

目录
- 1 最大似然估计
* - 1.1 实验要求
- 1.2 实验思路
- 1.3 代码实现
- 1.4 实验结果
- 2 Parzen窗
* - 2.1 实验要求
- 2.2 实验思路
- 2.3 代码实现
- 2.4 实验结果
- 3 K近邻
* - 3.1 实验要求
- 3.2 实验思路
- 3.3 代码实现及结果
– - 4 KNN实战
* - 4.1 实验要求
- 4.2 实验思路
- 4.3 实验结果与思考
1 最大似然估计
1.1 实验要求
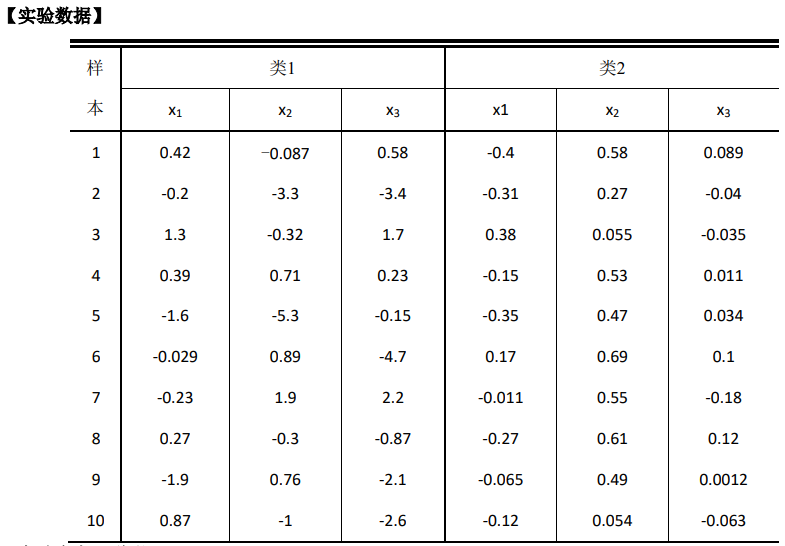

使用上面给出的三维数据:
- 编写程序,对类1和类2中的三个特征𝑥𝑖分别求解最大似然估计的均值𝜇̂和方差σ 2 \sigma^2 σ2。
- 编写程序,处理二维数据的情形𝑝(𝑥)~𝑁(µ, Σ)。对类1和类2中任意两个特征的组合分别求解最大似然估计的均值𝜇̂和方差Σ \Sigma Σ(每个类有3种可能)。
- 编写程序,处理三维数据的情形𝑝(𝑥)~𝑁(µ, Σ)。对类1和类2中三个特征求解最大似然估计的均值𝜇̂和 方差𝛴。
- 假设该三维高斯模型是可分离的,即Σ = d i a g ( σ 1 , σ 2 , σ 3 ) \Sigma=diag(\sigma^1,\sigma^2,\sigma^3)Σ=d i a g (σ1 ,σ2 ,σ3 ),编写程序估计类1和类2中的均值和协方差矩阵中的参数。
- 比较前 4 种方法计算出来的每一个特征的均值μ \mu μ的异同,并加以解释。
- 比较前 4 种方法计算出来的每一个特征的方差σ \sigma σ的异同,并加以解释。
; 1.2 实验思路
根据最大似然估计的原理,可以推导出:均值的最大似然估计就是样本的均值,而协方差的最大似然估计是n个( x k − μ ^ ) ( x k − μ ^ ) t (\textbf{x}_k-\hat{\mu})(\textbf{x}_k-\hat{\mu})^t (x k −μ^)(x k −μ^)t的算术平均。实际上对方差的最大似然估计是有偏的估计,样本的协方差矩阵C = 1 n − 1 ( x k − μ ^ ) ( x k − μ ^ ) t C=\frac{1}{n-1}(\textbf{x}_k-\hat{\mu})(\textbf{x}_k-\hat{\mu})^t C =n −1 1 (x k −μ^)(x k −μ^)t,而我们估计的方差是σ ^ = n − 1 n C \hat{\sigma}=\frac{n-1}{n}C σ^=n n −1 C,具体原理可以看:参数估计—最大似然估计与贝叶斯估计

对于任意一个 多元的高斯分布, 这里的多元就对应着数据的多特征(例如本次实验中的x1,x2,x3),此高斯分布的采样是以列向量的形式,每行的值为一个随机变量,因此计算统计属性:
- 均值:分别计算每个特征的均值,以向量的形式输出,即均值向量
- 方差:数据集中所有向量( 列向量)计算( x − μ ) ( x − μ ) T (\textbf{x}-\mu)(\textbf{x}-\mu)^T (x −μ)(x −μ)T,在求和取平均
当高斯模型是可分离的时,说明每个特征(随机变量)相互独立,则任意两个特征的协方差为0(Cov(x1,x2)=0),因此协方差矩阵的形式如下:
[ σ 1 2 0 . . . 0 0 σ 2 2 0 . . . . . . 0 0 σ n 2 ] \begin{bmatrix} \sigma_{1}^2 & 0 & … & 0\ 0 & \sigma_{2}^2 & & 0\ … & & … & \ 0 & 0 & & \sigma_{n}^2 \end{bmatrix}⎣⎢⎢⎡σ1 2 0 …0 0 σ2 2 0 ……0 0 σn 2 ⎦⎥⎥⎤
; 1.3 代码实现
数据以DataFrame的形式存储,计算均值向量的函数:
def calculateAvg(vectors:pd.DataFrame):
avg = pd.Series(index=vectors.columns,dtype=float)
for column in vectors.columns:
avg[column] = vectors[column].mean()
return np.array(avg)
计算协方差矩阵的函数:
def calculateCov(vectors:pd.DataFrame):
mu = np.matrix(calculateAvg(vectors)).T
dimension = vectors.shape[1]
Cov = np.zeros((dimension,dimension))
for index,row in vectors.iterrows():
xi = np.matrix(row).T
diff = xi - mu
Cov+=diff*diff.T
return Cov/vectors.shape[0]
利用 DataFrame[[特征1,特征2,..]]来提取训练集中的某几个特征,分别实现计算。
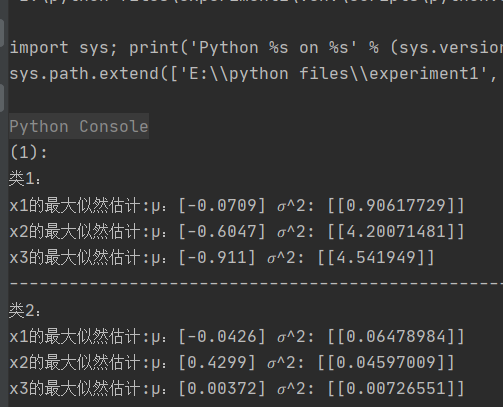
- 问(1)编写程序,对类1和类2中的三个特征𝑥𝑖分别求解最大似然估计的均值𝜇̂和方差σ 2 \sigma^2 σ2。
trainSet_1 = pd.read_csv('w1.csv')
trainSet_2 = pd.read_csv('w2.csv')
print("(1): ")
print("类1:")
trainSet_1_x1 = trainSet_1['x1'].to_frame()
print("x1的最大似然估计:μ:"+str(calculateAvg(trainSet_1_x1))+" 𝜎^2: "+str(calculateCov(trainSet_1_x1)))
trainSet_1_x2 = trainSet_1['x2'].to_frame()
print("x2的最大似然估计:μ:"+str(calculateAvg(trainSet_1_x2))+" 𝜎^2: "+str(calculateCov(trainSet_1_x2)))
trainSet_1_x3 = trainSet_1['x3'].to_frame()
print("x3的最大似然估计:μ:"+str(calculateAvg(trainSet_1_x3))+" 𝜎^2: "+str(calculateCov(trainSet_1_x3)))
print("------------------------------------------------------------------------------")
print("类2:")
trainSet_2_x1 = trainSet_2['x1'].to_frame()
print("x1的最大似然估计:μ:"+str(calculateAvg(trainSet_2_x1))+" 𝜎^2: "+str(calculateCov(trainSet_2_x1)))
trainSet_2_x2 = trainSet_2['x2'].to_frame()
print("x2的最大似然估计:μ:"+str(calculateAvg(trainSet_2_x2))+" 𝜎^2: "+str(calculateCov(trainSet_2_x2)))
trainSet_2_x3 = trainSet_2['x3'].to_frame()
print("x3的最大似然估计:μ:"+str(calculateAvg(trainSet_2_x3))+" 𝜎^2: "+str(calculateCov(trainSet_2_x3)))
- 问(2)编写程序,处理二维数据的情形𝑝(𝑥)~𝑁(µ, Σ)。对类1和类2中任意两个特征的组合分别求解最大似然估计的均值𝜇̂和方差Σ \Sigma Σ(每个类有3种可能)。
trainSet_1 = pd.read_csv('w1.csv')
trainSet_2 = pd.read_csv('w2.csv')
print("(2): ")
print("类1:")
trainSet_1_x1x2 = trainSet_1[['x1','x2']]
print("(x1,x2)的最大似然估计:")
print("μ:"+str(calculateAvg(trainSet_1_x1x2)))
print("𝜎^2: ")
print(calculateCov(trainSet_1_x1x2))
trainSet_1_x1x3 = trainSet_1[['x1','x3']]
print("(x1,x3)的最大似然估计:")
print("μ:"+str(calculateAvg(trainSet_1_x1x3)))
print("𝜎^2:")
print(calculateCov(trainSet_1_x1x3))
trainSet_1_x2x3 = trainSet_1[['x2','x3']]
print("(x2,x3)的最大似然估计:")
print("μ:"+str(calculateAvg(trainSet_1_x2x3)))
print("𝜎^2: ")
print(calculateCov(trainSet_1_x2x3))
print("------------------------------------------------------------------------------")
print("类2:")
trainSet_2_x1x2 = trainSet_2[['x1','x2']]
print("(x1,x2)的最大似然估计:")
print("μ:"+str(calculateAvg(trainSet_2_x1x2)))
print("𝜎^2: ")
print(calculateCov(trainSet_2_x1x2))
trainSet_2_x1x3 = trainSet_2[['x1','x3']]
print("(x1,x3)的最大似然估计:")
print("μ:"+str(calculateAvg(trainSet_2_x1x3)))
print("𝜎^2: ")
print(calculateCov(trainSet_2_x1x3))
trainSet_2_x2x3 = trainSet_2[['x2','x3']]
print("(x2,x3)的最大似然估计:")
print("μ:"+str(calculateAvg(trainSet_2_x2x3)))
print("𝜎^2: ")
print(calculateCov(trainSet_2_x2x3))
- (3)编写程序,处理三维数据的情形𝑝(𝑥)~𝑁(µ, Σ)。对类1和类2中三个特征求解最大似然估计的均值𝜇̂和 方差𝛴。
trainSet_1 = pd.read_csv('w1.csv')
trainSet_2 = pd.read_csv('w2.csv')
print("(3)")
print("类1")
print("(x1,x2,x3)的最大似然估计: µ"+str(calculateAvg(trainSet_1)))
print("Σ:")
print(calculateCov(trainSet_1))
print("------------------------------------------------------------------------------")
print("类2")
print("(x1,x2,x3)的最大似然估计: µ"+str(calculateAvg(trainSet_2)))
print("Σ:")
print(calculateCov(trainSet_2))
- (4)假设该三维高斯模型是可分离的,即Σ = d i a g ( σ 1 , σ 2 , σ 3 ) \Sigma=diag(\sigma^1,\sigma^2,\sigma^3)Σ=d i a g (σ1 ,σ2 ,σ3 ),编写程序估计类1和类2中的均值和协方差矩阵中的参数。
trainSet_1 = pd.read_csv('w1.csv')
trainSet_2 = pd.read_csv('w2.csv')
trainSet_1_x1 = trainSet_1['x1'].to_frame()
trainSet_1_x2 = trainSet_1['x2'].to_frame()
trainSet_1_x3 = trainSet_1['x3'].to_frame()
trainSet_2_x1 = trainSet_2['x1'].to_frame()
trainSet_2_x2 = trainSet_2['x2'].to_frame()
trainSet_2_x3 = trainSet_2['x3'].to_frame()
print("类1")
print("(x1,x2,x3)的最大似然估计:")
print("µ"+str(calculateAvg(trainSet_1)))
Cov_1 = np.zeros((3,3))
Cov_1[0, 0] = calculateCov(trainSet_1_x1)
Cov_1[1, 1] = calculateCov(trainSet_1_x2)
Cov_1[2, 2] = calculateCov(trainSet_1_x3)
print("Σ:")
print(Cov_1)
print("----------------------------------------------------------")
print("类2")
print("(x1,x2,x3)的最大似然估计:")
print("µ"+str(calculateAvg(trainSet_2)))
Cov_2 = np.zeros((3,3))
Cov_2[0, 0] = calculateCov(trainSet_2_x1)
Cov_2[1, 1] = calculateCov(trainSet_2_x2)
Cov_2[2, 2] = calculateCov(trainSet_2_x3)
print("Σ:")
print(Cov_2)
- (5)(6)比较前 4 种方法计算出来的每一个特征的均值μ \mu μ与方差Σ \Sigma Σ的异同,并加以解释。 均值的计算与向量维度无关,都是每一维数据求和再除以n。 因为该模型是可分离的,所以各个特征之间相互独立,每个训练样本向量(x1,x2,x3)的Cov(xi,xj)=0 所以协方差是一个对角矩阵,除对角线外其他处的值为0,对角线即为一维数据的方差。
1.4 实验结果
2. 问题2
`
(2):
类1:
(x1,x2)的最大似然估计:
μ:[-0.0709 -0.6047]
𝜎^2:
[[0.90617729 0.56778177]
[0.56778177 4.20071481]]
(x1,x3)的最大似然估计:
μ:[-0.0709 -0.911 ]
𝜎^2:
[[0.90617729 0.3940801 ]
[0.3940801 4.541949 ]]
(x2,x3)的最大似然估计:
μ:[-0.6047 -0.911 ]
𝜎^2:
[[4.20071481 0.7337023 ]
[0.7337023 4.541949 ]]
Original: https://blog.csdn.net/qq_45785407/article/details/121442792
Author: Sunburst7
Title: 实验——参数估计与非参数估计
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/648171/
转载文章受原作者版权保护。转载请注明原作者出处!