

【人工智能项目】LSTM实现数据预测分类实验
本次主要对csv文件中采集到的数据来区分树的品种实验,通过不同列的数据,送入lstm模型中,得到预测结果。


; 导包
import numpy as np
import pandas as pd
import glob
import os
import tensorflow as tf
from sklearn.model_selection import train_test_split
from sklearn.utils import shuffle
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
train_path = "./"
print(os.listdir(train_path))
['.ipynb_checkpoints', 'code.ipynb', 'data.csv', 'lstm.h5', 'plant_totaldatat.xlsx']
读取数据
data = pd.read_csv("data.csv")
data
Filename172.538173.141173.744174.348174.951175.554176.157176.76177.363…1165.8461166.3731166.91167.4271167.9541168.4811169.0081169.5351170.061Label0芭蕉0001.ROH414.421417445.234558482.571625378.288757483.976776476.850617423.253845445.033813477.653564…487.088196513.986938532.956604545.502625504.853424568.687744547.811096584.947449564.77337611芭蕉0002.ROH469.523712450.353333447.543030457.880981467.616699456.375458483.575287447.543030415.224365…560.357178511.477722473.337708613.151001513.384766495.418793618.771606618.570923495.61950712芭蕉0003.ROH508.265930502.946411522.317505471.932556512.682129503.950104498.429840487.891144465.910461…597.694275552.126953540.885681661.327881553.030273540.183106650.889526659.521240550.21997113芭蕉0004.ROH490.801819514.789917529.945557463.501617527.536682525.027466489.898499514.288025503.247528…567.784424576.416138573.906921625.596680548.915161621.280823632.221008652.595825599.19976814芭蕉0005.ROH431.383697433.290680436.703217408.901154459.386505461.694977453.264008435.900269438.810974…535.867249499.232788503.849731569.691467518.704285512.381043577.921692573.605835520.8120121…………………………………………………………2422樟树10096.ROH376.682861396.656189391.637787371.363342434.796234390.634094378.489502410.406677394.147003…478.155395441.520904413.317383508.265930447.844116424.558624497.927978522.618652449.95187472423樟树10097.ROH312.647797359.419495336.836578315.056641381.299835351.891876333.925903377.586182353.397400…434.495117420.242798342.758331476.047668397.258423369.054871446.639709460.390167384.91308672424樟树10098.ROH383.809052372.166290419.941681371.363342412.112946411.912201399.566894382.905731405.287903…438.208740460.089081427.469330478.556885463.300873468.620392485.181183525.328613500.03573672425樟树10099.ROH327.100861333.725159347.676392332.621124376.181030364.538300361.727966377.786926347.274902…417.934326411.410370377.184723433.190338413.919586395.752899432.989593445.636017425.56231772426樟树10100.ROH380.697601424.859741441.119446388.526367448.446320433.089966416.428803431.383697450.654449…500.838684497.526520458.182068537.673889493.210663465.709717551.625122561.059753480.2631537
2427 rows × 1757 columns
data.head()
Filename172.538173.141173.744174.348174.951175.554176.157176.76177.363…1165.8461166.3731166.91167.4271167.9541168.4811169.0081169.5351170.061Label0芭蕉0001.ROH414.421417445.234558482.571625378.288757483.976776476.850617423.253845445.033813477.653564…487.088196513.986938532.956604545.502625504.853424568.687744547.811096584.947449564.77337611芭蕉0002.ROH469.523712450.353333447.543030457.880981467.616699456.375458483.575287447.543030415.224365…560.357178511.477722473.337708613.151001513.384766495.418793618.771606618.570923495.61950712芭蕉0003.ROH508.265930502.946411522.317505471.932556512.682129503.950104498.429840487.891144465.910461…597.694275552.126953540.885681661.327881553.030273540.183106650.889526659.521240550.21997113芭蕉0004.ROH490.801819514.789917529.945557463.501617527.536682525.027466489.898499514.288025503.247528…567.784424576.416138573.906921625.596680548.915161621.280823632.221008652.595825599.19976814芭蕉0005.ROH431.383697433.290680436.703217408.901154459.386505461.694977453.264008435.900269438.810974…535.867249499.232788503.849731569.691467518.704285512.381043577.921692573.605835520.8120121
5 rows × 1757 columns
数据分析
data.index
RangeIndex(start=0, stop=2427, step=1)
print(data.info())
<class 'pandas.core.frame.dataframe'>
RangeIndex: 2427 entries, 0 to 2426
Columns: 1757 entries, Filename to Label
dtypes: float64(1755), int64(1), object(1)
memory usage: 32.5+ MB
None
</class>
data.dropna(axis=0, how='any', inplace=True)
data
Filename172.538173.141173.744174.348174.951175.554176.157176.76177.363…1165.8461166.3731166.91167.4271167.9541168.4811169.0081169.5351170.061Label0芭蕉0001.ROH414.421417445.234558482.571625378.288757483.976776476.850617423.253845445.033813477.653564…487.088196513.986938532.956604545.502625504.853424568.687744547.811096584.947449564.77337611芭蕉0002.ROH469.523712450.353333447.543030457.880981467.616699456.375458483.575287447.543030415.224365…560.357178511.477722473.337708613.151001513.384766495.418793618.771606618.570923495.61950712芭蕉0003.ROH508.265930502.946411522.317505471.932556512.682129503.950104498.429840487.891144465.910461…597.694275552.126953540.885681661.327881553.030273540.183106650.889526659.521240550.21997113芭蕉0004.ROH490.801819514.789917529.945557463.501617527.536682525.027466489.898499514.288025503.247528…567.784424576.416138573.906921625.596680548.915161621.280823632.221008652.595825599.19976814芭蕉0005.ROH431.383697433.290680436.703217408.901154459.386505461.694977453.264008435.900269438.810974…535.867249499.232788503.849731569.691467518.704285512.381043577.921692573.605835520.8120121…………………………………………………………2422樟树10096.ROH376.682861396.656189391.637787371.363342434.796234390.634094378.489502410.406677394.147003…478.155395441.520904413.317383508.265930447.844116424.558624497.927978522.618652449.95187472423樟树10097.ROH312.647797359.419495336.836578315.056641381.299835351.891876333.925903377.586182353.397400…434.495117420.242798342.758331476.047668397.258423369.054871446.639709460.390167384.91308672424樟树10098.ROH383.809052372.166290419.941681371.363342412.112946411.912201399.566894382.905731405.287903…438.208740460.089081427.469330478.556885463.300873468.620392485.181183525.328613500.03573672425樟树10099.ROH327.100861333.725159347.676392332.621124376.181030364.538300361.727966377.786926347.274902…417.934326411.410370377.184723433.190338413.919586395.752899432.989593445.636017425.56231772426樟树10100.ROH380.697601424.859741441.119446388.526367448.446320433.089966416.428803431.383697450.654449…500.838684497.526520458.182068537.673889493.210663465.709717551.625122561.059753480.2631537
2427 rows × 1757 columns
data = data.drop(['Filename'], axis=1)
data
172.538173.141173.744174.348174.951175.554176.157176.76177.363177.966…1165.8461166.3731166.91167.4271167.9541168.4811169.0081169.5351170.061Label0414.421417445.234558482.571625378.288757483.976776476.850617423.253845445.033813477.653564595.285400…487.088196513.986938532.956604545.502625504.853424568.687744547.811096584.947449564.77337611469.523712450.353333447.543030457.880981467.616699456.375458483.575287447.543030415.224365601.006409…560.357178511.477722473.337708613.151001513.384766495.418793618.771606618.570923495.61950712508.265930502.946411522.317505471.932556512.682129503.950104498.429840487.891144465.910461655.907959…597.694275552.126953540.885681661.327881553.030273540.183106650.889526659.521240550.21997113490.801819514.789917529.945557463.501617527.536682525.027466489.898499514.288025503.247528661.628967…567.784424576.416138573.906921625.596680548.915161621.280823632.221008652.595825599.19976814431.383697433.290680436.703217408.901154459.386505461.694977453.264008435.900269438.810974592.675842…535.867249499.232788503.849731569.691467518.704285512.381043577.921692573.605835520.8120121…………………………………………………………2422376.682861396.656189391.637787371.363342434.796234390.634094378.489502410.406677394.147003510.775147…478.155395441.520904413.317383508.265930447.844116424.558624497.927978522.618652449.95187472423312.647797359.419495336.836578315.056641381.299835351.891876333.925903377.586182353.397400424.960113…434.495117420.242798342.758331476.047668397.258423369.054871446.639709460.390167384.91308672424383.809052372.166290419.941681371.363342412.112946411.912201399.566894382.905731405.287903531.149963…438.208740460.089081427.469330478.556885463.300873468.620392485.181183525.328613500.03573672425327.100861333.725159347.676392332.621124376.181030364.538300361.727966377.786926347.274902443.227173…417.934326411.410370377.184723433.190338413.919586395.752899432.989593445.636017425.56231772426380.697601424.859741441.119446388.526367448.446320433.089966416.428803431.383697450.654449533.458435…500.838684497.526520458.182068537.673889493.210663465.709717551.625122561.059753480.2631537
2427 rows × 1756 columns
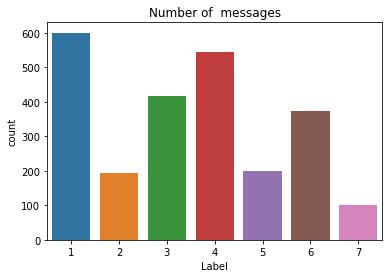
sns.countplot(data["Label"])
plt.xlabel("Label")
plt.title("Number of messages")
Text(0.5, 1.0, 'Number of messages')
df = data.sample(frac=1).reset_index(drop=True)
df
172.538173.141173.744174.348174.951175.554176.157176.76177.363177.966…1165.8461166.3731166.91167.4271167.9541168.4811169.0081169.5351170.061Label0429.978546448.345978447.342285430.380005473.839569442.323853457.178406452.862549429.175598582.739380…494.415100501.942718467.616699526.934509482.170136509.470367526.432617595.385803530.24664361281.834656293.979248335.431427288.057526310.238953317.365112305.822723321.179108327.502319398.462830…329.911163375.578827351.691132373.270355349.984863390.132263369.255615398.061371381.19946372440.316498426.164520453.665497430.480377450.052216461.594605456.174713440.517212444.130493607.429993…515.291748490.400360489.998871569.992554481.567932517.198731559.353516549.617737548.61407533285.247192309.737091289.362305302.008728340.750977327.000488323.688324345.769379316.963623418.034698…338.442474373.169983362.530914384.511627340.750977376.983978375.578827407.997833391.23629814458.081696475.345093447.743744437.606537476.950989457.278748469.523712437.305420436.803589594.683228…486.887451487.991516502.544952553.532104483.374573506.158203554.033997552.327698540.7853394…………………………………………………………2422441.822022464.706024461.996063427.368958481.266815490.299988465.207855473.939911446.037476610.240295…523.421570524.927124519.406860577.720947499.232788537.473144581.434570584.646362551.62512222423290.767456264.270203298.395477291.670776303.915741331.416687325.394592316.762909328.204895404.384583…352.795166357.010651372.969238393.544769368.553040391.236298399.767639412.915894403.18014542424303.915741286.652344305.722382293.176300329.810791303.815369317.967316328.907471294.179993419.239105…344.866058354.802551357.512512400.972046342.557587383.006103390.634094388.024506372.66815212425428.473022434.394745487.991516408.098206464.003449489.396667456.174713431.684814458.583557590.066223…528.038513561.059753473.237335578.624268537.673889496.221741553.732849616.162048509.16925022426454.468445441.621277450.754822424.357910459.286133460.289825469.222595459.787964443.729004592.274353…494.916931484.779724499.533875555.840576474.441772526.231873546.707092568.988892528.2392584
2427 rows × 1756 columns
df[df.isnull().values==True]
172.538173.141173.744174.348174.951175.554176.157176.76177.363177.966…1165.8461166.3731166.91167.4271167.9541168.4811169.0081169.5351170.061Label
0 rows × 1756 columns
x = df.iloc[:,:-1]
y = df.iloc[:,-1]
划分数据集
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(x_train)
X_train = scaler.transform(x_train)
X_test = scaler.transform(x_test)
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
(1941, 1755)
(1941,)
(486, 1755)
(486,)
from keras.utils import np_utils
X_train = X_train.reshape((-1,1,1755))
Y_train = np_utils.to_categorical(y_train)
X_test = X_test.reshape((-1,1,1755))
Y_test = np_utils.to_categorical(y_test)
print(X_train.shape)
print(Y_train.shape)
print(X_test.shape)
print(Y_test.shape)
(1941, 1, 1755)
(1941, 8)
(486, 1, 1755)
(486, 8)
模型
from keras import Sequential
from keras.layers import LSTM,Activation,Dense,Dropout,Input,Embedding,BatchNormalization,Add,concatenate,Flatten
model = Sequential()
model.add(LSTM(units=50,return_sequences=True,input_shape=(1,1755)))
model.add(Dropout(0.2))
model.add(LSTM(units=50,return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(units=50,return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(units=50))
model.add(Dropout(0.2))
model.add(Dense(units=128))
model.add(Dropout(0.2))
model.add(Dense(units=64))
model.add(Dropout(0.2))
model.add(Dense(units=16))
model.add(Dropout(0.2))
model.add(Dense(units=8,activation="softmax"))
from keras.callbacks import EarlyStopping,ReduceLROnPlateau,ModelCheckpoint,LearningRateScheduler
checkpoint = ModelCheckpoint("lstm.h5",
monitor="val_loss",
mode="min",
save_best_only = True,
verbose=1)
earlystop = EarlyStopping(monitor = 'val_loss',
min_delta = 0,
patience = 5,
verbose = 1,
restore_best_weights = True)
reduce_lr = ReduceLROnPlateau(monitor = 'val_loss',
factor = 0.2,
patience = 3,
verbose = 1)
callbacks = [earlystop, checkpoint, reduce_lr]
model.compile(optimizer="adam", loss='categorical_crossentropy', metrics=['accuracy'])
history_fit = model.fit(x=X_train,
y=Y_train,
batch_size=8,
epochs=30,
verbose=1,
validation_data=(X_test, Y_test),
callbacks=callbacks)
Train on 1941 samples, validate on 486 samples
Epoch 1/30
1941/1941 [==============================] - 6s 3ms/step - loss: 1.0300 - accuracy: 0.6188 - val_loss: 0.5473 - val_accuracy: 0.8313
Epoch 00001: val_loss improved from inf to 0.54729, saving model to lstm.h5
Epoch 2/30
1941/1941 [==============================] - 4s 2ms/step - loss: 0.6064 - accuracy: 0.7836 - val_loss: 0.3829 - val_accuracy: 0.8374
Epoch 00002: val_loss improved from 0.54729 to 0.38287, saving model to lstm.h5
Epoch 3/30
1941/1941 [==============================] - 4s 2ms/step - loss: 0.4797 - accuracy: 0.8089 - val_loss: 0.3595 - val_accuracy: 0.8272
Epoch 00003: val_loss improved from 0.38287 to 0.35947, saving model to lstm.h5
Epoch 4/30
1941/1941 [==============================] - 4s 2ms/step - loss: 0.4672 - accuracy: 0.8083 - val_loss: 0.2970 - val_accuracy: 0.8354
Epoch 00004: val_loss improved from 0.35947 to 0.29702, saving model to lstm.h5
Epoch 5/30
1941/1941 [==============================] - 4s 2ms/step - loss: 0.3946 - accuracy: 0.8557 - val_loss: 0.2658 - val_accuracy: 0.9033
Epoch 00005: val_loss improved from 0.29702 to 0.26579, saving model to lstm.h5
Epoch 6/30
1941/1941 [==============================] - 4s 2ms/step - loss: 0.3519 - accuracy: 0.8712 - val_loss: 0.2217 - val_accuracy: 0.8909
Epoch 00006: val_loss improved from 0.26579 to 0.22171, saving model to lstm.h5
Epoch 7/30
1941/1941 [==============================] - 4s 2ms/step - loss: 0.3287 - accuracy: 0.8743 - val_loss: 0.2439 - val_accuracy: 0.8683
Epoch 00007: val_loss did not improve from 0.22171
Epoch 8/30
1941/1941 [==============================] - 4s 2ms/step - loss: 0.3400 - accuracy: 0.8635 - val_loss: 0.2036 - val_accuracy: 0.9259
Epoch 00008: val_loss improved from 0.22171 to 0.20360, saving model to lstm.h5
Epoch 9/30
1941/1941 [==============================] - 4s 2ms/step - loss: 0.3541 - accuracy: 0.8666 - val_loss: 0.2087 - val_accuracy: 0.9321
Epoch 00009: val_loss did not improve from 0.20360
Epoch 10/30
1941/1941 [==============================] - 4s 2ms/step - loss: 0.3227 - accuracy: 0.8691 - val_loss: 0.2141 - val_accuracy: 0.9362
Epoch 00010: val_loss did not improve from 0.20360
Epoch 11/30
1941/1941 [==============================] - 4s 2ms/step - loss: 0.2842 - accuracy: 0.8851 - val_loss: 0.1821 - val_accuracy: 0.9506
Epoch 00011: val_loss improved from 0.20360 to 0.18205, saving model to lstm.h5
Epoch 12/30
1941/1941 [==============================] - 4s 2ms/step - loss: 0.3343 - accuracy: 0.8712 - val_loss: 0.2297 - val_accuracy: 0.8951
Epoch 00012: val_loss did not improve from 0.18205
Epoch 13/30
1941/1941 [==============================] - 4s 2ms/step - loss: 0.3082 - accuracy: 0.8800 - val_loss: 0.2213 - val_accuracy: 0.9321
Epoch 00013: val_loss did not improve from 0.18205
Epoch 14/30
1941/1941 [==============================] - 4s 2ms/step - loss: 0.2550 - accuracy: 0.9052 - val_loss: 0.1765 - val_accuracy: 0.9444
Epoch 00014: val_loss improved from 0.18205 to 0.17651, saving model to lstm.h5
Epoch 15/30
1941/1941 [==============================] - 4s 2ms/step - loss: 0.3290 - accuracy: 0.8856 - val_loss: 0.2044 - val_accuracy: 0.9383
Epoch 00015: val_loss did not improve from 0.17651
Epoch 16/30
1941/1941 [==============================] - 4s 2ms/step - loss: 0.2812 - accuracy: 0.9031 - val_loss: 0.1578 - val_accuracy: 0.9465
Epoch 00016: val_loss improved from 0.17651 to 0.15778, saving model to lstm.h5
Epoch 17/30
1941/1941 [==============================] - 4s 2ms/step - loss: 0.2332 - accuracy: 0.9145 - val_loss: 0.1287 - val_accuracy: 0.9547
Epoch 00017: val_loss improved from 0.15778 to 0.12870, saving model to lstm.h5
Epoch 18/30
1941/1941 [==============================] - 4s 2ms/step - loss: 0.2597 - accuracy: 0.9114 - val_loss: 0.1607 - val_accuracy: 0.9280
Epoch 00018: val_loss did not improve from 0.12870
Epoch 19/30
1941/1941 [==============================] - 4s 2ms/step - loss: 0.2570 - accuracy: 0.9052 - val_loss: 0.1230 - val_accuracy: 0.9671
Epoch 00019: val_loss improved from 0.12870 to 0.12305, saving model to lstm.h5
Epoch 20/30
1941/1941 [==============================] - 4s 2ms/step - loss: 0.2401 - accuracy: 0.9129 - val_loss: 0.1639 - val_accuracy: 0.9588
Epoch 00020: val_loss did not improve from 0.12305
Epoch 21/30
1941/1941 [==============================] - 4s 2ms/step - loss: 0.2233 - accuracy: 0.9155 - val_loss: 0.1172 - val_accuracy: 0.9671
Epoch 00021: val_loss improved from 0.12305 to 0.11718, saving model to lstm.h5
Epoch 22/30
1941/1941 [==============================] - 4s 2ms/step - loss: 0.2524 - accuracy: 0.9088 - val_loss: 0.1627 - val_accuracy: 0.9588
Epoch 00022: val_loss did not improve from 0.11718
Epoch 23/30
1941/1941 [==============================] - 4s 2ms/step - loss: 0.2185 - accuracy: 0.9176 - val_loss: 0.1313 - val_accuracy: 0.9342
Epoch 00023: val_loss did not improve from 0.11718
Epoch 24/30
1941/1941 [==============================] - 4s 2ms/step - loss: 0.2344 - accuracy: 0.9160 - val_loss: 0.1223 - val_accuracy: 0.9527
Epoch 00024: val_loss did not improve from 0.11718
Epoch 00024: ReduceLROnPlateau reducing learning rate to 0.00020000000949949026.
Epoch 25/30
1941/1941 [==============================] - 4s 2ms/step - loss: 0.1890 - accuracy: 0.9274 - val_loss: 0.0862 - val_accuracy: 0.9691
Epoch 00025: val_loss improved from 0.11718 to 0.08617, saving model to lstm.h5
Epoch 26/30
1941/1941 [==============================] - 4s 2ms/step - loss: 0.1475 - accuracy: 0.9361 - val_loss: 0.0794 - val_accuracy: 0.9733
Epoch 00026: val_loss improved from 0.08617 to 0.07940, saving model to lstm.h5
Epoch 27/30
1941/1941 [==============================] - 4s 2ms/step - loss: 0.1507 - accuracy: 0.9392 - val_loss: 0.0673 - val_accuracy: 0.9774
Epoch 00027: val_loss improved from 0.07940 to 0.06732, saving model to lstm.h5
Epoch 28/30
1941/1941 [==============================] - 4s 2ms/step - loss: 0.1498 - accuracy: 0.9444 - val_loss: 0.0764 - val_accuracy: 0.9733
Epoch 00028: val_loss did not improve from 0.06732
Epoch 29/30
1941/1941 [==============================] - 4s 2ms/step - loss: 0.1513 - accuracy: 0.9423 - val_loss: 0.0733 - val_accuracy: 0.9774
Epoch 00029: val_loss did not improve from 0.06732
Epoch 30/30
1941/1941 [==============================] - 4s 2ms/step - loss: 0.1338 - accuracy: 0.9418 - val_loss: 0.0815 - val_accuracy: 0.9753
Epoch 00030: val_loss did not improve from 0.06732
Epoch 00030: ReduceLROnPlateau reducing learning rate to 4.0000001899898055e-05.
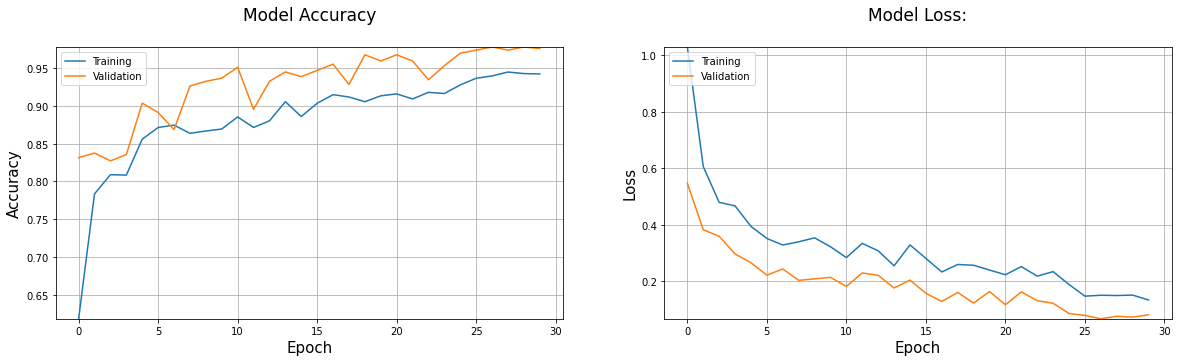
def plot_performance(history=None,figure_directory=None,ylim_pad=[0,0]):
xlabel="Epoch"
legends=["Training","Validation"]
plt.figure(figsize=(20,5))
y1=history.history["accuracy"]
y2=history.history["val_accuracy"]
min_y=min(min(y1),min(y2))-ylim_pad[0]
max_y=max(max(y1),max(y2))+ylim_pad[0]
plt.subplot(121)
plt.plot(y1)
plt.plot(y2)
plt.title("Model Accuracy\n",fontsize=17)
plt.xlabel(xlabel,fontsize=15)
plt.ylabel("Accuracy",fontsize=15)
plt.ylim(min_y,max_y)
plt.legend(legends,loc="upper left")
plt.grid()
y1=history.history["loss"]
y2=history.history["val_loss"]
min_y=min(min(y1),min(y2))-ylim_pad[1]
max_y=max(max(y1),max(y2))+ylim_pad[1]
plt.subplot(122)
plt.plot(y1)
plt.plot(y2)
plt.title("Model Loss:\n",fontsize=17)
plt.xlabel(xlabel,fontsize=15)
plt.ylabel("Loss",fontsize=15)
plt.ylim(min_y,max_y)
plt.legend(legends,loc="upper left")
plt.grid()
plt.show()
plot_performance(history=history_fit)
predict_y = model.predict_classes(X_test)
predict_y
array([1, 6, 4, 3, 4, 1, 4, 6, 6, 1, 1, 1, 1, 1, 1, 4, 4, 4, 4, 5, 4, 5,
7, 1, 4, 5, 3, 4, 1, 6, 4, 4, 5, 4, 1, 1, 7, 4, 1, 4, 6, 4, 4, 5,
4, 7, 7, 6, 1, 1, 5, 6, 2, 1, 4, 4, 1, 4, 4, 4, 6, 5, 2, 6, 3, 1,
2, 4, 2, 4, 1, 1, 1, 1, 1, 1, 6, 4, 1, 3, 5, 2, 4, 6, 3, 4, 4, 3,
6, 5, 7, 1, 1, 2, 7, 4, 1, 6, 6, 2, 6, 1, 3, 4, 1, 1, 1, 4, 2, 1,
3, 6, 2, 4, 4, 4, 3, 4, 1, 1, 6, 7, 6, 7, 2, 5, 1, 3, 4, 1, 3, 3,
5, 4, 4, 7, 6, 2, 6, 4, 6, 6, 3, 5, 3, 5, 6, 3, 4, 1, 3, 6, 1, 4,
6, 4, 6, 2, 2, 1, 7, 4, 6, 3, 6, 6, 5, 4, 4, 4, 4, 2, 4, 6, 1, 3,
1, 6, 6, 4, 1, 1, 4, 1, 4, 4, 2, 3, 1, 6, 4, 4, 3, 6, 5, 3, 4, 6,
1, 1, 3, 5, 4, 1, 6, 3, 4, 3, 1, 2, 1, 4, 6, 5, 3, 5, 4, 4, 4, 4,
7, 3, 1, 4, 2, 4, 6, 7, 4, 1, 4, 3, 1, 4, 1, 5, 2, 5, 3, 4, 1, 2,
4, 5, 1, 4, 4, 6, 3, 1, 4, 4, 5, 5, 6, 4, 3, 3, 1, 4, 5, 1, 1, 2,
3, 1, 1, 6, 7, 6, 4, 6, 1, 3, 4, 1, 4, 2, 7, 4, 5, 1, 4, 2, 1, 7,
3, 6, 4, 4, 1, 7, 1, 5, 4, 4, 1, 4, 4, 1, 1, 4, 1, 1, 3, 6, 3, 3,
6, 5, 4, 3, 1, 2, 6, 6, 6, 4, 2, 2, 3, 1, 5, 1, 4, 1, 7, 3, 1, 1,
3, 5, 6, 2, 4, 1, 1, 6, 1, 6, 6, 6, 7, 1, 5, 4, 2, 7, 1, 6, 3, 1,
4, 5, 2, 1, 4, 5, 6, 3, 1, 5, 1, 6, 3, 1, 3, 6, 6, 5, 1, 6, 4, 1,
7, 3, 4, 3, 7, 3, 6, 1, 5, 3, 4, 2, 4, 5, 4, 1, 1, 4, 6, 3, 6, 5,
4, 6, 1, 6, 3, 1, 4, 4, 3, 1, 5, 6, 6, 3, 5, 3, 5, 2, 1, 3, 2, 4,
1, 4, 1, 3, 7, 6, 3, 4, 4, 1, 4, 2, 1, 4, 4, 2, 1, 3, 1, 3, 4, 7,
4, 4, 1, 1, 1, 1, 4, 4, 1, 4, 5, 6, 5, 3, 3, 1, 4, 3, 2, 2, 6, 4,
4, 3, 2, 2, 1, 6, 3, 1, 3, 1, 6, 7, 4, 4, 4, 1, 1, 4, 3, 1, 4, 5,
4, 3], dtype=int64)
from sklearn.metrics import accuracy_score,f1_score,confusion_matrix,classification_report
print(classification_report(y_test,predict_y))
precision recall f1-score support
1 1.00 1.00 1.00 117
2 0.97 1.00 0.99 36
3 0.99 0.88 0.93 75
4 0.92 0.99 0.95 117
5 1.00 1.00 1.00 43
6 1.00 0.99 0.99 73
7 1.00 0.96 0.98 25
accuracy 0.98 486
macro avg 0.98 0.97 0.98 486
weighted avg 0.98 0.98 0.98 486
小结

Original: https://blog.csdn.net/Mind_programmonkey/article/details/121126350
Author: mind_programmonkey
Title: 【人工智能项目】LSTM实现数据预测分类实验
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/648225/
转载文章受原作者版权保护。转载请注明原作者出处!