

ffmpeg拉流硬解码yolov5 bytetrack 人流追踪统计 硬件编码推流直播
编程语言C++,所以环境搭建可能比较复杂,需要有耐心。
我的机器配置
CPU:I5 12490F
GPU:RTX2060 6GB
RAM:16×2 GB双通道
我测试运行可以25路(很极限了),20路比较稳,不会爆显存。
多路编码推流有个问题,就是NVIDIA对消费级显卡编码有限制一般是3路吧,但是这个可以破解的,很简单。照着readme做就好了。
https://github.com/keylase/nvidia-patch
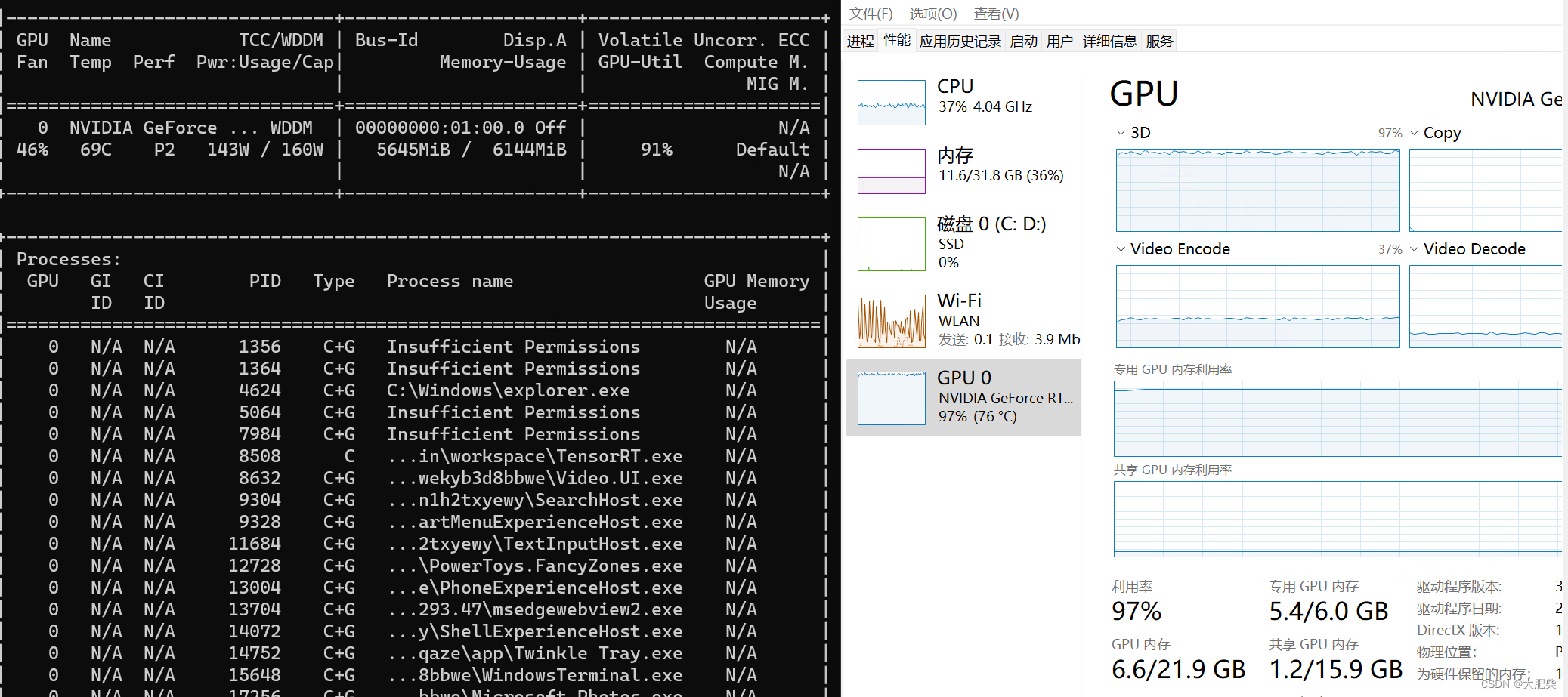
效果
榨干显卡

; 环境变量大家参考一下
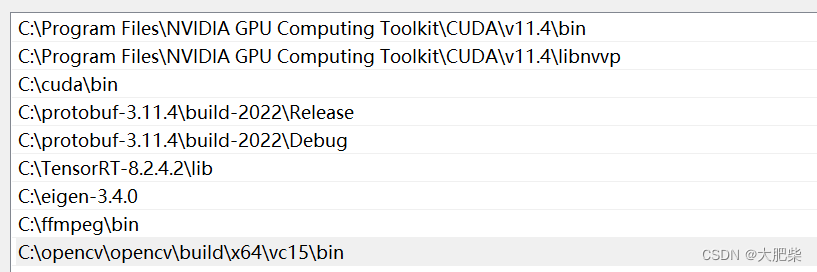
PS:cuda\bin 是cudnn的目录。
重要的事情说三遍
感谢杜老
感谢杜老
感谢杜老
一:整体架构:
(1) ffmpeg拉流RTSP,RTMP,硬解码,如果有nvidia显卡会根据流的编码格式选择对应的硬件解码器。
(2)推理框架使用的TensorRT8,所以第一次使用的时候,程序会building 模型,因为TensorRT的模型是一卡一模型的。
(3)ffmpeg推流,拿到推理和追踪之后的结果,opencv画框,然后丢给ffmpeg来找对应的编码器编码推流出去。
(4)Nginx服务器配置和flv.js插件。
二:所需的环境及对应库的版本
(1)系统Windows 11,显卡RTX 2060 6GB显存,驱动版本 471.11 cuda版本 11.4 ,VS2022(这里其实建议安装19,22的话nvidia的tenosrrt不支持22,所以到时候需要改一下nvidia对vs的版本判断,都是小问题)。PS:(先装vs再装cuda)
(2)
OpenCV 4.6.0(这个其实问题不大)
TensorRT 8.2.4 (这个很重要 自己看着来吧)
Protobuf 3.11.4 (严格一致)
eigen 3.4.0 (尽量一样)
ffmpeg 4.4 (最好保持一致。不要用5.0以上的API已经变了)
PS:其实Protobuf ,如果你装有Python的TensorFlow会自带Protobuf 的库,这个时候避免冲突你可以把Protobuf 3.11.4的库在环境变量里面提前一点
四:Nginx
代码目录压缩包解压运行即可。
推拉流的地址,但是这个地址不能用浏览器直接播放,可以用VLC media player,PotPlayer(这个更强大) 等软件验证框架是否搭建成功。
rtmp://你本机的IP:1936/live/home
这里说一下为什么用1936 本来rtmp默认是1935但是拉流也是rtmp使用1935,为避免端口堵塞,改用1936。
如果手头没有摄像头流的话 安卓手机可以下载一个APP IP摄像头可以来充当摄像头流测试
五:yolov5 6.0模型导出修改
line 55 forward function in yolov5/models/yolo.py
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
modified into:
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
bs = -1
ny = int(ny)
nx = int(nx)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
line 70 in yolov5/models/yolo.py
z.append(y.view(bs, -1, self.no))
modified into:
z.append(y.view(bs, self.na * ny * nx, self.no))
####### for yolov5-6.0
line 65 in yolov5/models/yolo.py
if self.grid[i].shape[2:4] != x[i].shape[2:4] or self.onnx_dynamic:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
modified into:
if self.grid[i].shape[2:4] != x[i].shape[2:4] or self.onnx_dynamic:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
disconnect for pytorch trace
anchor_grid = (self.anchors[i].clone() * self.stride[i]).view(1, -1, 1, 1, 2)
line 70 in yolov5/models/yolo.py
y[…, 2:4] = (y[…, 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
modified into:
y[…, 2:4] = (y[…, 2:4] * 2) ** 2 * anchor_grid # wh
line 73 in yolov5/models/yolo.py
wh = (y[…, 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
modified into:
wh = (y[…, 2:4] * 2) ** 2 * anchor_grid # wh
####### for yolov5-6.0
line 52 in yolov5/export.py
torch.onnx.export(dynamic_axes={‘images’: {0: ‘batch’, 2: ‘height’, 3: ‘width’}, # shape(1,3,640,640)
‘output’: {0: ‘batch’, 1: ‘anchors’} # shape(1,25200,85) 修改为
modified into:
torch.onnx.export(dynamic_axes={‘images’: {0: ‘batch’}, # shape(1,3,640,640)
‘output’: {0: ‘batch’} # shape(1,25200,85)
浏览器直接播放的插件:
https://github.com/bilibili/flv.js
Original: https://blog.csdn.net/qq_43502221/article/details/126314662
Author: 大肥柴
Title: ffmpeg tensorrt c++多拉流硬解码yolov5 yolov7 bytetrack 人流追踪统计 硬件编码推流直播
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/648920/
转载文章受原作者版权保护。转载请注明原作者出处!