

一、基础介绍
门槛最低的深度学习引导 – 知乎 (zhihu.com)![]()
 https://zhuanlan.zhihu.com/p/463019160 ; MindSpore入门实践 – 知乎 (zhihu.com)
https://zhuanlan.zhihu.com/p/463019160 ; MindSpore入门实践 – 知乎 (zhihu.com)![]() https://zhuanlan.zhihu.com/p/463229660 ;
https://zhuanlan.zhihu.com/p/463229660 ;
1. 课程内容
- 快速入门:准备数据 – 创建模型 – 损失与优化 – 训练与推理
- 张量TENSOR:初始化 – 属性 – 索引 – 转换
- 数据处理:整体流程 – 加载 – 迭代 – 处理与增强
- 创建网络:定义模型 – 模型参数 – 构建网络
- 自动微分:求导 – 梯度缩放 – 停止计算
- 模型训练:超参 – 损失函数 – 优化器 – 训练
- 保存与加载:模型保存 – 加载模型 – 迁移学习
- 推理与部署:模型导出 – 转化格式 – 部署与体验
2. MindSpore全场景AI计算框架
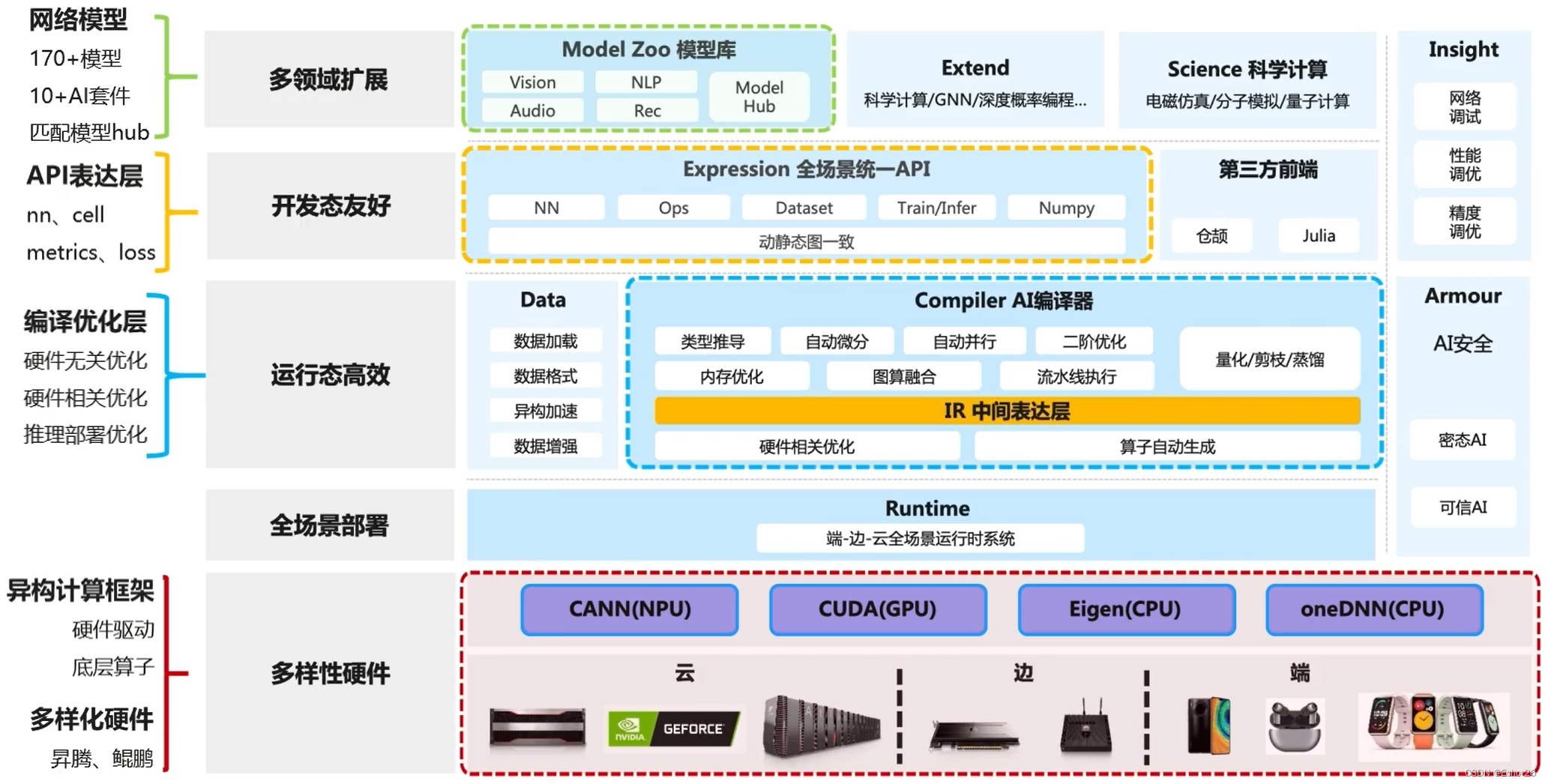
3. MindSpore架构特点
- 用户态易用,用户态可以非常方便地去使用
- 运行态高效,运行的时候非常快速
- 部署态灵活,部署的时候非常灵活方便
4. MindSpore全场景AI计算框架的流程图
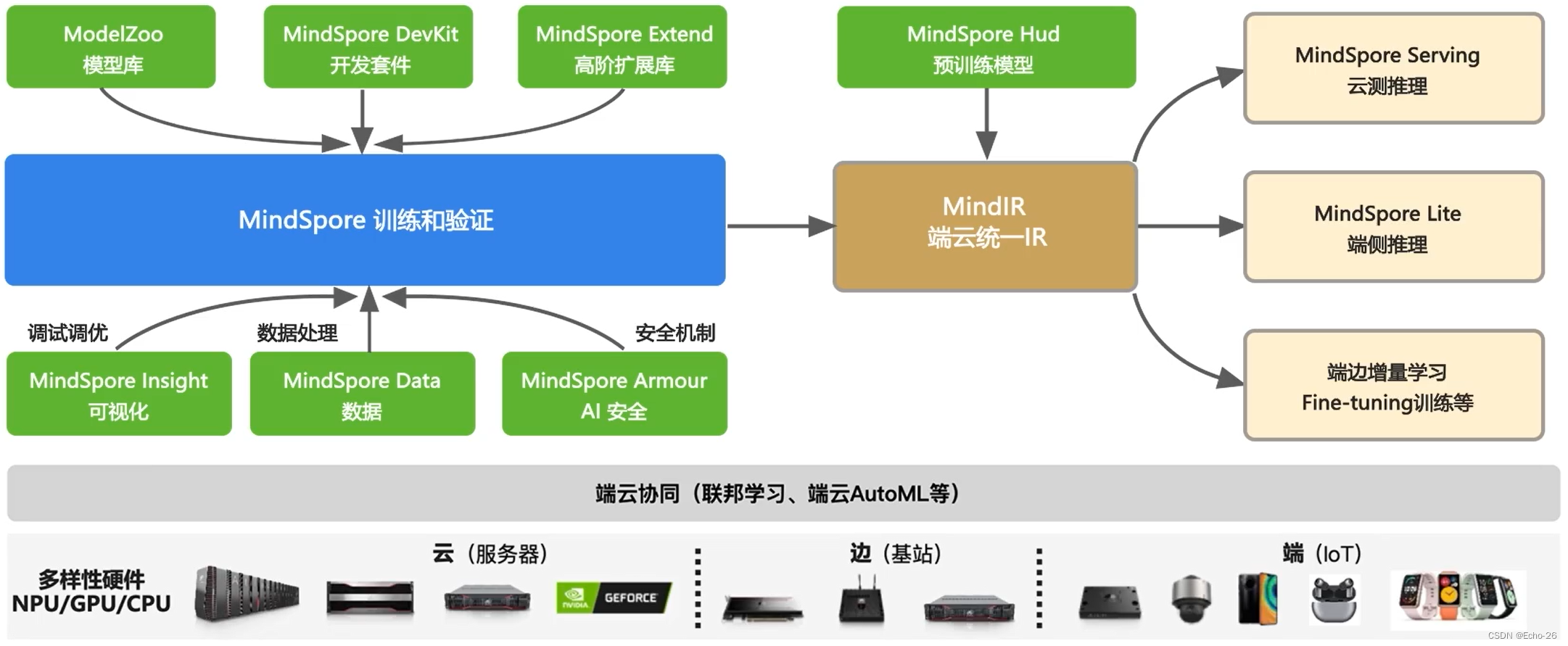
5. MindSpore全场景AI计算框架的API设计
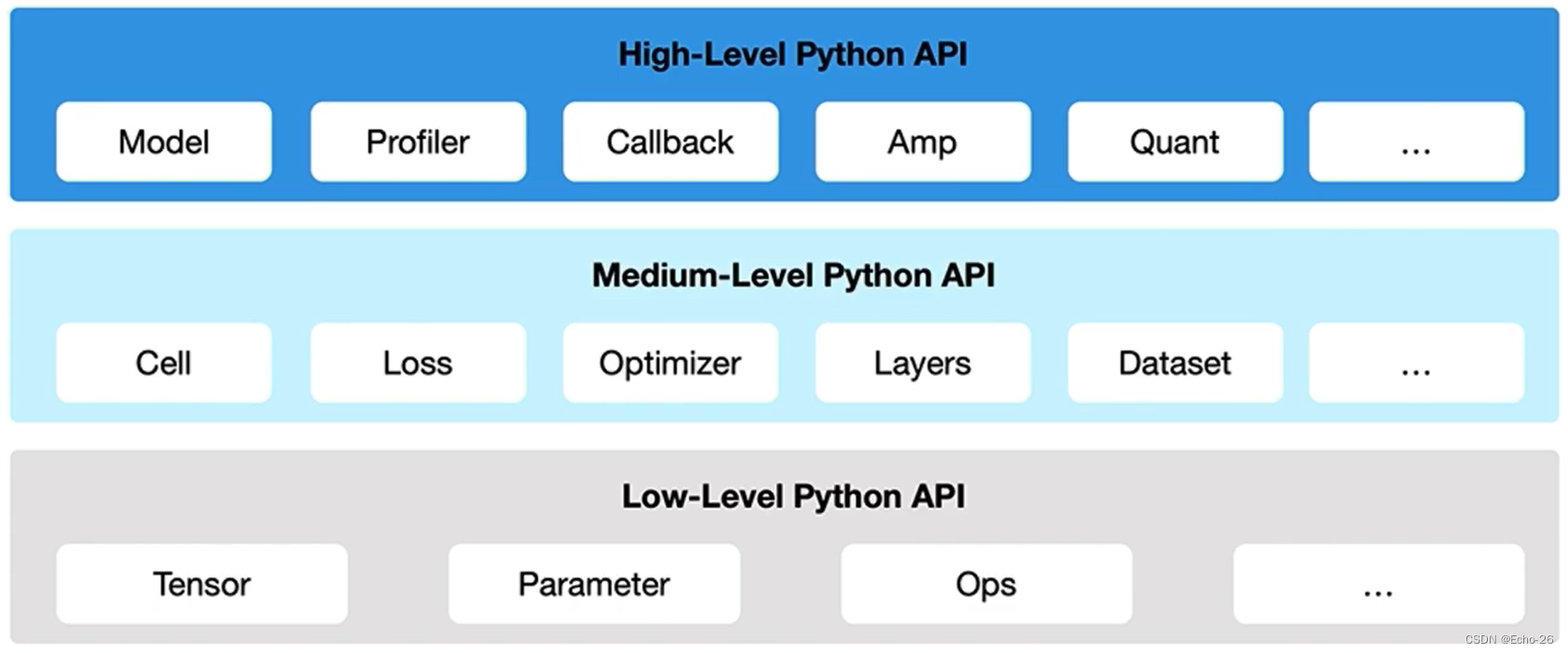
- High-Level:封装如网络模型训练相关的Models、量化Quant和混合精度Amp的一些接口,做到高层封装来方便开发者使用
- Medium-Level:最常用的,提供类似于神经网络的操作,如损失函数、优化器和数据处理等接口
- Low-Level:用得比较少或者针对一些特殊的处理和特殊的场景或者深度用户才会使用到,如果觉着神经网络层或者nn层的API不够用的时候,就可以调用Opsv
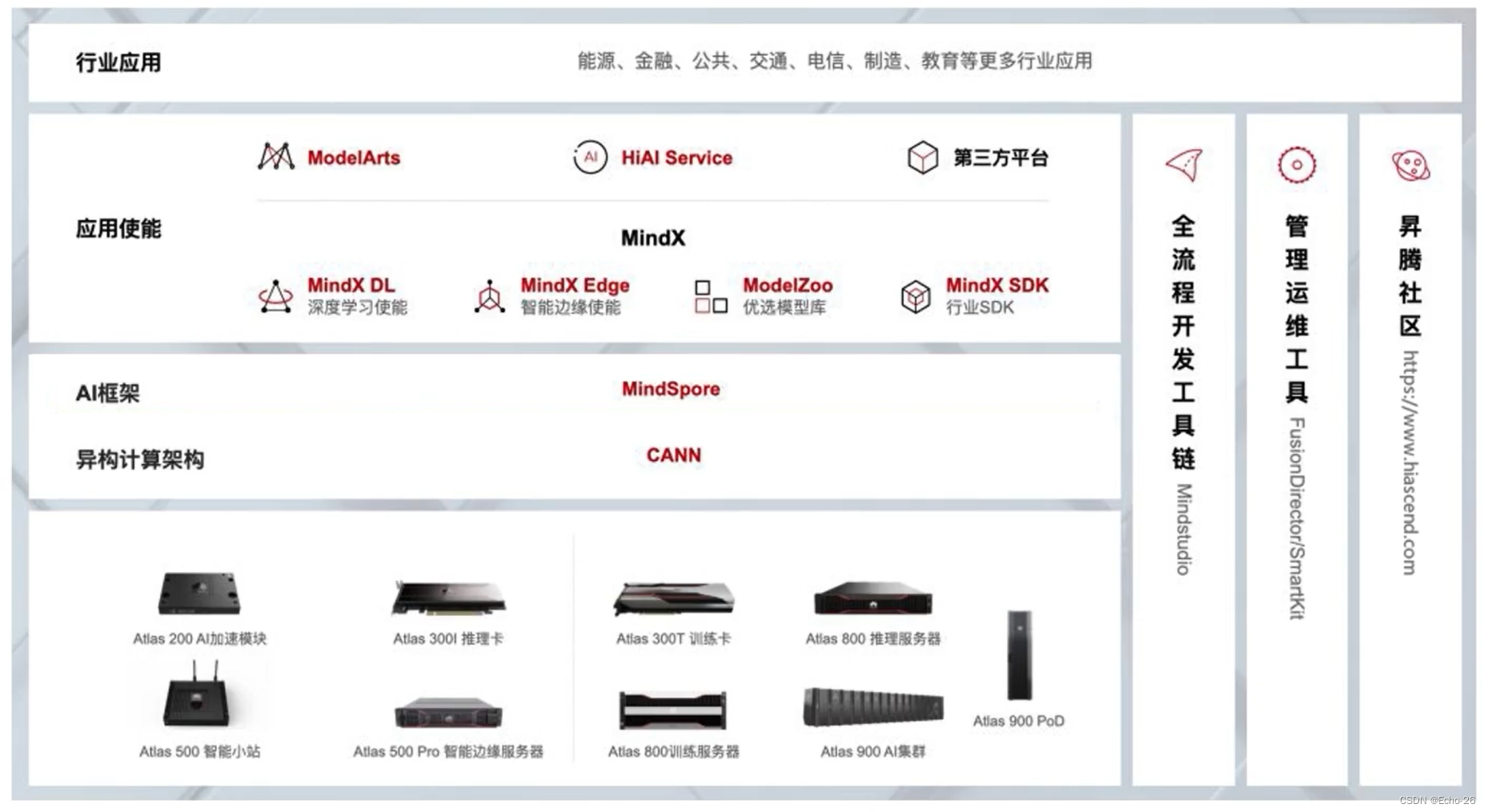
6. 华为昇腾AI全栈解决方案
二、快速入门
- 快速入门:准备数据 – 创建模型 – 损失与优化 – 训练与推理
- *MNIST数据集 + Lenet5网络模型
1. MindSpore Vision开发套件的安装
- 访问 https://gitee.com/mindspore/vision
- 克隆/下载
- 在Terminal里面输出 git clone https://gitee.com/mindspore/vision.git
- 在Terminal里面输出 cd vision
- 在Terminal里面输出 python setup.py install
2. 快速入门:手写数字识别
2.1 下载并处理数据集
- MNIST数据集是由10类 (0-9) 28*28的灰度图片组成的,训练数据集包含60000张图片,测试数据集包含10000张图片

- MindSpore Vision套件提供了用于下载并处理MNIST数据集的Mnist模块,将数据集下载、解压到指定位置并进行数据处理如下
from mindvision.dataset import Mnist
download_train = Mnist(path="./mnist", split="train", batch_size=32, shuffle=True, resize=32, download=True)
download_eval = Mnist(path="./mnist", split="test", batch_size=32, resize=32, download=True)
dataset_train = download_train.run()
dataset_eval = download_eval.run()
参数说明
path:数据集路径
split:数据集类型,支持train、test、infer,默认train
batch_size:每个训练批次设定的数据大小,默认为32,当前数据集轮次每一个迭代的大小,一起塞到网络模型里面训练的最小单位
repeat_num:训练时遍历数据集的次数,默认为1
shuffle:是否需要将数据集随机打乱 (可选参数)
resize:输出图像的图像大小,默认为32*32
download:是否需要下载数据集,默认为false
2.2 创建模型
- 按照LeNet的网络结构,LeNet除去输入层共有7层,其中有3个卷积层、2个子采样层和3个全连接层
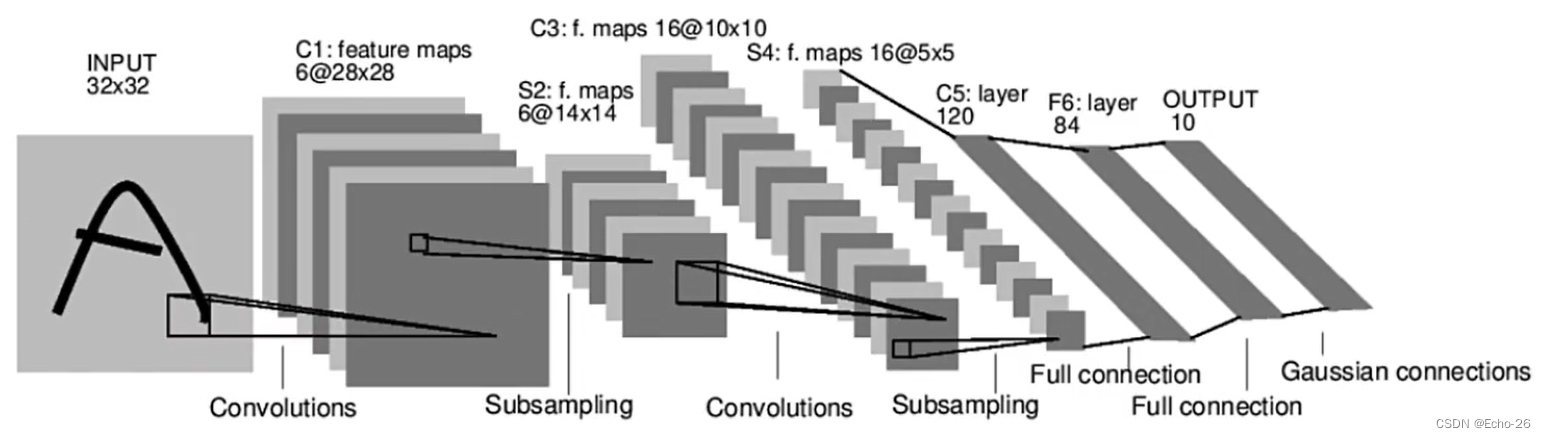
- MindSpore Vision套件提供了LeNet网络模型接口lenet,定义网络模型如下
from mindvision.classification.models import lenet
network = lenet(num_classes=10)
2.3 定义损失函数和优化器
- 要训练神经网络模型。需要定义损失函数和优化器函数
- 损失函数这里使用交叉熵损失函数SoftmaxCrossEntropyWithLogits
- 优化器这里使用Momentum
import mindspore.nn as nn
from mindspore.train import Model
定义损失函数
net_loss = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
定义优化器函数
net_opt = nn.Momentum(network.trainable_params(), learning_rate=0.01, momentum=0.9)
一般来说,学习率learning_rate不会设置太大,它控制着数据每次更新的幅度
动量momentum
2.4 训练及保存模型
- 在开始训练之前,MindSpore需要提前声明网络模型在训练过程中是否需要保存中间过程和结果,因此使用ModelCheckpoint接口用于保存网络模型和参数,以便进行后续的Fine-tuning (微调) 操作
from mindspore.train.callback import ModelCheckpoint, CheckpointConfig
设置模型保存参数
config_ck = CheckpointConfig(save_checkpoint_steps=1875, keep_checkpoint_max=10)
save_checkpoint_steps=1875 - 每1875次就会保存一次模型
keep_checkpoint_max=10 - 最大的保存次数是10
应用模型保存参数
ckpoint = ModelCheckpoint(prefix="lenet", directory="./lenet", config=config_ck)
- 通过MindSpore提供的model.train接口可以方便地进行网络的训练,LossMonitor可以监控训练过程中loss值的变化
from mindvision.engine.callback import LossMonitor
初始化模型参数
model = Model(network, loss_fn=net_loss, optimizer=net_opt, metrics={'acc'})
训练网络模型
model.train(1, dataset_train, callbacks=[ckpoint, LossMonitor(0.01)])
- 通过模型运行测试集得到的结果,验证模型的泛化能力
- 使用model.eval接口读入测试数据集
- 使用保存后的模型参数进行推理
acc = model.eval(dataset_eval)
print("{}".format(acc))
2.5 加载模型
from mindspore import load_checkpoint, load_param_into_net
加载已经保存的用于测试的模型
param_dict = load_checkpoint("./lenet/lenet-1_1875.ckpt")
加载参数到网络中
load_param_into_net(network, param_dict)
2.6 验证模型
- 我们使用生成的模型进行单个图片数据的分类预测,具体步骤为被预测的图片会随机生成,每次运行结果可能会不一样
import numpy as np
from mindspore import Tensor
import matplotlib.pyplot as plt
mnist = Mnist("./mnist", split="test", batch_size=6, resize=32)
dataset_infer = mnist.run()
ds_test = dataset_infer.create_dict_iterator() # 构建迭代器,把数据集拿出来放到内存里面
data = next(ds_test)
images = data["image"].asnumpy()
labels = data["label"].asnumpy()
plt.figure()
for i in range(1, 7):
plt.subplot(2, 3, i)
plt.imshow(images[i-1][0], interpolation="None", cmap="gray")
plt.show()
使用函数model.predict预测image对应的分类
output = model.predict(Tensor(data['image']))
predicted = np.argmax(output.asnumpy(), axis=1)
输出预测分类和实际分类
print(f'Predicted: "{predicted}", Actual: "{labels}"')
三、张量
- *张量TENSOR:初始化 – 属性 – 索引 – 转换
1. 数据格式
- 标量,向量,矩阵
2. 张量的概念
- 张量有形状,下面是几个相关术语
- 形状:张量的每个轴的长度,即元素个数
- 秩:张量轴数,标量的秩为0,向量的秩为1,矩阵的秩为2
- 轴:张量的一个特殊维度
- 大小:张量的总项数,即乘积形 状向量
- 注意:虽然我们常看到”二维张量”之类的表述,但是2秩向量通常并不是用来描述二维空间的
- 张量可以简单看作是一个高维的数据结构或者数据类型
- MindSpore中所有的数学运算和操作都是基于张量Tensor的
- 张量的属性
- 形状 (shape):Tensor的shape,是一个tuple
- 维数 (ndim):Tensor的秩,也就是len(tensor.shape),是一个整数
- 元素个数 (size):Tensor中所有元素的个数,是一个整数
- 单个元素大小 (itemsize):Tensor中每一个元素占用字节数,是一个整数
- 数据类型 (dtype):Tensor的dtype,是MindSpore的一个数据类型
- 占用字节数量 (nbytes):Tensor占用的总字节数,是一个整数
- 每一维步长 (strides):Tensor每一维所需要的字节数,是一个tuple
- 转置张量 (T):Tensor的转置,是一个Tensor
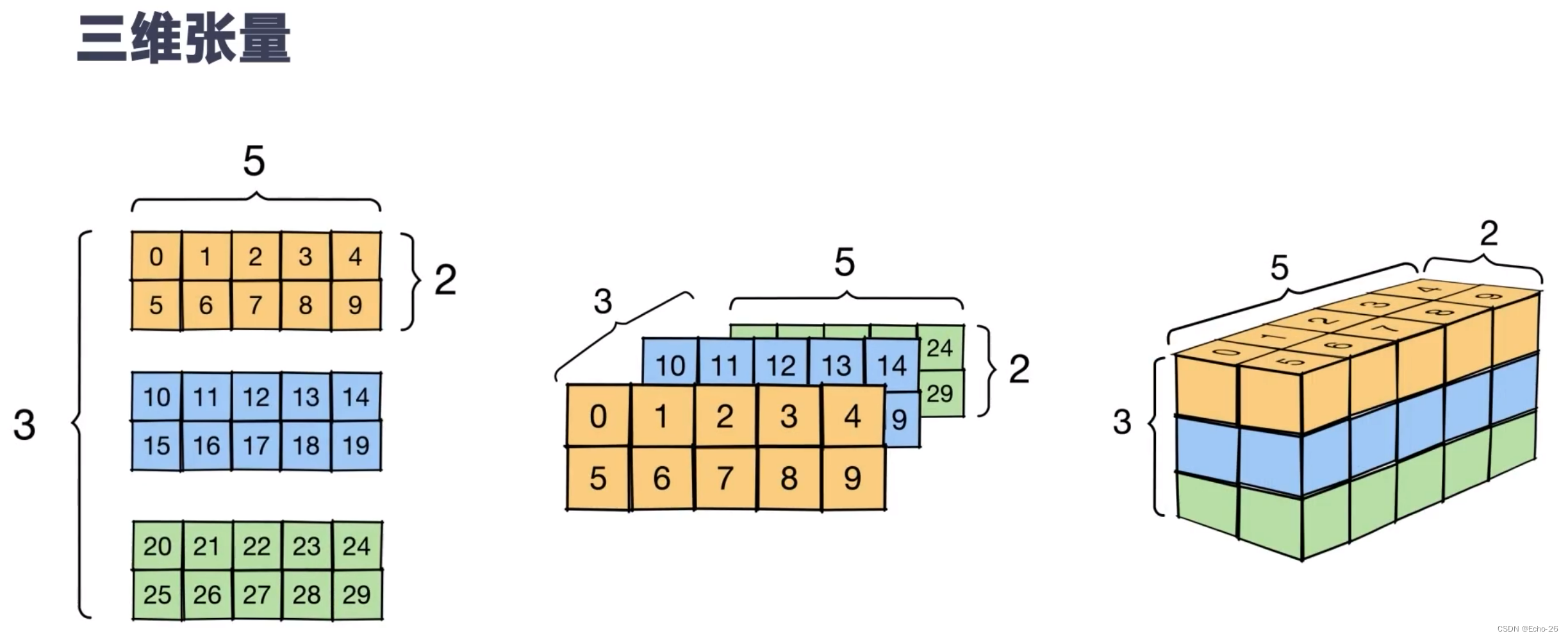
- 长宽高分别对应张量里面的三个轴
3. 创建张量
- 张量的创建方式有多种,构建张量时,支持传入Tensor、float、int、bool、tuple、list和NumPy.array类型
- 根据数据直接生成
- 可以根据数据创建张量,数据类型可以设置或者通过框架自动推断
from mindspore import Tensor
x1 = 0.5
tensor1 = Tensor(x1)
print(x1) # 0.5
print(type(x1)) #
print(tensor1) # 0.5
print(type(tensor1)) #
x2 = [0.5, 0.6]
tensor2 = Tensor(x2)
print(x2) # [0.5, 0.6]
print(type(x2)) #
print(tensor2) # [0.5 0.6]
print(type(tensor2)) #
- 从NumPy数组生成
- 可以从NumPy数组创建张量
import numpy as np
arr = np.array([1, 0, 1, 0])
x_np = Tensor(arr)
print(arr) # [1 0 1 0]
print(type(arr)) #
print(x_np) # [1 0 1 0]
print(type(x_np)) #
- 使用init初始化器构造张量
- 当使用init初始化器对张量进行初始化时,支持传入的参数有init、shape和dtype
- init:支持传入initializer的子类
- shape:支持传入list、tuple和int
- dytpe:支持传入mindspore.dtype
- 为什么需要使用构造器来构造Tensor
- 在神经网络里面,张量是一个高维数据,如果张量一开始初始化的时候做得好,可能会有助于神经网络模型的学习
- init主要用于并行模式下的延后初始化,在正常情况下不建议使用init对参数进行初始化
from mindspore import Tensor
from mindspore import set_seed
from mindspore import dtype as mstype
from mindspore.common import initializer as init
set_seed(1)
tensor3 = Tensor(shape=(2, 2), dtype=mstype.float32, init=init.One())
print(tensor3) # [[1. 1.] [1. 1.]]
print(type(tensor3)) #
tensor4 = Tensor(shape=(2, 2), dtype=mstype.float32, init=init.Normal())
print(tensor4) # [[-0.00128023 -0.01392901] [ 0.0130886 -0.00107818]]
print(type(tensor4)) #
- 继承另一个张量的属性,形成新的张量
from mindspore import ops
x3 = Tensor(np.array([[0, 1], [2, 1]]).astype(np.int32))
print(x3) # [[0 1] [2 1]]
print(type(x3)) #
onelike = ops.OnesLike()
output1 = onelike(x3)
print(output1) # [[1 1] [1 1]]
print(type(output1)) #
4. 张量属性
- 形状 (shape):Tensor的shape,是一个tuple
- 维数 (ndim):Tensor的秩,也就是len(tensor.shape),是一个整数
- 元素个数 (size):Tensor中所有元素的个数,是一个整数
- 单个元素大小 (itemsize):Tensor中每一个元素占用字节数,是一个整数
- 数据类型 (dtype):Tensor的dtype,是MindSpore的一个数据类型
- 占用字节数量 (nbytes):Tensor占用的总字节数,是一个整数
- 每一维步长 (strides):Tensor每一维所需要的字节数,是一个tuple
- 转置张量 (T):Tensor的转置,是一个Tensor
5. 张量索引
- Tensor索引和Numpy索引类似
- 索引从0开始编制,负索引表示按倒序编制
- 冒号:和…用于对数据进行切片
tensor5 = Tensor(np.array([[0, 1], [2, 3]]).astype(np.int32))
print("Tensor: ", tensor5) # Tensor: [[0 1] [2 3]]
print("First row: ", tensor5[0]) # First row: [0 1]
print("Value of top right corner: ", tensor5[0, 1]) # Value of top right corner: 1
print("Last column: ", tensor5[:, -1]) # Last column: [1 3]
print("Last column: ", tensor5[..., -1]) # Last column: [1 3]
print("First column: ", tensor5[:, 0]) # First column: [0 2]
print("First column: ", tensor5[..., 0]) # First column: [0 2]
6. 张量运算
- 张量之间有很多运算,包括算数、线性代数、矩阵处理 (转置、标引、切片) 和采样等,张量运算和NumPy的使用方式类似
- 普通算数运算有:加 (+)、减 (-)、乘 (*)、除 (/)、取模 (%)、整除 (//)
- Concat将给定维度上的一系列张量连接起来
tensor6 = Tensor(np.array([[0, 1], [2, 3]]).astype(np.int32))
tensor7 = Tensor(np.array([[4, 5], [6, 7]]).astype(np.int32))
op = ops.Concat()
output2 = op((tensor6, tensor7))
print("tensor6: ", tensor6) # Tensor6: [[0 1] [2 3]]
print("tensor7: ", tensor7) # Tensor7: [[4 5] [6 7]]
print("output2: ", output2) # output2: [[0 1] [2 3] [4 5] [6 7]]
print("output2 shape: ", output2.shape) # output2 shape: (4, 2)
7. Tensor和NumPy转换
- Tensor可以和NumPy进行相互转换
- Tensor转换为NumPy
- 使用 asnumpy()将Tensor变量转换为NumPy变量
- NumPy转换为Tensor
- 与张量创建相同,使用 Tensor()将NumPy变量转换为Tensor变量
Tensor转换为NumPy,使用asnumpy()将Tensor变量转换为NumPy变量
zeros = ops.Zeros()
tensor_x = zeros((2, 2), mstype.float32)
numpy_x = tensor_x.asnumpy()
print(type(tensor_x)) #
print(type(numpy_x)) #
NumPy转换为Tensor,与张量创建相同,使用Tensor()将NumPy变量转换为Tensor变量
output3 = np.array([1, 0, 1, 0])
t_output3 = Tensor(output3)
print(type(output3)) #
print(type(t_output3)) #
四、数据处理
- 数据处理:整体流程 – 加载 – 迭代 – 处理与增强
- *输入Tensor – 数据处理 – 输入到神经网络模型 – 数据的加载 – 数据的迭代 – 数据的处理与增强
1. MindSpore数据处理的整体流程
- 在网络训练和推理流程中,原始数据一般存储在磁盘或数据库中,需要首先通过数据加载步骤将其读取到内存空间,转换成框架通用的张量 (Tensor) 格式,然后通过数据处理和增强步骤,将其映射到更加易于学习的特征空间,同时增加样本的数量和泛化性,最后输入到网络进行计算
- 第一步,把数据加载到内存中里面,但内存空间是有限的,而磁盘是非常大的,所以我们使用采样器sampler,通过采样器把一部分数据加载到内存里面,在输入到神经网络模型之前把这些数据变成MindSpore的一个Tensor
- 数据集加载使得模型训练时能源源不断地获取数据进行训练,Dataset对多种常用的数据集提供对应的类来实现数据集的加载,同时对于不同存储格式的数据文件,Dataset也有对应的类来进行数据加载
- Dataset提供了多种用途的采样器 (Sampler),采样器负责生成读取的index序列,Dataset负责根据index读取相应数据,帮助用户对数据集进行不同形式的采样,以满足训练需求,解决诸如数据集过大或样本类别分布不均等问题
- 注意,采样器负责对样本做filter和reorder操作,不会执行Batch操作
- 第二步,把这个Tensor输入给Transform模块,Transform模块会对数据处理进行一系列的变换,如打散、清洗等,让我们的数据更加丰富,提升数据的泛化性
- Dataset将数据加载到内存后,数据按Tensor形式进行组织。同时Tensor也是数据增强操作中的基本数据结构
- 第三步,把数据输入到神经网络模型进行训练
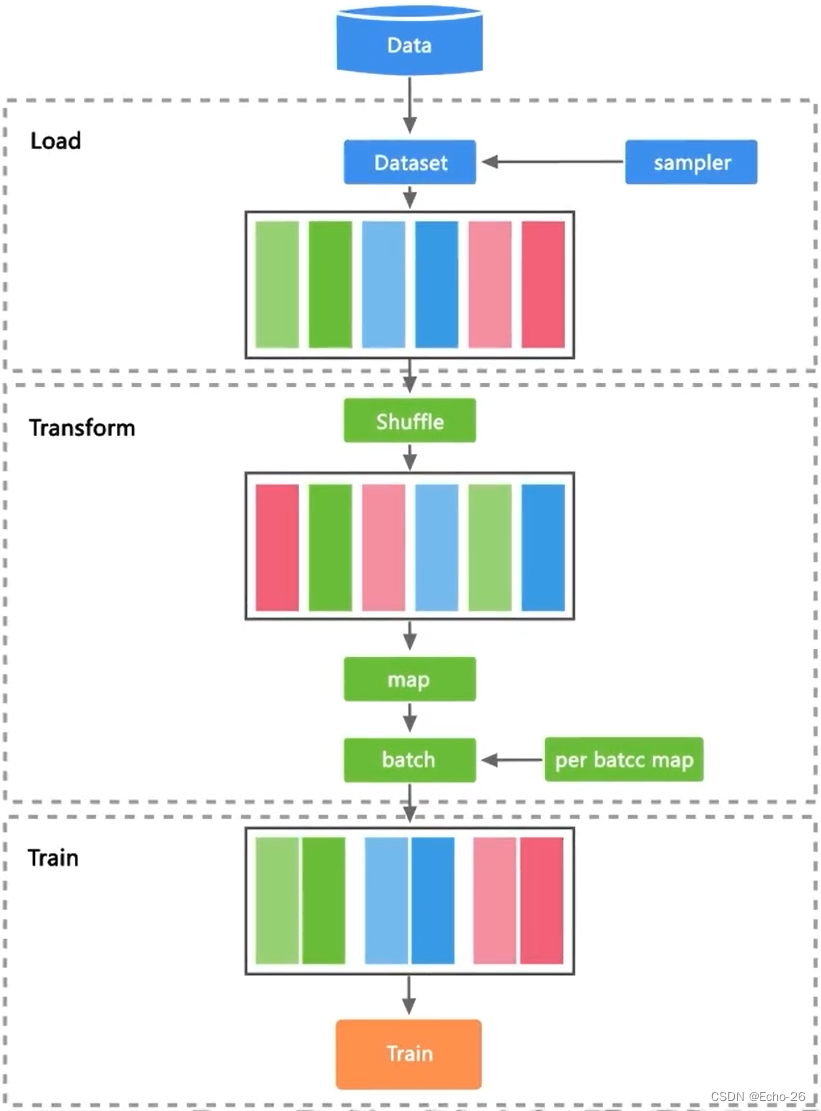
2. 下载并加载数据集
- CIFAR-10数据集共有60000张32*32的彩色图像,分为10个类别,每一类有6000张图片,数据集中一共有50000张训练图片和10000张测试图片,cifar-10接口提供CIFAR-10数据集的下载和加载功
from mindvision.dataset import Cifar10
数据集根目录
data_dir = "./datasets"
下载解压并加载CIFAR-10训练数据集
dataset = Cifar10(path=data_dir, split="train", batch_size=6, resize=32, download=True)
dataset = dataset.run()
CIFAR-10数据集文件的目录结构
datasets/
├── cifar-10-batches-py
│ ├── batches.meta
│ ├── data_batch_1
│ ├── data_batch_2
│ ├── data_batch_3
│ ├── data_batch_4
│ ├── data_batch_5
│ ├── readme.html
│ └── test_batch
└── cifar-10-python.tar.gz
3. 迭代数据集
- 用户可以用create_dict_iterator接口创建数据迭代器,迭代访问数据,访问的数据类型默认为Tensor,若设置output_numpy=True,访问的数据类型为Numpy
next():把下一批的数据集通过迭代的方式去访问
data = next(dataset.create_dict_iterator())
Data type:
Image shape: (6, 3, 32, 32)
6*3*32*32的张量
32是图片的大小32*32
3是3个通道,意味着图片是彩色的,
6是batch_size的大小,即每一批塞到内存里面的数据集有多少张32*32*3图片
Label: [7 1 2 8 7 8]
print(f"Data type:{type(data['image'])}\nImage shape: {data['image'].shape}\nLabel: {data['label']}")
Data type:
Image shape: (6, 3, 32, 32)
Label: [8 0 0 2 6 1]
data = next(dataset.create_dict_iterator(output_numpy=True))
print(f"Data type:{type(data['image'])}\nImage shape: {data['image'].shape}\nLabel: {data['label']}")
4. 数据处理
- mindvision.dataset.Cifar10接口提供数据处理功能,只要设置相应的属性即可对数据进行处理操作
- shuffle:是否打乱数据集的顺序,设置为True时打乱数据集的顺序,默认为false
- batch_size:每组包含的数据个数,batch_size=2设置每组包含2个数据,batch_size值默认大小为32
- repeat_num:重复数据集的个数,repeat_num=1即一份数据集,repeat_num值默认大小为1
import numpy as np
import matplotlib.pyplot as plt
import mindspore.dataset.vision.c_transforms as transforms
trans = [transforms.HWC2CHW()]
dataset = Cifar10(data_dir, batch_size=6, resize=32, repeat_num=1, shuffle=True, transform=trans)
data = dataset.run()
data = next(data.create_dict_iterator())
images = data["image"].asnumpy()
labels = data["label"].asnumpy()
print(f"Image shape: {images.shape}, Label: {labels}") # Image shape: (6, 3, 32, 32), Label: [9 3 8 9 6 8]
plt.figure()
for i in range(1, 7):
plt.subplot(2, 3, i)
image_trans = np.transpose(images[i-1], (1, 2, 0))
plt.title(f"{dataset.index2label[labels[i-1]]}")
plt.imshow(image_trans, interpolation="None")
plt.show()

5. 数据增强
- 数据量过小或是样本场景单一等问题会影响模型的训练效果,用户可以通过数据增强操作扩充样本多样性,从而提升模型的泛化能力
- mindvision.dataset.Cifar10接口使用默认的数据增强功能,用户可通过设置属性transform和target_transform进行数据增强操作
- transform:对数据集图像数据进行增强
- target_transform:对数据集标签数据进行处理
- mindspore.dataset.vision.c_transforms模块中的算子对CIFAR-10数据集进行数据增强
import numpy as np
import matplotlib.pyplot as plt
import mindspore.dataset.vision.c_transforms as transforms
图像增强
trans = [
transforms.RandomCrop((32, 32), (4, 4, 4, 4)), # 对图像进行自动裁剪
transforms.RandomHorizontalFlip(prob=0.5), # 对图像进行随机水平翻转
transforms.HWC2CHW(), # (h, w, c)转换为(c, h, w)
]
dataset = Cifar10(data_dir, batch_size=6, resize=32, transform=trans)
data = dataset.run()
data = next(data.create_dict_iterator())
images = data["image"].asnumpy()
labels = data["label"].asnumpy()
print(f"Image shape: {images.shape}, Label: {labels}") # Image shape: (6, 3, 32, 32), Label: [9 3 8 9 6 8]
plt.figure()
for i in range(1, 7):
plt.subplot(2, 3, i)
image_trans = np.transpose(images[i-1], (1, 2, 0))
plt.title(f"{dataset.index2label[labels[i-1]]}")
plt.imshow(image_trans, interpolation="None")
plt.show()

五、创建网络
- 创建网络:定义模型 – 模型参数 – 构建网络
- 神经网络模型由多个数据操作层组成,mindspore.nn提供了各种网络基础模块
- 我们以构建LeNet-5网络为例,先展示使用mindspore.nn建立神经网络模型,再展示使用mindvision.classification.models快速构建LeNet-5网络模型
- mindvision.classification.models是基于mindspore.nn开发的网络模型接口,提供了一些经典且常用的网络模型,方便用户使用
1. LeNet-5模型
- LeNet-5模型是Yann LeCun教授于1998年提出的一种典型的卷积神经网络,在MNIST数据集上达到99.4%准确率,是CNN领域的第一篇经典之作
- C代表卷积层,S代表采样层,F代表全连接层
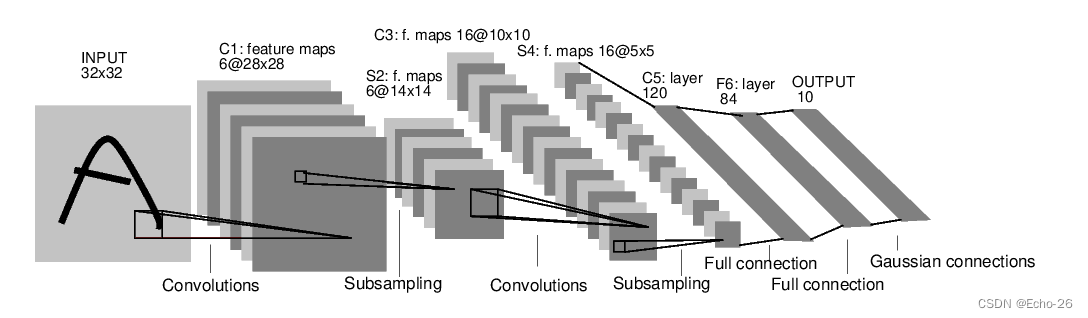
2. 定义模型类
- 图片的输入size固定在32∗3232∗32,为了获得良好的卷积效果,要求数字在图片的中央,所以输入32∗3232∗32其实为28∗2828∗28图片填充后的结果
- 另外不像CNN网络三通道的输入图片,LeNet图片的输入仅是规范化后的二值图像,网络的输出为0~9十个数字的预测概率,可以理解为输入图像属于0~9数字的可能性大小
- MindSpore的cell类是构建所有网络的基类,也是网络的基本单元。构建神经网络时,需要继承cell类,并重写_init_方法和construct方法
import mindspore.nn as nn
class LeNet5(nn.Cell):
"""
LeNet-5网络结构
"""
def __init__(self, num_class=10, num_channel=1):
super(LeNet5, self).__init__()
# 卷积层,输入的通道数为num_channel,输出的通道数为6,卷积核大小为5*5
self.conv1 = nn.Conv2d(num_channel, 6, 5, pad_mode='valid')
# 卷积层,输入的通道数为6,输出的通道数为16,卷积核大小为5*5
self.conv2 = nn.Conv2d(6, 16, 5, pad_mode='valid')
# 全连接层,输入个数为16*5*5,输出个数为120
self.fc1 = nn.Dense(16 * 5 * 5, 120)
# 全连接层,输入个数为120,输出个数为84
self.fc2 = nn.Dense(120, 84)
# 全连接层,输入个数为84,分类的个数为num_class
self.fc3 = nn.Dense(84, num_class)
# ReLU激活函数
self.relu = nn.ReLU()
# 池化层
self.max_pool2d = nn.MaxPool2d(kernel_size=2, stride=2)
# 多维数组展平为一维数组
self.flatten = nn.Flatten()
def construct(self, x):
# 使用定义好的运算构建前向网络
x = self.conv1(x)
x = self.relu(x)
x = self.max_pool2d(x)
x = self.conv2(x)
x = self.relu(x)
x = self.max_pool2d(x)
x = self.flatten(x)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.relu(x)
x = self.fc3(x)
return x
model = LeNet5()
print(model)
'''
LeNet5<
(conv1): Conv2d
(conv2): Conv2d
(fc1): Dense
(fc2): Dense
(fc3): Dense
(relu): ReLU<>
(max_pool2d): MaxPool2d
(flatten): Flatten<>
>
'''
3. 模型层
- 首先介绍LeNet-5网络中使用到cell类的关键成员函数,然后通过实例化网络介绍如何利用cell类访问模型参数
- nn.Conv2d
- 卷积层,卷积算子在通讯中会经常用到,其实就是滤波操作
- 加入nn.Conv2d层,给网络中加入卷积函数,帮助神经网络提取特征
import numpy as np
from mindspore import Tensor
from mindspore import dtype as mstype
输入的通道数为1,输出的通道数为6,卷积核大小为5*5,使用normal算子初始化参数,不填充像素
conv2d = nn.Conv2d(1, 6, 5, has_bias=False, weight_init='normal', pad_mode='valid')
input_x = Tensor(np.ones([1, 1, 32, 32]), mstype.float32)
print(conv2d(input_x).shape) # (1, 6, 28, 28)
28*28是因为卷积的特殊计算方式,在卷积核进行滤波操作时,图像最边缘的地方因为卷积核没有办法覆盖,所以最终计算的时候,就会去掉边缘的值
输入的通道数为1,输出的通道数为6,卷积核大小为5*5,使用normal算子初始化参数,不填充像素
conv2d = nn.Conv2d(1, 6, 5, has_bias=False, weight_init='normal', pad_mode='same')
input_x = Tensor(np.ones([1, 1, 32, 32]), mstype.float32)
print(conv2d(input_x).shape) # (1, 6, 32, 32)
32*32是因为卷积之前自动对边缘值进行补充,所以卷积的输出和输入是一样的
- nn.Relu
- 激活层
- 加入nn.Relu层,给网络中加入非线性的激活函数,帮助神经网络学习各种复杂的特征
relu = nn.ReLU()
input_x = Tensor(np.array([-1, 2, -3, 2, -1]), mstype.float16)
output = relu(input_x)
print(output) # [0. 2. 0. 2. 0.]
- nn.MaxPool2d
- 采样层或者池化层
- 初始化nn.MaxPool2d层,将6×28×28的张量降采样为6×7×7的张量
max_pool2d = nn.MaxPool2d(kernel_size=2, stride=2) # 采样的窗口设置为2*2,步长设置为2
input_x = Tensor(np.ones([1, 6, 28, 28]), mstype.float32)
print(max_pool2d(input_x).shape) # (1, 6, 14, 14)
max_pool2d = nn.MaxPool2d(kernel_size=4, stride=4) # 采样的窗口设置为4*4,步长设置为4
input_x = Tensor(np.ones([1, 6, 28, 28]), mstype.float32)
print(max_pool2d(input_x).shape) # (1, 6, 7, 7)
- nn.Flatten
- 初始化nn.Flatten层,将1×16×5×5的四维张量转换为400个连续元素的二维张量
flatten = nn.Flatten()
input_x = Tensor(np.ones([1, 16, 5, 5]), mstype.float32)
output = flatten(input_x)
print(output.shape) # (1, 400)
- nn.Dense
- 全连接层,矩阵相乘
- 初始化nn.Dense层,对输入矩阵进行线性变换
dense = nn.Dense(400, 120, weight_init='normal')
input_x = Tensor(np.ones([1, 400]), mstype.float32)
output = dense(input_x)
print(output.shape) # (1, 120)
4. 模型参数
- 网络内部的卷积层和全连接层等实例化后,即具有权重参数和偏置参数,这些参数会在训练过程中不断进行优化,在训练过程中可通过get_parameters()来查看网络各层的名字、形状、数据类型和是否反向计算等信息
for m in model.get_parameters():
print(f"layer:{m.name}, shape:{m.shape}, dtype:{m.dtype}, requeires_grad:{m.requires_grad}")
layer:backbone.conv1.weight, shape:(6, 1, 5, 5), dtype:Float32, requeires_grad:True
layer:backbone.conv2.weight, shape:(16, 6, 5, 5), dtype:Float32, requeires_grad:True
layer:backbone.fc1.weight, shape:(120, 400), dtype:Float32, requeires_grad:True
layer:backbone.fc1.bias, shape:(120,), dtype:Float32, requeires_grad:True
layer:backbone.fc2.weight, shape:(84, 120), dtype:Float32, requeires_grad:True
layer:backbone.fc2.bias, shape:(84,), dtype:Float32, requeires_grad:True
layer:backbone.fc3.weight, shape:(10, 84), dtype:Float32, requeires_grad:True
layer:backbone.fc3.bias, shape:(10,), dtype:Float32, requeires_grad:True
5. 快速构建LeNet-5网络模型
- 上述介绍了使用mindspore.cell构建LeNet-5网络模型,在mindvision.classification.models中已有构建好的网络模型接口,也可使用
lenet接口直接构建LeNet-5网络模型
from mindvision.classification.models import lenet
num_classes表示分类的数量,pretrained表示是否使用与训练模型进行训练
model = lenet(num_classes=10, pretrained=False)
for m in model.get_parameters():
print(f"layer:{m.name}, shape:{m.shape}, dtype:{m.dtype}, requeires_grad:{m.requires_grad}")
layer:backbone.conv1.weight, shape:(6, 1, 5, 5), dtype:Float32, requeires_grad:True
layer:backbone.conv2.weight, shape:(16, 6, 5, 5), dtype:Float32, requeires_grad:True
layer:backbone.fc1.weight, shape:(120, 400), dtype:Float32, requeires_grad:True
layer:backbone.fc1.bias, shape:(120,), dtype:Float32, requeires_grad:True
layer:backbone.fc2.weight, shape:(84, 120), dtype:Float32, requeires_grad:True
layer:backbone.fc2.bias, shape:(84,), dtype:Float32, requeires_grad:True
layer:backbone.fc3.weight, shape:(10, 84), dtype:Float32, requeires_grad:True
layer:backbone.fc3.bias, shape:(10,), dtype:Float32, requeires_grad:True
Original: https://blog.csdn.net/qq_36404481/article/details/125046293
Author: Echo-26
Title: 华为AI计算框架昇思MindSpore零基础快速入门 (上)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/650854/
转载文章受原作者版权保护。转载请注明原作者出处!