

导读
继续PyTorch学习系列。前篇介绍了PyTorch中最为基础也最为核心的数据结构——Tensor,有了这些基本概念即可开始深度学习实践了。本篇围绕这一话题,本着提纲挈领删繁就简的原则,从宏观上介绍搭建深度学习模型的几个基本要素。
不同于经典的机器学习流程,深度学习模型的搭建和训练更为灵活和简单,称之为灵活是因为一般没有成熟和直接可用的模型,而更多需要使用者自己去设计和组装各个网络模块;称之为简单是因为深度学习往往实现端到端的训练,即直接从原始数据集到模型输出,而无需经典机器学习中的数据预处理、特征工程、特征选择等多阶段式的工作流。

类似于把大象装进冰箱需要3步一样,构建一个深度学习模型也可以将其分为三步:
- 数据集准备
- 模型定义
- 模型训练
本文就首先围绕这三个环节加以介绍,然后给出一个简单的应用案例。
01 数据集准备
理论上,深度学习中的数据集准备与经典机器学习中的数据集准备并无本质性差别,大体都是基于特定的数据构建样本和标签的过程,其中这里的样本依据应用场景的不同而有不同的样式,比如CV领域中典型的就是图片,而NLP领域中典型的就是一段段的文本。但无论原始样本如何,最终都要将其转化为数值型的Tensor。
当然,将数据集转化为Tensor之后理论上即可用于深度学习模型的输入和训练,但为了更好的支持模型训练以及大数据集下的分batch进行训练,PyTorch中提供了标准的数据集类型(Dataset),而我们则一般是要继承此类来提供这一格式。这里主要介绍3个常用的数据集相关的类:
- Dataset:所有自定义数据集的基类
- TensorDataset:Dataset的一个wrapper,用于快速构建Dataset
- DataLoader:Dataset的一个wrapper,将Dataset自动划分为多个batch
1.Dataset
Dataset是PyTorch中提供的一个数据集基类,首先查看Dataset的签名文档如下:
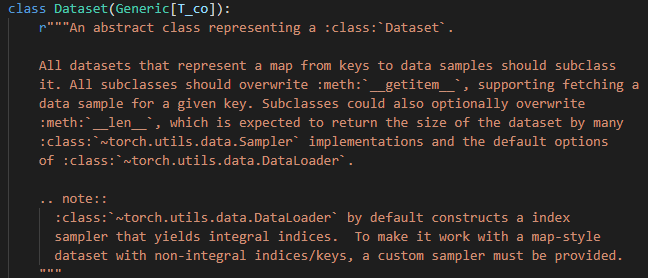
从中可以看出,所有自定义的数据集都应继承此类,并重载其中的__getitem__和__len__两个方法即可。当然,还需通过类初始化方法__init__来设置要加载的数据。典型的自定义一个Dataset的实现如下:
class MyDataset(Dataset):
def __init__(self, x, y):
super().__init__()
......
def __getitem__(self):
return ......
def __len__(self):
return ......
2.TensorDataset
上述通过Dataset的方式可以实现一个标准自定义数据集的构建,但如果对于比较简单的数据集仍需八股文似的重载__getitem__和__len__两个方法,则难免有些繁杂和俗套。而TensorDataset就是对上述需求的一个简化,即当仅需将特定的tensor包裹为一个Dataset类型作为自定义数据集时,那么直接使用TensorDataset即可。这里仍然先给出其签名文档:
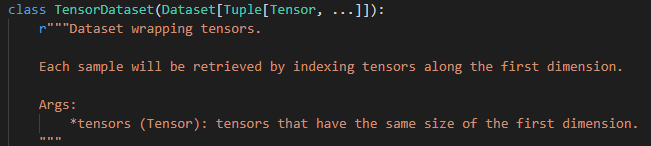
具体应用时,只需将若干个tensor格式的输入作为参数传入TensorDataset,而后返回结果即是一个标准的Dataset类型数据集。标准使用方式如下:
my_dataset = TensorDataset(tenso_x, tensor_y)
3.DataLoader
深度学习往往适用于大数据集场景,训练一个成熟的深度学习模型一般也需要足够体量的数据。所以,在深度学习训练过程中一般不会每次都将所有训练集数据一次性的喂给模型,而是小批量分批次的训练,其中每个批量叫做一个batch,完整的训练集参与一次训练叫做一个epoch。实现小批量多批次的方式有很多,比如完全可以通过随机取一个索引分片的方式来实现这一工作,但更为标准和优雅的方式则是使用Dataloader。其给出的签名文档如下:
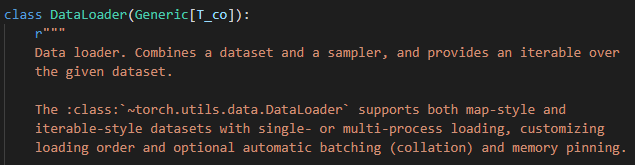
可见,DataLoader大体上可以等价为对一个Dataset实现随机采样(sampler),而后对指定数据集提供可迭代的类型。相应的,其使用方式也相对简单:直接将一个Dataset类型的数据集作为参数传入DataLoader即可。简单的使用样例如下:
dataloader = DataLoader(MyDataset, batch_size=128, shuffle=True)
以上是应用PyTorch构建数据集时常用的三种操作,基本可以覆盖日常使用的绝大部分需求,后面会结合实际案例加以完整演示。
02 网络架构定义
深度学习与经典机器学习的一个最大的区别在于模型结构方面,经典机器学习模型往往有着固定的范式和结构,例如:随机森林就是由指定数量的决策树构成,虽然这里的n_estimators可以任选,但整体来看随机森林模型的结构是确定的;而深度学习模型的基础在于神经网络,即由若干的神经网络层构成,每一层使用的神经网络模块类型可以不同(全连接层、卷积层等等),包含的神经元数量差异也会带来很大的不同。也正因如此,深度学习给使用者提供了更大的设计创新空间。
当然,网络架构(Architecture)的设计不需要从零开始,PyTorch这些深度学习框架的一大功能就是提供了基础的神经网络模块(Module),而使用者仅需根据自己的设计意图将其灵活组装起来即可——就像搭积木一般!PyTorch中所有网络模块均位于torch.nn模块下(nn=nueral network),总共包括以下模块:
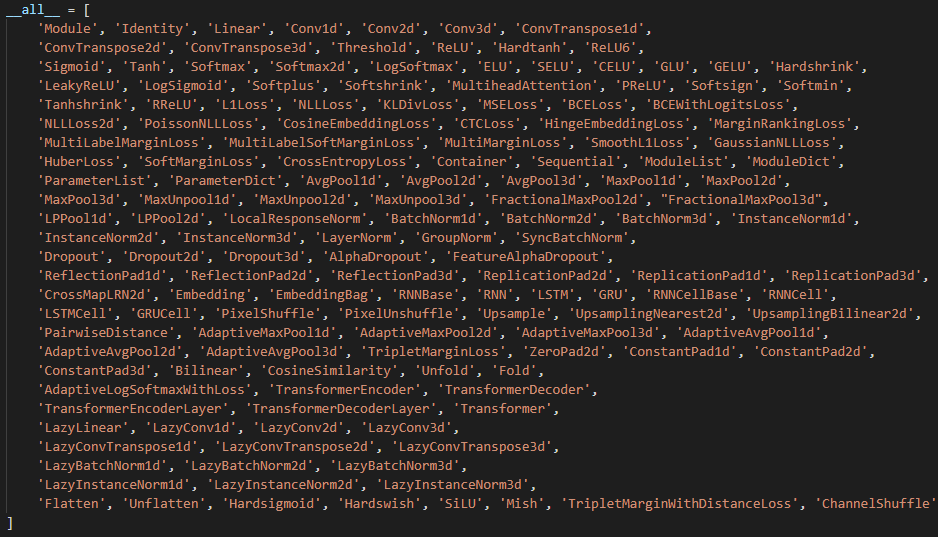
这些模块数量庞大,功能各异,构成了深度学习模型的核心。但就其功能而言,大体分为以下几类:
- 模型功能类:例如Linear、Conv2d,RNN等,分别对应全连接层、卷积层、循环神经网络层,
- 激活函数:例如Sigmoid,Tanh,ReLU等,
- 损失函数:CrossEntropyLoss,MSELoss等,其中前者是分类常用的损失函数,后者是回归常用的损失函数
- 规范化:LayerNorm等,
- 防止过拟合:Dropout等
- 其他
某种程度上讲,学习深度学习的主体在于理解掌握这些基础的网络模块其各自的功能和使用方法,在此基础上方可根据自己对数据和场景的理解来自定义设计网络架构,从而实现预期的模型效果。
该部分内容过于庞大,断不是一篇两篇推文能解释清楚的,自认当前自己也不足以完全理解,所以对这些模块的学习和介绍当徐徐图之、各个击破。
在这些单个网络模块的基础上,构建的完整网络模型则需继承PyTorch中的Module类来加以实现(这一过程类似于继承Dataset类实现自定义数据集),这里仍然给出Module的签名文档:
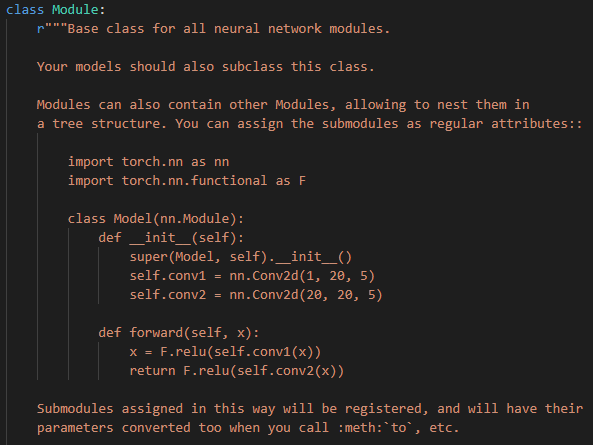
从中可以看出,所有自定义的网络模型均需继承Module类,并一般需要重写forward函数(用于实现神经网络的前向传播过程),而后模型即完成了注册,并拥有了相应的可训练参数等。
03 模型训练
仍然与经典机器学习模型的训练不同,深度学习模型由于其网络架构一般是自定义设计的,所以一般也不能简单的通过调用fit/predict的方式来实现简洁的模型训练/预测过程,而往往交由使用者自己去实现。
大体上,实现模型训练主要包含以下要素:
- 完成数据集的准备和模型定义
- 指定一个损失函数,用于评估当前模型在指定数据集上的表现
- 指定一个优化器,用于”指导”模型朝着预期方向前进
- 写一个循环调度,实现模型训练的迭代和进化
数据集的准备和模型定义部分就是前两小节所述内容;而损失函数,简单需求可以依据PyTorch提供的常用损失函数,而更为复杂和个性化的损失函数则继承Module类的方式来加以自定义实现;优化器部分则无太多”花样”可言,一般直接调用内置的优化器即可,例如Adam、SGD等等。
这些操作结合后续的实践案例一并介绍。
04 一个简单的深度学习案例
麻雀虽小五脏俱全,解剖一只麻雀,可有助于探悟内涵实质和基本规律。
有了前述小节的理论基础,就可以开始深度学习实践案例了,这里以sklearn中自带的手写数字分类作为目标来加以实践。
1.首先给出 应用sklearn中随机森林模型的实现方式和效果
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
X, y = load_digits(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y)
rf = RandomForestClassifier().fit(X_train, y_train)
rf.score(X_test, y_test)
### 输出:0.9688888888888889
当然,该数据集分类的难度不大,即使在未经过调参的情况下也取得了很好的分类效果。
2.基于PyTorch的深度学习模型训练实践,这里按照标准的深度学习训练流程,仍然使用上述手写数字分类数据集进行实验:
a.构建Dataset类型数据集
import torch
from torch.utils.data import TensorDataset, DataLoader
X_train_tensor = torch.Tensor(X_train)
y_train_tensor = torch.Tensor(y_train).long() # 主要标签需要用整数形式,否则后续用于计算交叉熵损失时报错
dataset = TensorDataset(X_train_tensor, y_train_tensor) # 直接调用TensorDataset加以包裹使用
dataloader = DataLoader(dataset, batch_size=128, shuffle=True) # 每128个样本为一个batch,训练时设为随机
X_test_tensor = torch.Tensor(X_test) # 测试集只需转化为tensor即可
y_test_tensor = torch.Tensor(y_test).long()
b.自定义一个网络模型,仅使用Linear网络层
from torch import nn, optim
class Model(nn.Module): # 继承Module基类
def __init__(self, n_input=64, n_hidden=32, n_ouput=10):
# 定义一个含有单隐藏层的全连接网络,其中输入64为手写数字数据集的特征数,输出10为类别数,隐藏层神经元数量设置32
super().__init__()
# 使用全连接层和ReLU激活函数搭建网络模型
self.dnn = nn.Sequential(
nn.Linear(n_input, n_hidden),
nn.ReLU(),
nn.Linear(n_hidden, n_output)
)
def forward(self, x):
# 重载forward函数,从输入到输出
return self.dnn(x)
c.八股文式的深度学习训练流程
model = Model() # 初始化模型
creterion = nn.CrossEntropyLoss() # 选用交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # 选用Adam优化器,传入模型参数,设置学习率
for epoch in range(50): # 50个epoch
for data, label in dataloader: # DataLoader是一个可迭代对象
optimizer.zero_grad() # 待优化参数梯度清空
prob = model(data) # 执行一次前向传播,计算预测结果
loss = creterion(prob, label) # 评估模型损失
loss.backward() # 损失反向传播,完成对待优化参数的梯度求解
optimizer.step() # 参数更新
if (epoch + 1) % 5 == 0: # 每隔5个epoch打印当前模型训练效果
with torch.no_grad():
train_prob = model(X_train_tensor)
train_pred = train_prob.argmax(dim=1)
acc_train = (train_pred==y_train_tensor).float().mean()
test_prob = model(X_test_tensor)
test_pred = test_prob.argmax(dim=1)
acc_test = (test_pred==y_test_tensor).float().mean()
print(f"epoch: {epoch}, train_accuracy: {acc_train}, test_accuracy: {acc_test} !")
### 输出
epoch: 4, train_accuracy: 0.8507795333862305, test_accuracy: 0.8577777743339539 !
epoch: 9, train_accuracy: 0.948775053024292, test_accuracy: 0.9200000166893005 !
epoch: 14, train_accuracy: 0.9717891812324524, test_accuracy: 0.9444444179534912 !
epoch: 19, train_accuracy: 0.9799554347991943, test_accuracy: 0.9577777981758118 !
epoch: 24, train_accuracy: 0.9866369962692261, test_accuracy: 0.9644444584846497 !
epoch: 29, train_accuracy: 0.9925761222839355, test_accuracy: 0.9644444584846497 !
epoch: 34, train_accuracy: 0.9925761222839355, test_accuracy: 0.9644444584846497 !
epoch: 39, train_accuracy: 0.9962880611419678, test_accuracy: 0.9666666388511658 !
epoch: 44, train_accuracy: 0.9970304369926453, test_accuracy: 0.9711111187934875 !
epoch: 49, train_accuracy: 0.9970304369926453, test_accuracy: 0.9711111187934875 !
至此,就完成了一个深度学习模型训练的基本流程,从数据集准备到模型定义,直至最后的模型训练及输出。当然,由于该数据集分类任务比较简单,加之数据量不大,所以深度学习的优势并不明显。
相关阅读:
- *
*
Original: https://blog.csdn.net/weixin_43841688/article/details/123343656
Author: 小数志
Title: PyTorch学习系列教程:构建一个深度学习模型需要哪几步?
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/650711/
转载文章受原作者版权保护。转载请注明原作者出处!