

基本问题
工业生产过程中会产生大量的数据,比如电压、温度、流量等等,它们随时间推移而不断产生,这些数据在多数情况下是正常的,否则生产无法正常进行;少数情况下,数据是异常的,生产效率会降低甚至发生事故。在重大事件(如事故)发生之前,通常会在运行数据上有所体现,比如电流突然上升,后续很可能断电,造成一些不必要的损失,如果及时发现电流增大这一信号,及时找到原因并处置则可以将损失降到最小。因此及时发现异常数据并报警,提醒操作人员进行相应的操作,可以提高生产效率并避免事故发生。
当前工业界常用的异常发现机制很简单,一般是凭经验设置一个范围,当仪表超过该范围时就认为是异常。这种方式过于简单粗暴了,经常会发生漏报(范围设置过宽)或误报(范围设置过窄)。因为生产过程是动态的,产生的数据也是动态的,简单的设置范围不可能适用于所有的生产状况,如下图:
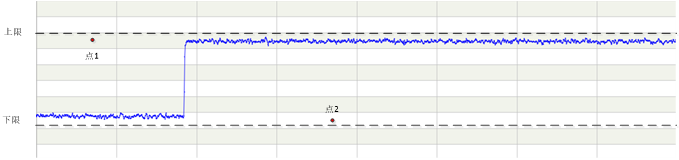

左侧平稳期和右侧平稳期都是正常状态,如果左侧出现点1,右侧出现点2,它们都应该被判定为异常点,但如果简单的用固定范围来判断,这两个点都在固定范围内(图中的上下限),判断就会出错,所以需要动态的去判断某个点是否异常。
动态的判断异常,容易想到的方法是利用机器学习方法来动态发现异常。但机器学习是有监督方法,需要大量已知的异常数据,而实际场景通常并没有这些现成的数据,还需要人工标记出来。但是工业仪表产生的数据量对于人来说是个天文数字,依靠人工来标记不现实,而且人工标记也很难保证正确性,还要再去校对,工作量无比巨大,结果也就没有可操作性。所以只能使用无监督学习方法完成异常发现任务。
; 算法思路
没有标记好的异常数据,无监督方法怎么定义”异常”呢?
先来看一份数据:
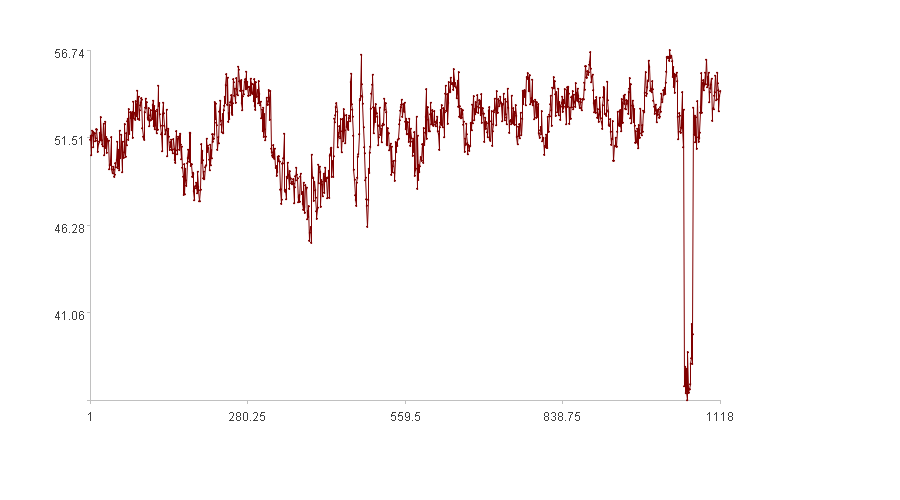
先来看人是怎么发现异常的。

人观察这段数据后,发现的异常如上图,各段原因如下:
① 变化过快;
② 值过小。
异常大致是这几类:值过大或过小和变化过快。它们有个共同的特点,出现的情况比较少。我们不难得出一个抽象的说法:经常出现的情况是正常, 没出现过或者很少出现的情况可以定义为异常。
那么发现异常的任务就转换为发现不常出现的情况,判断数据是否不常出现,就是看当前数据相较于之前一段时间内的数据是否不常出现。利用之前一段时间数据学出一个模型 E,用它来判断当前数据是否异常。比如之前一段时间的数据在110内,那么当前时刻的数据在这个范围内就认为是正常,如果当前时刻的数据不在该范围内(比如等于11或0),则认为是异常。而110这个范围就是通过历史数据学出的模型 E。拿着模型 _E_就能算出当前数据是否异常了,即:

这样数据过大或者过小的异常就可以被发现了。
但是这种方法不一定能发现变化过快的异常数据,如下图:

上述方法可以发现(b)©中的异常,但对于(d)中的异常就无能为力了,那该如何发现呢?
(d)中的情况就是变化过快,我们来看看能否用”变化快慢”这个数学量来发现异常。

上图中曲线 _C_就是”变化快慢”曲线,他是利用原值 _X_衍生得到的,用刚才介绍的方法对 _C_来发现异常即可发现变化过快这类异常。
由此看来, 只要找到合适的数学量来表征这些数据的某些特征,就可以区分出常见和不常见的状态。比如下图:
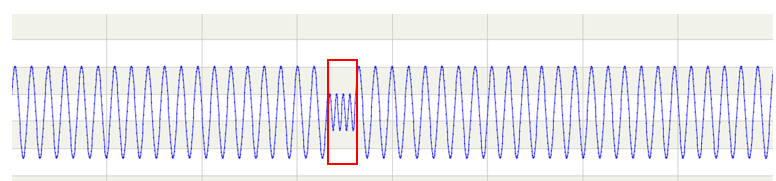
红框中的异常就是幅度异常,值和变化率都处于正常范围,只是幅度变小了,此时需要一个表征幅度的数学量来发现异常。
仅仅是生成是否异常还不够,异常还应区分异常的程度,比如1~10范围内是正常的,当前时刻是11的异常度就应该小于当前时刻是15的异常度,也就是说超限的幅度越大,异常度越大。这就要改造上面模型 E,让它的判断结果返回一个连续值,使其能表征超限幅度越大,异常度越大。
实践效果
把上面思路写成代码,就可以完成异常发现了。比如动态算出值过大过小的异常度,SPL代码大体如下:
A1=file(C1).import@tc().(tag1)2=A1.(if(#
Original: https://blog.csdn.net/u010634066/article/details/126738031
Author: 石臻臻的杂货铺
Title: SPL工业智能:发现时序数据的异常
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/646396/
转载文章受原作者版权保护。转载请注明原作者出处!