

yolov5 训练结果解析
本文仅用于记录之前在CSDN中所学有关YOLOv5结果解析所转载知识的记录和总结笔记用。
在每次训练之后,都会在runs-train 文件夹下出现一下文件,如下图:


一:weights
包含best.pt (做detect 时用这个)和last.pt (最后一次训练模型)
二:confusion
1 :混淆矩阵:
①:混淆矩阵是对分类问题的预测结果的总结。使用计数值汇总正确和不正确预测的数量,并按每个类进行细分,这是混淆矩阵的关键所在。混淆矩阵显示了分类模型的在进行预测时会对哪一部分产生混淆。它不仅可以让我们了解分类模型所犯的错误,更重要的是可以了解哪些错误类型正在发生。正是这种对结果的分解克服了仅使用分类准确率所带来的局限性。
②:在机器学习领域和统计分类问题中,混淆矩阵(英语:confusion matrix )是可视化工具,特别用于监督学习,在无监督学习一般叫做匹配矩阵。矩阵的每一列代表一个类的实例预测,而每一行表示一个实际的类的实例。之所以如此命名,是因为通过这个矩阵可以方便地看出机器是否将两个不同的类混淆了(比如说把一个类错当成了另一个)。
2 :图解
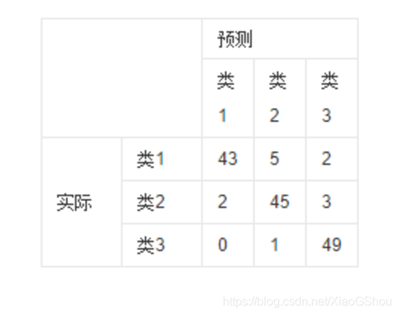
该图解释:
横轴是预测类别,纵轴是真实类别;
每一行之和为 50 ,表示每个类各有 50 个样本,第一行说明类 1 的 50 个样本有 43 个分类正确, 5 个错分为类 2 , 2 个错分为类 3 。
每一行代表了真实的目标被预测为其他类的数量,比如第一行: 43 代表真实的类一中有 43 个被预测为类一, 5 个被错预测为类 2,2 个被错预测为类 3 ;
表格里的数目总数为 150 ,表示共有 150 个测试样本,
3 : TP/TN/FP/FN

①.真阳性(True Positive ,TP ):样本的真实类别是正例,并且模型预测的结果也是正例,预测正确
②.真阴性(True Negative ,TN ):样本的真实类别是负例,并且模型将其预测成为负例,预测正确
③.假阳性(False Positive ,FP ):样本的真实类别是负例,但是模型将其预测成为正例,预测错误
④.假阴性(False Negative ,FN ):样本的真实类别是正例,但是模型将其预测成为负例,预测错误
几个指标:
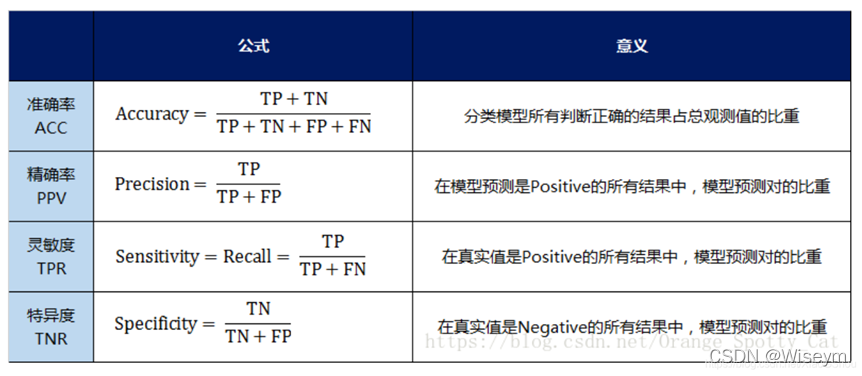
1 )正确率(accuracy )
正确率是我们最常见的评价指标,accuracy =(TP+TN )/(P+N),这个很容易理解,就是被分对的样本数除以所有的样本数,通常来说,正确率越高,分类器越好;
2 )错误率(error rate)
错误率则与正确率相反,描述被分类器错分的比例,error rate = (FP+FN)/(P+N),对某一个实例来说,分对与分错是互斥事件,所以accuracy =1 – error rate ;
3 )灵敏度(sensitive )
sensitive = TP/P ,表示的是所有正例中被分对的比例,衡量了分类器对正例的识别能力;
4 )特效度(specificity)
specificity = TN/N ,表示的是所有负例中被分对的比例,衡量了分类器对负例的识别能力;
5 )精度(precision )
精度是精确性的度量,表示被分为正例的示例中实际为正例的比例,precision=TP/(TP+FP );
6 )召回率(recall )
召回率是覆盖面的度量,度量有多个正例被分为正例,recall=TP/(TP+FN)=TP/P=sensitive ,可以看到召回率与灵敏度是一样的。
①:accuracy (总体准确率)
分类模型总体判断的 准确率(包括了所有class 的总体准确率)

为什么说 acc 常用,但不能满足所有任务分类要求呢?
例1 :恐怖分子识别任务,二分类问题,恐怖分子为正例,非恐怖分子负例。
这个任务的特点是正例负例分布非常不平均,因为恐怖分子的数量远远小于非恐怖分子的数量。假设一个数据集中的恐怖分子的数量与非恐怖分子的数量比例为1:999999999 ,我们引入一个二分类判别模型,它的行为是将所有样例都识别为负例(非恐怖分子),那么在这个数据集上该模型的Accuracy 高达99.9999999%,但恐怕没有任何一家航空公司会为这个模型买单,因为它永远不会识别出恐怖分子,航空公司更关注有多少恐怖分子被识别了出来。
例2 :垃圾邮件识别任务,二分类问题,垃圾邮件为正例,非垃圾邮件为负例。
与恐怖分子识别任务类似,人们更关心有多少垃圾邮件被识别了出来,而不是Accuracy 。
在上述两个任务中,人们的关注点发生了变化,Accuracy 已经无法满足要求,由此我们引入 Precision (精准度)和 Recall (召回率),它们 仅适用于二分类问题。
注:准确率是我们最常见的评价指标,而且很容易理解,就是被分对的样本数除以所有的样本数,通常来说,正确率越高,分类器越好。
准确率确实是一个很好很直观的评价指标,但是有时候准确率高并不能代表一个算法就好。比如某个地区某天地震的预测,假设我们有一堆的特征作为地震分类的属性,类别只有两个:0 :不发生地震、1 :发生地震。一个不加思考的分类器,对每一个测试用例都将类别划分为0 ,那那么它就可能达到99%的准确率,但真的地震来临时,这个分类器毫无察觉,这个分类带来的损失是巨大的。为什么99%的准确率的分类器却不是我们想要的,因为这里数据分布不均衡,类别1 的数据太少,完全错分类别1 依然可以达到很高的准确率却忽视了我们关注的东西。再举个例子说明下。在正负样本不平衡的情况下,准确率这个评价指标有很大的缺陷。比如在互联网广告里面,点击的数量是很少的,一般只有千分之几,如果用acc ,即使全部预测成负类(不点击)acc 也有99%以上,没有意义。因此,单纯靠准确率来评价一个算法模型是远远不够科学全面的。
②:precision (单一类准确率):预测为positive 的准确率
Precision 从预测结果角度出发,描述了二分类器预测出来的正例结果中有多少是真实正例,即该二分类器预测的正例有多少是准确的;
“分类器认为是正类并且确实是正类的部分占所有分类器认为是正类的比例”,衡量的是一个分类器分出来的正类的确是正类的概率
两种极端情况就是,如果精度是100%,就代表所有分类器分出来的正类确实都是正类。如果精度是0%,就代表分类器分出来的正类没一个是正类。光是精度还不能衡量分类器的好坏程度,比如50 个正样本和50 个负样本,我的分类器把49 个正样本和50 个负样本都分为负样本,剩下一个正样本分为正样本,这样我的精度也是100%,但是傻子也知道这个分类器很垃圾。

③:回归率recall :真实为positive 的准确率,即正样本有多少被找出来了( 召回了多少)。
Recall 从真实结果角度出发,描述了测试集中的真实正例有多少被二分类器挑选了出来,即真实的正例有多少被该二分类器召回。
“分类器认为是正类并且确实是正类的部分占所有确实是正类的比例”,衡量的是一个分类能把所有的正类都找出来的能力。两种极端情况,如果召回率是100%,就代表所有的正类都被分类器分为正类。如果召回率是0%,就代表没一个正类被分为正类。

综合 recall 和 precision :
Precision 和Recall 通常是一对矛盾的性能度量指标。一般来说,Precision 越高时,Recall 往往越低。原因是,如果我们希望提高Precision ,即二分类器预测的正例尽可能是真实正例,那么就要提高二分类器预测正例的门槛,例如,之前预测正例只要是概率大于等于0.5 的样例我们就标注为正例,那么现在要提高到概率大于等于0.7 我们才标注为正例,这样才能保证二分类器挑选出来的正例更有可能是真实正例;而这个目标恰恰与提高Recall 相反,如果我们希望提高Recall ,即二分类器尽可能地将真实正例挑选出来,那么势必要降低二分类器预测正例的门槛,例如之前预测正例只要概率大于等于0.5 的样例我们就标注为真实正例,那么现在要降低到大于等于0.3 我们就将其标注为正例,这样才能保证二分类器挑选出尽可能多的真实正例。
- Precision 和Recall 往往是一对矛盾的性能度量指标;
- 提高Precision ==提高二分类器预测正例门槛==使得二分类器预测的正例尽可能是真实正例;
- 提高Recall ==降低二分类器预测正例门槛==使得二分类器尽可能将真实的正例挑选出来;
④F1-Score
F1 分数(F1-score )是分类问题的一个衡量指标。一些多分类问题的机器学习竞赛,常常将F1-score 作为最终测评的方法。它是精确率和召回率的调和平均数,最大为1 ,最小为0 。
对于某个分类,综合了Precision 和Recall 的一个判断指标, F1-Score的值是从0 到1 的,1 是最好,0 是最差
简而言之就是想同时控制recall 和precision 来评价模型的好坏

如何理解F1
假设我们得到了模型的Precision/Recall 如下

F1 = 2(PrecisionRecall)/(Precision+Recall)

只有一个值,就好做模型对比了,这里我们根据F1 可以发现Algorithm1 是三者中最优的。
Fβ 分数 : 另外一个综合 Precision 和 Recall 的标准, F1-Score 的变形
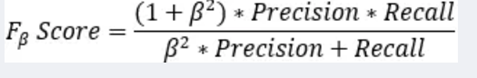

⑤:真实为negative 的准确率

⑥: 预测为negative 的准确率
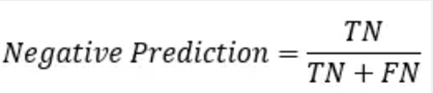
⑦:错误接受率
FAR (False Acceptance Rate)是错误接受率,也叫误识率,表示错误判定为正例的次数与所有实际为负例的次数的比例。错误判定为正例的次数是FP ,所有实际为负例的次数是(FP + TN),
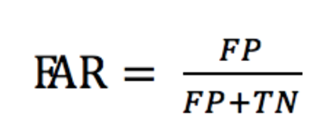
在语音唤醒例子中,FP = 1, TN = 99,所以FAR = 1 / (99 + 1) = 1%,即错误接受率为1%。在语音唤醒场景下,错误接受率也叫误唤醒率,表示说了多少次非唤醒词却被唤醒次数的比例。
⑧:错误拒绝率
FRR (False Rejection Rate)是错误拒绝率,也叫拒识率,表示错误判定为负例的次数与所有实际为正例的次数的比例。错误判定为负例的次数是FN ,所有实际为正例的次数是(TP + FN),
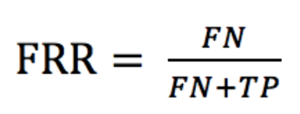
在语音唤醒例子中,FN = 2, TP = 98,所以FRR = 2/ (2 + 98) = 2%,即错误拒绝率为2%。在语音唤醒场景下,错误拒绝率也叫不唤醒率,表示说了多少次唤醒词却没被唤醒次数的比例。
4 :实例解释
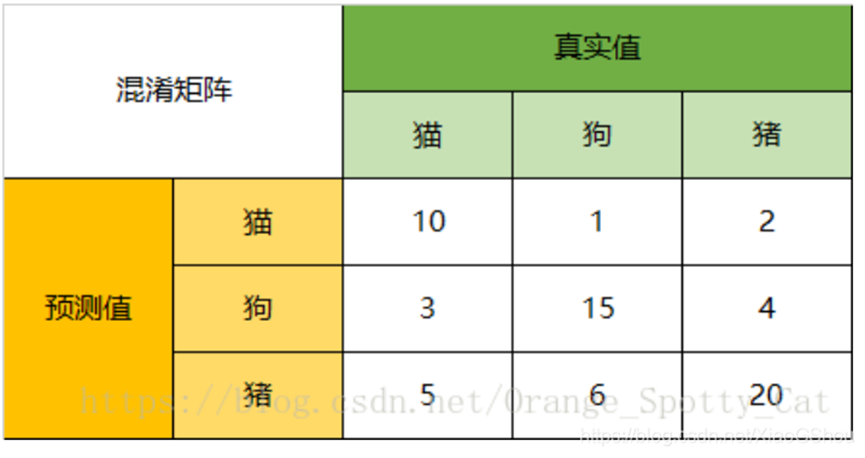
由此图可看出有66个样本,其中真实为猫的样本为18 个,狗有22 个,猪有26 个。其中预测正确的有10+15+20=45 个
Accuracy
在总共66 个动物中,我们一共预测对了10 + 15 + 20=45 个样本,所以准确率(Accuracy )=45/66 = 68.2%。
以猫为例,我们可以将上面的图合并为二分问题:

Precision
所以,以猫为例,模型的预测结果告诉我们,66 只动物里有13 只是猫,但是其实这13 只猫只有10 只预测对了。模型认为是猫的13 只动物里,有1 条狗,两只猪。所以,Precision (猫)= 10/13 = 76.9%
Recall
以猫为例,在总共18 只真猫中,我们的模型认为里面只有10 只是猫,剩下的3 只是狗,5 只都是猪。这5 只八成是橘猫,能理解。所以,Recall (猫)= 10/18 = 55.6%
Specificity
以猫为例,在总共48 只不是猫的动物中,模型认为有45 只不是猫。所以,Specificity (猫)= 45/48 = 93.8%。
虽然在45 只动物里,模型依然认为错判了6 只狗与4 只猪,但是从猫的角度而言,模型的判断是没有错的。
F1-Score
通过公式,可以计算出,对猫而言,F1-Score=(2 * 0.769 * 0.556 )/(0.769 + 0.556 )= 64.54%
同样,我们也可以分别计算猪与狗各自的二级指标与三级指标值。
3 :events.out
暂时不知道是做什么用的
4 :F1_curve
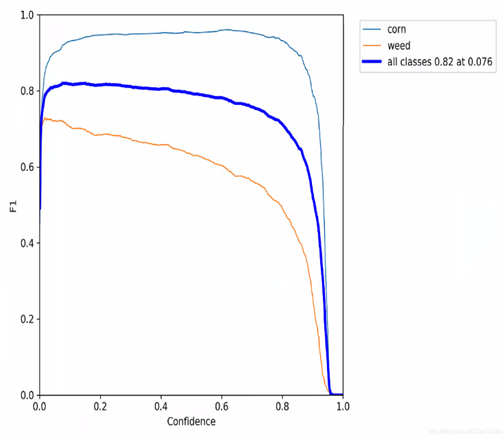
置信度和F1 分数的关系图
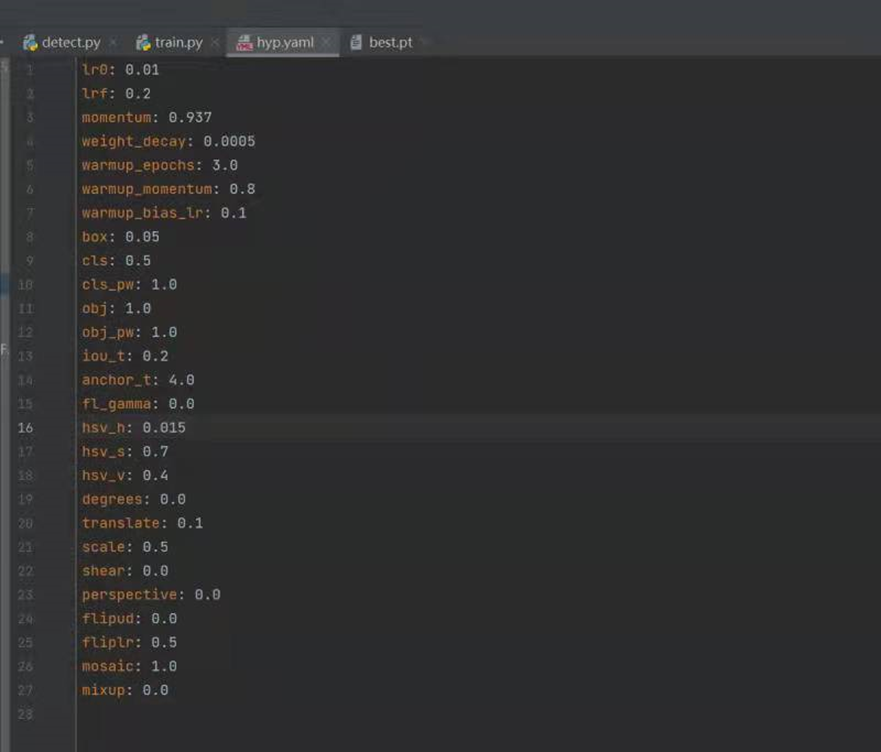
5 :hyp.yaml
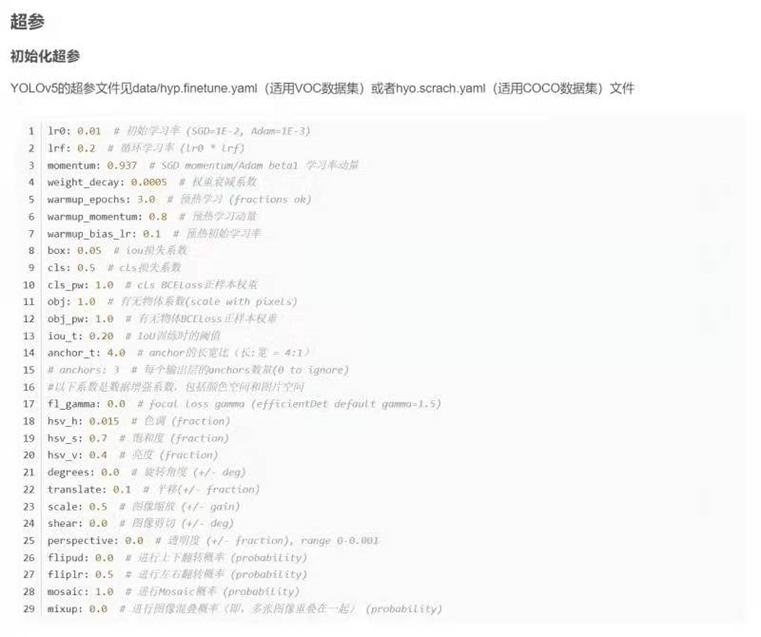

第一个图是训练集得数据量,每个类别多少
第二个就是labels
第三个就是center xy
第四个就是label 得高宽
关于labels 的统计信息,有没有作用暂时不知道

第一张图第二行第一个和第二张图第四行第三个是一样的,所以这个也是关于标记框的统计图,
具体有没有作用,后面在慢慢积累吧。
7 :opt.yaml

8:P_curve.png

准确率和置信度的关系图
9 :PR_curve.png
PR 曲线中的P 代表的是precision (精准率),R 代表的是recall (召回率),其代表的是精准率与召回率的关系,一般情况下,将recall 设置为横坐标,precision 设置为纵坐标。PR 曲线下围成的面积即AP ,所有类别AP 平均值即Map

如果其中一个学习器的PR 曲线A 完全包住另一个学习器B 的PR 曲线,则可断言A 的性能优于B 。但是A 和B 发生交叉,那性能该如何判断呢?我们可以根据曲线下方的面积大小来进行比较,但更常用的是平衡点F1 。平衡点(BEP )是P=R 时的取值(斜率为1 ),F1 值越大,我们可以认为该学习器的性能较好。

平衡点( Break-Even Point, BEP )
就是找一个 准确率 = 召回率 的值,就像上面的图那样。
如何判断一个数据集正负样本是均衡的?
PR 和 ROC 在面对不平衡数据时的表现是不同的。在数据不平衡时, PR 曲线是敏感的,随着正负样本比例的变化, PR 会发生强烈的变化。而 ROC 曲线是不敏感的,其曲线能够基本保持不变。
ROC 的面对不平衡数据的一致性表明其能够衡量一个模型本身的预测能力,而这个预测能力是与样本正负比例无关的。但是这个不敏感的特性使得其较难以看出一个模型在面临样本比例变化时模型的预测情况。而 PRC 因为对样本比例敏感,因此能够看出分类器随着样本比例变化的效果,而实际中的数据又是不平衡的,这样有助于了解分类器实际的效果和作用,也能够以此进行模型的改进。
综上,在实际学习中,我们可以使用 ROC 来判断两个分类器的优良,然后进行分类器的选择,然后可以根据 PRC 表现出来的结果衡量一个分类器面对不平衡数据进行分类时的能力,从而进行模型的改进和优化。
real world data 经常会面临class imbalance 问题,即正负样本比例失衡。根据计算公式可以推知, 在 testing set 出现imbalance 时ROC 曲线能保持不变,而PR 则会出现大变化。
PRC 相对的优势
当正负样本差距不大的情况下,ROC 和PR 的趋势是差不多的,但是当负样本很多的时候,两者就截然不同了,ROC 效果依然看似很好,但是PR 上反映效果一般。解释起来也简单,假设就1 个正例,100 个负例,那么基本上TPR 可能一直维持在100 左右,然后突然降到0 。这就说明PR 曲线在正负样本比例悬殊较大时更能反映分类的性能。
在正负样本分布得极不均匀(highly skewed datasets)的情况下,PRC 比ROC 能更有效地反应分类器的好坏。
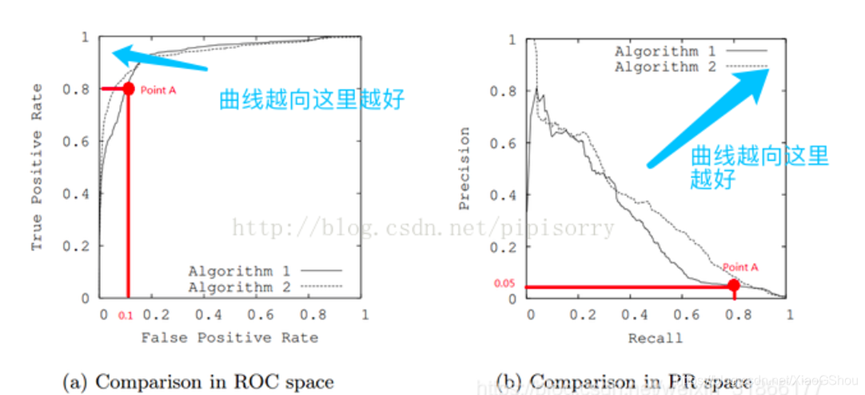
假设数据集有100 个positive instances 。由图a 中的点A ,可以得到以下结论:TPR=TP/(TP+FN)=TP/actual positives=TP/100=0.8 ,所以TP=80 由图b 中的点A ,可得:Precision=TP/(TP+FP)=80/(80+FP)=0.05 ,所以FP=1520 再由图a 中点A ,可得:FPR=FP/(FP+TN)=FP/actual negatives=1520/actual negatives=0.1 ,所以actual negatives 是15200 。
由此,可以得出原数据集中只有100 个positive instances ,却有15200 个negative instances !这就是极不均匀的数据集。直观地说,在点A 处,分类器将1600 (1520+80)个instance 分为positive ,而其中实际上只有80 个是真正的positive 。 我们凭直觉来看,其实这个分类器并不好。但由于真正negative instances 的数量远远大约positive ,ROC 的结果却”看上去很美”。所以在这种情况下,PRC 更能体现本质。
结论: 在negative instances 的数量远远大于positive instances 的data set 里,PRC 更能有效衡量分类器的好坏。
参考:PR和ROC PR
10 :R_curve.png

11:results.png

Box:YOLO V5 使用GIOU Loss 作为bounding box 的损失,Box 推测为GIoU 损失函数均值,越小方框越准;
Objectness:推测为目标检测loss 均值,越小目标检测越准;
Classification:推测为分类loss 均值,越小分类越准;
Precision:精度(找对的正类/所有找到的正类);
Recall :真实为positive 的准确率,即正样本有多少被找出来了( 召回了多少)。
Recall 从真实结果角度出发,描述了测试集中的真实正例有多少被二分类器挑选了出来,即真实的正例有多少被该二分类器召回。
val BOX: 验证集 bounding box 损失
val Objectness :验证集目标检测 loss 均值
val classification :验证集分类 loss 均值
mAP 是用Precision 和Recall 作为两轴作图后围成的面积,m 表示平均,@后面的数表示判定iou 为正负样本的阈值,@0.5:0.95 表示阈值取0.5:0.05:0.95 后取均值。
mAP@.5:.95 ( mAP@[.5:.95] )
表示在不同IoU 阈值(从0.5 到0.95 ,步长0.05 )(0.5 、0.55 、0.6 、0.65 、0.7 、0.75 、0.8 、0.85 、0.9 、0.95 )上的平均mAP 。
mAP@.5 :表示阈值大于0.5 的平均mAP
一般训练结果主要观察精度和召回率波动情况(波动不是很大则训练效果较好)
然后观察mAP@0.5 & mAP@0.5:0.95 评价训练结果。
map 计算:
就是每个recall 区间做相应的计算,即每个recall 的区间内我们只取这个区间内precision 的最大值然后和这个区间的长度做乘积,所以最后体现出来就是一系列的矩形的面积,还是以上面的那个例子为例,我们一共有recall 一共变化了7次,我们就有7个recall 区间要做计算,然后实际我们计算的时候人为的要把这个曲线变化成单调递减的,也就是对现有的precision 序列要做一些处理,
1 、precision 与recall 计算
按照置信度降序排序
sorted_ind = np.argsort(-confidence)
BB = BB[sorted_ind, :] #预测框坐标
image_ids = [image_ids[x] for x in sorted_ind] #各个预测框的对应图片id
便利预测框,并统计TPs和FPs
nd = len(image_ids)
tp = np.zeros(nd)
fp = np.zeros(nd)
for d in range(nd):
R = class_recs[image_ids[d]]
bb = BB[d, :].astype(float)
ovmax = -np.inf
BBGT = R[‘bbox’].astype(float) # ground truth
if BBGT.size > 0:
计算IoU
intersection
ixmin = np.maximum(BBGT[:, 0], bb[0])
iymin = np.maximum(BBGT[:, 1], bb[1])
ixmax = np.minimum(BBGT[:, 2], bb[2])
iymax = np.minimum(BBGT[:, 3], bb[3])
iw = np.maximum(ixmax – ixmin + 1., 0.)
ih = np.maximum(iymax – iymin + 1., 0.)
inters = iw * ih
union
uni = ((bb[2] – bb[0] + 1.) * (bb[3] – bb[1] + 1.) +
(BBGT[:, 2] – BBGT[:, 0] + 1.) *
(BBGT[:, 3] – BBGT[:, 1] + 1.) – inters)
overlaps = inters / uni
ovmax = np.max(overlaps)
jmax = np.argmax(overlaps)
取最大的IoU
if ovmax > ovthresh: #是否大于阈值
if not R[‘difficult’][jmax]: #非difficult物体
if not R[‘det’][jmax]: #未被检测
tp[d] = 1.
R[‘det’][jmax] = 1 #标记已被检测
else:
fp[d] = 1.
else:
fp[d] = 1.
计算precision recall
fp = np.cumsum(fp)
tp = np.cumsum(tp)
rec = tp / float(npos)
avoid divide by zero in case the first detection matches a difficult
ground truth
prec = tp / np.maximum(tp + fp, np.finfo(np.float64).eps)
2 、这里最终得到一系列的precision 和recall 值,并且这些值是按照置信度降低排列统计的,可以认为是取不同的置信度阈值(或者rank 值)得到的。然后据此可以计算AP :
def voc_ap(rec, prec, use_07_metric=False):
“””Compute VOC AP given precision and recall. If use_07_metric is true, uses
the VOC 07 11-point method (default:False).
“””
if use_07_metric: #使用07年方法
11 个点
ap = 0.
for t in np.arange(0., 1.1, 0.1):
if np.sum(rec >= t) == 0:
p = 0
else:
p = np.max(prec[rec >= t]) #插值
ap = ap + p / 11.
else: #新方式,计算所有点
correct AP calculation
first append sentinel values at the end
mrec = np.concatenate(([0.], rec, [1.]))
mpre = np.concatenate(([0.], prec, [0.]))
compute the precision 曲线值(也用了插值)
for i in range(mpre.size – 1, 0, -1):
mpre[i – 1] = np.maximum(mpre[i – 1], mpre[i])
to calculate area under PR curve, look for points
where X axis (recall) changes value
i = np.where(mrec[1:] != mrec[:-1])[0]
and sum (\Delta recall) * prec
ap = np.sum((mrec[i + 1] – mrec[i]) * mpre[i + 1])
return ap
这个代码在任何一个目标检测的代码里应该都可以找到的,下面我们看下这个代码做了哪些事情:首先我们输入的序列是我们得到的:
rec:[0.0666,0.0666,0.1333,0.1333,0.1333,0.1333,0.1333,0.1333,0.1333,0.2,0.2,0.2666,0.3333 ,0.4,0.4,0.4,0.4,0.4,0.4,0.4,0.4,0.4,0.4666,0.4666],
然后是我们的pre :[1,0.5,0.6666,0.5,0.4,0.3333,0.2857,0.25,0.2222,0.3,0.2727,0.3333,0.3846,0.4285,0.4,0.375,0.3529, 0.3333,0.3157,0.3,0.2857,0.2727,0.3043,0.2916]。
代码里首先是判断是不是用11 点的方法,我们这里不用所以跳转到下面的代码:
mrec = np.concatenate(([0.], rec, [1.]))
mpre = np.concatenate(([0.], prec, [0.]))
那么这一步呢就是相当于把我们的recall 开放的区间给补上了,补成了闭合的区间。mpre 也是做了对应的补偿。
for i in range(mpre.size – 1, 0, -1):
mpre[i – 1] = np.maximum(mpre[i – 1], mpre[i])
那这一步呢就是在做我们上面说到的人为地把这个pre-rec 曲线变成单调递减的,我们这里可以看到他就是在做一个比较,就是后一项要是比前一项大的话那么就把这个大的值赋值给前一项。做完这一步后的pre 就变成了:[1. 1. 0.6666 0.6666 0.5 0.4285 0.4285 0.4285 0.4285 0.4285 0.4285 0.4285 0.4285 0.4285 0.4285 0.4 0.375 0.3529 0.3333 0.3157 0.3043 0.3043 0.3043 0.3043 0.2916 0. ]我们发现与之前的[0. 1. 0.5 0.6666 0.5 0.4 0.3333 0.2857 0.25 0.2222 0.3 0.2727 0.3333 0.3846 0.4285 0.4 0.375 0.3529 0.3333 0.3157 0.3 0.2857 0.2727 0.3043 0.2916 0. ]对比那些在0.4285 之前出现的但是比0.4285 小的数值都被替换成了0.4285.,相当于强行把这个曲线给填的鼓了起来。
做完这个操作后,我们就要按rec 区间去计算ap 了,准确来说是用rec 的区间长度乘以这个区间上的最大的pre (注意这里是处理后的pre )。代码实现起来就是:
i = np.where(mrec[1:] != mrec[:-1])[0]#获取rec区间变化的点
ap = np.sum((mrec[i + 1] – mrec[i]) * mpre[i + 1])#(mrec[i + 1] – mrec[i])这里得到rec区间的
长度,mpre[i + 1]这里是这个区间上对应的pre数值(处理后的)
结果是:
[0.0666 0.0667 0.0667 0.0666 0.0667 0.0667 0.0666 0.5334]和[1. 0.6666 0.4285 0.4285 0.4285 0.4285 0.3043 0. ]我们看一下首先是0.0666 他代表第一个rec0.0666 到0 的区间长度,然后呢这个区间上出现的最大的pre 是1 ,第二项0.0667 代表0.0666 到0.1333 的区间长度是0.0667 ,在rec 取0.1333 这段区间上最大额pre 是0.4285 (变化后的),后面的以此类推这块还有疑问的建议结合这上面的那个表和pre 处理后的序列看一下哈,。为啥pre 输出的最后一项是0 呢,是因为这段区间实际上recall 是没有达到过的我们最大的rec 也就只到了0.4666 就结束了。
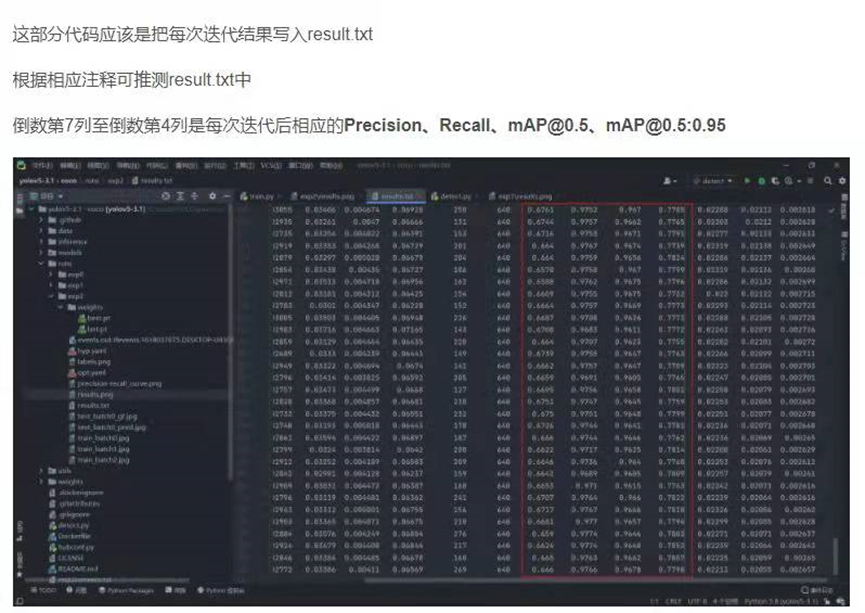
12 :results.txt
打印的训练结果信息 每一个epoch
这部分代码应该是把每次迭代结果写入result.txt
Write
with open(results_file, ‘a’) as f:
f.write(s + ‘%10.4g’ * 7 % results + ‘\n’) # P, R, mAP@.5, mAP@.5-.95, val_loss(box, obj, cls)
if len(opt.name) and opt.bucket:
os.system(‘gsutil cp %s gs://%s/results/results%s.txt’ % (results_file, opt.bucket, opt.name))
Original: https://blog.csdn.net/m0_54111890/article/details/123362039
Author: Wiseym
Title: yolov5 训练结果解析
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/646392/
转载文章受原作者版权保护。转载请注明原作者出处!