLIP 对图像进行筛选,得到最终的生成结果。
; Parti
在 Imagen 刚出来后没多久(Imagen的介绍可以看扩散模型部分),Google 又继续提出了新的文本生成图像模型 Parti,其全称为「Pathways Autoregressive Text-to-Image」,直观来看,就是使用了 Google 最新提出的 Pathway 语言模型 5。

与 Imagen 不同的是,Parti 又回归了 原始文本生成图像的做法,不是直接使用文本表征作为条件扩散模型范式去生成图像,而是使用 Pathway 语言模型,学习文本表征到图像表征的映射,也就是像 DALL-E2 一样,学习一个先验模型,同时,Parti 使用的是基于 VQGAN 的方法,而不是扩散模型。
具体来说,Parti 首先训练一个 ViT-VQGAN 模型,之后使用 Pathway 语言模型学习文本到图像 token 的映射,由于 Pathway 语言模型强大的序列预测能力,其输出的图像表征非常出色,在预测过程中,只需将文本映射为图片表征,然后使用 ViT-VQGAN 解码器模块进行解码即可。
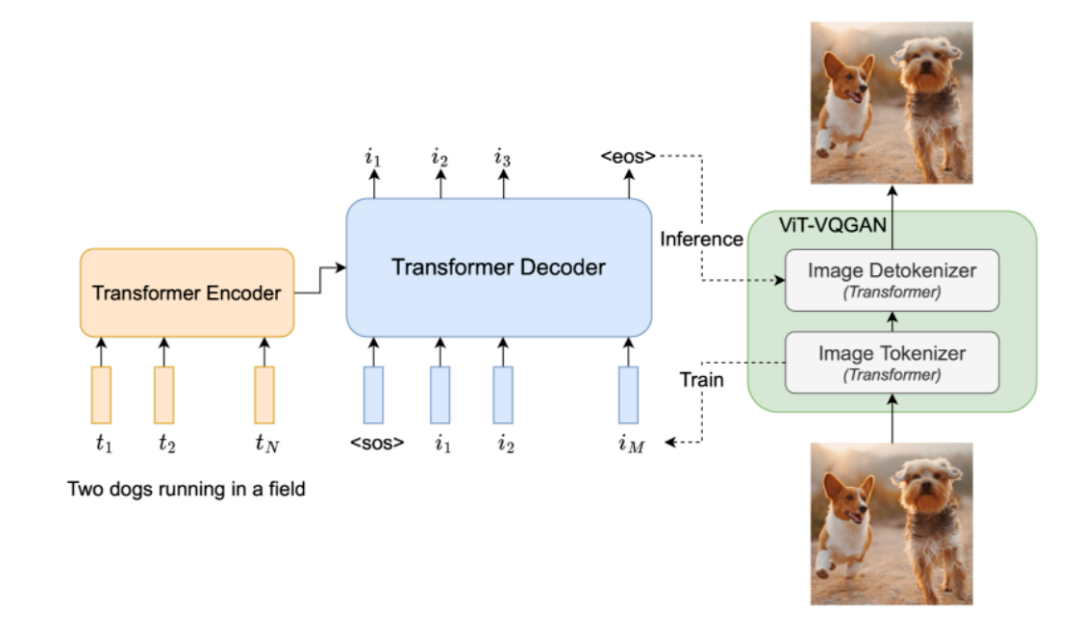
Parti 最大的特色就是 20B 的大模型,其参数量支持模型能够进行复杂语义理解,下图是不同参数量模型对于文本描述:「一张身穿橙色连帽衫和蓝色太阳镜的袋鼠肖像照片站在悉尼歌剧院前的草地上,胸前举着写着”欢迎朋友”标语的牌子!」 的生成效果,可以看出 20B 的大模型能够非常精准的理解 Prompt 的语义信息。

; NUWA-Infinity
NUWA-Infinity 是微软亚洲亚洲研究院 NUWA 团队基于之前工作,研发出的无限视觉生成模型,其特点是, 可以对已有的画进行续画,尤其是对于风景画效果非常惊艳,同时,该模型还支持文本生成图像,动画生成等任务,不过由于其主要创新点在于图片续画,因此在这里只对这一功能进行详细介绍6。

为了实现这一功能,作者提出了全局自回归嵌套局部自回归的生成机制,其中,全局自回归建模视觉块之间的依赖(patch-level),而局部自回归建模视觉 token 之间的依赖(token-level)。其公式表达为:
P ( x ∣ y ) = ∏ n = 1 N P ( p n ∣ P < n , y ) = ∏ n = 1 N ∏ m = 1 M P ( p n ( m ) ∣ p < n , p n ( < m ) ∣ , y ) \mathbb P(x|y) = \prod^N_{n=1}\mathbb P(p_n|P_{
也就是一个全局自回归模型中(n个patch),嵌入了一个局部自回归模型(m个token)。
在 NUWA-Infinity 中,作者还提出了两个机制,Nearby Context Pool(NCP)和 Arbitrary Direction Controller (ADC)。其中,ADC 负责将图片分割成 patch 并决定 patch 的方向,如下图所示,左图为训练的时候的顺序定义,右图是推理的时候的顺序定义。
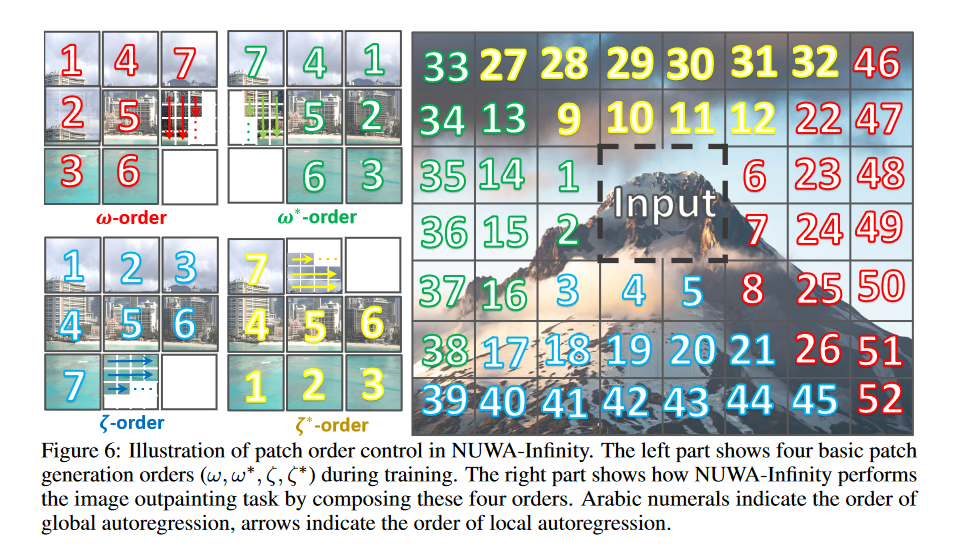
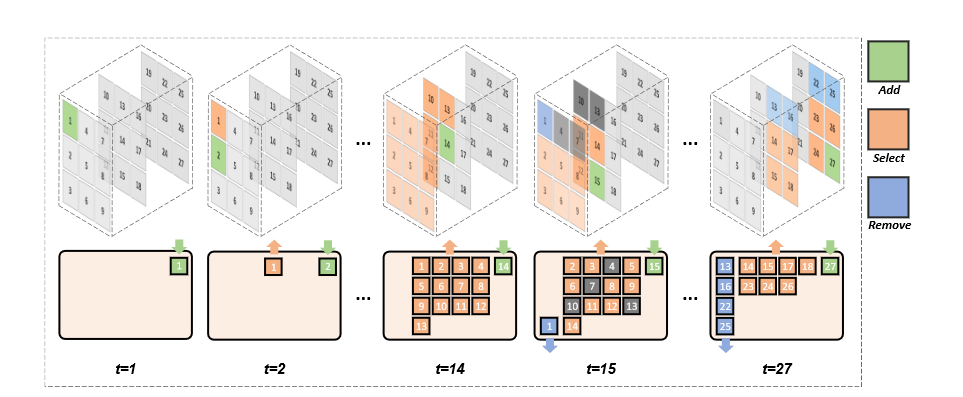
由于当图片尺寸变大之后,patch 的数量会超过自回归模型所能接收的最大长度,因此需要有一个增加新 patch 和移除旧 patch 的机制,这样就保证了自回归模型一直在需要生成的 patch 附近进行序列学习。
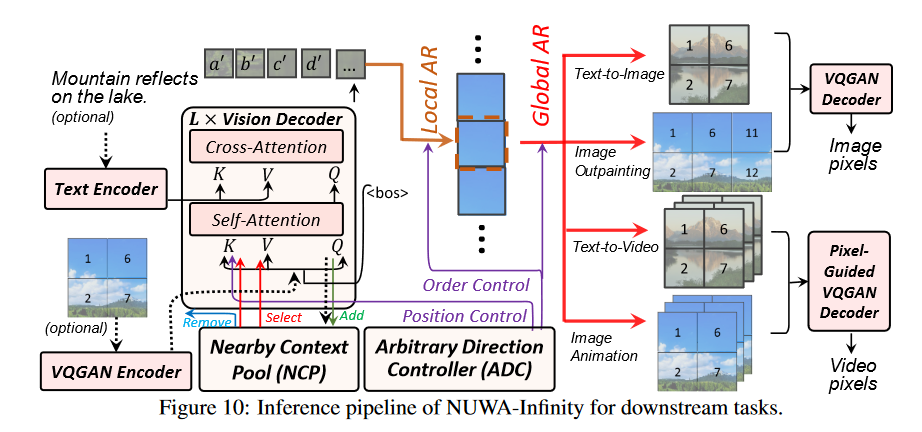
在模型的训练过程中,首先将图片分成 patch,然后,随机选择一种 patch 生成顺序,这对应于全局自回归操作。而对于每一个 patch,首先选择其邻近的 patch,加入位置编码以及文本信息,一起送入到自回归模型中,得到预测的中间离散表征 p ^ n \hat p_n p ^n ,同时,对于之前的 patch, 使用训练好的 VQ-GAN 生成中间离散表征 ,而模型的目标则是让 p ^ n \hat p_n p ^n 与 p n p_n p n 足够接近。直观来说,模型本质上是在训练一个模型,其通过与当前 patch 的邻近的 patch 的中间离散表征,和文本表征,来预测当前 patch 的中间离散表征。

在推理过程中,对于图片续画任务,只需要将图片输入进模型,选择 K 个 patch 作为条件,对 NCP 进行初始化,然后就可以通过已有的选择的 patch 结合文本信息,来对下个patch进行预测,最后使用 VQGAN Decoder 来将预测的 patch 的中间离散表征解码成图片即可,通过不断的迭代,最终实现对图片的续画功能。
; 基于 Diffusion Model
Diffusion Model
GLIDE
DALL-E2
Imagen
Stable Diffusion
模型试玩
总结
Original: https://blog.csdn.net/qq_32275289/article/details/126941108
Author: NLP_wendi
Title: AI艺术的背后:详解文本生成图像模型【基于GAN】
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/651127/
转载文章受原作者版权保护。转载请注明原作者出处!