

欢迎访问个人网络日志🌹🌹知行空间🌹🌹
元学习算法MAML简介
*
– 1.元学习(meta learning)
– 2.模型无关元学习
–
+ 2.1 元学习问题建模
+ 2.2 MAML算法
– 3.将MAML应用到回归分类任务上的算法流程
– 4.代码解读
– 参考资料
论文: Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks Chelsea
代码: https://github.com/cbfinn/maml
ICML2017的一篇论文,作者 Chelsea Finn是斯坦福的老师,一不小心去作者主页看了下,MIT和伯克利的学生,真强。_
元学习MAML论文介绍
模型无关元学习算法,即 Model-Agnostic Meta-Learning Algorithm(MAML)。
1.元学习(meta learning)
元学习即学会学习,区别与普通的深度学习过程。普通的深度学习具体到某一任务,如图像分类,即训练一个模型实现一个数据集内的图像分类,这种方法有一定的局限性,即模型只能在当前任务(task)上工作,不能应用到其他任务。譬如基于手写字识别数据集训练的分类模型不能用来实现猫和狗的分类。有没有一种方法,可以学会完成分类这一任务,不针对具体是实现哪些对象的分类,学会分类任务后再基于少量的具体数据训练学会是具体给猫狗分类还是给手写字分类。相当于说一个模型实现了原来多个模型的功能。
元学习训练模型是为了获得一个可以快速应用到小样本数据的新任务上的模型,元学习通过初步训练获得模型比较好的初值,再基于初值对具体任务在小样本训练数据上少量更新权重即可取得好的效果。
元学习还可以理解成是寻找一组具有较高敏感度的参数,基于找到的参数,只需要进行少量的迭代即可在新的任务上取得理想的结果。
元学习可应用于训练数据有限的 Few-Shot Learning任务。
2.模型无关元学习
2.1 元学习问题建模
元学习是在一系列任务上学习,目标是学习得到一个比较敏感的模型,使该模型能够基于小样本数据简单训练快速应用到新任务上。也就是说,元学习将一系列学习任务当作训练样本。
譬如,识别一个动物是不是狗是任务T 1 T_1 T 1 ,识别一个手写数字是不是9是任务T 2 T_2 T 2 ,识别一辆车是不是坦克是任务T 3 T_3 T 3 ,普通的学习方法会针对每个训练一个模型,也是基于前述的任务要训练3个模型分别完成。观察前面的三个任务T 1 , T 2 , T 3 T_1,T_2,T_3 T 1 ,T 2 ,T 3 具有共性,即都是识别分类任务,能不能有一种通用模型可以学习识别分类这一任务,然后再基于少量的数据对通用模型微调即可快速应用的新的类似任务。如基于T 1 , T 2 , T 2 T1,T2,T2 T 1 ,T 2 ,T 2使模型学会分类能力,然后提供少量的 是否是飞机的训练数据,即可快速学会判断天空中的一个物体是否是飞机。
使用数学公式描述:
单个任务表示为:
T = { L ( X 1 , a 1 , . . . , X H , a H ) , q ( X 1 ) , q ( X t + 1 ∣ X t , a t ) , H } T={L(X_1,a_1,…,X_H,a_H),q(X_1),q(X_{t+1}|X_t,a_t),H}T ={L (X 1 ,a 1 ,…,X H ,a H ),q (X 1 ),q (X t +1 ∣X t ,a t ),H }
- X X X是输入
- a a a是输出
- L L L是损失函数
- q ( X 1 ) q(X_1)q (X 1 )是初始输入变量的概率分布
- q ( X t + 1 ∣ X t , a t ) q(X_{t+1}|X_t,a_t)q (X t +1 ∣X t ,a t )是输入变量的状态转移分布
- H H H输入变量序列的长度,对于监督学习问题,其值为
1,应用在强化学习等中。 - L ( X 1 , a 1 , . . . , X H , a H ) → R L(X_1,a_1,…,X_H,a_H) \rightarrow \R L (X 1 ,a 1 ,…,X H ,a H )→R是针对具体任务的损失函数,如回归问题通常是均方误差(Mean Square Error, MSE),分类问题通常是交叉商(Cross Entropy, CE)。
在元学习(meta-learning)中,考虑多个任务T T T的分布为p ( T ) p(T)p (T ),这正是元学习模型要学习的目标。具体的任务T i T_i T i 是从任务分布p ( T ) p(T)p (T )中取样的,模型的训练基于任务T i T_i T i 的K K K个训练样本和任务T i T_i T i 的损失函数L i L_i L i 。任务T i T_i T i 的测试误差,将作为元学习模型的训练误差。
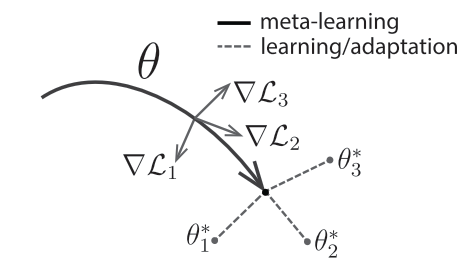

上图中∇ L 1 , ∇ L 2 , ∇ L 3 \nabla L_1,\nabla L_2,\nabla L_3 ∇L 1 ,∇L 2 ,∇L 3 分别表示任务T 1 , T 2 , T 3 T_1,T_2,T_3 T 1 ,T 2 ,T 3 上的损失函数梯度,θ 1 ⋆ , θ 2 ⋆ , θ 3 ⋆ \theta_1^\star,\theta_2^\star,\theta_3^\star θ1 ⋆,θ2 ⋆,θ3 ⋆分别表示具体到任务T 1 , T 2 , T 3 T_1,T_2,T_3 T 1 ,T 2 ,T 3 上的参数,θ \theta θ是元学习模型的参数。
; 2.2 MAML算法

算法中参数更新分成两步,一次是更新
θ ′ \theta’θ′,之后才是更新θ \theta θ。这和元学习的的定义相关。θ ′ \theta’θ′的更新是在具体某个T a s k i {Task}_i T a s k i 上学习时发生的,而元学习的目标是找到一组参数θ \theta θ能够对多个任务T a s k Task T a s k都具有表征能力。所以t h e t a theta t h e t a的更新过程分成了两个,先是针对具体任务T a s k i Task_i T a s k i 的更新优化后是针对元学习模型的优化。
第一步,针对任务T i T_i T i 的模型优化为:
θ ′ = θ − α ∇ θ L T i ( f θ ) \theta’=\theta-\alpha\nabla_{\theta}L_{T_i}(f_\theta)θ′=θ−α∇θL T i (f θ)
- f θ f_\theta f θ表示元学习模型
第二步,针对元学习模型的优化为:
m i n θ ∑ T i ∼ p ( T ) L T i ( f θ ′ ) = ∑ T i ∼ p ( T ) L T i ( f θ − α ∇ θ L T i ( f θ ) ) θ ← θ − β ∇ θ ∑ T i ∼ p ( T ) L T i ( f θ ′ ) \mathop{min}\limits \theta \sum\limits{T_i\sim p(T)}L_{T_i}(f_\theta’)=\sum\limits_{T_i\sim p(T)}L_{T_i}(f_{\theta-\alpha\nabla_{\theta}L_{T_i}(f_\theta)}) \ \ \theta \leftarrow \theta – \beta\nabla_\theta\sum\limits_{T_i\sim p(T)}L_{T_i}(f_\theta’)θmin T i ∼p (T )∑L T i (f θ′)=T i ∼p (T )∑L T i (f θ−α∇θL T i (f θ))θ←θ−β∇θT i ∼p (T )∑L T i (f θ′)
3.将MAML应用到回归分类任务上的算法流程

方程2和方程3分别是均方误差和交叉熵。
; 4.代码解读
MAML原作者的代码是基于 tensorflow 1.x版本实现的,结构比较清晰。
模型封装了一个MAML类,数据的加载在类 DataGenerator中。
main.py的train函数中定义了 metatrain的过程:
for itr in range(resume_itr, FLAGS.pretrain_iterations + FLAGS.metatrain_iterations):
feed_dict = {}
if 'generate' in dir(data_generator):
batch_x, batch_y, amp, phase = data_generator.generate()
if FLAGS.baseline == 'oracle':
batch_x = np.concatenate([batch_x, np.zeros([batch_x.shape[0], batch_x.shape[1], 2])], 2)
for i in range(FLAGS.meta_batch_size):
batch_x[i, :, 1] = amp[i]
batch_x[i, :, 2] = phase[i]
"""
# a: training data for inner gradient,
# b: test data for meta gradient
这里 数据被分成两部分inputa和inputb
inputa用来训练针对具体任务的模型,更新其权重
inputb用来测试基于inputa训练的模型,并计算对具体任务的模型在intputb的losses
inputb上的测试loss用来更新元模型,具体实现见maml.py中task_metalearn函数
"""
inputa = batch_x[:, :num_classes*FLAGS.update_batch_size, :]
labela = batch_y[:, :num_classes*FLAGS.update_batch_size, :]
inputb = batch_x[:, num_classes*FLAGS.update_batch_size:, :]
labelb = batch_y[:, num_classes*FLAGS.update_batch_size:, :]
feed_dict = {model.inputa: inputa, model.inputb: inputb, model.labela: labela, model.labelb: labelb}
if itr < FLAGS.pretrain_iterations:
input_tensors = [model.pretrain_op]
else:
input_tensors = [model.metatrain_op]
...
result = sess.run(input_tensors, feed_dict)
在 MAML类 construct_model函数中定义有 task_metalearn函数,在这个函数中有使用 num_updates参数, num_updates参数表示 train函数中的每个元模型训练迭代中针对某个任务的模型迭代次数,针对某个任务的模型每更新一次,在测试数据 inputb上计算1次 losses,更新 某个任务的模型num_updates次后,得到长度为 num_updates的list lossesb,再用 lossesb来更新元模型。
def task_metalearn(inp, reuse=True):
""" Perform gradient descent for one task in the meta-batch. """
inputa, inputb, labela, labelb = inp
task_outputbs, task_lossesb = [], []
if self.classification:
task_accuraciesb = []
task_outputa = self.forward(inputa, weights, reuse=reuse)
task_lossa = self.loss_func(task_outputa, labela)
grads = tf.gradients(task_lossa, list(weights.values()))
if FLAGS.stop_grad:
grads = [tf.stop_gradient(grad) for grad in grads]
gradients = dict(zip(weights.keys(), grads))
fast_weights = dict(zip(weights.keys(), [weights[key] - self.update_lr*gradients[key] for key in weights.keys()]))
output = self.forward(inputb, fast_weights, reuse=True)
task_outputbs.append(output)
task_lossesb.append(self.loss_func(output, labelb))
for j in range(num_updates - 1):
loss = self.loss_func(self.forward(inputa, fast_weights, reuse=True), labela)
grads = tf.gradients(loss, list(fast_weights.values()))
if FLAGS.stop_grad:
grads = [tf.stop_gradient(grad) for grad in grads]
gradients = dict(zip(fast_weights.keys(), grads))
fast_weights = dict(zip(fast_weights.keys(), [fast_weights[key] - self.update_lr*gradients[key] for key in fast_weights.keys()]))
output = self.forward(inputb, fast_weights, reuse=True)
task_outputbs.append(output)
task_lossesb.append(self.loss_func(output, labelb))
task_output = [task_outputa, task_outputbs, task_lossa, task_lossesb]
训练结束得到元模型后,要将元模型应用到具体任务时,要先根据提供的样本数据 (x,y)对元模型进行微调 test_num_updates后,再使用微调后的模型在测试数据上输出测试结果,其过程参照 task_metalearn。这也就能解释测试时所用的类在训练时是没有的,为什么测试时模型可以输出测试的类别。正因为模型在测试时有个在少量测试数据上的微调的过程,可以理解成元学习模型先训练得到一个预训练权重,然后再在少量新的其他任务的训练数据上少里训练,然后在新任务的测试数据上验证。
类别为a,b的训练数据
训练
元学习模型
微调fast_learning
类别为c,d的测试数据
类别为c,d的测试数据
测试
参考资料
欢迎访问个人网络日志🌹🌹知行空间🌹🌹
Original: https://blog.csdn.net/lx_ros/article/details/124335133
Author: 恒友成
Title: (二)元学习算法MAML简介及代码分析
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/647635/
转载文章受原作者版权保护。转载请注明原作者出处!