

本文参照:图像增强综述 – FANG_YANG – 博客园 (cnblogs.com)对传统图像增强方法做了总结,并把相关代码由matlab转成了python。
- 像素级方法
1.1图像反转
图像反转(Image Negative)在许多应用中都很有用,例如显示医学图像和用单色正片拍摄屏幕,其想法是将产生的负片用作投影片。
转换方程:T:G(x,y)=L−F(x,y),其中L是最大强度值,灰度图像L为255。
效果:


代码:
import cv2 as cv
fig = cv.imread('test1.jpg')
#图像反转
L = 255
fig1 = L - fig
cv.imshow('image',fig)
cv.imshow('image negative',fig1)
cv.waitKey(0)
cv.destroyAllWindows()
1.2. 对比度拉伸
低对比度的图像可能是由于光照不足,图像传感器缺乏动态范围,甚至在图像采集过程中透镜孔径设置错误。对比度拉伸(Contrast Stretching)背后的想法是增加图像处理中灰度的动态范围。
转换公式:G(x,y)=g1+(g2−g1)/(f2−f1)[F(x,y)−1],其中这里[f1,f2]为灰度在新范围[g1,g2]上的映射,这里f1为图像的最小强度值,f2为图像的最大强度值。该函数增强了图像的对比度,显示了均匀的强度分布。
效果:

代码:
import cv2
import numpy as np
img = cv2.imread("test2.jpg", 0)
Imax = np.max(img)
Imin = np.min(img)
MAX = 255
MIN = 0
img1 = (img - Imin) / (Imax - Imin) * (MAX - MIN) + MIN
cv2.imshow("img", img)
cv2.imshow("img_test", img1.astype('uint8'))#这个地方如果不转成深度为8的格式的话,由于原数据是小数的形式会导致图像显示错误
cv2.waitKey()
1.3. 动态范围压缩
有时,处理后的图像的动态范围远远超过显示设备的能力,在这种情况下,只有图像最亮的部分在显示屏上可见. 则需要对图像进行动态范围压缩(Compression of dynamic range)。
转换公式:s=clog(1+|r|), c是度量常数,是对数函数执行所需的压缩。r表示当前像素的灰度,s为转换后该像素的灰度。例如将以下图像的[0.255]压缩到[0,150],其中
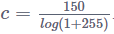 .
.
效果:

1.4. 灰度切片
灰度切片(Grey level slicing)相当于带通滤波的空间域。灰度切片函数既可以强调一组灰度值而减少其他所有灰度值,也可以强调一组灰度值而不考虑其他灰度值。例如对图像中灰度值为[100, 180]的区域进行强调,对其他区域进行抑制。
效果:

代码:
import cv2
import numpy as np
img = cv2.imread("test3.jpg", 0)
cv2.imshow("img", img)
h, w = img.shape
for i in range(h):
for j in range(w):
if 100<img[i][j]<180: img[i][j]="150" else: cv2.imshow("img_test", img) cv2.waitkey()< code></img[i][j]<180:>
1.5. 图像相减
图像相减是从另一个图像中减去一个像素或整个图像的数字数值的过程。这主要是出于两个原因——调平图像的不均匀部分和检测两幅图像之间的变化。一个常用的方法是从场景中减去背景光照的变化,以便更容易地分析其中的前景对象.例如在捕获过程中光照很差的文本,以便在整个图像中有很强的光照梯度,如果我们希望将前景文本从背景页面中分离出来,也许我们不能调整光照,但是我们可以在场景中放入不同的东西。例如,显微镜成像通常就是这样。所以我们用一张白纸替换文本,在不改变任何东西的情况下,我们捕捉到一个新的图像。我们可以从原始图像中减去光场图像,试图消除背景强度的变化。
效果:


代码:
import cv2
img = cv2.imread("test41.png", 0)
img1 = cv2.imread("test42.png", 0)
img2 = img1 - img
cv2.namedWindow("img",0)
cv2.resizeWindow('img', 400, 300)
cv2.namedWindow("img1",0)
cv2.resizeWindow('img1', 400, 300)
cv2.namedWindow("img_test",0)
cv2.resizeWindow('img_test', 400, 300)
cv2.imshow("img", img)
cv2.imshow("img1", img1)
cv2.imshow("img_test", img2)
cv2.waitKey()
1.6. 图像平均
图像平均是通过找到K个图像的平均值来获得的。应用于图像去噪。

效果:

1.7. 直方图
1.7.1 直方图均衡化
直方图均衡化是一种常用的图像增强技术。假设我们有一个主要是黑色的图像。然后它的直方图会向灰度的下端倾斜,所有的图像细节都被压缩到直方图的暗端。如果能将暗端的灰度”拉伸”,生成一个更均匀分布的直方图,那么图像就会清晰得多。

1.7.2 自适应直方图均衡化
直方图均衡化中,是直接对全局图像进行均衡化,是Global Histogram Equalization,而没有考虑到局部图像区域(Local Region),自适应直方图均衡化(AHE)就是在均衡化的过程中只利用局部区域窗口内的直方图分布来构建映射函数首先,最简单并且直接的想法,对A图像每个像素点进行遍历,用像素点周围W * W的窗口进行计算直方图变换的CDF(累计概率分布),然后对该像素点进行映射。[9]
1.7.3 Contrast Limited Adaptive Hitogram Equalization(CLAHE)
CLAHE相对于AHE,提出了两个改进的地方。
- 第一,提出一种限制直方图分布的方法。考虑图像A的直方图,设定一个阈值,假定直方图某个灰度级超过了阈值,就对 之进行裁剪,然后将超出阈值的部分平均分配到各个灰度级,这个过程可以用下图[10]来进行解释。图中左上图是原来的直方图分布,可以看出有两处峰值,其对应的CDF为左下图,可以看出有两段梯度比较大,变化剧烈。对于之前频率超过了阈值的灰度级,那么就把这些超过阈值的部分裁剪掉平均分配到各个灰度级上,如右上图,那么这会使得CDF变得较为平缓,如右下图。通常阈值的设定可以直接设定灰度级出现频数,也可以设定为占总像素比例,后者更容易使用。由于右下图所示的CDF不会有太大的剧烈变化,所以可以避免过度增强噪声点。[9]


实验结果(从左往右依次是原图,HE,CLAHE):

代码:
import cv2
def CLAHE(image):
clahe = cv2.createCLAHE(clipLimit=3, tileGridSize=(7,7))
dst = clahe.apply(image)
return dst
cv2.namedWindow("img",0)
cv2.resizeWindow('img', 400, 300)
cv2.namedWindow("img1",0)
cv2.resizeWindow('img1', 400, 300)
cv2.namedWindow("img2",0)
cv2.resizeWindow('img2', 400, 300)
img = cv2.imread("test42.png", 0)
cv2.imshow("img", img)
img1 = cv2.equalizeHist(img)
cv2.imshow("img1", img1)
img2 = CLAHE(img)
cv2.imshow("img2", img2)
cv2.waitKey(0)
- 掩模算子
掩模算子通过在图像上滑动掩模,将掩模值与落在它们下面的像素值相乘并获得总和,来执行掩模与图像的卷积。

2.1 图像平滑(均值滤波)

2.2 中值滤波
中值滤波是基于排序统计理论的一种能有效抑制噪声的非线性信号处理技术,中值滤波的基本原理是把数字图像或数字序列中一点的值用该点的一个邻域中各点值的中值代替,让周围的像素值接近的真实值,从而消除孤立的噪声点。
效果:(原图,均值滤波,中值滤波)

代码:
import cv2
img = cv2.imread("test41.png", 0)
img1 = cv2.blur(img,(5,5))
img2 = cv2.medianBlur(img, 5)
cv2.namedWindow("img",0)
cv2.resizeWindow('img', 400, 300)
cv2.namedWindow("img1",0)
cv2.resizeWindow('img1', 400, 300)
cv2.namedWindow("img2",0)
cv2.resizeWindow('img2', 400, 300)
cv2.imshow("img",img)
cv2.imshow("img1",img1)
cv2.imshow("img2",img2)
cv2.waitKey()
cv2.destroyAllWindows()
2.3 高斯滤波
高斯滤波就是对整幅图像进行加权平均的过程,每一个像素点的值,都由其本身和邻域内的其他像素值经过加权平均后得到。高斯滤波是一种线性平滑滤波,适用于消除高斯噪声,广泛应用于图像处理的减噪过程。

高斯滤波的重要两步就是先找到高斯模板然后再进行卷积,模板(mask在查阅中有的地方也称作掩膜或者是高斯核)。所以这个时候需要知道它怎么来?又怎么用?
举个栗子:
假定中心点的坐标是(0,0),那么取距离它最近的8个点坐标,为了计算,需要设定σ的值。假定σ=1.5,则模糊半径为1的高斯模板就算如下

这个时候我们我们还要确保这九个点加起来为1(这个是高斯模板的特性),这9个点的权重总和等于0.4787147,因此上面9个值还要分别除以0.4787147,得到最终的高斯模板。

有了高斯模板,那么高斯滤波的计算便顺风顺水了。
举个栗子:
假设现有9个像素点,灰度值(0-255)的高斯滤波计算如下:

将这9个值加起来,就是中心点的高斯滤波的值。
对所有点重复这个过程,就得到了高斯模糊后的图像。
效果:

代码:
img_guassian = cv2.imread("test5.jpg", 0)
img3 = cv2.GaussianBlur(img_guassian,(5,5),0)
cv2.imshow("img",img_guassian)
cv2.imshow("img3",img3)
cv2.waitKey()
cv2.destroyAllWindows()
2.4 图像锐化
图像锐化 _(image sharpening)_是补偿图像的轮廓,增强图像的边缘及灰度跳变的部分,使图像变得清晰,分为空间域处理和频域处理两类。图像锐化是为了突出图像上地物的边缘、轮廓,或某些线性目标要素的特征。这种滤波方法提高了地物边缘与周围像元之间的反差,因此也被称为边缘增强。

效果:

代码:
import cv2
import numpy as np
img = cv2.imread("test41.png", 0)
kernel = np.array([[0, -1, 0], [-1, 5, -1], [0, -1, 0]], np.float32) #定义一个核
img_test = cv2.filter2D(img, -1, kernel=kernel)
cv2.imshow("img",img)
cv2.imshow("img_test",img_test)
cv2.waitKey()
cv2.destroyAllWindows()
2.5 Derivative operations
常见的偏导算子有sobel算子和laplacian算子,sobel算子是一阶偏导算子,laplacian算子是二阶偏导算子。

sobel效果:

代码:
import cv2
img = cv2.imread("test41.png", 0)
x = cv2.Sobel(img, cv2.CV_16S, 1, 0)
y = cv2.Sobel(img, cv2.CV_16S, 0, 1)
absX = cv2.convertScaleAbs(x) # 转回uint8
absY = cv2.convertScaleAbs(y)
dst = cv2.addWeighted(absX, 0.5, absY, 0.5, 0)
cv2.imshow("img", img)
cv2.imshow("absX", absX)
cv2.imshow("absY", absY)
cv2.imshow("Result", dst)
cv2.waitKey(0)
cv2.destroyAllWindows()
'''
在Sobel函数的第二个参数这里使用了cv2.CV_16S。因为OpenCV文档中对Sobel算子的介绍中有这么一句:“in the case of 8-bit input images it will result in truncated derivatives”。即Sobel函数求完导数后会有负值,还有会大于255的值。而原图像是uint8,即8位无符号数,所以Sobel建立的图像位数不够,会有截断。因此要使用16位有符号的数据类型,即cv2.CV_16S。
在经过处理后,别忘了用convertScaleAbs()函数将其转回原来的uint8形式。否则将无法显示图像,而只是一副灰色的窗口。convertScaleAbs()的原型为:
dst = cv2.convertScaleAbs(src[, dst[, alpha[, beta]]])
其中可选参数alpha是伸缩系数,beta是加到结果上的一个值。结果返回uint8类型的图片。
由于Sobel算子是在两个方向计算的,最后还需要用cv2.addWeighted(...)函数将其组合起来。其函数原型为:
dst = cv2.addWeighted(src1, alpha, src2, beta, gamma[, dst[, dtype]])
其中alpha是第一幅图片中元素的权重,beta是第二个的权重,gamma是加到最后结果上的一个值。
'''
laplacian效果:

代码:
gray_lap = cv2.Laplacian(img, cv2.CV_16S, ksize=3)
dst = cv2.convertScaleAbs(gray_lap)
cv2.imshow("img", img)
cv2.imshow('laplacian', dst)
cv2.waitKey(0)
cv2.destroyAllWindows()
- Transform operations
这一节是将图片从空间域转到频域,在频域进行操作,公式表示为G(u,v)=F(u,v)H(u,v),F(u,v)是原图经过快速傅里叶变换转换(Fast Fourier Transform, 简称fft)到频域的频谱,H(u,v)是在频域执行的操作,G(u,v)是在频域处理后的频谱结果,最后G(u,v)可以通过快速傅里叶反变换(ifft)得到滤波的图像。
3.1 低通滤波
流程:1) 原始正常的图像,加噪处理,得到img_noise; 2) img_noise图像进行傅里叶变换,得到频谱; 3) 对得到的频谱进行理想低通滤波,低于截止频率d0d0的通过,高于的抑制; 4) 对滤波后的频谱进行反傅里叶变换,得到滤波后图像。[2]
效果:

3.2 高通滤波
高通滤波与低通滤波类似,区别在于低于截止频率的抑制,高于截止频率的通过。
效果:

3.3 带通滤波
带通滤波有两个截止频率d0d0, d1d1,其中d0d0是较低的频率,d1d1是较高的频率,图像频谱在[d0,d1][d0,d1]之间的通过,在区间之外的抑制。

3.4 同态滤波
同态滤波是把频率过滤和灰度变换结合起来的一种图像处理方法,它依靠图像的照度/ 反射率模型作为频域处理的基础,利用压缩亮度范围和增强对比度来改善图像的质量。使用这种方法可以使图像处理符合人眼对于亮度响应的非线性特性,避免了直接对图像进行傅立叶变换处理的失真。[8]
同态滤波的基本原理是:将像元灰度值看作是照度和反射率两个组份的产物。由于照度相对变化很小,可以看作是图像的低频成份,而反射率则是高频成份。通过分别处理照度和反射率对灰度值的影响,达到揭示阴影区细节特征的目的。[8]
流程:S(x,y)−−−>Log−−−>FFT−−−>filter−−−>IFFT−−−>Exp−−−>T(x,y)S(x,y)−−−>Log−−−>FFT−−−>filter−−−>IFFT−−−>Exp−−−>T(x,y)[8]

- Coloring Operations
4.1 False coloring
将彩色图像转换为灰度图像是一个不可逆的过程,灰度图像也不可能变换为原来的彩色图像。而某些场合需要将灰度图像转变为彩色图像;伪彩色处理主要是把黑白的灰度图像或者多波段图像转换为彩色图像的技术过程。其目的是提高图像内容的可辨识度。
伪彩色图像的含义是,每个像素的颜色不是由每个基色分量的数值直接决定,而是把像素值当作彩色查找表(事先做好的)的表项入口地址,去查找一个显示图像时使用的R,G,B强度值,用查找出的R,G,B强度值产生的彩色称为伪彩色。
效果:

代码:
import cv2
img = cv2.imread("test41.png", 0)
img1 = cv2.applyColorMap(img, 9)#OpenCV定义了12种colormap(色度图)0-11
cv2.imshow("img", img)
cv2.imshow("img1", img1)
cv2.waitKey(0)
cv2.destroyAllWindows()
4.2 Full color processing
上面处理的都是灰度图像,如果要处理全彩色图像,则需要对彩色的每个通道分别处理,然后叠加在一起。下面以均值滤波和中值滤波为例,对彩色图像进行处理。
效果:

代码:
import cv2
img = cv2.imread("test41.png")
img1 = cv2.blur(img,(5,5))
img2 = cv2.medianBlur(img, 5)
cv2.imshow("img",img)
cv2.imshow("img1",img1)
cv2.imshow("img2",img2)
cv2.waitKey()
cv2.destroyAllWindows()
- Retinex
视网膜-大脑皮层(Retinex)理论认为世界是无色的,人眼看到的世界是光与物质相互作用的结果,也就是说,映射到人眼中的图像和光的长波(R)、中波(G)、短波(B)以及物体的反射性质有关。基于这个理论,可以抽象下图中的公式I(x,y)=R(x,y)∙L(x,y),I(x,y)代表观察到的图像,R(x,y)代表物体的反射属性,L(x,y)代表物体表面的光照。

5.1 Single-Scale Retinex
在Retinex理论中,一个假定是光照I(x,y)是缓慢变化的,也就是低频的,要从I(x,y)中还原出R(x,y),所以可以通过低通滤波器得到光照分量。
具体做法:
- 对源公式两边同时取对数,得到log(R)=log(I)−log(L)
- 通过高斯模糊低通滤波器对原图进行滤波,公式为L=F∗I
- 得到L后,利用第一步的公式得到log(R),然后通过exp函数得到R
5.2 Multi-Scale Retinex
上面是单个尺度下的Retinex算法,当然也存在多尺度的Retinex算法,最为经典的就是3尺度的,大、中、小,既能实现图像动态范围的压缩,又能保持色感的一致性较好。[11]
具体做法: 对每个尺度分别进行单尺度的Retinex算法,将每个尺度的结果相加取平均得到最终结果(这里是简单地取权重相同,当然还可以设立权重不等).
5.3 Multi-Scale Retinex with Color Restoration
在前面的增强过程中,图像可能会因为增加了噪声,而使得图像的局部细节色彩失真,不能显现出物体的真正颜色,整体视觉效果变差。带色彩恢复因子C的多尺度算法是在多个固定尺度的基础上考虑色彩不失真恢复的结果,在多尺度Retinex算法过程中,通过引入一个色彩因子C来弥补由于图像局部区域对比度增强而导致的图像颜色失真的缺陷,通常情况下所引入的色彩恢复因子C的表达式为:

其中,Ci表示为第i个颜色通道地色彩恢复系数,它的作用是调节3个通道颜色的比例,f(⋅)表示颜色空间的映射函数,通常可以采用下面的形式:

其中,β是增益常数,α是受控制的非线性强度,带色彩恢复的多尺度Retinex算法通过色彩恢复因子C这个系数来调整原始图像中3个颜色通道之间的比例关系,从而把相对有点暗的区域的信息凸显出来,以达到消除图像色彩失真缺陷的目的。处理后的图像局域对比度得以提高,而且其亮度与真实的场景很相似,图像在人们的视觉感知下显得更为逼真。因此,MSRCR算法会具有比较好的颜色再现性、亮度恒常性与动态范围压缩等特性。[12]
效果:从左到右——原图,SSR,MSR,MSRCR

代码:
import argparse
import numpy as np
import cv2
def singleScaleRetinexProcess(img, sigma):
temp = cv2.GaussianBlur(img, (0, 0), sigma)
gaussian = np.where(temp == 0, 0.01, temp)
retinex = np.log10(img + 0.01) - np.log10(gaussian)
return retinex
def multiScaleRetinexProcess(img, sigma_list):
retinex = np.zeros_like(img * 1.0)
for sigma in sigma_list:
retinex = singleScaleRetinexProcess(img, sigma)
retinex = retinex / len(sigma_list)
return retinex
def colorRestoration(img, alpha, beta):
img_sum = np.sum(img, axis=2, keepdims=True)
color_restoration = beta * (np.log10(alpha * img) - np.log10(img_sum))
return color_restoration
def multiScaleRetinexWithColorRestorationProcess(img, sigma_list, G, b, alpha, beta):
img = np.float64(img) + 1.0
img_retinex = multiScaleRetinexProcess(img, sigma_list)
img_color = colorRestoration(img, alpha, beta)
img_msrcr = G * (img_retinex * img_color + b)
return img_msrcr
def simplestColorBalance(img, low_clip, high_clip):
total = img.shape[0] * img.shape[1]
for i in range(img.shape[2]):
unique, counts = np.unique(img[:, :, i], return_counts=True)
current = 0
for u, c in zip(unique, counts):
if float(current) / total < low_clip:
low_val = u
if float(current) / total < high_clip:
high_val = u
current += c
img[:, :, i] = np.maximum(np.minimum(img[:, :, i], high_val), low_val)
return img
def touint8(img):
for i in range(img.shape[2]):
img[:, :, i] = (img[:, :, i] - np.min(img[:, :, i])) / \
(np.max(img[:, :, i]) - np.min(img[:, :, i])) * 255
img = np.uint8(np.minimum(np.maximum(img, 0), 255))
return img
def SSR(img, sigma=300):
ssr = singleScaleRetinexProcess(img, sigma)
ssr = touint8(ssr)
return ssr
def MSR(img, sigma_list=[15, 80, 250]):
msr = multiScaleRetinexProcess(img, sigma_list)
msr = touint8(msr)
return msr
def MSRCR(img, sigma_list=[15, 80, 250], G=5, b=25, alpha=125, beta=46, low_clip=0.01, high_clip=0.99):
msrcr = multiScaleRetinexWithColorRestorationProcess(img, sigma_list, G, b, alpha, beta)
msrcr = touint8(msrcr)
msrcr = simplestColorBalance(msrcr, low_clip, high_clip)
return msrcr
def main():
ap = argparse.ArgumentParser()
ap.add_argument('--image', required=True)
args = vars(ap.parse_args())
image = cv2.imread(args["image"])
ssr = SSR(image)
msr = MSR(image)
msrcr = MSRCR(image)
cv2.namedWindow("Retinex", 0)
cv2.resizeWindow('Retinex', 1400, 300)
cv2.imshow("Retinex", np.hstack([image, ssr, msr, msrcr]))
cv2.waitKey(0)
if __name__ == "__main__":
main()
- Dark Channel Prior
暗通道先验(Dark Channel Prior)是说在绝大多数非天空的局部区域内,某一些像素至少一个颜色通道具有很低的值,这是何凯明等人基于5000多张自然图像的统计得到的定理。根据这一定理,何凯明等人提出了暗通道先验的去雾算法[13],
以自然图像和雾气图像为例[14](左边是原图,右边是暗通道):


暗通道先验公式如下所示:

上述公式的意义用代码表达也很简单,首先求出每个像素RGB分量中的最小值,存入一副和原始图像大小相同的灰度图中,然后再对这幅灰度图进行最小值滤波,滤波的半径由窗口大小决定。暗通道先验的理论指出:Jdark→0
去雾公认的模型为:

其中I为观测强度,J为场景亮度,A为全球大气光,t为描述非散射到达相机的光部分的介质透射率。去雾的目的是从I中恢复无雾的J.
对上述公式进行变形,得到如下公式:

上标c表示RGB三个通道的意思,假设t在一个窗口下为常数,对上述公式两边同时取两次最小值,得到:

根据暗原色先验理论有:

所以前述公式可以化简为:

在现实生活中,即使是晴天白云,空气中也存在着一些颗粒,因此,看远处的物体还是能感觉到雾的影响,另外,雾的存在让人类感到景深的存在,因此,有必要在去雾的时候保留一定程度的雾,这可以通过在上述式子中引入一个在[0,1] 之间的因子,则上式修正为:

论文中给出的ω等于0.95,对A,论文中给出了一个计算方法: 从暗通道图中按照亮度的大小取前0.1%的像素,在这些位置中,在原始有雾图像I中寻找对应的具有最高亮度的点的值,作为A值。这样A知道了,利用上述公式t也就知道了,在根据原始去雾公式,J也就可以计算了。公式为J=(I−A)/t+A。
当t 的值很小时,会导致J的值偏大,从而使得图像整体向白场过度,因此一般可设置一阈值t0,当t值小于t0时,令t=t0,论文中取t0=0.1。

下面实现了一个最简单的版本,简化了很多,没有取窗口,没有用导向滤波等等,更多复杂的操作参考原始论文[13]。
效果:

代码:
import cv2
import argparse
import numpy as np
def hazeRemoval(img, w=0.7, t0=0.1):
#求每个像素的暗通道
darkChannel = img.min(axis=2)
#取暗通道的最大值最为全球大气光
A = darkChannel.max()
darkChannel = darkChannel.astype(np.double)
#利用公式求得透射率
t = 1 - w * (darkChannel / A)
#设定透射率的最小值
t[t < t0] = t0
J = img
#对每个通道分别进行去雾
J[:, :, 0] = (img[:, :, 0] - (1 - t) * A) / t
J[:, :, 1] = (img[:, :, 1] - (1 - t) * A) / t
J[:, :, 2] = (img[:, :, 2] - (1 - t) * A) / t
return J
def main():
ap = argparse.ArgumentParser()
ap.add_argument('--image', required=True)
args = vars(ap.parse_args())
hazeImage = cv2.imread(args["image"])
result = hazeRemoval(hazeImage.copy())
cv2.imshow("HazeRemoval", np.hstack([hazeImage, result]))
cv2.waitKey(0)
if __name__ == '__main__':
main()
Original: https://blog.csdn.net/xspyzm/article/details/116995049
Author: ,
Title: 传统图像增强算法python实现
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/642464/
转载文章受原作者版权保护。转载请注明原作者出处!