

https://arxiv.org/pdf/2111.06377.pdf
构建自编码器,对mask的图片进行重建
先看效果
左:mask的图片
中:重建的图片
右:ground truth


摘要
这篇文章展示masked autoencoder(MAE)是CV中可扩展的自监督学习器。
MAE的方法很简单:随机mask输入图片的一些块,然后重建这些缺失像素。
基于两个核心设计:
- 开发了一个非对称encoder-decoder结构。encoder只对可见块子集进行处理(不使用mask token),一个轻量级decoder使用隐表示和mask token对原图片进行重建。
- 将图片很大比例进行mask(例如75%),会变成一个有意义的自监督任务。
结合这两个设计,可以高效且有效地训练更大的模型:加速训练(3x 或更多)并提升了准确性。
本可扩展方法可以学习大容量模型并能更好地泛化。下游任务的迁移性能优于有监督的预训练,并显示出非常好的扩展行为。
介绍
在NLP中,使用自监督预训练模型取得了很多成功。例如使用自回归的GPT和masked autoencoding的BERT。他们的思想都很简单:移除一部分数据,然后学习去预测这部分被移除的内容。
作者认为需要考虑:视觉和语言中的masked autoencoding到底有什么区别。
尝试从以下观点进行考虑:
- 架构不同。视觉中,主要采用了卷积网络,卷积通常在网格级处理,不包含mask token和位置编码。这种架构隔阂,已经由Vision Transformers (ViT)解决,不再是阻碍。
- 视觉和语言的信息密度不同。语言是人类生成的信号,有很高的语义和信息密度。当训练一个模型仅仅对每句话预测少量丢失单词时,任务可以转化成复杂的语言理解问题。相反,图片是有着很多空间冗余的自然信号(一个缺失的块可以由周围的块进行恢复,周围的块包含目标、场景等高级信息)。为了克服这种区别、鼓励学习有用特征。作者展示了一个CV的简单策略:随机mask了很大比例的块。这个策略很大程度上减少了冗余,为自监督任务提升了难度,超越了低级别图像统计的理解范畴。
- 自编码器的decoder,将隐表示映射回输入,这在重建文本和图像中有所不同。在视觉中,decoder重建像素,因此decoder的得到是一个相比于目标识别任务更低语义级别的输出。这与语言不同,语言中预测的缺失单词包含了丰富的语义特征。尽管在BERT中,decoder可以很简单(一个MLP),但对于图片,decoder在决定学习隐表示的语义级别时起关键作用。
方法
Masked autoencoder(MAE)是一种自编码方法,给定原始信号的部分观测,然后对原始信号进行重建。
和其他自编码器方法类似,本文的方法中:一个encoder将一个观测信号映射为隐表示,一个decoder使用隐表示对原始信号进行重建
与传统自编码器不同,采用了非对称设计,允许encoder只处理部分、观测到的信号,一个轻量级decoder以隐表示和mask token进行重建。如图
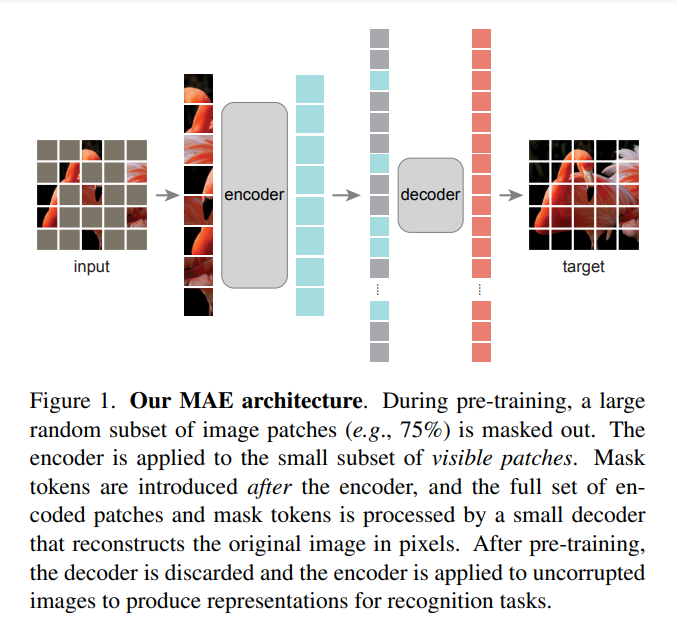
Masking
参考 ViT,将图像分成规则的非重叠块。然后采样得到块的一个子集,然后mask掉剩下部分。
采样策略比较直接:采用均匀分布,不放回随机采样。称之为”随机抽样”
使用高mask率的随机采样大幅消灭冗余性。因此可以得到一个任务,在这里,不能轻易地通过从可见邻块进行推断。
均匀分布防止了潜在的中心偏差(更多在中心附近的块被mask)
最终,得到了高度稀疏的输入,可以设计更有效的encoder
MAE encoder
encoder参考ViT,但是只应用于可见的、未被mask的块。和标准ViT一样,encoder使用线性投影和位置编码得到patch的embedding。然后通过一系列Transformer block处理结果集合。
然后,encoder只对(25%左右)的小子集进行处理。masked块被移除,没有使用mask token。这帮助在训练巨大encoder的时候只占用更小的计算量和内存。
MAE decoder
MAE decoder的输入是token的整个集合,包含了:
- 编码后的可见块
- mask token
每个mask token是一个可学习的共享变量,表示预测缺失块的存在性.
对全体集合的所有token添加位置编码。如果没有位置编码,mask token就会缺失在图片中的位置信息。
decoder也有另外一系列的Transformer block
MAE decoder只在用于图像重建任务的预训练时候使用。(Encoder用来在识别中提供图像表示)
因此,decoder的结构在设计时可以与encoder进行独立,并且可以灵活设计。
作者实验了很小的decoder,比encoder更窄更浅。例如,与encoder相比,默认decoder在每个token上计算量小于10%。
使用这种非对称设计,token的完整集合只由轻量decoder进行处理,减少了预训练时间
重建目标
MAE通过对每个mask块预测像素值,来重建输入。
decoder输出的每个元素是表示预测块的像素值的向量。
decoder的最后一层是一个线性投影,输出通道的数量等于块像素值的数量。对decoder输出进行reshape,得到一个重建图片。
采用MSE作为损失函数,计算重建图片和原始图片在像素空间的误差。
与BERT类似,只对mask的块中计算loss。
作者还研究了一个变种方法:重建目标是对每个mask块的normalized像素值。对每个块,计算了所有像素的均值和方差,然后用来对块进行normalize。实验中,使用标准化像素作为重建目标提升了表示质量。
简单实现
MAE预训练可以有效进行实现,无需特别稀疏操作。
首先,对每个输入块生成一个token(使用线性投影加位置编码)
然后随机shuffle了token列表,根据mask率,移除了列表的后面部分。这与不放回抽样等价,等到了所有token的一个小子集。
编码后,在encoded块列表后面添加mask token的列表,unshuffle这个完整列表,对齐所有token和目标
decoder应用这个完整列表(其中包含位置编码)。
无需稀疏操作,其中的操作例如shuffle和unshuffle很快。
总结
个人认为,作者主要采用大力出奇迹的方法。认为图像中存在大量的冗余信息,这样可以只需要很小一部分就能提取出合适的语义。
Original: https://www.cnblogs.com/antelx/p/15545878.html
Author: Antel
Title: Masked Autoencoders Are Scalable Vision Learners
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/643309/
转载文章受原作者版权保护。转载请注明原作者出处!