

Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech(ICML 2021)
KAKAO公司与KAIST韩国科学院,近年在TTS领域佳作频出,目前最主流的HiFiGAN 声码器也是其成果。
目录
1. 变分推断(Variational Inference)
概览:
提出一种TTS模型框架VITS,用到normalizing flow和对抗训练方法,提高合成语音自然度,其中论文结果上显示已经和GT相当。结合VAE和FLOW的前沿架构。
代码: https://github.com/jaywalnut310/vits
Demo地址: https://jaywalnut310.github.io/vits
论文地址:https://arxiv.org/abs/2106.0610
突破点:
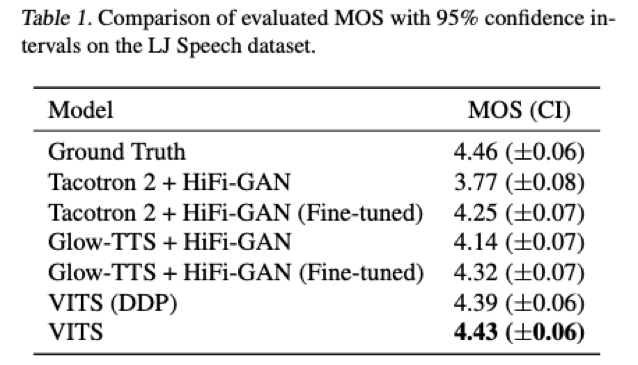
- 首个自然度超过2-stage架构SOTA的完全E2E模型。MOS4.43, 仅低于GT录音0.03。声称目前公开系统最好效果。
- 得益于图像领域中把Flow引入VAE提升生成效果的研究,成功把Flow-VAE应用到了完全E2E的TTS任务中。
- 训练非常简便,完全E2E。不需要像Fastspeech系列模型需要额外提pitch, energy等特征,也不像多数2-stage架构需要根据声学模型的输出来finetune声码器以达到最佳效果。
- 摆脱了预设的声学谱作为链接声学模型和声码器的特征,成功的应用来VAE去E2E的学习隐性表示来链接两个模块
- 多说话人模型自然度不下降,不像其他模型趋于持平GT录音MOS分

high level的优缺点总结:
VITS优点
- 合成速度足够快
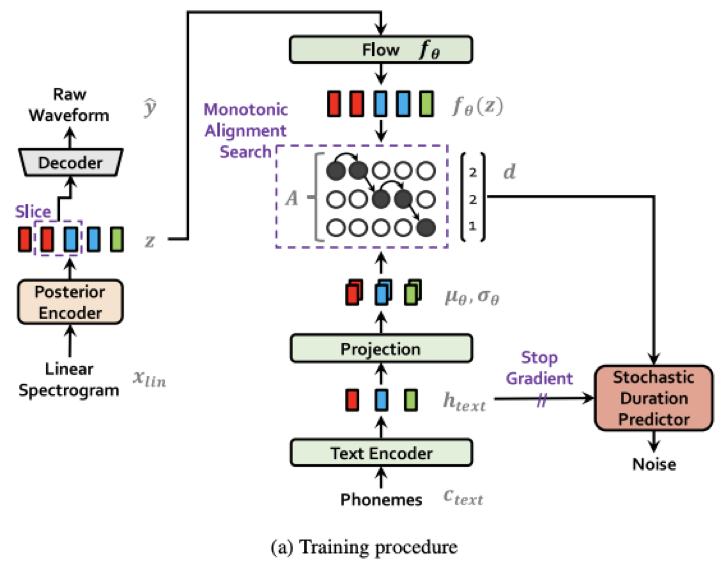
- 三个主要网络结构均为可并行的非自回归结构保证了合成速度:
- 和Fastspeech系统相同的transformer作为文本Encoder
- 和Glow-TTS相同的Flow结构作为VAE的主体
- 和HiFiGAN生成器相同的反卷积作为Decoder
- 长文本稳定性好
- 采用了Glow-TTS相同的单调对齐搜索算法(MAS), 保证生成对齐的稳定性
- 语音多样性好
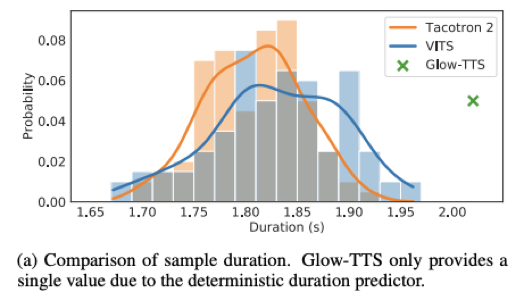
- 在预测音素时长的模块中也引入Flow结构增加生成韵律的多样性
缺点:
- 多样性,稳定性的trade off
- 训练收敛速度慢
- *全局信息学习能力较弱(韵律,风格略平淡)
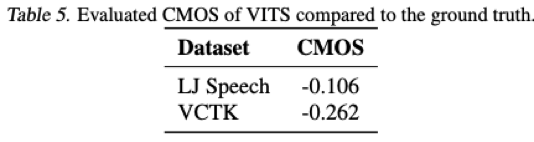
接近GT,但是单独做CMOS还是比GT要低的。
模型详解:
看懂需要的前置知识,推荐苏神的生成模型系列文章:
- VAE系列文章,看到你自己觉得懂了: _ 变分自编码器(一):原来是这么一回事 – 科学空间|Scientific Spaces_
- Flow/Glow:
细水长flow之NICE:流模型的基本概念与实现 – 科学空间|Scientific Spaces
细水长flow之RealNVP与Glow:流模型的传承与升华 – 科学空间|Scientific Spaces
- 上述两者的结合,也就是本篇论文主要部分:
细水长flow之f-VAEs:Glow与VAEs的联姻 – 科学空间|Scientific Spaces
了解一个模型就从它的Loss入手:
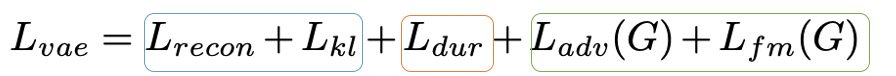
三部分 Loss 对应三个主要模块:
1. 变分推断 (Variational Inference)
优化目标:最大化条件下界(ELBO)
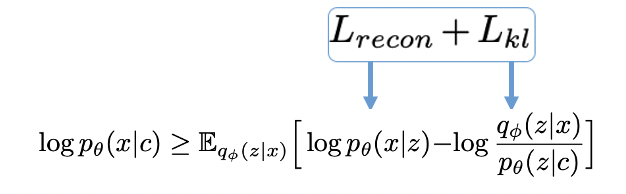
符号解释:
z 为线性谱经过后验编码器后得到的隐变量
y_hat 为 z 经过decoder后得到预测音频序列
x 为真实音频的Mel谱
c 为文本, d为音素时长duration,A为对齐矩阵
p(x|c) 和 p(x|z) 分别为目标 x 对 c 和 z 的最大似然
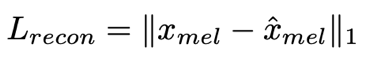
- 预测音频 y_hat 提取的Mel谱和真实Mel谱的L1 Loss
- Decoder为HiFiGAN声码器的generator生成器
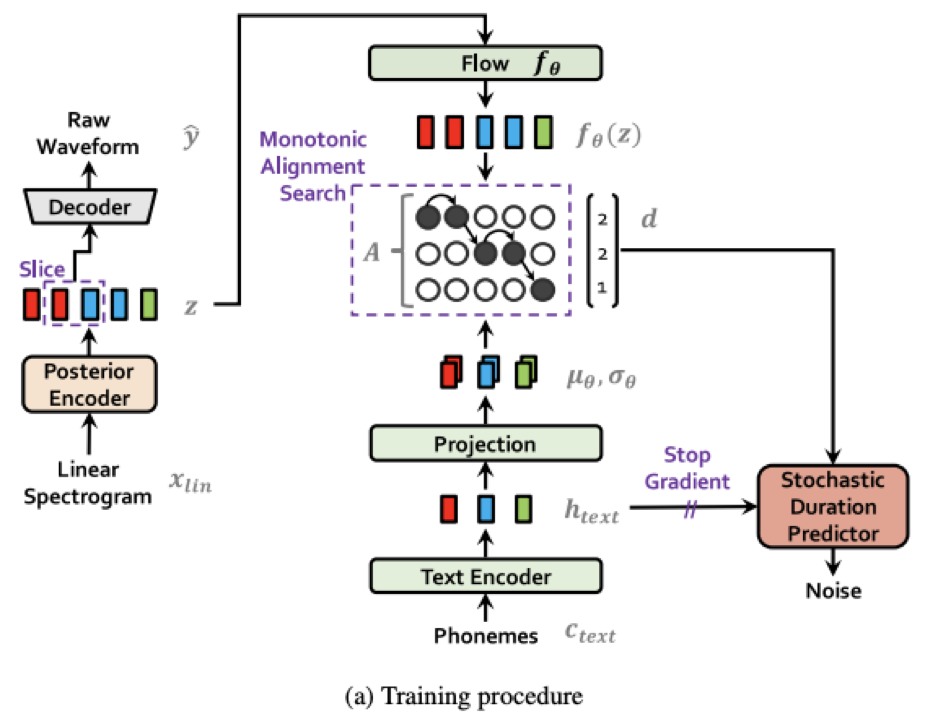

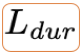
- 通过单调对齐搜索算法(MAS), 获得文本编码后预测的均值方差和隐变量 z 通过Flow后的正态分布的最优对齐矩阵。
- 时长预测模块去学习这个对齐矩阵序列
- Flow应用到此模块增加生成序列的多样性
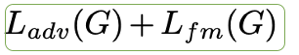
- Decoder 即为 HiFiGAN的生成器,两个Loss 也对应原论文中相同的对抗Loss 和特征鉴别器Loss, 想深入了解可以参考原论文。
总结与思考
整篇文章总体还是很优美,通过合理的应用vae-flow架构,得到了不错的效果。后续微软谭旭的natrual TTS工作也是很大程度借鉴了这篇文章,给出了更多的解释。
目前生成模型包括新的Diffusion模型在常规数据集上都能做到不错的效果,更高难度的高表现力数据的还原将成为未来热点方向。但大概率突破仍然会产生在类似的生成模型架构上。
Original: https://blog.csdn.net/Terry_ZzZzZz/article/details/120458064
Author: Terry_ZzZzZz
Title: VITS 语音合成完全端到端TTS的里程碑
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/648812/
转载文章受原作者版权保护。转载请注明原作者出处!