

BEVFusion这个名字是有撞车的
两个自动驾驶相关的文章都是这个简称
- BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation mit-han-lab/bevfusion: BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation (github.com) 主要是从模型加速的方向去进行优化的,暂时还没有细读,主要解读第二篇。
 BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework ADLab-AutoDrive/BEVFusion: Offical PyTorch implementation of “BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework” (github.com) 这篇文章主要从工业落地的角度出发,提出解决鲁棒性问题。
BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework ADLab-AutoDrive/BEVFusion: Offical PyTorch implementation of “BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework” (github.com) 这篇文章主要从工业落地的角度出发,提出解决鲁棒性问题。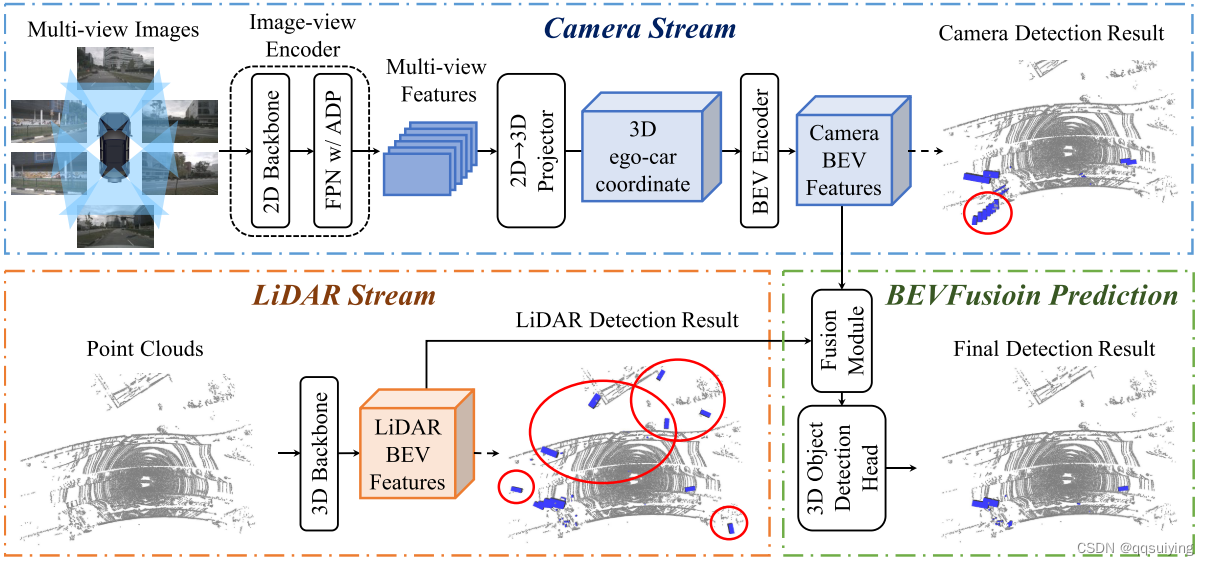
另一个有意思的是,这两个工作,从github粗看,应该都是用到了mmdet3d的框架

在右侧的A Simple and Robust LiDAR-Camera Fusion Framework中,似乎2d的检测也是使用的mmdet的框架。感觉这两个的代码阅读应该都会相对于友好一些(希望是这样…..)
一些背景:
感知模块(如3D BBox检测,3D语义分割)一直是自动驾驶系统里最重要的环节之一,为了达到足够的安全冗余,车辆上一般会集成多种传感器,如激光雷达,摄像头,毫米波雷达等,这些传感器特性不同,能够起到很好的互补作用。在面向L4的自动驾驶系统里,激光雷达(后面简称雷达)和摄像头(通常也称为视觉)起到的作用会更加重大,所以无论是学术上还是工业上,这二者的融合算法一直都是一个非常热门的研究领域。
通常,雷达和视觉的融合策略分为三种类型:决策层融合(通常我们称为 后融合),决策+特征融合( 中间层融合),特征融合( 前融合), 后融合就是将基于雷达的模型输出的最终结果,比如3D BBox, 和视觉检测器输出的结果,如2D BBox, 通过滤波算法进行融合; 中间层融合是将某一个模态输出的最终结果,投影到另一种模态的深度学习特征层上,然后再利用一个后续的融合网络进行信息融合; 前融合则是直接在两种模态的Raw Data或者深度模型的特征层上进行融合,然后利用神经网络直接输出最终的结果。这里有篇文章做了比较详细的介绍;
这几种融合策略当然各有优劣,但是在工业界普遍使用的是后融合,因为这种方案比较灵活,鲁棒性也更好,不同模态的输出的结果通过人工设计的算法和规则进行整合,不同模态在不同情况下会有不同的使用优先级,因此能够更好的处理单一传感器失效时对系统的影响。但是后融合缺点也很多,一是信息的利用不是很充分,二是把系统链路变得更加复杂,链路越长,越容易出问题,三是当规则越堆叠越多之后维护代价会很高。学术界目前比较推崇的是前融合方案,能够更好的利用神经网络端到端的特性。但是前融合的方案少有能够直接上车的,原因我们认为是目前的前融合方案鲁棒性达不到实际要求, 尤其是当雷达信号出现问题时,目前的前融合方案几乎都无法处理。
在实际环境下会面临以下几种问题:
1)雷达和相机的外参不准 由于校准问题或车辆运行时颠簸抖动,会造成外参不准,导致点云和图像直接的投影会出现偏差
2)相机噪声 比如镜头脏污遮挡,卡帧,甚至是某个相机损坏等, 导致点云投影到图像上找不到对应的特征或得到错误的特征
3)雷达噪声 除了脏污遮挡问题;对于一些低反的物体,雷达本身特性导致返回点缺失,我们就在实际场景中发现,在雨天黑色的车辆反射点就极少,如图2所示;另外对于某些车型,比如国内新发售的蔚来ET7,其激光雷达的FOV本来就只会覆盖到一个有限的角度;
对于问题1)和2),一些方法已经提供一些兼容能力,比如DeepFusion[7],但是对于问题3)雷达噪声导致的点云缺失,都是无能为力的。因为这类方法都需要通过点云坐标去Query图像特性,一旦点云缺失,所有的手段都无法进行了。所以我们提出了BEVFusion的框架,和之前的方法不同的是雷达点云的处理和图像的处理是独立进行的,利用神经网络进行编码,投射到统一的BEV空间,然后将二者在BEV空间上进行融合。这种情况下雷达和视觉没有了主次依赖,从而能够实现近似后融合的灵活性:单一模态可以独立进行完成任务,当增加多种模态后,性能会大幅提高,但是当某一模态缺失或者产生噪声,不会对整体产生破坏性结果。
摘要:
现有的方法多依赖于来自lidar传感器的点云作为queries,利用图像空间中的特征。
但对于这些方案,如果lidar发生故障,则整个框架不能做出任何预测,这在根本上限制了实际自动驾驶场景的部署能力。
引言
在感知系统的早期阶段,人们为每个传感器设计单独的深度模型[35、36、56、15、51],并通过后处理方法融合信息[30]。 请注意,人们发现鸟瞰图 (BEV) 已成为自动驾驶场景的事实标准,因为一般来说,汽车无法飞行 [19、22、37、15、52、31]。 然而,由于缺乏深度信息,通常很难在纯图像输入上回归 3D 边界框,同样,当 LiDAR 没有接收到足够的点时,也很难对点云上的对象进行分类。
最近,人们设计的雷达-相机融合网络,可以更好地利用这两种模式的信息。大部分工作可以总结为如下:
- 给定一个或几个liadar点云,点云到世界坐标系的变换矩阵和相机到世界坐标系的本质矩阵。
- 转换lidar点或候选框到相机坐标系,然后将他们作为queries去选择对应的图像特征。
然而,这些方法严重依赖点云的原始数据(需要从lidar点生成图像queries),然而在 真实场景中,lidar数据会因为各种原因造成缺失(比如 lidar点反射率低、物体纹理、数据传输故障、视野受限无法达到360度等等),导致当前的融合方法无法在实际工作中达到预期效果。
作者认为,lidar+相机融合的理想框架应该满足:
- 无论是否存在其他模态,单个模态的每个模型都不应该失败。
- 同时拥有两个模态数据时,可以进一步提高感知的准确性。
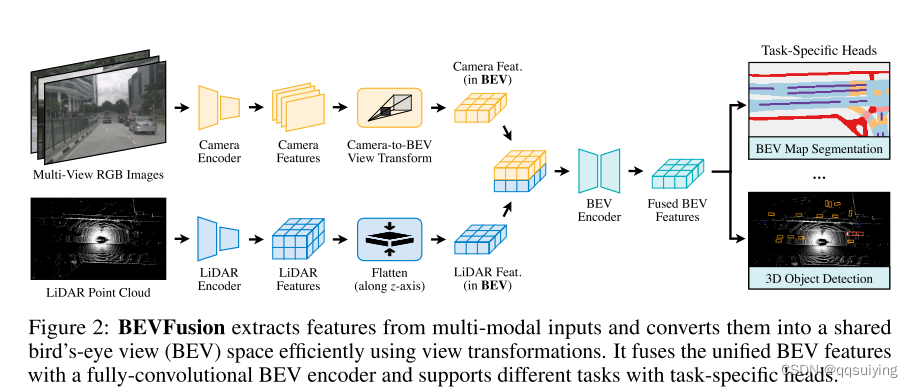
于是作者设计了如下图的融合框架。BEVFusion有两个独立流,将来自相机和lidar的原始输入编码为同一个BEV空间
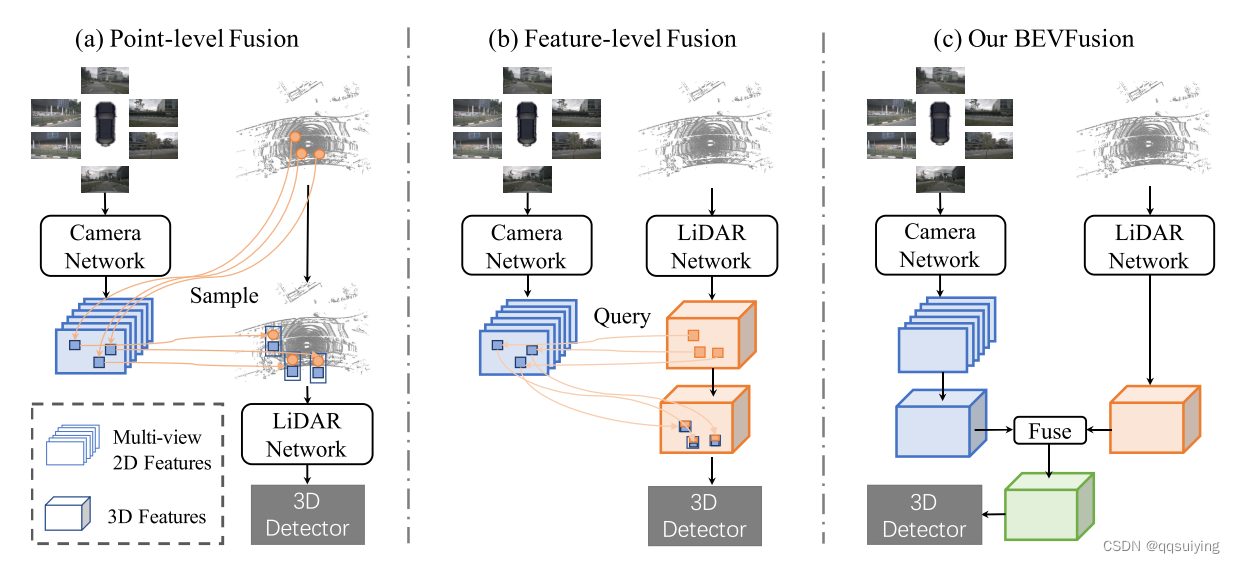
不同点云-图像融合框架的对比
由于是通用的融合框架,相机流和lidar流的方法都可以自由选择。作者测试过程中,选用 Lift-Splat-Shoot [32] 作为相机流,它将多视图图像特征投影到 3D ego-car 坐标特征以生成相机 BEV 特征;对于 LiDAR 流,作者选择了三个流行的模型,两个基于体素的模型和一个基于柱子的模型 [56,1,19] 将 LiDAR 特征编码到 BEV 空间中。在 nuScenes 数据集上,这个简单的框架显示出很强的泛化能力。
相关工作
这里作者写的是 不同输入模式的3D检测方法。
- 单独camera(感觉作者这里写的有点问题吧,pointpillar为啥放到camera里面了) 由于KITTI只有单目,所以大多数研究方法都用于解决单目3D目标检测。随着nuScenes和Wayme这些新数据集的发展,有一些方法开始以多视图图像作为输入进行处理,并且优于单目方法。 与常见的自动驾驶数据集一样,物体通常在平坦的地面上移动,PointPillars [19] 建议将 3D 特征映射到鸟瞰图 2D 空间以减少计算开销。它很快成为该领域的事实标准 [37, 19, 15, 52, 31, 22]。 Lift-SplatShoot (LSS) [32] 使用深度估计网络来提取多视角图像的隐含深度信息,并将相机特征图转换为 3D Ego-car 坐标。方法 [37, 15, 52] 也受到 LSS [32] 的启发,并参考 LiDAR 进行深度预测的监督。类似的想法也可以在 BEVDet [15, 14] 中找到,这是多视图 3D 对象检测中最先进的方法。 MonoDistill [6] 和 LiGA Stereo [11] 通过将 LiDAR 信息统一到相机分支来提高性能。
- 单独lidar LiDAR 方法最初根据其特征模式分为两类:i)直接在原始 LiDAR 点云上运行的基于点的方法 [36、35、34、40、55、21]; ii) 将原始点云转换为欧几里得特征空间,例如 3D 体素 [61]、特征柱 [19、50、56] 和距离图像 [9、43]。最近,人们开始在单个模型中利用这两种特征模式来增加表示能力[39]。另一项工作是利用类似于相机感知的鸟瞰平面的优势[19,9,43]。
- lidar-camera fusion 由于激光雷达和相机产生的特征通常包含互补信息,人们开始开发可以在两种模式上联合优化的方法,并很快成为 3D 检测的事实标准。如图 1 所示,这些方法可以根据它们的融合机制分为两类,(a) 点级融合,其中一个通过原始 LiDAR 点查询图像特征,然后将它们连接回作为附加点特征 [16, 41、45、57]; (b) 特征级融合,首先将 LiDAR 点投影到特征空间 [58] 或生成提案 [1],查询相关的相机特征,然后连接回特征空间 [23]。后者构成了 3D 检测中最先进的方法,具体来说,TransFusion [1] 使用 LiDAR 特征的边界框预测作为查询图像特征的提议,然后采用类似 Transformer 的架构来融合信息回到 LiDAR 功能。同样,DeepFusion [20] 将每个视图图像上的 LiDAR 特征投影为查询,然后利用交叉注意力来处理两种模式。 当前融合机制的一个被忽视的假设是它们严重依赖 LiDAR 点云,事实上,如果缺少 LiDAR 输入,这些方法将不可避免地失败。这将阻碍此类算法在现实环境中的部署。相比之下,我们的 BEVFusion 是一个非常简单但有效的融合框架,它通过将相机分支从 LiDAR 点云中分离出来,从根本上克服了这个问题,如图 1(c) 所示。
- others
还有其他工作可以利用其他模式,例如通过特征图连接融合相机雷达 [3, 17, 29, 28]。虽然很有趣,但这些 方法超出了我们的工作范围。尽管一项并行工作 [5] 旨在在单个网络中融合多模态信息,但其设计仅限于一个特 定的检测头 [51],而我们的框架可以推广到任意架构。
BEVFusion: A General Framework for LiDAR-Camera Fusion

两个输入流单独处理,转换为BEV空间
- Camera stream architecture: From multi-view images to BEV space 由于我们的框架能够合并任何相机流,我们从一种流行的方法开始,Lift-Splat-Shoot (LSS) [33]。由于 LSS 最初是针对 BEV 语义分割而不是 3D 检测提出的,我们发现直接使用 LSS 架构的性能较差,因此我们适度调整 LSS 以提高性能(消融研究见第 4.5 节)。在图 2(顶部)中,我们详细介绍了相机流的设计,其中包括将原始图像编码为深度特征的 imageview 编码器、将这些特征转换为 3D ego-car 坐标的视图投影仪模块和编码器最后将特征编码到鸟瞰图(BEV)空间中。
- Image-view Encoder 旨在将输入图像编码为语义信息丰富的深度特征。它由一个用于基本特征提取的 2D 主干和一个用于尺度变量对象表示的颈部模块组成。与使用卷积神经网络 ResNet [12] 作为主干网络的 LSS [32] 不同,我们使用更具代表性的一种,Dual-Swin-Tiny [24] 作为主干网络。在[32]之后,我们在主干之上使用标准特征金字塔网络(FPN)[25]来利用多尺度分辨率的特征。为了更好地对齐这些特征,我们首先提出了一个简单的特征自适应模块(ADP)来细化上采样的特征。具体来说,我们在连接之前对每个上采样特征应用自适应平均池和 1×1 卷积。见附录二。 A.1 为详细的模块架构。
- View Projector Module 由于图像特征仍处于 2D 图像坐标中,我们设计了一个视图投影模块将它们转换为 3D ego-car 坐标。我们应用 [32] 中提出的 2D → 3D 视图投影来构建相机 BEV 特征。所采用的视图投影仪以图像视图特征为输入,通过分类的方式对深度进行密集预测。然后根据相机外部参数和预测的图像深度,我们可以导出图像视图特征以在预定义的点云中进行渲染,并获得伪体素 V ∈ RX×Y×Z×C。
- BEV Encoder Module 为了进一步将体素特征 V ∈ RX×Y×Z×C 编码为 BEV 空间特征(FCamera ∈ RX×Y×CCamera ),我们设计了一个简单的编码器模块。我们没有应用池化操作或以步长 2 堆叠 3D 卷积来压缩 z 维度,而是采用空间到通道(S2C)操作 [52] 通过重塑将 V 从 4D 张量转换为 3D 张量 V ∈ RX×Y×(ZC)保留语义信息并降低成本。然后我们使用四个 3×3 卷积层逐渐将通道维度减小到 CCamera 中并提取高级语义信息。与基于下采样低分辨率特征提取高级特征的 LSS [32] 不同,我们的编码器直接处理全分辨率相机 BEV 特征以保留空间信息。
- LiDAR stream architecture: From point clouds to BEV space 同样,我们的框架可以合并任何将 LiDAR 点转换为 BEV 特征的网络,FLiDAR ∈ RX×Y×CLiDAR,作为我们的 LiDAR 流。一种常见的方法是学习原始点的参数化体素化 [61] 以减少 Z 维,然后利用由稀疏 3D 卷积 [54] 组成的网络在 BEV 空间中有效地产生特征。在实践中,我们采用三种流行的方法,PointPillars [19]、CenterPoint [56] 和 TransFusion [1] 作为我们的 LiDAR 流,以展示我们框架的泛化能力。

- Detection head 由于我们框架的最后一个功能是在 BEV 空间中,我们可以利用早期作品中流行的检测头模块。这进一步证明了我们框架的泛化能力。本质上,我们在三个流行的检测头类别之上比较我们的框架,基于锚的[19]、基于无锚的[56]和基于变换的
Experiments
作者使用的nuScenes数据集。每帧包含六个带有周围视图的摄像头和一个来自 LiDAR 的点云。 10 个类有多达 140 万个带注释的 3D 边界框。我们使用 nuScenes 检测分数(NDS)和平均精度(mAP)作为评估指标。
我们使用开源的 MMDetection3D [7] 在 PyTorch 中实现我们的网络。我们使用 Dual-Swin-Tiny [24] 作为图像视图编码器的 2D bakbone 进行 BEVFusion。 PointPillars [19]、CenterPoint [56] 和 TransFusion-L [1] 被选为我们的 LiDAR 流和 3D 检测头。我们将图像尺寸设置为 448 × 800,体素尺寸遵循 LiDAR 流 [19, 56, 1] 的官方设置。我们的训练包括两个阶段:i)我们首先分别使用多视图图像输入和 LiDAR 点云输入来训练 LiDAR 流和相机流。具体来说,我们在 MMDetection3D [7] 中按照 LiDAR 官方设置训练两个流; ii) 然后我们训练 BEVFusion 的另外 9 个 epoch,这些 epoch 继承了两个训练流的权重。请注意,当涉及多视图图像输入时,不应用数据增强(即翻转、旋转或 CBGS [63])。在测试期间,我们遵循 MMDetection3D [7] 中仅 LiDAR 检测器 [19, 56, 1] 的设置,无需任何额外的后处理。
参考链接
BEVFusion: 一个通用且鲁棒的激光雷达和视觉融合框架 – 知乎 (zhihu.com)
Original: https://blog.csdn.net/qqsuiying/article/details/125350670
Author: qqsuiying
Title: BEVFusion: A Simple and Robust LiDAR-CameraFusion Framework 细读
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/650519/
转载文章受原作者版权保护。转载请注明原作者出处!