

记录了近期专题练习的所有 27 道题目的完整题解。题单见 链接。
2022.4.26 计数专题
自然设 (f_i) 表示一条有向路径的数量,考虑若干种情况。
- 不经过根,(2f_{i – 1})。
- 恰好以根为一端,(4f_{i – 1})。
- 完全跨过根的两个子树,(2f_{i – 1} ^ 2)。
- 根,(1)。
- 完全跨过根但在一个子树内。设 (g_i) 表示两条不交的有向路径的数量,(2g_i)。
[f_i = 6f_{i – 1} + 2f_{i – 1} ^ 2 + 1 + 2g_i ]
考虑算 (g_i),发现当一条路径经过根又回到其子树,且另一条路径也在相同子树时,又要用到三条不交有向路径的方案数。
这样下去不行,结合 (n\leq 400) 的数据范围,我们再记录一维表示路径条数。
设 (f_{i, j}) 表示 (i) 树 (j) 条有向路径的方案数,转移枚举 (j, k) 表示左子树和右子树的原路径条数。
- 不经过根,(f_{i – 1, j} \times f_{i – 1, k} \to f_{i, j + k})。
- 以根为一个端点,共有 (2(j + k)) 个端点可以与根相接,(f_{i – 1, j} \times f_{i – 1, k} \times 2(j + k) \to f_{i, j + k})。
- 不同子树的两条路径通过根合并成一条,枚举左子树和右子树的一个出点和一个入点,(f_{i – 1, j} \times f_{i – 1, k} \times 2jk \to f_{i, j + k – 1})。
- 相同子树的两条路径通过根合并成一条,枚举左子树还是右子树,然后从中选择一个入点和一个出点(减掉成环的情况),(f_{i – 1, j} \times f_{i – 1, k} \times (j(j – 1) + k(k – 1)) \to f_{i, j + k – 1})。
- 新增根单点,(f_{i – 1, j} \times f_{i – 1, k} \to f_{i, j + k + 1})。
由于 (i) 每次加 (1) 最多只会湮灭掉一条路径,所以路径条数这一维只需要开到 (n – i + 1)。
答案即 (f_{n, 1}),时间复杂度 (\mathcal{O}(n ^ 3))。
代码。
考虑一次操作的本质。
若为 (00),(10) 或 (01) 则 (0) 的个数减 (1),否则 (1) 的个数减 (1)。
直接对操作序列计数难以去重,因此一般均考虑对最终得到的 (01) 串计数。
我们发现每次操作可以减少相邻两个 (1) 之间的 (0) 的个数,或直接删掉下标相邻的两个 (1) 之间用于填放 (0) 的空隙,于是尝试设相邻两个 (1) 之间 (0) 的个数序列为 (a),注意开头和结尾的连续若干个 (0) 也要算上。举例,若 (s = \texttt {001011001}),则 (a = {2, 1, 0, 2, 0})。
显然,一个 (a) 和一个 (01) 串一对应。因此考虑对 (a) 序列计数。
设原 (01) 串相对应的序列为 (b)。尝试探究 (a) 能被 (b) 生成的充要条件。
这个有点困难,我们先观察一次操作对 (b) 的影响,再反推条件。显然,每次操作可以将 (b) 的某个不为 (0) 的数减 (1),或者删掉 不在开头或结尾 的 (0)。
发现 (a) 的两端元素的取值相对独立,因为在操作过程中它们一直不会被删去(换言之, 直接删去某个数是导致重复的罪魁祸首。若不可以删去数,答案显然为 (\prod\limits_{i = 1} ^ {|b|} (b_i + 1)))。根据乘法原理,答案首先乘上 (a_1) 和 (a_{|a|}) 的取值范围,即 ((b_1 + 1)(b_{|b|} + 1))。接下来忽略掉 (a) 的两端和 (b) 的两端。
根据操作的具体内容,不难得到 (a) 被 (b) 生成的充要条件:存在序列 (i) 满足 (1 \leq i_1 < \cdots < i_{|a|} \leq |b|),使得 (a_j \leq b_{i_j}(1\leq j \leq |a|))。
容易判定 (a) 被 (b) 生成,形如子序列自动机。记录指针 (p) 表示当前 (b) 匹配到的位置,初始值为 (0)。贪心找到大于 (p) 的最小的位置 (q) 使得当前 (a) 匹配到的位置 (a_j \leq b_q),令 (j) 加 (1) 且 (p \gets q)。重复该过程直到 (j > |a|)(成功)或 (q) 不存在(失败)。
根据判定过程就可以 DP 了。设 (f_i) 表示匹配到 (b_i) 的序列 (a) 的个数。(a) 的长度不影响转移,所以无需记录。
两种转移方法,一是枚举下一个 (a) 值是什么,并匹配到相应位置 (j(i < j)),(f_i) 贡献给 (f_j),但这样太劣了。直接考虑 (f_i) 对 (f_j(i < j)) 的贡献系数,不难发现,当 (a) 值小于等于 (b_{i + 1} \sim b_{j – 1}) 当中任何一个数时,匹配在 (j) 之前停止。因此贡献系数为 (\max\left(0, b_j – \max\limits_{p = i + 1} ^ {j – 1} b_p\right))。
因为贡献系数主要与 (j) 有关,从 (i) 转移过去的角度考虑不方便。转换角度,(j) 受到 (i) 的贡献。
有 (i, j) 之间的最大值,容易想到单调栈。维护从左(栈底)到右(栈顶)递减的单调栈,那么当前栈中存储的所有元素即可以影响到 (\max\limits_{p = i + 1} ^ {j – 1} b_p) 的 (b_1 \sim b_{j – 1}) 的 后缀最大值(p_1 < \cdots < p_c)。
我们发现,对于 (i\in [p_{k – 1}, p_k)),它们对 (f_j) 的贡献系数都是 (b_{p_k})。而对于 (\geq b_j) 的 (p_k),(p_k) 左边的元素显然无法贡献至 (f_j)。而弹栈时只会弹出 (\leq b_j) 的栈顶,因此直接在弹栈的时候计算贡献即可。
需要使用前缀和优化求出一段区间的 (f) 值之和。时间复杂度线性。
代码。
考虑一个朴素算法,根据期望的线性性,对每个 (a_i) 和 (i \in [1, k]),枚举它在此之前被选中的情况 (msk \in [0, 2 ^ {i – 1}])。继而算出它现在的值,乘以概率 (\dfrac 1 {n ^ {1 + \mathrm{popcount}(msk)}})。时间复杂度 (\mathcal{O}(n k2 ^ k))。
首先,我们的复杂度关于 (n) 只能是线性。因此我们尝试在值域上做点文章。
一个数被减掉的数值是很少的,但这并不意味着我们可以将所有数划分为很少个等价类。具体地,这个等价类的最小大小是 (1\sim k – 1) 的最小公倍数 (P = 720720)(不包含 (k) 因为不需要知道最后一次减掉的是多少)。
也就是说,对于 (a_i),它的具体值不重要。我们只关心它模 (P) 之后的值,这是因为对于前 (k – 1) 次操作而言, 任何数模(P) 的值只会减小,不会增大,而 (P\lfloor \frac{a_i}{P} \rfloor) 这一部分的贡献容易计算。
基于以上推理我们尝试设计 DP。设 (f_{i, j}) 表示进行 (i) 轮后模 (P) 等于 (j) 的数的个数的期望值。转移是非常容易的。
对于 (f_{i, j}) 而言,若 (j) 被选择则以 (\dfrac 1 n) 的系数(概率)转移到 (f_{i + 1, j – (j \mod (i + 1))}),否则以 (1 – \dfrac 1 n) 的系数转移到 (f_{i + 1, j})。
算答案也很容易,即 (\dfrac{\sum\limits_{i, j} f_{i, j} j} n),再加上 (P\lfloor \frac {a_i} P \rfloor) 这部分的贡献 (\dfrac{\sum\limits_{i = 1} ^ n {P\lfloor \frac {a_i} P\rfloor}} n),最后乘以 (n ^ k)。
时间复杂度 (\mathcal{O}(k \times \mathrm{lcm}(1\sim (k – 1)))。
代码。
考虑对于确定的 (s, t) 如何求解最小移动步数。
使用经典套路,将所有偶数位或奇数位的值异或 (1),操作转化为交换相邻的 (0) 和 (1)(本题最核心的地方就在于对操作的转化,剩下来就不难想了)。
若转化后 (s, t) 中 (01) 个数不等,无解。否则最小移动步数即 (s, t) 对应 (1) 下标之差的和。
那么就简单了。应用在每个间隔处统计答案的技巧,设 (f_{i, j}) 表示考虑前缀 (i),当前 (s) 中 (1) 的个数比 (t) 中 (1) 的个数多 (j) 的方案数,(g_{i, j}) 表示所有这样的方案的答案之和。
(f_{i, j}) 转移枚举 (s) 和 (t) 下一位为 (0) 或 (1) 转移到 (f_{i + 1, j – 1 / j / j + 1})。
(g_{i, j}) 转移同理,加上 (f_{i, j}|j|) 作为贡献,因为我们在每个间隔((i\to i + 1) 的过程)处统计答案。
时间复杂度平方。
代码。
非常典的套路。
设 (f_{i, j}) 表示到关键点 (i) 恰好 经过 (j) 个关键点的方案数。
关键点要以 (x) 为第一关键字,(y) 为第二关键字排序,保证后面的关键点不会转移到前面的关键点,即无后效性。
朴素想法是直接 (f_{i, j} = \sum\limits_{k = 0} ^ {i – 1} f_{k, j – 1} p(k, i)),其中 (p(k, i)) 是关键点 (k) 到关键点 (i) 的方案数,可以组合数 (\mathcal{O}(1)) 计算。但是这样显然会算重,因为我们无法保证 (k\to i) 的路径上不经过其它关键点。
问题不大。注意到任何一条以 (k, i) 之间某个点 (q(q\neq k\land q\neq i)) 作为下一个关键点的路径均会被算到 (f_{q, j + 1}) 里面去,所以我们只需用不限制其它关键点时 (k) 作为路径上第 (j) 个关键点到 (i) 的方案数,减去不限制其它关键点时 (k) 作为路径上第 (j + 1) 个关键点到 (i) 的方案数。
我们通过 差分容斥,得到转移 (f_{i, j} = \sum\limits_{k = 0} ^ {i – 1} (f_{k, j – 1} – f_{k, j}) \times p(k, i))。
第二维显然只需开到 (\log_2 s) 大小。剩下来的方案数可以用总方案数减去经过关键点个数 (\leq \log_2 s) 的方案数。时间复杂度 (\mathcal{O}(k ^ 2\log s))。
代码。
定义一棵 有向树 是好树当且仅当它的最长链长为 (n),每个点的出度 + 入度 (\leq 3) 且对于树上任意两点,存在一个点使得该点与这两个点具有祖先后代关系。求好树的个数模 (998244353)。(1\leq n\leq 10 ^ 6)。
考虑限制的等价描述。
前两个条件很直白,我们尝试翻译第三个条件。一个直观的想法是好树必须是内向树(根向树)或外向树(叶向树),也就是整棵树必须找到一个 “根”,使得任何一个点都与该节点具有祖先后代关系。
一棵内向树在改变其所有边方向后可以得到一棵外向树,对于外向树同理。因此,内向树和外向树一一对应。这意味着我们只需对外向树计数。
- 一条链既可以是内向树,也可以是外向树。因此最后的答案乘(2) 后要减(1)。
设 (f_i) 表示当 (n = i) 时的答案,尝试递推答案。
我们枚举根的度数,根据限制 2,它只有可能向外伸出 (1, 2) 或 (3) 条边。
- 对于伸出一条边,方案数即 (f_{i – 1}),因为任何一棵这样的树都是由一条边接上最长链长为 (n – 1) 的好树得到(这里有些问题,接下来会讲)。
- 对于伸出两条边,方案数即 (\dfrac {f_{i – 1}(f_{i – 1} + 1)} 2),原因同上。注意子树之间无序,所以是 (\dbinom {f_{i – 1} + 1} 2)。 等等,我们只要保证 至少 有一条链长为 (n),所以接上来的两棵子树并不需要都有长为 (n – 1) 的链。对于形如 至少 的限制一般考虑 容斥,用 所有 的方案数减去 全都不 的方案数。 因此,设 (s) 为 (f) 的前缀和,则方案数应为 (\dbinom{s_{i – 1} + 1} 2 – \dbinom{s_{i – 2} + 1} 2)。
- 对于伸出三条边,同理,方案数为 (\dbinom {s_{i – 1} + 2} 3 – \dbinom{s_{i – 2} + 2} 3)((n) 个无标号的球放进 (m) 个有标号盒子里,允许多个球放入相同盒子,方案数为 (\dbinom{m + n – 1} n),经典插板法)。
等等,是不是有些问题?接上一棵最长链长 (n – 1) 的好树时,好像出现了度数为 (4) 的点,因为 (f_{i – 1}) 中包含度数为 (3) 的根,再接上一条边求不符合限制 2 了。
因此,直接忽略掉伸出三条边的情况,即我们钦定根节点只能伸出一条边或两条边,则根据上述分析,转移方程为
[f_i = f_{i – 1} + \dbinom{s_{i – 1} + 1} 2 – \dbinom{s_{i – 2} + 1} 2 ]
答案即 (f_n),再加上伸出去三条边的情况 (\dbinom{s_{n – 1} + 2} 3 – \dbinom{s_{n – 2} + 2} 3)。
如果你这么写,会发现过不了样例 3。样例这么大,怎么调啊?对不起 yyl,我们错怪你了,原来你是对的(大雾)。
既然外向树计数没有问题,自然是限制 3 的转化出了点差错。仔细想想,似乎内向树和外向树并不是 “存在节点使得任何一个节点都与该节点具有祖先后代关系” 的等价条件。还有一种可能,那就是内向树和外向树拼起来,它们有同一个根。或者说,一个内向树和一棵外向树通过一条有向链拼接在一起。
直接枚举拼接的这条有向链长度 (L)。为了防止重复计数,树根的度数必须为 2,即树根不能向下延伸链,否则会和有向链拼成一个更长的链。所以 (L) 必须是正数,否则拼接处的节点度数等于 (4)。
设 (g_i) 表示强制树根度数为 (2) 的 (i) 好树内向树个数,根据上述分析显然
[g_i = \dbinom{s_{i – 1} + 1} 2 – \dbinom{s_{i – 2} + 1} 2 ]
则答案还要加上 (\sum\limits_{L = 1} ^ {n – 2}\sum\limits_{i = 1} ^ {n – L – 1} g_i g_{n – L – i})。容易前缀和优化做到线性时间复杂度。
代码。
初步想法:每个连通块独立,对每个连通块求出 012 是否出现过的对应方案数,DP 合并。则 (f_{{0, 1, 2}}) 即为所求。
问题转化为求一个连通块对应状态的对应方案数。问题看起来很不可 (\rm polylog)。注意到 (n \leq 40),考虑 meet-in-the-middle。
我们发现就算进行了上述转化,问题仍然很复杂,考虑继续简化。
单点 (S) 先忽略掉,最后答案乘上 (2 ^ {|S|})。
对于连通块 (G),若存在两个点标号不同,那么必然存在 1 边。因此,把 1 的限制忽略掉,最终求出来出现 02 的答案 (res),减掉出现 02 但不出现 1 的方案数即是答案,后者等于不出现 1 的总方案减掉只出现 0 或只出现 2 的方案。由于不存在单点,且一个连通块有两种不出现 1 的方案(点标全 0 或点标全 1),答案即 (res – (2 ^ {cnt} – 2)),其中 (cnt) 是连通块数量。
根据容斥原理,只要我们求出至少存在 0,至少存在 2 和至少存在 02 的方案数,就可以求出恰好存在 0,恰好存在 2 和恰好存在 02 的方案数。
非二分图必然存在 0 或 2,否则存在两种 01 染色方案使得不存在 0 或 2。因此,对于至少存在 02 的方案数,即 (2 ^ {|G|} – 2[\mathrm{bipartite}(G)])。
至少存在 0 和至少存在 2 是等价的,点标取反易证一一对应。所以直接求至少含有 2 的标号方案,记为 (cnt)。
将点集 (V) 分成两半 (X, Y),枚举 (X) 的所有标号情况。若 (X) 内部含 2 边,则答案加上 (2 ^ {|Y|}),否则答案加上 (Y) 含 2 或 (XY) 之间含 2 的 (Y) 的数量。容斥一下即 (2 ^ {|Y|}) 减去 (XY) 之间不含 2 且 (Y) 内部不含 2 的 (Y) 数量。
(XY) 之间不含 2 的限制形如 (Y) 的某些节点只能取 0,即等于 1 的节点属于某个特定的集合 (Z),(Z) 是 (Y) 所有不与 (X) 的等于 1 的节点相邻的节点,(Z) 容易在枚举 (X) 时直接算出。限制形如高维前缀和。
对此,枚举 (Y) 的所有标号情况。若 (Y) 内部不含 2,则令 (f_{Y_1}) 加上 (1),其中 (Y_1) 是 (Y) 标号为 1 的点集。那么枚举 (X) 的所有标号情况时,算出对应的 (Z),则 (XY) 之间不含 2 且 (Y) 内部不含 2 的 (Y) 的数量即 (f_Z)。
时间复杂度 (\mathcal{O}(n2 ^ {n / 2})),注意特判 (m = 0)。
代码。
这题真的只有 2900 吗?
排列太复杂,先分析对于固定的删边顺序,每个点 (x) 留下的概率。给边标号,设第 (i) 条边被删去的次序为 (p_i)。
容易发现,包含 (x) 的连通块每次 “扩张”,都会让 (x) 留下的概率减半。连通块扩张意味着扩展的这条边 (e) 在 (e) 与 (x) 之间所有边被删去之后才删去,即 (p_e) 大于 (e) 与 (x) 之间所有边。
自然考虑以 (x) 为根求解节点 (x) 的答案。由于每条边 (e = (u, v)(u = fa(v))) 的子节点 (v) 互不相同,所以把边权 (p_e) 赋给它的子节点 (v)。
答案即 (\dfrac {1}{2 ^ c}),其中 (c) 为使得 (x) 与节点 (u) 之间所有点的点权均不大于 (p_u)(注意此时我们仍在 (p) 固定的情况下讨论)的 (u) 的个数。
接下来尝试解决原问题。
由于若干子树相对独立,考虑 DP。笔者一开始设 (f_{i, j}) 表示以 (i) 为根的子树,这样的点有 (j) 个的方案数(因为概率和符合条件的点的个数相关)。但是这样无法封闭转移。因为当 (i) 的权值为 (v) 时,子树内原本可能符合条件但点权 (< v) 的节点就寄了。
因此我们还需记录一维 (k) 表示仅考虑点权 (> k) 的节点时,符合条件的节点个数。注意不等价于仅考虑点权 (> k) 且符合条件的节点。
对于确定的 (i, j, k),转移自然考虑枚举 (i) 的点权 (v)。这样,(i) 的每个儿子子树内部权值 (< v) 的节点个数 (w_u) 之和必须等于 (v – 1),而符合条件的节点个数 (c_u) 之和必须等于 (j – [v > k]),因为 (v > k) 时节点 (i) 会对总数产生 (1) 的贡献,否则不会。
注意到子树内 (< v) 的节点是不合法的(因为 (i) 的点权是 (v)),所以 对于(u) 子树的点权顺序而言,我们仅考虑点权 (> w_u) 的节点。因此,(f_{i, j, k}) 有转移式
[f_{i, j, k} = \sum\limits_{v = 1} ^ {sz_i} \sum\limits_{\sum w_u = v – 1} \sum\limits_{\sum c_u = j – [v > k]} \dbinom {\sum w_u}{w_{u_1}, \cdots, w_{u_{|\mathrm{son}(i)|}}} \prod\limits_{u \in \mathrm{son}(i)} f_{u, c_u, w_u} ]
中间那个是合并两个排列的多重组合数。
等等,好像有些问题。
当 (v \leq k) 的时候,(v) 本身都不被考虑,对 (\sum w_u) 的限制自然就不存在了。换言之,当 (v\leq k) 的时候,对子树节点权值的限制变成了 (\leq k) 本身的限制,而不是 (i) 的点权 (v) 的限制。
因此,转移式中的 (\sum w_u = v – 1) 应改为 (\sum w_u = \max(k – 1, v – 1))。(k) 也要减去 (1) 的原因是 (v) 包含在 (\leq k) 的部分,所以剩下来 (\leq k) 的权值个数为 (k – 1),即儿子子树占用 (k – 1) 个 (\leq k) 的权值。
(w) 和 (c) 的限制均为背包形式。这部分直接做。
显然,我们不需要每枚举一个 (v) 就做一次背包,这样太浪费时间。在枚举 (j, k, v) 之前先做好儿子的背包,枚举时就可以 (\mathcal{O}(1)) 求点值。
答案即 (\dfrac{\sum\limits_{j = 0} ^ {n – 1} f_{x, j, 0} \times \dfrac{1} {2 ^ j}}{(n – 1)!})。注意对于根节点 (x) 不需要再枚举其权值(因为根本不存在啊),(f_{x, j, 0}) 即子树背包得到的 (g_{j, 0}),第一维是 (\sum c_u),第二维是 (\sum w_u)。
求每个点的答案都需要进行一次树形 DP,而一次 DP 的复杂度为 (\mathcal{O}(n ^ 4))((i, j, k, v) 四维,以及树形背包每一维 (n ^ 2) 共两维),所以时间复杂度 (\mathcal{O}(n ^ 5))。
应该可以通过?浮点数运算还是挺耗时间的。
考虑优化。(j) 这一维其实没啥用,直接把它乘到结果里面去,即设 (f_{i, k}) 表示以 (i) 为根的子树仅考虑权值 (\geq k) 时,所有 (sz_i!) 种情况对应的 (\dfrac {1}{2 ^ j}) 之和,其中 (j) 就是一种情况符合条件的节点个数。
转移稍微进行一些变通,即当 (v > k) 时,符合条件的节点个数增加 (1),所以有 (0.5) 的系数,即
[f_{i, k} = \sum\limits_{v = 1} ^ {sz_i} \begin{cases} g_{k – 1} & v \leq k\ 0.5g_{v – 1} & v > k \end{cases} ]
背包部分直接变成 (n ^ 2),但枚举 (i, k, v) 仍然是 (n ^ 3),可以前缀和优化做到 (n ^ 2)。因此总复杂度 (\mathcal{O}(n ^ 3)),不过不必要。
代码。
挺好想的一道题。
直接枚举所有字典序小于 (a) 的美丽矩阵 (b) 与 (a) 的 LCP(最长公共前缀)以及 (b) 的下一位的值。不妨设第一个不同位为 ((i, j))。
直接枚举 (b_{i, j}\in [1, a_{i, j})) 且 (b_{i, j}) 在 (b_{i, 1} \sim b_{i, j – 1})(即 (a_{i, 1}\sim a_{i, j – 1}))和 (b_{i – 1, j})(即 (a_{i – 1, j}))当中不能出现过,那么当前行接下来可以随便填,下面所有行也可以随便填,但要满足上下相邻两个数不同。
对于下面所有行,方案数很容易算,就是 (n) 阶错排数的 (n – i) 次方。但是对于当前行剩下 (n – j) 个元素,它们的填法受到 (b_{i – 1, j + 1} \sim b_{i – 1, n})(即 (a_{i – 1, j + 1} \sim a_{i – 1, n}))的限制,但不完全受到限制。具体地,求出有多少个数 (v) 使得 (v) 没有 在 (b_{i, 1} \sim b_{i, j}) 当中出现过,且在 (b_{i – 1, j + 1} \sim b_{i + 1, n}) 当中出现过(等价于没有在 (b_{i – 1, 1}\sim b_{i – 1, j}) 当中出现过),记作 (L),那么相当于是 (n – j) 阶排列有多少个限制了 (L) 个位置的错排,记作 (f_{n – j, L})。
假设 (f_{i, j}) 已经求出,考虑优化 (n ^ 3) 的时间复杂度。因为唯一不确定因素是 (b_{i, j}),所以我们先求出没有出现在 (b_{i, 1}\sim b_{i, j – 1}) 且没有出现在 (b_{i – 1, 1}\sim b_{i – 1, j}) 的数的个数 (L),(b_{i, j}) 对 (L) 的影响最多是当 (b_{i, j}) 没有出现在 (b_{i – 1, 1}\sim b_{i – 1, j}) 时将 (L) 减去 (1)。
因此,只需在 (v\notin b_{i, 1} \sim b_{i, j – 1}) 的前提下,维护存在多少个 (v) 使得 (v\notin b_{i – 1, 1}\sim b_{i – 1, j})。并且支持查询 (\leq V) 的 (v) 的个数。
可以用两个 BIT 维护,一个维护在前提下 (v\notin b_{i – 1, 1} \sim b_{i – 1, j}) 的个数,另一个维护在前提下 (v\in b_{i – 1, 1} \sim b_{i – 1, j}) 的个数。注意 (b_{i, j}) 不能等于 (b_{i – 1, j}),所以若 (b_{i – 1, j}) 没有在 (b_{i, 1}\sim b_{i, j – 1}) 出现过,那么还要在对应 BIT 里面减掉,求完当前位置的贡献后再加回去。
这部分时间复杂度 (\mathcal{O}(n ^ 2\log n))。
接下来解决遗留问题,怎么求 (f_{i, j})。
当 (i = j) 时是经典错排,有递推式 (f_{i, i} = (n – 1)(f_{i – 1} + f_{i – 2}))。
否则 (i > j),不妨设 (i) 这个位置没有限制。选择 (j) 个有限制的数当中某一个放到位置 (i),得到 (j f_{i – 1, j – 1});选择 (i – j) 个无限制的数当中某一个放到位置 (i),得到 ((i – j)f_{i – 1, j})。因此 (f_{i, j} = jf_{i – 1, j – 1} + (i – j)f_{i – 1, j})。
代码。
2022.4.28 计数专题
显然问题形如 (f_{i, j} = f_{i – 1, j} + f_{i – 1, j – 1} + f_{i – 2, j – 1}) 的递推。
发现 (n) 非常大,考虑根据实际意义分治。
对于任意一种 (L + R = n),从 (n) 个球里面分出 (j) 组的方案数就是分别从 (L) 和 (R) 个球里面分出总共 (j) 组的方案数,由于还有 (i – 2) 项,即第 (L) 和 (L + 1) 个球可能被分进一组,所以还要加上分别从 (L – 1) 和 (R – 1) 个球里面分出总共 (j – 1) 组的方案数。由于任何一种分组方式要么不包含 ({L, L + 1}),要么包含,所以这样数是不重不漏的。
根据上述分析,(f_{n, j} = \left(\sum\limits_{x + y = j} f_{L, x} f_{R, y}\right) + \left(\sum\limits_{x + y = j – 1} f_{L – 1, x} f_{R – 1, y}\right)),即 (f_n = f_L * f_R + x * f_{L – 1} * f_{R – 1}),其中 (*) 表示加法卷积。
令 (L = \left\lfloor\dfrac n 2\right\rfloor),(R = n – L) 递归,再使用 NTT 优化卷积即可。
等等?复杂度是不是有些问题?当 (n) 是偶数时我们会递归进两个规模为 (\dfrac n 2) 的子问题,当 (n) 是奇数时则会递归进三个(其实两个就够了,因为可以递推)。
主定理分析复杂度,(T(n) = 2T\left(\dfrac n 2\right) + \mathcal{O}(1)),发现我们要做 (T(n) = \mathcal{O}(n)) 次 NTT!大寄特寄!
此时笔者怀着绝望的心情给这玩意加了一个记忆化(猜测很多递归都是重复的),发现它过了?还跑的飞快?冷静分析一下,我们似乎确实不会访问到太多种类的下标 (i),因为只有能被表示为 (\dfrac {n – r}{2 ^ k}) 的数才会被递归到,而 (r) 又是 (\mathcal{O}(1)) 的(因为每一层至多减去 (2),而上一层递归下来时减掉的值在本层除以 (2) 之后折半了,所以 (\mathcal {O}(1 + \frac 1 2 + \frac 1 4 + \cdots) = \mathcal{O}(1))),所以时间复杂度就是 (\mathcal{O}(k\log k\log n))。
看了别的同学的题解后笔者发现直接分治实际上和倍增 NTT 是等价的。
注意多项式 (> 32767) 的位置要清空,否则这些位置循环卷积后会贡献至低位使得答案错误。
代码。
这题真的只有 * 3000 吗?
注意到最终串 (t) 长度固定,因此为了不重不漏地计数,我们尝试从两端向回文中心依次枚举对应两个(或一个,当且仅当枚举到回文中心)位置上的字符。
不妨设串长为偶数,此时我们填入恰好 (k = \dfrac {|s| + n} 2) 层字符。
据题意,(s) 能生成 (t) 当且仅当 (s) 是 (t) 的子序列。模仿子序列自动机,我们尝试枚举 (t),并 从两端向中心 匹配 (s)(因为 (t) 是回文串,所以每一层的两个字符相等)。设 (f_{i, l, r}) 表示填好 (i) 层字符时,在 两端尽量匹配(s) 的前提下还剩 (s_l \sim s_r) 没有匹配。
- 当(s_l = s_r) 时,(f_{i, l, r}) 以(25) 的系数转移到(f_{i + 1, l, r}),以(1) 的系数转移到(f_{i, l + 1, r – 1})。
- 当(s_l \neq s_r) 时,(f_{i, l, r}) 以(24) 的系数转移到(f_{i + 1, l, r}),以(1) 的系数转移到(f_{i, l + 1, r}) 或(f_{i, l, r – 1})。
- 任何(l > r) 的状态均可视作等价的终点(g_i),以(26) 的系数转移到(g_{i + 1})。因为已经匹配(s),剩下字符可以任意填。
(g_k) 即为所求。
(n) 非常大。使用矩阵快速幂优化,我们有了一个 (|s| ^ 6\log n) 的算法。
接下来需要使用一些魔法。
我们将转移图 (G) 给建出来(这是一个自动机)。上面有若干 (24) 和 (25) 的自环,以及终点处 (26) 的自环。具体地,若 (s_{l, r}) 满足 (s_l = s_r),则对应节点有 (25) 条自环,称为 (25) 点;否则有 (24) 条自环,称为 (24) 点。
所有能转移到 (l > r) 的 (s_{l, r}) 均连向终点,(1) 的系数对应图上的一条边。这里借用 CF 官方题解的图片。
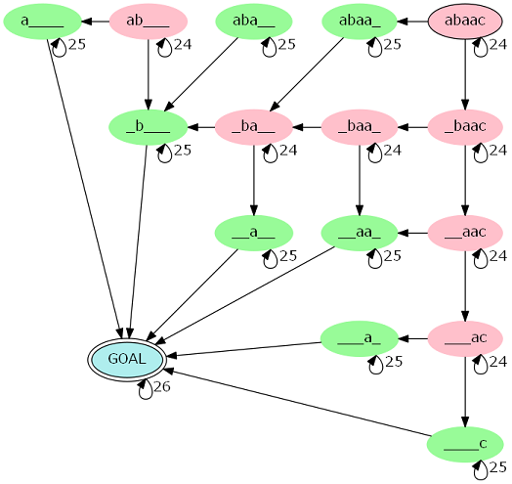

从起点 (s_{1, |s|}) 到终点的长度为 (k) 的路径条数即为答案。
若想优化复杂度,必须要寻找路径之间的等价性。
注意到整个自动机的规模是很小的,大部分时间我们都在走自环。将目光放在自环上。
我们去掉所有自环得到新图 (G_{\mathrm{acyc}})。对于 (G_{\mathrm{acyc}}) 上的任意一条从起点 (s_{1, |s|}) 到终点的路径 (P_{\mathrm{acyc}}),在其中插入若干自环使其长度为 (k),即可 唯一对应 (G) 上的一条需要计入答案的合法路径 (P)。
不妨设 (P_{\mathrm{acyc}}) 上有 (a) 个 (24) 点和 (b) 个 (25) 点,本题最关键的性质是 插入自环的方案数仅与(a) 和(b) 有关。这是因为在插入自环时,影响方案数的并非一个点具体是什么,而是一个点的自环个数。
换句话说,对于任意两条均具有 (a) 个 (24) 点和 (b) 个 (25) 点的路径 (P_{\mathrm{acyc}}) 和 (Q_{\mathrm{acyc}}),任何一种在 (P_{\mathrm{acyc}}) 中插入自环的方案可唯一对应一种在 (Q_{\mathrm{acyc}}) 中插入自环的方案(只需将 (P) 和 (Q) 的 (24) 点和 (25) 点一一对应即可)。
因此,设 (F(a, b)) 表示往 (a) 个 (24) 点和 (b) 个 (25) 点当中插入 (k – a – b) 条自环的方案数,则答案可表示为 (\sum #(a, b) F(a, b)),其中 (#(a, b)) 表示 (G_{\mathrm{acyc}}) 上从起点到终点经过 (a) 个 (24) 点和 (b) 个 (25) 点的路径条数。
考虑求解 (F(a, b))。
朴素的想法是直接把自动机建出来跑。具体地,建出这样一个自动机 (A_{a, b}),其形如 (a) 个 (24) 点连成一条链,接上 (b) 个 (25) 点连成一条链,再接上一个终点,并添上每个节点对应的自环数量。那么从起点走 (k) 步到终点的方案数即为 (F(a, b))。
这样做的时间复杂度是 (|s| ^ 5\log n),很劣。考虑优化。
我们发现大部分时间都浪费在矩阵快速幂上,但最终我们只取出了从起点到终点的路径条数。效率低下的主要原因是没有利用 矩阵快速幂能求出图上任意两点间长度为(k) 的路径条数 这一性质。
考虑将若干自动机合并在一起。
具体地,建出一张大自动机 (A),其形如 (|s| – 1) 个 (24) 点连成一条链(任何路径的 (24) 点个数最多为 (|s| – 1):走向终点的最后一步一定是 (25) 点),接上 (\left\lceil \dfrac{|s|} 2\right\rceil) 个 (25) 点连成一条链。在每个 (25) 点后均接上一个终点。
这样,任意一条 (a) 个 (24) 点和 (b) 个 (25) 点的路径均被自动机 (A) 表示出。只需求一遍 (A ^ k),然后合适地选取起点和终点即可 (\mathcal{O}(1)) 获得信息 (F(a, b))。
整个过程如下,图源 CF 官方题解。
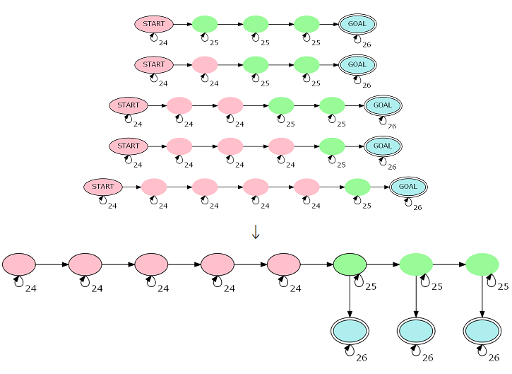
由于 (|A| = 2|s|) 所以求 (A ^ k) 会比较卡常。模数很小,所以用 long long 存矩阵就可以只在最后取模。
此外,根据 (A) 是上三角矩阵的特点,容易优化 (6) 倍常数。
考虑求解 (#(a, b))。
由于 (#(a, b)) 是在 (G_{\mathrm{acyc}}) 上的,所以直接 DAG DP 即可做到 (|s| ^ 4):设 (g_{l, r, a, b}) 表示从 (s_{l, r}) 走到终点经过 (a) 个 (24) 点和 (b) 个 (25) 点的方案数,转移很显然。
过不去,考虑优化。
我们发现,一个点的自环数和经过该点后串长减小的长度息息相关。更具体地,如果我们确定了一条路径经过了 (a) 个 (24) 个有自环的点,那么因为剩下来的点全都是 (25) 个有自环的点,而一个 (24) 点使未被匹配的 (s) 长度减小 (1),一个 (25) 点使为被匹配的 (s) 的长度减小 (2),故确定 (25) 点的个数为 (\left\lceil\dfrac {|s| – a} 2\right\rceil)。
这说明 (b) 是 (a) 的函数,即 (b) 可以根据 (a) 直接推出来,所以不需要记录 (b)。这样复杂度就成了 (|s| ^ 3),结合 (F(a, b)) 的 (|s| ^ 3\log n)(上述性质对自动机部分没有什么优化),可以通过本题的 (|s| + n) 为偶数的情况。
对于 (|s| + n) 为奇数的情况,最后一步只能消去一个字符。因此,最后一步形如从 (s_{l, l + 1}) 且 (s_l = s_{l + 1}) 的状态走到终点的路径是不合法的。
令 (k = \left\lceil\dfrac {|s| + n} 2\right\rceil),只需先做一遍偶数的情况,再令 (G) 上所有 (s_{l, l + 1}) 且 (s_l = s_{l + 1}) 的状态成为终点,减掉从起点走 (k – 1) 步到终点的方案数即可((#(a, b)) 和 (F(a, b)) 都类似求)。注意后者的 (F(a, b)) 从 (A ^ {k – 1}) 中得到,所以先减去后者再加上前者可以优化掉一半常数(不用做两次矩阵快速幂)。
时间复杂度 (\mathcal{O}(|s| ^ 3\log n))。
我的评价是,这道题目太好太神了,做完很受启发。
代码。
很明显,题目的限制想让我们进行树形 DP。
设 (f_{i, j}) 表示以 (i) 为根的子树,所有情况下虚树大小的 (j) 次方和。发现这样无法封闭转移,因为我们不知道新增贡献。
考虑换个状态。如果我们知道子树外是否有点,就可以确定当前枚举的这条边 ((u, v)(u = fa(v))) 是否产生贡献。
这启发我们设计状态 (f_{i, j}) 表示钦定子树外没有点的方案数,(g_{i, j}) 表示钦定子树外有点的方案数,前提均为 子树内有至少一个点在点集里。容易发现二者互斥,所以不会重复计数。
显然,(g_{root, k}) 即为所求。
先考虑如何合并 (f_u) 和 (f_v)。二项式展开 ((\sum x + \sum y) ^ j = \sum\limits_{p = 0} ^ j \dbinom j p (\sum x) ^ p (\sum y) ^ {j – p}),所以
[f_{x, j} = \sum\limits_{p = 0} ^ j \dbinom j p f_{u, p} f_{v, j – p} ]
这个复杂度不可以用树形背包分析,因为一个节点对 (j) 这一维产生的贡献不是 (\mathcal{O}(1)),而是 (\mathcal{O}(k)),所以总复杂度是稳稳寄掉的 (\mathcal{O}(n k ^ 2))。
我们要用到一个奇技淫巧,就是普通幂转下降幂维护。
根据 (x ^ k = \sum\limits_{p = 0} ^ k \begin{Bmatrix} k \ p \end{Bmatrix} x ^ {\underline{p}}),进行一个变形得到 (x ^ k = \sum\limits_{p = 0} ^ k \dfrac{1} {p!} \begin{Bmatrix} k \ p \end{Bmatrix} \dbinom x p),这玩意有什么用呢?就是我们只用维护 (f_{i, j} = \sum \dbinom x p),而此时一个节点对 (j) 这一维产生的贡献即 (\mathcal{O}(1))( 分析),因为当 (x < p) 时 (\dbinom x p = 0),而一个点对虚树大小的贡献最多为 (1)(在我们使用的状态设计前提下是这样的)。
(f_u) 和 (f_v) 的乘积根据范德蒙德卷积 (\dbinom {x + y} m = \sum\limits_{p = 0} ^ m \dbinom x p \dbinom y {m – p}),得到和一开始一样的合并式。
考虑转移。分当前点 (i) 是否选择讨论。令 (u) 为当前考虑的 (i) 的子节点。
若当前点选,则对 (f_i) 和 (g_i) 的贡献均为 (P = \prod (g_ux + 1)),因为一棵子树可以有点并且使得 ((i, u)) 产生贡献,也可以没有点,产生 (1) 的贡献。
若当前点不选,则
- 对(f_i) 的贡献是(\sum f_u),加上(P),减去(\sum g_ux),再减去(1)(只有一个(g_ux) 那么对应的(u) 子树外没有点,没有(g_ux) 那么子树内没有点,均不符合定义)
- 对(g_i) 的贡献是(P – 1)。
根据 “分析”,时间复杂度 (\mathcal{O}(nk))。
- 实际上直接维护下降幂即可,因为下降幂也满足二项式定理,而当(x < p) 时(x ^ {\underline{p}}) 同样为(0)。
代码。
挺没技术含量的一道题。比 CF755G 还要简单的倍增 NTT。
当 (n > k) 时答案为 (0),以下默认 (n \leq k)。
设 (f_{i, j}) 表示前 (i) 个数或起来二进制上有 (j) 个 (1) 的方案数(只是单纯考虑这 (j) 个 (1),元素之间无序,且 忽略掉剩下来(k – j) 个位置的存在),转移为
[f_{i, j} = \sum\limits_{p = 1} ^ {j} f_{i – 1, j – p} \dbinom j p 2 ^ {j – p} ]
含义是从 (j) 的 (1) 的位置中选 (p) 个放新的 (1),剩下 (2 ^ {j – p}) 个位置任选。
很好,这很卷积。
把组合数拆掉,有
[f_{i, j} = j!\sum\limits_{p = 1} ^ {j} \dfrac{f_{i – 1, j – p}}{(j – p)!} p! 2 ^ {j – p} ]
答案即 (\sum\limits_{j = 0} ^ k \dbinom k j f_{k, j})。
这样有了一个做 (n) 遍卷积的 (\mathcal{O}(nk\log k)) 过不去做法。
注意到每次转移的式子一模一样,考虑分治。
考察 (f_{i, j}) 和 (f_{i’, j’}) 两个值,它们会合并到 (f_{i + i’, j + j’})。尝试探究其系数。
从实际意义角度出发,从 (j + j’) 个位置中选择 (j) 个位置归到 (f_{i, j}) 对应的 (1),剩下来的位置归到 (f_{i’, j’}) 对应的 (1)。此外,对于后 (i’) 个下标,每个下标上都有 (j) 个位置可以自由选。综上,得到 (f_{i, j}) 和 (f_{i’, j’}) 的合并系数 (\dbinom {j + j’} j 2 ^ {i’j})。
设 (a + b = i(a, b > 0)),则转移式即
[f_{i, j} = \sum\limits_{p = 0} ^ j f_{a, p} f_{b, j – p} \dbinom j p 2 ^ {bp} ]
容易写成卷积形式
[f_{i, j} = j! \sum\limits_{p = 0} ^ j \dfrac{f_{a, p} 2 ^ {bp}}{p!} \dfrac{f_{b, j – p}}{(j – p)!} ]
直接取 (i) 的一半分治递归即可。注意加上记忆化。如果直接递归 (a) 等于 (i) 除以 (2) 下取整,递归 (b = i – a) 但不加记忆化,可以被卡爆,因为当 (n) 是奇数时,主定理分析 (T(n) = 2T(\frac n 2) + \mathcal{O}(1)) 解得要做 (\mathcal{O}(n)) 次卷积,爆炸。另一种解决方案是直接递归 (a),当 (i) 是奇数时先做一遍一步转移卷积得到 (f_b) 再合并 (f_a) 和 (f_b)。
要写三模 NTT 或 MTT。
代码。
实际上题目不存在一个长度 (> 3) 的简单环经过了 (1) 号点的限制根本不必要。
自然,我们首先尝试判断如何判定一张图存在满足题目的三个条件的路径。考察所有被经过奇数次的边,它们一定能被拆分成若干个简单环,因为与一个点相连的奇边条数一定是偶数(从 (1) 开始回到 (1) 意味着整条路径是回路)。
因此,类似最大 XOR 和路径那题的做法,我们容易通过一次 dfs 求出整张图上所有简单环的边权异或和(称为环的权值),只需检查是否存在一个非空子集使其异或起来等于 (0),这是线性基的拿手好戏。
从图中删去点 (1) 后,题目的性质实际上保证了任何一个连通块当中与 (1) 在原图上相连的点的个数不超过 (2)。
一个连通块一个连通块地考虑,设考虑到第 (i) 个连通块且所有简单环权值加入线性基后其形态为 (j) 的方案数为 (f_{i, j})。
转移即考虑当前连通块,若与 (1) 相连的点的个数等于 (1),那么可以选择断掉这条边不加入任何简单环,或者不点掉这条边,加入当前连通块的所有简单环。否则与 (1) 相连的点的个数等于 (2),可以选择断掉所有边不加入任何简单环,断掉任何一条边加入当前连通块的所有简单环,或者保留所有边加入当前连通块的所有简单环以及 (1) 和与(1) 相连的两个点形成的简单环。
加入简单环是以线性基的形式加入的,注意,若要加入的线性基已经不满秩(即行向量个数不等于加入的简单环个数),说明这些简单环已经形成了符合条件的路径,不符合题意,不能加入。
现在唯一的问题是如何表示一个线性基。自然的想法是为线性基编号,然后预处理所有线性基的合并关系(同时判断哪些线性基无法合并)。
打表发现本质不同的线性基个数只有 (374) 种。具体地,枚举五位分别放 (0\sim 2 ^ i(0\leq i\leq 4)),然后将本质相同(简化阶梯型相等)的线性基给去掉,可以暴力判断相等或给线性基一个哈希值并开桶判断(一共 (25) 个 bit,容易压缩至 ([0, 2 ^ {25})))。
还有一个注意点是,不同于最大 XOR 和路径,我们不能加入相同简单环(否则会导致错误判断存在可以生成 (0) 的非空子集),所以 dfs 找环并加入的过程需要格外注意细节。
综上,时间复杂度 (\mathcal{O}(W_wnw)),其中 (w = 5) 表示位数,(W_w) 表示位数为 (w) 的本质不同线性基个数。
至于限制不必要的问题,当一个连通块存在 (6) 个及以上与 (1) 相连的边时,至少存在 (6) 个本质不同的简单环,所以只需枚举 (2 ^ 5) 种情况即可。有 (\dfrac 1 5) 的常数毕竟每次会至少考虑到 (5) 个点。
代码。
注意到 (x) 和 (k) 很小而 (n) 很大,同时所有青蛙之间的距离必然不超过 (k)(因为每次只能跳最左边的青蛙),以及这 (q) 个奇奇怪怪的限制(联想到 “美食家” 这题),矩阵快速幂没得跑了。
预处理转移矩阵 (A) 的幂,在断点处特殊考虑,每次矩阵快速幂时只需向量乘矩阵,时间复杂度为 (\mathcal{O}((q + |A|)|A| ^ 2\log n))(这里 (|A|) 表示 (A) 的规模而不是行列式啊喂)。
这题唯一有技术含量的地方在于状态的设计。
我们有两条路,一是设 (f_{i, j}) 表示最左边的青蛙在 (i) 处,剩下来的青蛙状态为 (j) 时最小体力花费。这样由于每次跳动最多会让 (i) 增加 (k – x + 1),所以共需要记录 ((k – x + 1)\dbinom {k – 1} {x – 1}) 个状态,算一下当 (x = 4),(k = 8) 时共有 (170) 个状态,即 (|A| = 170),勉强可以通过。
另一种是设 (f_{i, j}) 表示当前的 视野 在 (i\sim i + k – 1) 处,以这样的视野观察到青蛙的状态为 (j) 时的最小体力花费。具体地,(j) 的第 (p) 位为 (1) 当且仅当 (i + p) 处有青蛙。这样一来,若 (2\mid j) 即 (i) 处没有青蛙时,转移到 (i + 1) 只需给 (j) 除以 (2) 而非跳最左边的青蛙。因此只需记录 (\dbinom k x) 个状态,当 (x = 4),(k = 8) 时只有 (70) 个状态,稳稳通过。
所以说有的时候巧妙的状态设计是很重要的。
代码。
(q) 组询问,以 16 进制的形式给出 (L, R),求出满足以下条件的整数 (x) 的个数。
- (L\leq x \leq R)。
- (f(x) < x)。其中(f(x)) 定义如下:
设 (x) 在 16 进制下的数位分别为 (\overline{d_k d_{k – 1} d_{k – 2} \cdots d_0}),令 (y = \sum\limits_{i = 0} ^ {15} 2 ^ i[i\in d]),则 (f(x) = x \oplus y)。换句话说,(f(x)) 等于 (x) 异或上 “(2) 的 “所有在 (x) 的 16 进制下出现的数码” 次幂之和”。
(1\leq q\leq 10 ^ 4),(0\leq L\leq R < 16 ^ {15})。
考虑数位 DP,用 (\leq R) 的符合条件 2 的数的个数减去 (< L) 的符合条件 2 的数的个数。
令 (D = \max d)。我们只关心 (x) 在二进制下第 (D) 位的取值。因为若为 (1),则 (f(x)) 的第 (D) 位为 (0)(而高位不变因为 (D) 已经是最高位了),(f(x) < x);否则 (f(x)) 的第 (D) 位为 (1),(f(x) > x)。
因此,直接枚举 (D),套路地设 (f_{i, j, k}) 表示当前考虑了高 (i) 位(16 进制下),是否已经存在一位满足 (d_p = D) 以及是否顶到上界。根据实际意义枚举下一位转移即可,注意考虑 (D),顶到上界的 (d_{p – 1}(R)) 以及 二进制下 第 (D) 位为 (0) 的限制。
答案即对 (R) 求的 (\sum\limits_{D = 0} ^ {15} f_{0, 1, 0} + f_{0, 1, 1}) 减去对 (L) 求的 (\sum\limits_{D = 0} ^ {15} f_{0, 1, 0}),因为前者是 (\leq),后者是 (
时间复杂度 (\mathcal{O}(qw ^ 3))。
代码。
一道计数好题。
首先对题目进行第一步转化,设一种方案 (S)((S) 表示有空的志愿者的点集)的半径为 (f(S)),将 (n – 1 + \sum\limits_{r = 1} ^ {n – 1} r \sum\limits_{S \neq \varnothing \land S \neq U} [f(S) = i]) 改写为 (\sum\limits_{r = 1} ^ {n – 1} \sum\limits_S [f(S)\geq r]),因为对于一般 DP 限制,大于等于比恰好等于更容易满足。
从差分容斥算半径恰好等于某个值的方案数也可以推得上式,因此问题转化为对每个 (r) 求解 (\sum\limits_{S} [f(S) \geq r])。
设有空的点为白点,没有空的点为黑点。
容易发现,一个方案的半径大于等于 (r) 当且仅当存在一个点使得距离它最近的黑点与它的距离大于 (r)。接下来的一切分析都围绕这个结论展开。
设 (f_{i, j}) 表示以 (i) 为根的子树内部距离 (i) 最近的黑点的距离为 (j) 的方案数,自然的想法是当 (j = r + 1) 时就满足了条件。但实际上并非这样,因为 (i) 只满足了子树内的限制,还没有满足子树外的限制(即 (i) 子树外距离 (i) 最近的黑点并不一定距离 (i) 大于 (r))。我们记这样的点为 预备点,即已经满足子树内距离其最近的黑点与其距离大于 (r) 的限制,可能成为聚会中心的点。
为此,我们再设 (g_{i, j}) 表示 (i) 的子树内最深的预备点与 (i) 的距离为 (j) 时的方案数(如果最深的都不满足子树外要求,那么更浅的一定不满足,所以只关心最深的预备点),这样就可以封闭转移了。
注意,(f, g) 两者是 互斥 的,即若子树内已经存在预备点,那么没有必要再考虑距离 (i) 最近的黑点与 (i) 的距离。如果不存在时,我们才要记录距离 (i) 最近的黑点与 (i) 的距离。这保证计数不重不漏。
我一开始想同时考虑到一个节点的所有儿子,发现根本不可做就弃疗了。实际上,如果从 合并两棵子树 的角度分析,问题就变得相当好做。这也说明 树形 DP 不方便同时考虑所有子节点时,单独考虑合并两棵子树 是很有用的策略。
初始化很容易,(f_{i, 0} = g_{i, 0} = 1),分别代表当前点涂成黑点和白点两种选择。
设当前合并节点 (i) 与其子节点 (u)。
- 合并(f_{i, j}) 和(f_{u, k})。据定义,距离(i) 最近的黑点距离为(\min(j, k + 1)),转移到(f_{i, \min(j, k + 1)})。
- 合并(f_{i, j}) 和(g_{u, k})。若(j + (k + 1) > r),那么(u) 子树内的预备点不会被干扰,转移到(g_{i, k + 1})。否则该预备点由于不满足子树外限制被舍弃,转移到(f_{i, j})。
- 合并(g_{i, j}) 和(f_{u, k})。同理,若(j + (k + 1) > r) 则转移到(g_{i, j}),否则转移到(f_{i, k + 1})。
- 合并(g_{i, j}) 和(g_{u, k})。转移到(g_{i, \max(j, k + 1)})。
答案即 (\sum\limits_{i = 0} ^ n g_{root, i})。
根据转移式,我们发现一个节点的 (f, g) 有值的部分大小为 (\mathcal{O}(\mathrm{maxdep}(i)) \leq \mathcal{O}(\mathrm{size}(i))),所以根据树形背包的复杂度分析,一次 DP 的复杂度为 (\mathcal{O}(n ^ 2))。
综上,总复杂度为 (\mathcal{O}(n ^ 3))。
代码。
这个 “最大流等于 (m)” 的限制看起来很有趣。
自然地,设 (f_{i, j}) 表示向形如 (S\to T) 的图上进行 (i) 次操作使得最大流等于 (j) 的方案数。答案即 (f_{n, m})。
考察对 (S\to T) 进行一次操作后图的形态。图上会增加一条形如 (S\to w \to T) 的链,并使得最大流增加 (1)。
接下来的操作如果对 (S\to w\to T) 进行,那么问题就变成了这样的子问题:向形如 (S\to w\to T) 的图上进行若干次操作,使得最大流等于某个值。不妨设进行 (i) 次操作后使得最大流为 (j) 的方案数为 (g_{i, j})。
或者从这样的角度思考:不妨设最终我们对 (S\to T) 进行了 (c) 次操作,那么整张图会出现 (c) 条形如 (S\to w_i \to T) 的链,原图的最小割等于 (1)((S\to T))加上每条这样的链在若干次操作之后的最小割 之和( 结论 1)。因为这些链是 并联 的,我们要把每条链都割开才能保证 (S) 与 (T) 不连通。
显然, 链之间相互独立,因为一条链上的操作不会影响到其它链的最小割。这说明一个 (S\to T) 的 (f_{i, j}) 由若干 (S\to w\to T) 的子问题 (g_{i’, j’}) 组合得到。
根据结论 (1),(f_{i, j}) 由 (g_{i’, j’}) 做背包得到,即
[f_{i, j} = \sum\limits_{\sum i_p = i}\sum\limits_{\sum j_p = j – 1} \prod\limits_p g_{i_p, j_p} ]
(这个方程有点问题,我接下来会讲到)
(g_{i, j}) 的求解是容易的。对于 (S\to w\to T) 而言,它的最小割等于对 (S\to w) 进行若干次操作后 (S\to w) 的最小割与对 (w\to T) 进行若干次操作后 (w\to T) 的最小割的 最小值。这与上面的求和不同,因为 (S\to w) 和 (w\to T) 是 串联 的关系。
因此我们有
[g_{i, j} = \sum\limits_{a + b = i}\sum\limits_{\min(p, q) = j} f_{a, p}f_{b, q} ]
对每个 (f) 都暴力跑一遍背包,时间复杂度 (\mathcal{O}(n ^ 6))。先不提效率,我们发现这样的代码过不了样例 3,连正确性都无法保证。
问题出在哪呢?重新阅读题面,我们发现 同构的图之间没有顺序,但做背包时物品之间是有顺序的,即 (g_{a, b} \times g_{a, b}) 表示先从 (g_{a, b}) 个图中选一个 (G_x),再从 (g_{a, b}) 的图中选一个的方案数 (G_y),但对于两种 有顺序 的选择方案 (A_1) 和 (A_2),可能有 (A_1(G_x) = A_2(G_y)) 且 (A_1(G_y) = A_2(G_x)),二者同构却会被我们视作不同。
对此的解决方法是,向背包中加入一个物品 (g_{a, b}) 时, 不要以完全背包的形式加入,而是直接枚举加入的个数 (k),那么方案数形如 (k) 个无标号的球放入 (g_{a, b}) 个有标号的盒子,允许多个球放入一个盒子,即 (\dbinom{g_{a, b} + k – 1} k),做烂掉了属于是。
组合数直接对每个 (g_{a, b}) 预处理,这部分是 (\mathcal{O}(n ^ 3))。背包部分由于多个一个调和级数,所以复杂度变成 (\mathcal{O}(n ^ 6\ln n))。
令人震惊的是,它可以 通过,因为常数太小了(大概有几千分之一的样子)。
考虑优化。
实际上我们完全没有必要对每个 (f) 做一遍背包,因为如果 (a > i) 或者 (b > j),那么就算 (g_{a, b}) 加入了背包,也不会对 (f_{i, j}) 产生贡献(都有一维大于 (f_{i, j}) 了还怎么可能对 (f_{i, j}) 产生贡献啊?)。
这样复杂度就是 (\mathcal{O}(n ^ 4\ln n)) 的,可以通过。
代码对 (f_{i, j}) 的定义稍有区别,其中 (j) 表示除了 (S\to T) 这条边以外剩下的图的最小割为 (j)(即原来的 (f_{i, j + 1}),所以答案是 (f_{n, m – 1}))。
代码。
2022.4.30 杂题
经典的 wqs 二分题目。
笑死,根本没有人写官方题解的数据结构维护贪心做法。
设 (f_{i, j, k}) 表示前 (i) 个精灵使用 (j) 个宝贝球和 (k) 个精灵球的最大期望个数,直接 (n ^ 3) 就可以通过(震惊了)。
对 (k) 这一维使用 wqs 二分即可得到一个 (n ^ 2\log n) 的优秀做法。
同时对 (j, k) 使用 wqs 二分即可得到一个 (n\log ^ 2 n) 的踩标算做法。
注意,一般 wqs 二分要求选取物品个数极值化,但 wqs 二分套 wqs 二分究竟以内层物品个数还是外层物品个数为第一关键字是个问题。我也不知道。所以我给出的建议方案是,二分值域为实数时显然没有问题,为整数则调整二分边界时不要除去 (m),即令 (l = m) 或 (r = m),到 (l + 1 = r) 时停止。由于剩余值域很小,直接把所有可能的斜率情况暴力跑一遍求答案即可。
诶,wqs 二分套 wqs 二分好像是假的。详见 这个帖子。还是老老实实写一层 wqs 二分罢。
一层 wqs 二分 & wqs 二分套 wqs 二分(错误的)。
非常有启发性且诈骗的题目。
我们注意到一个重要性质,那就是位运算在每一位独立。
设 (f(i, d)) 表示 (s_is_{i \oplus 1}s_{i\oplus 2} \cdots s_{i\oplus (2 ^ d – 1)}),即将 (s) 的下标异或 (i) 得到的字符串的前 (2 ^ d) 位。发现 (f(i, d + 1) = f(i, d) + f(i \oplus 2 ^ d, d))。
因此,类似后缀排序,设 (p(i, d)) 表示 (f(i, d)) 在所有 (f(j, d)(0\leq j < 2 ^ n)) 当中的排名,则 (p(i, d + 1)) 即为二元组 ((p(i, d), p(i \oplus 2 ^ d, d))) 在所有二元组 ((p(j, d), p(j \oplus 2 ^ d, d))) 当中的排名。
倍增并直接排序,时间复杂度 (\mathcal{O}(2 ^ nn ^ 2))。使用基数排序可以去掉一个 (n),但在本题中并不必要。
代码。
注意到问题与任意两点在原图上的最小割相关,所以建出最小割树。
记 (d(i, j)) 表示节点 (i, j) 在最小割树上的简单路径经过的所有边的边权的最小值,问题转化为求一个 (n) 阶排列 (p_1, p_2, \cdots, p_n),最大化 (f(p) = \sum\limits_{i = 1} ^ {n – 1} d(p_i, p_{i – 1}))。
这看上去是一个很经典的问题。实际上确实很经典。
由于 (d(i, j)) 是边权最小值的形式,所以我们猜测答案上界就是所有边的边权和。考虑构造。
找到整棵树上边权最小的边 ((u, v)),设它把树分成 (S, T) 两个点集。
考虑最终的排列。如果 (u\to v) 这条边被经过超过一次,通过调整法容易证明不优,因此,我们断言必然存在最优排列使得 (u\to v) 只被经过一次,即必然是先完整地走完 (S),再从 (S) 中的某个点以 (w(u\to v)) 的贡献走到 (T) 中的某个点,再完整地走完 (T)。
分两步证明上述结论。
- (u\to v) 不可能被经过超过两次。考虑(a, b\in S) 且(c, d\in T),因为((u, v)) 是权值最小边,所以(d(a, b) + d(b, c) + d(c, d) \geq d(a, c) + d(c, b) + d(b, d))。
- (u\to v) 不可能被经过恰好两次。否则,不妨设(a, b\in S) 且(c, d\in T),我们从(a) 走到(c),走遍整个(T),再从(d) 走到(b) 回到(S)(所以(p_1, p_n\in S))。考虑调整为新的路径(p_1 \to \cdots \to a \to b \to \cdots \to p_n \to c\to \cdots \to d)。由于(d(p_n, c) = w(u\to v) = d(d, b)) 且(d(a, b) \geq w(u\to v) = d(a, c))(((u, v)) 是权值最小边),所以(d(a, b) + d(p_n, c) \geq d(a, c) + d(d, b))。
跨过 (u, v) 的这次移动 (p_i\to p_{i + 1}) 最小值已经是 (w(u\to v)) 了,所以无论 (p_i) 是 (S) 内部的哪个点,(p_{i + 1}) 是 (T) 内部的哪个点,都不会影响到 (d(p_i, p_{i + 1}))。这样,我们将问题划分成了在 (S) 和 (T) 内部的子问题(问题形如 “对于一棵树 (T) 求出 (|T|) 阶排列 (p) 最大化 (\sum\limits_{i = 1} ^ {|T| – 1} d(p_i, p_{i + 1})))。递归边界即点集内部只剩下一个点,此时直接输出它的编号即可。
通过上述构造过程,我们也证明了答案上界恰为所有边的边权和。因为我们构造出来的方案是最优解,而方案中每条边恰好贡献一次。
时间复杂度是构建最小割树的复杂度,加上构造的复杂度 (\mathcal{O}(n ^ 2))。
代码。
存在一个 (n) 个点的多边形,点按顺序从 (1) 到 (n) 标号。(m) 条不在除了端点以外的地方相交的对角线将多边形划分成 (m + 1) 个区域 (R_1, R_2, \cdots, R_{m + 1})。
令某个区域的端点为 (a_1, a_2, \cdots, a_{|R_i|}),定义一个区域的重要度为 (f(R_i) = \sum\limits_{j = 1} ^ {|R_i|} 2 ^ {a_j})。将所有区域按重要度从小到大排序并编号,即 (f(R_1) < f(R_2) < \cdots < f(R_{m + 1}))。
现在,你要给每个区域染上一种颜色,用一个 (1\sim 20) 之间的正整数表示。
求出这样一种染色方案,使得对于任意两个颜色相同的区域 (R_i) 和 (R_j(i\neq j)),均满足它们之间的任何一条简单路径上都均存在至少一个区域 (R_k) 使得 (R_k) 的颜色小于 (R_i) 和 (R_j) 的颜色。简单路径定义为不经过重复区域,且路径上相邻两个区域有一条公共边的路径。
按编号顺序输出每个区域的颜色。
可以证明在题目限制下一定存在解,若有多解输出任意一个。
(3\leq n \leq 10 ^ 5),(0\leq m \leq n – 3)。
阅读理解 + STL 基础使用练习题。
我们将整个多边形剖分的区域建出树来,任意两个区域的简单路径就是它们在树上的简单路径。相当于我们要给整棵树染色,使得任意两个相同颜色的节点之间存在颜色小于它的节点。
那么问题就变成了两部分,一是给多边形剖分建树,二是树染色。
先解决第一部分建树。
设所有对角线连接顶点 (a_i, b_i),且 (a_i < b_i)。由于保证对角线两两不交,所以我们类似括号序列那样处理每条对角线。将所有二元组涉及到的共 (2m) 个顶点按标号从小到大排序,然后依次扫描。注意若两个顶点编号相同,那么按照类型为 (b) 的顶点在前,类型为 (a) 的顶点在后,这样才能保证不会错误匹配。
设当前节点为 (x_i)。若 (x_i) 是某个 (a_j),那么将其入栈。否则 (x_i) 是某个 (b_j),且当前栈顶即为其对应的 (a_j)。那么 ([a_j, b_j]) 这个区间就形成了一个区域。想象用一把刀把它切掉,这意味着我们将所有在 ((a_j, b_j)) 范围内的顶点删去(有些节点在之前的操作中已经被删去了)。本次操作被删去的顶点,再加上两个端点 (a_j) 和 (b_j),就是当前区域 (R_k) 的顶点。删点可以用双向链表或 set 维护。
这样,我们得到了所有 (m + 1) 个区域的所有顶点。将其按照字典序(题目中的规则)从小到大排序得到编号。然后枚举每一条对角线,它是某两个区域的公共边,找到这两个区域(通过 map 或其他方式容易实现)并在他们之间连一条边,即可得到最终的剖分树。
第二部分看起来有些棘手(但我不会告诉你本人做过一道非常类似的题目所以直接秒掉了,题目在题解最后)。尝试分析一些性质。
先假设我们已经找到了符合条件的染色方案。 很多问题都是先从一个满足限制的局面出发分析性质,从而推得满足限制的充要条件。
对于某种颜色 (c),找到树上所有颜色为 (c) 的节点 (S)。考虑点集 (S) 在原树上张成的虚树,必然需要有若干颜色 (< c) 的节点将 (S) 分割开来。也即扣掉颜色 (< c) 的点之后 (S) 不连通。
考察点分治的过程,我们将根节点扣掉后,形成若干不连通的子树。这与上面的观察有相似之处,考虑定量描述。因为一棵树的深度具有子节点大于父节点的性质,所以原图的任意一棵点分树的深度情况均为一种可行的染色方案。
(我已经尽力在说明应该怎么想到点分树了,可是看起来还是有些不自然 /ll)
因此,只需对原树进行点分治,求出每个点在点分树上的深度。标号大小为严格 (\log_2 n + 1),符合题目 (20) 的限制。前提是在寻找子树重心时正确下传子树大小,而非用当前分治重心的父亲作为根时对应子树大小作为以当前分治重心作为根时对应子树大小,尽管后者不影响时间复杂度但会使得递归层数不满足严格 (\log_2 n) 的限制(应该至多乘上一个 (2),那么就寄了)。
时间复杂度线性对数。类似的问题见 P5912 [POI2004]JAS。
代码。
感觉并没有太搞懂这道题的内核,只是学了个表面。tourist 的题就是神啊!
二分转化成判定性问题不必多说,关键是怎么判断一个初始值能够走遍整张图。
第三个限制很烦人,我们一定是围绕它做文章。考虑从某个点 (x) 开始走出一步到 (y) 的过程,我们希望是 (y) 也能回到 (x),这样我们走的这一步就 无后效性 了,而且能为总点数带来 (b_y) 的贡献,进而可以直接贪心每次扩展一个点,再走回来。
对于有第三个限制的情况,核心思路还是不变的。我们尝试从某个点 (x) 开始走出去,绕一个圈子再回到 (x) 的过程,不妨设这条路径为 (x \to p_1 \to \cdots \to p_k \to x),那么我们可以直接将这条路径带来的贡献加入(即扩展路径上所有没有被扩展的点,并加上它们的 (b) 值)。
可以证明这样做 无后效性,即我们可以再次从已经扩展的 任何一个点(包括新扩展的点)出发,绕一个环扩展其他点。
核心是这样的:如果路径上存在一个有向简单环(尽管是有向但不能经过重复无向边,即满足第三条限制),那么我们可以沿进入这个简单环的路径回到原来已扩展的点或者在进入这个简单环之前的路径上的任何一个点。
举个例子,如果 (a) 是已经被扩展的点,我们发现 (a\to b\to c\to d\to e \to c) 是可行的,那么我们可以沿 (c\to b\to a) 回到原来已扩展的点 (a) 以及进入简单环之前的路径上的点 (b),因为 (e\to c) 使得当前路径不再受 (b\to c) 之后不可以 (c\to b) 的限制。
因此,我们每次找到原图上从某个已扩展的点 (x) 出发,第一步跨向某个未扩展的点 (y)(如果 (y) 已扩展那不如直接从 (y) 出发呢)的带有简单环的一条路径,可以通过 dfs 实现。
我们发现这个复杂度好像有点寄,不能打 visit 标记,因为可能从 (x) 开始走某条路径到 (y) 之后走不通了,但是走另一条路到 (y) 就能继续走下去,所以不能在第一次访问 (y) 走不通就 ban 掉 (y)。
怎么办呢?这个时候就要发动我们的慧眼观察性质了。我们发现,如果存在两条路径 (x\to p_i\to y) 以及 (x\to p’_i\to y) 都能到达 (y),其中最后一步 (p_k\to y) 和 (p’_k \to y) 的 (p_k) 和 (p’_k) 是不同节点(否则可以令 (y) 等于 (p_k)),那么由于 (b) 是正数,所以一定可以 (x\to p_i \to y) 再沿着 (p’_i) 的逆路径走回来(感觉这是本题最关键的性质),这意味着我们找到了一条具有简单环的路径,可以直接扩展。
由于一个节点最多只会被访问一次,若访问两次则直接扩展了,所以一次扩展的复杂度为 (\mathcal{O}(m))。因为最多进行 (\mathcal{O}(n)) 次扩展,所以总时间复杂度即 (\mathcal{O}(nm\log a_i))。
- 注意,当访问到一个已经被扩展的节点时也可以直接扩展当前路径上所有节点,这样就不要考虑访问到已经被扩展的节点的情况(我们从某个已经被扩展的节点 (x) 开始向外走一步到某个未被扩展的节点 (y),那么不仅 (y) 要被标记,(x) 也要被标记,否则可能出现 (x\to y) 且 (z\to y’\to x \to y) 使得我们认为 (x\to y\to x\to y’\to z) 是一条合法路径,就寄了,提交记录为证。容易发现标记 (x) 起到的效果和访问到被扩展的节点时直接扩展当前路径上所有节点是一样的)。
- 还有一个注意点是枚举被扩展的作为路径起点的节点中不能包含本轮被扩展的节点,否则可能出现 (x\to y\to z) 使得 (z) 被访问,然后 (y) 被另一条路径再次访问使得 (y) 被扩展,(y) 又作为被扩展的节点向外走到 (z),使得我们认为 (x\to y\to z\to y) 是合法路径,(z) 被错误地扩展。解决方法是预先记录要从哪些被扩展的节点开始 dfs,或者找到扩展路径后立刻结束本轮扩展。
代码。
我今天就是要用 kruskal 过了这道题!
建出原图 (G) 的最小生成树 (T),则 (G) 上任意两点 (u, v) 的最短路即 (T) 上 (u, v) 之间边权最大值。
更进一步地,建出原图 (G) 的 kruskal 重构树 (T),对于 (T) 上的每个非叶子节点 (u),设其权值为 (w),那么对于 (G) 的补图 (G’),所有 (u) 的左子树的叶子节点与所有右子树的叶子节点之间有权值为 (w) 的边(前提是连边的点对在原图上无连边)。
我们希望求出 (G’) 的最小生成树 (T’)。但是 (G’) 上的边太多,我们无法使用朴素的最小生成树算法,必须进行优化。
考虑 kruskal 求最小生成树的过程,每次找到权值最小的边,若两端在最小生成树上不连通,则加入最小生成树。因此,我们按权值从小到大依次考虑 (T) 上每个非叶子节点带来的影响。
权值从小到大在重构树上对应着深度从深到浅,所以我们先递归考虑当前节点的左右儿子,再考虑当前节点。
设当前节点为 (u),其左子树所有叶子节点为 (L),右子树所有叶子节点为 (R)。在递归处理左右子树时,(L) 和 (R) 在 (G’) 上已经形成了若干连通块。设 (L) 形成的连通块集合为 (S_L = {GL_i}),(R) 形成的连通块集合为 (S_R = {GR_i}),每个 (GL_i) 均由若干 (L) 当中的节点组成,(GR_i) 同理。
考虑合并 (S_L) 和 (S_R)。
枚举 (S_L) 内所有连通块 (GL_i),然后枚举 (GL_i) 内所有节点 (x),然后枚举 (S_R) 内所有连通块 (GR_j),然后枚举 (GR_j) 内所有节点 (y),如果 (x, y) 之间没有连边,那么它们在补图上直接相连,就把 (GR_j) 从 (S_R) 中删去,并合并到 (GL_i) 当中。
注意,由于可能出现 (GL_i) 和 (GL_k) 同时与 (GR_j) 合并使得它们连通的情况,所以对于每个 (GL_i) 处理完要丢进 (S_R) 里面去。
看起来很暴力对吧。只要你加上启发式合并,它的复杂度就变成了惊人的 (\log ^ 2n)。
我们来证明这一点。考虑枚举 (x, y) 的复杂度。
因为一旦 (x, y) 之间在 (G) 上没有直接连边,那么必然有两个连通块被合并。据此可证明,使得 (x, y) 没有直接连边的次数为 (\mathcal{O}(n))。
合并连通块的复杂度由启发式合并保证,用 set 维护每个连通块,这部分时间复杂度 (\mathcal{O}(n\log ^ 2 n))。
所以只需保证直接连边的 (x, y) 不会被枚举太多次即可。直接连边的 (x, y) 每次被枚举一定形如,在此之前 (x) 作为 (GL_i) 的某个点在 (GL_i) 被丢进 (S_R) 时合并进 (R),使得 (y) 作为接下来被枚举到的 (GL_i) 的某个点,且 (x) 作为 (GR_i) 的某个点(其实还有一种情况是在 LCA 处,一个作为 (GL_i) 里面的点,另一个作为 (GR_j) 里面的点被枚举到,不过这部分由于原图每条边只会贡献一次,所以枚举次数为 (\mathcal{O}(m)))。由于我们对 (|L|) 和 (|R|) 的合并也是启发式的,所以一个点作为 (L) 中的某个点被合并进 (R) 的次数不超过 (\log n),故使得 (x, y) 之间直接连边的次数为 (\mathcal{O}(m\log n))。
因为每次查询 (x, y) 之间是否有连边的时间复杂度为 (\mathcal{O}(\log n)),所以总时间复杂度为 (\mathcal{O}(m\log ^ 2 n))。
合并两个连通块时需要在补图 (G’) 的最小生成树 (T’) 上的连通块代表元之间连权值为 (w(u)) 的边。求出 (T’) 后回答询问就是很简单的询问树上两点之间边权最大值,树上倍增做即可。
代码。
题目限制相当于整张图是一个树状结构,不会出现一个空地被若干城市包围的情况。但其实也不完全对,因为图上可能出现矩形城市块,不太好处理。
我们希望将整张图抽象成树状结构,因为对于树上形如 “点亮一个点或查询距离某个点最近的被点亮的点” 的问题,它是一类与树上邻域相关的问题,可以用动态点分治(点分树)解决。经典例题如 Qtree 5。
直接把每个城市看成树上的一个节点是不可行的,因为矩形城市块会使得整张图出现环。
接下来就是本题最巧妙的地方了。既然一个单独的城市无法视作一个节点,不妨将 一列或一行极长的城市段 视作一个节点。两个节点相邻当且仅当它们内部存在两个城市相邻。
下文将一列(横坐标 (x) 相同)极长城市段视作一个节点。
我们建出树 (T) 以及其点分树 (T’)。在尝试解决查询距离某个城市最近的商店之前,我们先要思考如何计算两个城市 (x, y) 之间的距离。设其对应节点分别为 (u, v),格点之间的最短路体现在节点上必然形如 (u\to v)。求出 (u, v) 在 (T) 上的 LCA (d),(x, y) 之间的距离可以被表示为 城市 (x) 到 节点 (d) 的最短路长度,加上 (y) 到 (d) 的最短路长度。等等,还有些问题,(x) 走到 (d) 之后并不一定会立刻离开 (d) 走向 (y),而是会先走到 (y) 到 (d) 的最短路在 (d) 上的对应 城市 (p(d, y)) 再离开 (d)。因此还要加上 (p(d, x)) 与 (p(d, y)) 之间的距离。可以证明对于任意城市
(x),(p(d, x)) 都是唯一的(否则可证存在环),但证明似乎很麻烦,所以感性理解一下吧。
这样我们可以查询任意两个城市的最短路了,这比普通的树上求距离要麻烦一些。对每个分治重心 (u) 求出其子树内所有节点 (v) 所代表的所有城市 (x) 与 (u) 的最短距离 (d(u, x)) 以及最短路在 (u) 上的对应城市 (p(u, x))。查询 (x, y) 的最短路时,先求出它们对应节点在 (T’) 上的 LCA (d),那么 (D(d, x, y) = d(d, x) + d(d, y) + |p_y(d, x) – p_y(d, y)|) 即为所求((D(d, x, y)) 表示从 (x) 到节点 (d) 再到 (y) 的最短距离),其中 (p_y(d, x)) 即 (p(d, x)) 的纵坐标。
有了这个工具,我们尝试解决原问题。
考虑询问城市 (x),我们找到 (x) 的对应节点 (u) 在 (T’) 上的所有祖先 (a)(包括 (u) 本身),根据计算式,我们相当于求 (\min D(a, x, y)) 即 (\min d(a, x) + d(a, y) + |p_y(a, x) – p_y(a, y)|)。如果 (a) 不是 (x) 和 (y) 的 LCA,式子的值只会变大,不影响最终答案,而每个 (y) 都会在与 (x) 的 LCA 处正确计算 (x, y) 之间的距离,这就证明了正确性。
考虑将 (D(a, x, y)) 拆成仅与 (x) 有关的部分和仅与 (y) 有关的部分。这个绝对值很讨厌,分类讨论把它拆掉。当 (p_y(a, y) \leq p_y(a, x)) 时,
[D(a, x, y) = (d(a, x) + p_y(a, x)) + (d(a, y) – p_y(a, y)) ]
否则 (p_y(a, y) > p_y(a, x)),
[D(a, x, y) = (d(a, x) – p_y(a, x)) + (d(a, y) + p_y(a, y)) ]
因此,点亮一个城市 (y) 时,枚举其对应节点在 (T’) 上的所有祖先 (a),并将 (d(a, y) – p_y(a, y)) 挂到序列 (A_a) 的下标 (p_y(a, y)) 处,(d(a, y) + p_y(a, y)) 挂到序列 (B_a) 的下标 (p_y(a, y)) 处,查询 (x) 跳到祖先 (a) 时只需查询 (A_a) 在 (p_y(a, x)) 处的前缀最小值和 (B_a) 在 (p_y(a, x)) 处的后缀最小值即可。做这一步是因为拆成仅与 (x) 有关和仅与 (y) 有关的部分的前提条件是对 (y) 到 (a) 的最短路在 (a) 处的对应城市 (p(a, y)) 的纵坐标 (p_y(a, y)) 进行了限制。
单点取 (\min),前缀(后缀)查询最小值,用树状数组分别维护 (A_a) 和 (B_a) 即可。注意要对每个节点动态开 BIT 大小( vector 实现),并将坐标限制在一定范围内(容易限制在连续段长度范围内)才能保证 (\mathcal{O}(n\log n)) 的复杂度。
显然,时间复杂度为 (\mathcal{O}(n\log ^ 2 n)),空间复杂度为 (\mathcal{O}(n\log n))。
接下来分析一下具体实现细节,因为 (n = 3 \times 10 ^ 5) 但时限只有 3s 所以还是很卡的,需要精细实现以减小常数。
- 首先 在一开始 将所有点用
map映射到 (1\sim n) 的整数,接下来处理所有坐标必须用映射值,否则在内层处理的时候如果还要映射 (\mathbb N_+ ^ 2 \to \mathbb N_+),那么常数会相当大。 - 我们需要多次判断一个格子是否在以某个节点 (x) 为分治重心的子树内,为此我们不能为节点开一个
map或者哈希表之类的玩意,这样也直接炸掉了。解决方案是注意到点分树的深度很小,所以直接记录每个格子属于哪个节点,以及每个节点在 (T’) 上深度为 (d) 的祖先编号。 - BFS 预处理 (d(a, x)) 和 (p(a, x)) 的时候,我们需要多次判断格子 (x) 的四周是否属于当前分治重心的子树。不能每次 BFS 到 (x) 再用
map之类的东西判断,因为 BFS 总复杂度是 (n\log n)。可以在一开始预处理每个格子四周是否有格子以及对应编号。
换句话说,只能在常数极小的树状数组处有 (\log ^ 2),其它地方能卡就卡,千万不要把别的地方也写成 (\log ^ 2) 或者常数极大的 (\log n) 了,这样铁定过不去。
代码。
高妙啊!高妙啊!
如果不添加任何 “返祖边”,原图的哈密顿路径只能形如 (1\to 2 \to \cdots \to n)。
添加返祖边 (x\to y(x > y)) 后,哈密顿路径形如
[1\xrightarrow{+1\ \mathrm {each\ time}} y – 1 \rightsquigarrow x \to y \rightsquigarrow x + 1 \xrightarrow{+1\ \mathrm {each\ time}} n ]
并且 (y – 1\to x) 和 (y\to x + 1) 的链不能有交,且并为 ([y – 1, x + 1])。
因此,如果记录了每个 ((y – 1, y)) 能否通过两条不交且并为 ([y – 1, x + 1]) 的链与 ((x, x + 1)) 连通(必须是对应位置 (y – 1) 和 (x),以及 (y) 和 (x + 1) 连通,即 ((, )) 是 有序对),就可以再检查 (1 \sim y – 2) 以及 (x + 1\sim n – 1) 是否均有 (i\to i + 1) 这条边,从而判断 (x\to y) 是否合法。
至此我们得到了 (x\to y) 合法的充要条件。
考虑枚举每个 ((y – 1, y)),看它的右边有多少个 ((x – 1, x)) 满足条件。考虑 (y – 1) 的所有不为 (y – 1 \to y) 的出边 (y – 1\to u),如果存在路径 (y\xrightarrow{+1\ \mathrm {each\ time}} u – 1),那么 ((y – 1, y)) 就能到达 ((u, u – 1)),同理 ((y, y – 1)) 能到达 ((u – 1, u))。
这样可以直接 DP(称为直接 bfs 似乎更合适),设 (f_{i, 0/1}) 分别表示从 ((y – 1, y)) 能否到达有序对 ((i, i + 1)) 或 ((i + 1, i)),转移若 (f_{i, t} = 1) 且 (i\to u + 1) 有边且存在链 (i + 1 \xrightarrow{+1\ \mathrm {each\ time}} u),那么 (f_{u, t\oplus 1}) 等于 (1)。最后一个条件可以对每个节点 (i) 维护最后一个 (j) 使得存在链 (i\xrightarrow{+1\ \mathrm {each\ time}} j),记做 (R_i),则该条件等价于 (R_{i + 1} \geq u)。
直接对每个 ((y – 1, y)) 都做一遍时间复杂度为 (\mathcal{O}(n ^ 2)),可以用 bitset 除掉 (w) 但仍然无法通过。
继续观察性质。我们发现在 (p\nrightarrow p + 1) 的位置 (p) 一定会产生一个断点,因为不存在 (i < p) 能转移到 (u > p)。对于 (j\leq p) 均有 (R_j \leq p),而 (i < p) 意味着 (i + 1\leq p),所以 (R_{i + 1}\leq p),与 (R_{i + 1}\geq u > p) 矛盾。
因此我们得到 (p) 左侧和 (p) 右侧是独立的。
不妨设 (p) 是所有这样的断点当中最小的一个。
修改状态设计,设 (f_{i, 0 / 1}) 分别表示从 ((p, p + 1)) 能否到达有序对 ((i, i + 1)) 或 ((i + 1, i)),初始值即 (f_{p, 0} = 1)(代码里面的状态定义是反过来的,不过问题不大,因为接下来的分析容易证明到达 ((i, i + 1)) 和 ((i + 1, i)) 是基本上等价的)。
根据 可达性的传递性,如果 ((p, p + 1)) 可达有序二元组 (x) 和 (y),那么 (x) 与 (y) 也相互可达。这说明 (x\to y(x\geq lst – 1 \land y\leq p + 1))(其中 (lst) 表示最后一个使得 (R_i = n) 的 (i),这是为了保证 (x + 1 \rightsquigarrow n),而由于 (p) 是最左侧的断点所以 (R_1 = p),为保证 (1\rightsquigarrow y – 1) 那么需要有 (y\leq p + 1))合法当且仅当 (f_{x, 0} \land f_{y – 1, 0}) 或者 (f_{x, 1} \land f_{y – 1, 1})。
进行一个容斥,用满足 (f_{x, 0}) 的 (x) 的个数乘以 (f_{y – 1, 0}) 的 (y – 1) 的个数,加上满足 (f_{x, 1}) 的 (x) 的个数乘以 (f_{y – 1, 1}) 的 (u – 1) 的个数。这样,满足 (f_{x, 0} \land f_{x, 1} \land f_{y – 1, 0} \land f_{y – 1, 1}) 的 (x, y) 对就会被算两次。所以,再减去满足 (f_{x, 0} \land f_{x, 1}) 的 (x) 的个数乘以 (f_{y – 1, 0} \land f_{y – 1, 1}) 的 (y) 的个数即可。
还有一些注意点。
- 当(y = 1) 时,(f_{y – 1, 0 / 1} = f_{0, 0 / 1}) 似乎没有定义,因为不存在节点(0),当(x = n) 时同理。一个解决办法是像 tourist 那样,把(y) 的枚举范围限制在(2\sim p + 1) 之间,(x) 的枚举范围限制在(lst – 1\sim n – 1) 之间,再单独考虑(y = 1) 和(x = n) 的情况,后者是 trivial 的。另一个解决办法是从(0) 向所有(1\sim n) 连边,并从(1\sim n) 向(n + 1) 连边,将原图不定起点终点的哈密顿路径转化为固定起点(0) 和终点(n + 1),使得(f_{0, 0 / 1}) 和(f_{n, 0 / 1}) 变得良定义(这才是添加虚点的有逻辑的解释好吧!某些题解一上来就添加虚点还不给解释就让人摸不着头脑)。
- 注意,当整张有向图只有(p\nrightarrow p + 1) 这一个断点时(等价描述是(R_{R_1 + 1} = n)),(p\to p + 1) 这条边会被算进答案(据枚举方式易得这一点),所以要特判减掉。
- 注意特判(R_1 = n) 的情况,此时答案即(\dbinom n 2)。
综上,总时间复杂度线性。
代码。
阴间毒瘤细节码农题,思维含量并不是太高。
首先,对于一次询问 (Q(u, v, l, r)),由于信息具有可减性,所以转化为 (Q(u, v, 1, r) – Q(u, v, 1, l – 1)),记作 (Q(u, v, r) – Q(u, v, l – 1))。这相当于做了一个扫描线。
求字符串出现次数自然考虑后缀数据结构。
对于后缀数组而言,对于特定 (t) 求解 (t) 在文本串 (s) 中出现次数的方法是二分找到第一个 (\geq t) 的后缀排名 (L),以及最后一个 (\leq t) 的后缀排名。显然,任何排名在 ([L, R]) 之间的后缀均以 (t) 为前缀,代表了 (t) 在 (s) 中的一次出现。
对于本题也一样。我们先对 (s_i) 进行后缀排序,设当前扫描线到位置 (p),则管用的只有 (s_1\sim s_p) 的后缀。对于一次询问 (Q(u, v, p)),我们只需要对 (u\to v) 形成的字符串 (t(u\to v)) 进行上述操作即可。
具体地,二分排名 (m),问题转化为比较 (t(u\to v)) 和排名为 (m) 的后缀 (s) 的大小关系。
一般的比较方法是二分 LCP 然后判下一个字符的大小关系。对于本题而言,如果再二分 LCP (len),那么需要求出 (s_{1\sim len}) 的哈希值,以及 (u\to v) 长度为 (len) 的前缀的哈希值,后者需要树上倍增求解(或者长链剖分可以做到 (\mathcal{O}(1)) 求 (k) 级祖先,配合树上哈希 (\mathcal{O}(1)) 求得哈希值,但是这样太麻烦了),时间复杂度 (\mathcal{O}(q\log ^ 3n)),常数还很大,显然过不去。
这个时候需要一点奇技淫巧(来自 ymx)。
我们对整棵树进行重链剖分。那么 (u\to v) 被剖成了若干段((\mathcal{O}(\log n)))在 dfn 上连续的区间 ([l_1, r_1], \cdots, [l_c, r_c])。我们可以先找出 LCP 落在哪个区间,再在该区间内二分。这样不仅好写,而且时间复杂度也是严格的 (\mathcal{O}(n\log ^ 2 n))。
求得 (t(u\to v)) 对应的排名区间 ([L, R]) 后,只需求出当中有多少个管用的后缀。扫描线时 BIT 维护即可。
以下是一些注意点。
- 哈希值每一位不能直接减去
a的 ASCII 值,否则aab和ab会被视作相等。 - base 应当大于多串 SA 插入分隔符的最大数值(虽然应该也不会卡这玩意)。
- 二分上下界注意!二分(L) 的时候下界为(1),上界为 SA 总长 加(1),(R) 的上下界则要减去(1)(这玩意调了我半个小时 =.=)。
- 注意排名和下标不要搞混了。
如果用 SAM 写,则需要快速定位一条链在 DAG 上的位置。这可以通过 DAG 链剖分实现,做到 (\mathcal{O}(q\log n))(我超,牛批),具体可见 FZzzz 神的博客。
代码。
Original: https://www.cnblogs.com/alex-wei/p/special_training_202204.html
Author: qAlex_Weiq
Title: 2022.4 专题题解汇总
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/642642/
转载文章受原作者版权保护。转载请注明原作者出处!