

- 一.目标
- 1.首页
- 2.网页源代码
- 二.爬取详情页
- 1.查看详情页
- 2.小说详情
- 3.小说简介
- 4.播放列表
- 三.爬取小说音频
- 1.确定数据加载方式
- 2.寻找真实音频播放地址
- 3.URL解码
- 4.加密方式
- 5.解密
- 四.代码思路
- 五.源代码
- 六.结果
- 1.详情页
- 2.音频播放地址
- 七.总结
看过我的在线小说播放器博文的朋友问我,能不能详细介绍一下小说播放链接的获取。本篇博文将要介绍解密有声小说反爬,重点在于获得小说真实播放地址。
一.目标
1.首页
这是一个可以在线播放有声小说的网站,通过选择书籍,选择剧集最后实现有声小说的在线收听。


2.网页源代码
通过查看网页源代码,发现此网站为静态网站,所有网页内容都能在源代码中找到。

(网页源代码)
二.爬取详情页
1.查看详情页
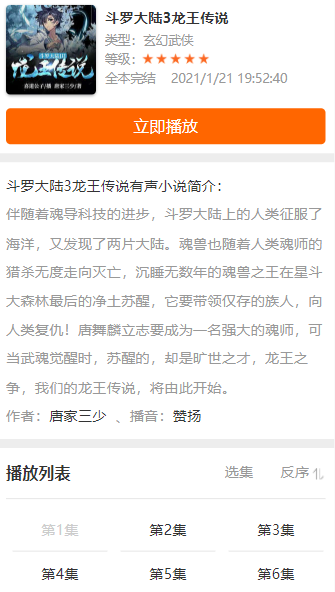
可以看到,网页从上到下大致分为三部分,小说详情,小说简介,播放列表。
2.小说详情
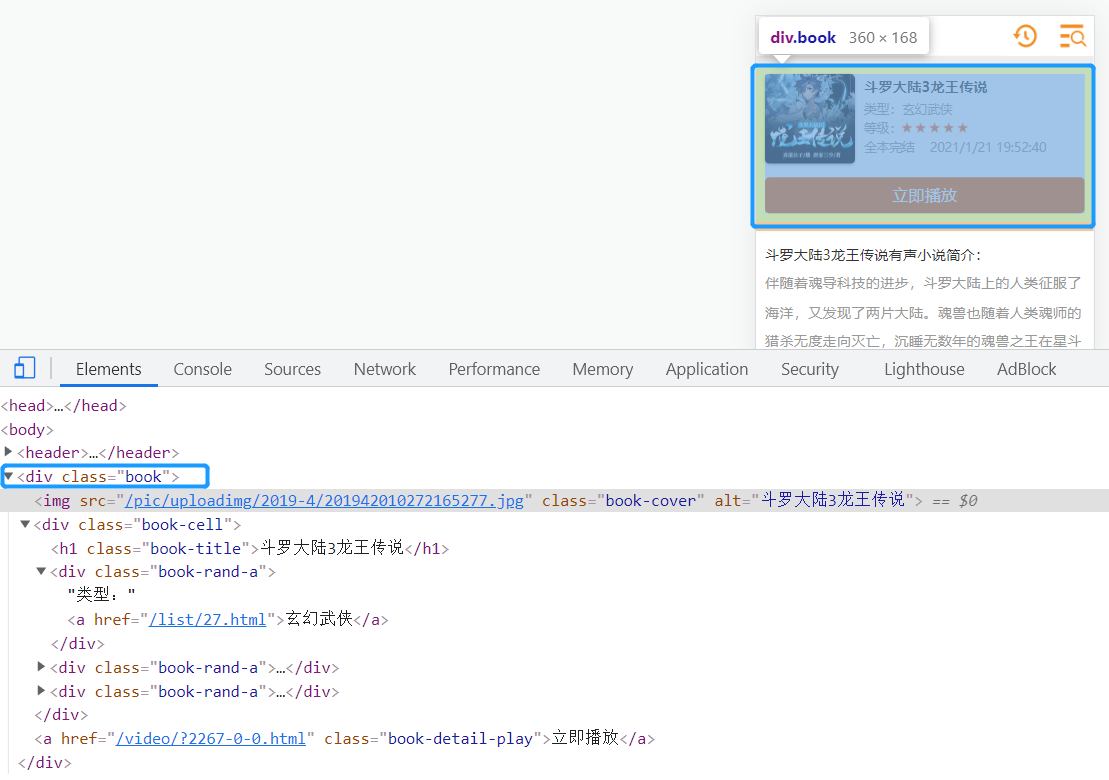
打开开发者工具,摁下键盘组合键Ctrl+Shift+M,使用鼠标点击小说详情确定元素所在html标签,可以确定,小说详情在第一个class为book的div标签里。在这个标签中能得到小说封面、名称、类型、等级、状态、更新时间。
3.小说简介
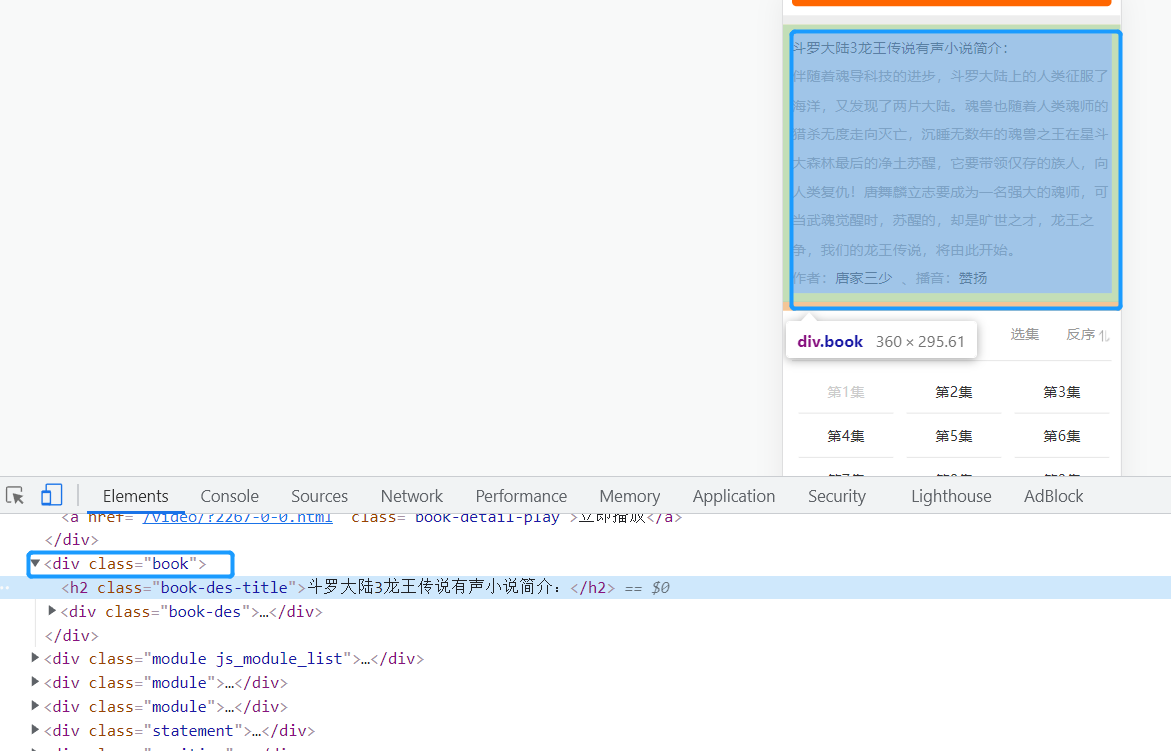
在第二个class为book的div标签中能得到小说简介、作者、播音。
4.播放列表

在id为playlist的div标签中,能得到小说的播放列表,每集小说都在对应的li标签中,li标签下的a标签中包含小说剧集和播放网页地址(并非真正音频地址)。
三.爬取小说音频
1.确定数据加载方式
随便点击一个剧集,网页就会跳转到音频播放页面。
使用Ctrl+U查看网页源代码,未发现类似.mp3、.m4a格式音频地址,此时可以确定真实音频地址被加密了,或者是通过单独的接口异步加载进入网页。
2.寻找真实音频播放地址
开发者模式别关,刷新网页,点击网页的播放键,开始播放音频,将开发者工具筛选从All(所有)改成Media(媒体)。
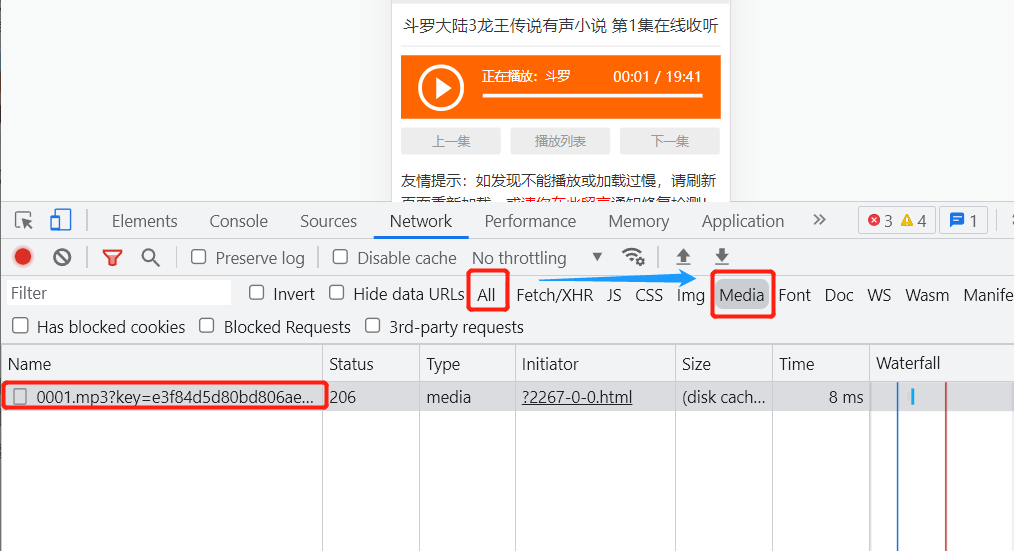
通过筛选,发现此音频真实播放地址为:
3.URL解码
上面的地址是什么哦,好乱啊,不要着急,这是URL编码,可以使用在线工具进行编码转换。
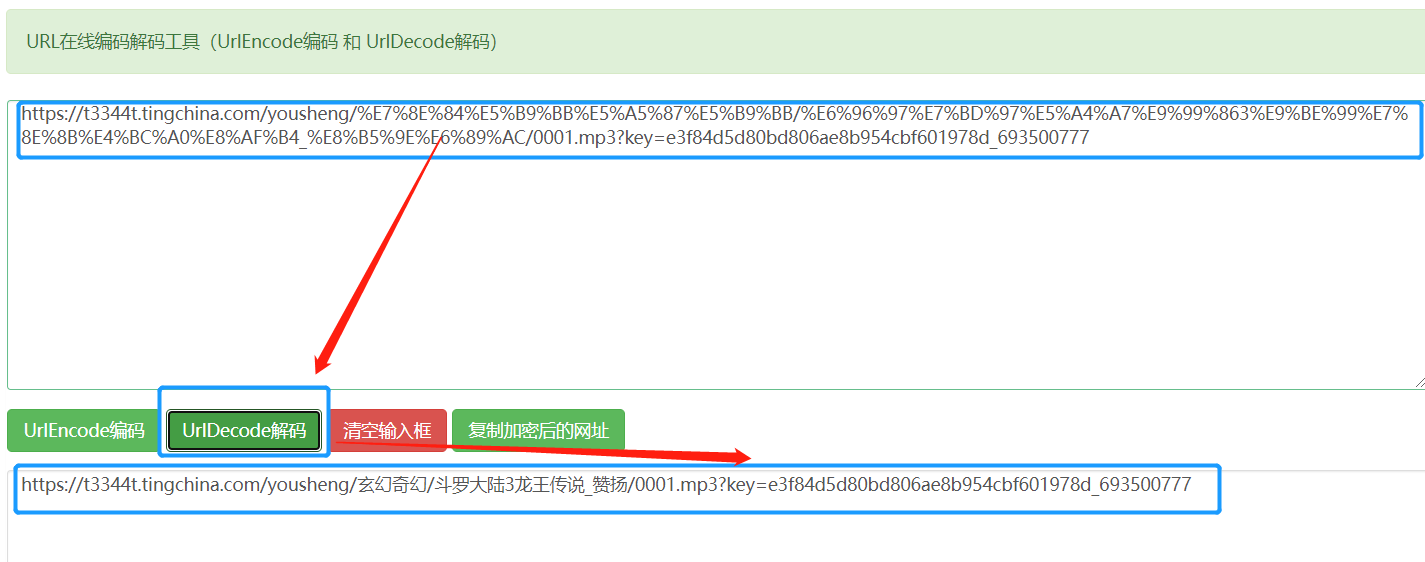
哦,原来网页将中文进行了编码转化。(我用的URL解码网站:http://www.jsons.cn/urlencode/)。
4.加密方式
回到网页源代码,下面这串Js吸引了我的注意。

于是去开发者工具中进行搜索函数名:FonHen_JieMa
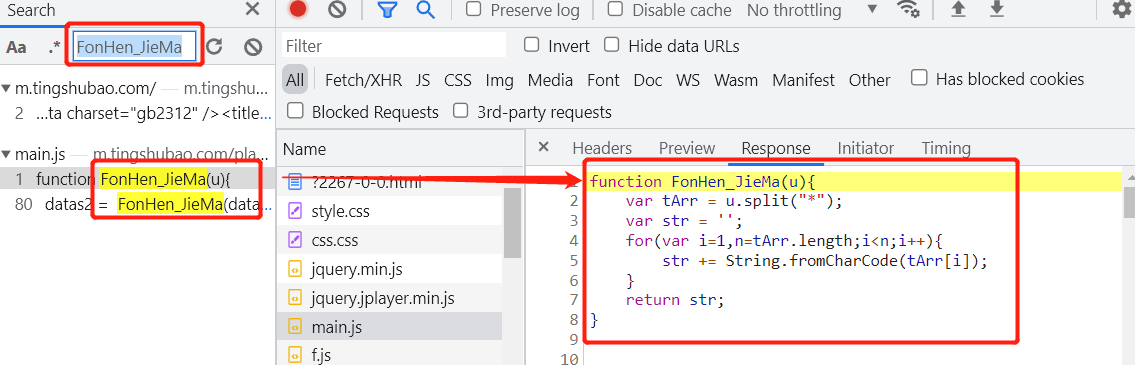
发现此函数先是将传入的参数进行了字符串切割,然后遍历切割后的数组,使用String.fromCharCode()函数进行处理后,返回结果。
因为对Js了解不多,特地查了一下:
JavaScript fromCharCode()方法:
将Unicode 编码转为一个字符
var n = String.fromCharCode(65);
输出结果:A
此函数会将一个ASCII(Unicode)编码转成字符。
5.解密
将加密字符以*为分隔符进行切割,得到:
['', '51', '48', '49', '51', '48', '47', '121', '111', '117', '115', '104', '101', '110', '103', '47', '29572', '24187', '22855', '24187', '47', '26007', '32599', '22823', '-27066', '51', '-24679', '29579', '20256', '-29708', '95', '-29346', '25196', '47', '48', '48', '48', '49', '46', '109', '112', '51', '38', '57', '53', '53', '38', '116', '99']
去除掉空字符串,将数字输入到ASCII编码转换网站上,进行验证。



验证了前三位,再随机选取几个有符号数输入进行验证:



这里解释一下,为什么会有”负数”,此负数为有符号数,需要转化成原码然后进行还原:
对应的Python代码为:
chr((int(~int(s.replace("-", '')) & 0xffff) + 1))
非有符号数可以直接使用
chr(int(s))
直接获取对应的 ASCII 字符。
原码,补码和反码的知识可以参考:
四.代码思路
针对加密参数,提出我的撰写代码思路。

五.源代码
Tingshubao_Spider.py
import requests
import re
from urllib.parse import urljoin
import urllib3
from lxml import etree
urllib3.disable_warnings()#解决warning
class Tingshu_bao_spider:
def do_get_request(self,url):
"""
发送网络请求,获取网页源代码
:param url:
:return:
"""
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36",
"Referer":url}
try:
r=requests.get(url,headers=headers,timeout=6)
if r.status_code==200:
r.encoding=r.apparent_encoding
html=r.text
return html
else:
return False
except:
return False
def get_novel_detail(self,sound_link):
"""
获取小说详情
:param sound_link:
:return:
"""
novel_detail_item={}
html=self.do_get_request(sound_link)
if html:
res=etree.HTML(html)
name=res.xpath('//div[@class="book-cell"]/h1[@class="book-title"]/text()')
if name:
novel_detail_item['novel_name']=name[0].split("有声小说简介:")[0]
else:
novel_detail_item['novel_name']="未知"
cover=res.xpath('//div[@class="book"]/img[@class="book-cover"]/@src')
if cover:
novel_detail_item['novel_cover']=urljoin(sound_link,cover[0])
else:
novel_detail_item['novel_cover']="未知"
datas=res.xpath('//div[@class="book-rand-a"]//text()')
if datas:
novel_detail_item['novel_type'] = datas[1]
novel_detail_item['novel_status'] = datas[3]
novel_detail_item['novel_update_time'] = datas[-1]
else:
novel_detail_item['novel_type']="未知"
novel_detail_item['novel_status'] = "未知"
novel_detail_item['novel_update_time'] = "未知"
#作者
data2 = res.xpath('//div[@class="book-des"]/p/a/text()')
if data2:
novel_detail_item['novel_author'] = data2[0]
novel_detail_item['novel_anchor'] = data2[-1]
else:
novel_detail_item['novel_author']="未知"
novel_detail_item['novel_anchor']="未知"
introduce = res.xpath('//div[@class="book-des"]/text()')
if introduce:
novel_detail_item['novel_introduce'] = introduce[0]
else:
novel_detail_item['novel_introduce']="未知"
selector=res.xpath('//div[@id="playlist"]/ul/li')
play_list=[]
for data in selector:
play_item={}
novel_play_name=data.xpath("./a/@title")
if novel_play_name:
play_item["play_name"]=novel_play_name[0]
else:
play_item["play_name"]="NULL"
novel_play_link = data.xpath("./a/@href")
if novel_play_name:
play_item["play_link"] = urljoin(sound_link,novel_play_link[0])
else:
play_item["play_link"]="NULL"
play_list.append(play_item)
novel_detail_item['play_list']=play_list
return novel_detail_item
else:
return False
def get_audio_play_link(self,detail_intro_link):
"""
获取小说播放链接地址
:param detail_intro_link:
:return:
"""
html=self.do_get_request(detail_intro_link)
if html:
base_url="https://t3344t.tingchina.com/"
aim_asciis=re.findall("FonHen_JieMa\('(.*?)'",html)
if aim_asciis:
sp = aim_asciis[0].split("*")
res = ""
for s in sp:
if s != "":
if "-" in s:
res += chr((int(~int(s.replace("-", '')) & 0xffff) + 1))
else:
res += chr(int(s))
aim_suffix = "/" + res.split('&')[0].split('/', 1)[-1]
play_url=urljoin(base_url,aim_suffix)
return play_url
else:
return False
else:
return False
if __name__ == '__main__':
t=Tingshu_bao_spider()
aim_url='http://m.tingshubao.com/book/2267.html'
print(t.get_novel_detail(aim_url))
print(t.get_audio_play_link('http://m.tingshubao.com/video/?2267-0-0.html'))
六.结果
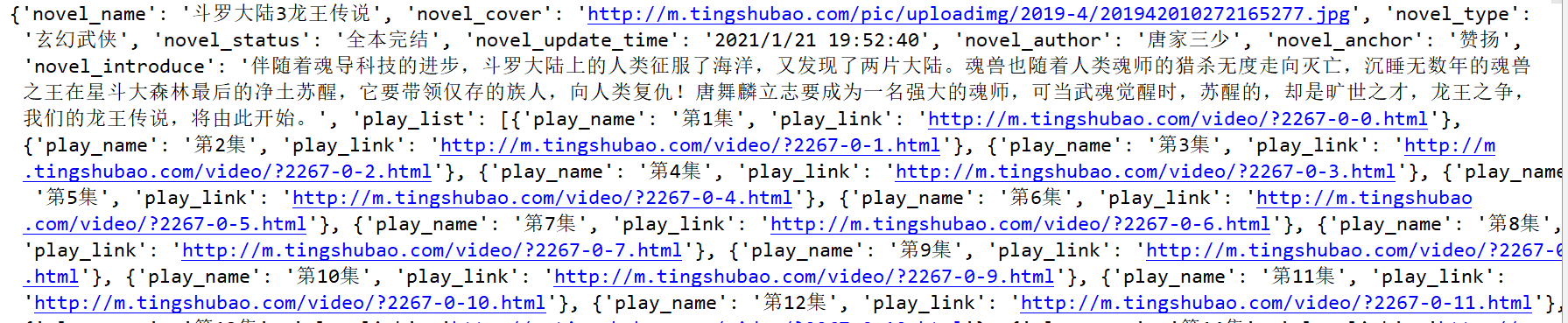
1.详情页
2.音频播放地址

有了真实播放地址,就能写代码,下载音频了。
七.总结
本次分析了一个有声小说网站,重点在于分析其小说详情页、音频播放地址,加密方式判断。思路、代码方面有什么不足欢迎各位大佬指正、批评!

Original: https://www.cnblogs.com/a1397852386/p/15729824.html
Author: 懷淰メ
Title: Python3网络爬虫–爬取有声小说(附源码)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/643580/
转载文章受原作者版权保护。转载请注明原作者出处!