

Encoder · overall
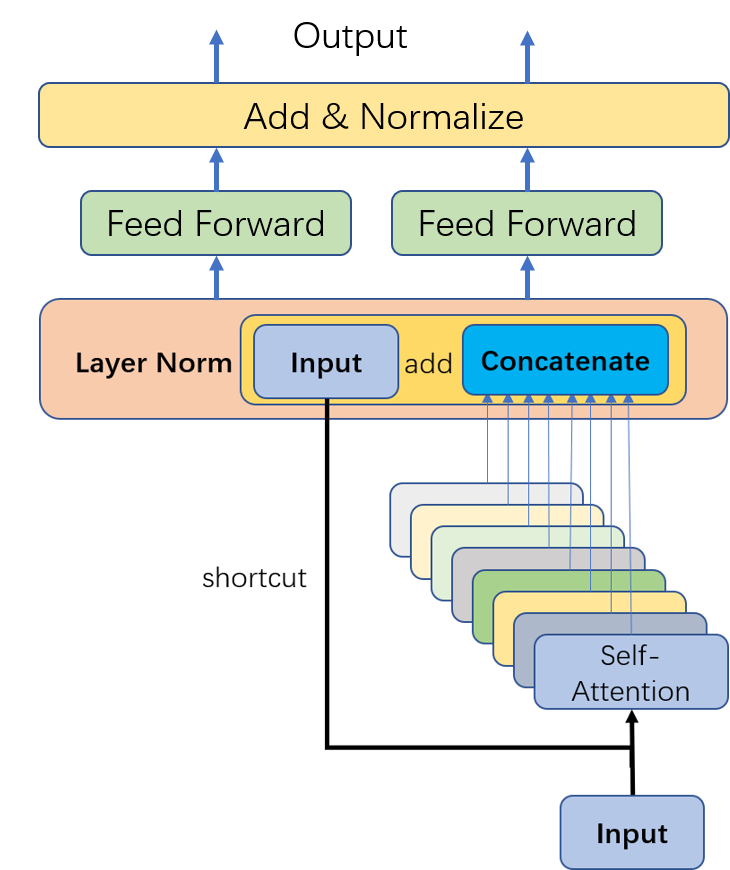

整个Encoder分为输入,自注意力,layer normalization 和 前馈网络几个大步组成;接下来细致地分块理一理几个步骤地具体操作是如何完成的;
; Patch Embedding
在Vision Transformer开始,大家习惯上将一张图像分割为一个个的patch,
Linear Transformation
define:Inputs[batch, patch, dimension] = Inputs[b, m, n] = X[b, m, n];
通常我们将输入的图像打成patches,经过patch embedding,每一个patch会变换成一个长度为n的token,一共有m个tokens,我们一次并行处理b个图像,因此我们用上面式子中的b,m,n分别表示batch size为b,tokens(patches)数目为m,每一个tokens的序列长度为n;
经过patch embedding,我们将 Images[batch,3,H,W]的图像表示映射到了Inputs[b,m,n]token表示;接下来我们方便起见将Inputs表示为X[b, m, n];
我们会初始化三个权重矩阵Wq,Wk,Wv,这三个权重矩阵用于做线性变换,并且这三个矩阵的参数是学习(training)得到的,分别是

经过这样一个线性变换,我们将输入的token序列变换到了其他的特征空间;需要注意我们在这里描述的是自注意力机制,因此Wk和Wv对应的输入是相同的,对于NLP中的Transformer·Encoder是有些不同的,如下图;

需要指出的是,目前的常规操作是我们会保持输入和输出tokens的dimension是相同的,因此我们会将Wq,Wk,Wv的size设置为nxn,因此可以得出,经过linear transformation,我们得到的Query,Key,Value三个的维度关系是
X[b, m, n] · Wq[n, n] = Query[b, m, n] X[b, m, n] · Wk[n, n] = Key[b, m, n] X[b, m, n] · Wv[n, n] = Value[b, m, n]
; self-Attention
当我们经过Linear Transformation,我们得到了输入X的三种特征表示,或者说是三种状态空间下的表示,分别是Query,Key,Value;接下来我们需要实施一次”注意力”机制;所谓的注意力机制就是我们希望通过权重分配得到对重要特征的关注,在这篇不进行所谓原理的理解和解释,旨在代码操作层面和维度变换这两个角度上进行梳理,因此我们暂且不关心具体的道理;需要注意dk是每一个Head下的维度;
O u t p u t s = s o f t m a x ( Q ⋅ K T d k ) ⋅ V Outputs = softmax(\frac {Q·K^T}{\sqrt{d_k}})·V O u t p u t s =s o f t m a x (d k Q ⋅K T )⋅V
维度变换:Q [ b , m , n ] ⋅ K T [ b , n , m ] = y [ b , m , m ] Q[b, m, n] · K^T[b, n , m] = y[b, m, m]Q [b ,m ,n ]⋅K T [b ,n ,m ]=y [b ,m ,m ]
我们对得到的y先进行一次逐元素的放缩,然后经过一个softmax得到attention map,y i [ m , m ] y_i[m,m]y i [m ,m ],可以认为维度是m x m的原因如下:每一个token需要计算和其他所有token(包括自身)的相似性,而每一个token都进行一次这样的操作,那么得到了mxm个注意力得分;可以看到计算复杂度是相当高的,这也是之后很多工作想办法解决的问题;
最后和V进行逐元素的相乘得到输出;
y [ b , m , m ] ⋅ V [ b , m , n ] = O u t p u t s [ b , m , n ] y[b,m,m]·V[b,m,n] = Outputs[b,m,n]y [b ,m ,m ]⋅V [b ,m ,n ]=O u t p u t s [b ,m ,n ]
import torch
import torch.nn as nn
class ScaledDotProductAttention(nn.Module):
"""Scaled dot-product attention mechanism."""
def __init__(self, attention_dropout=0.0):
super(ScaledDotProductAttention, self).__init__()
# 初始化dropout和softmax函数;
self.dropout = nn.Dropout(attention_dropout)
self.softmax = nn.Softmax(dim=2) # 在每一个token内部进行计算;
def forward(self, q, k, v, scale=None, attn_mask=None):
"""前向传播.
Args:
q: Queries张量,形状为[b, m, n]
k: Keys张量,形状为[b, m, n]
v: Values张量,形状为[b, m, n]
scale: 缩放因子,一个浮点标量
attn_mask: Masking张量,形状为[b, m, n]
Returns:
上下文张量和attetention张量
"""
attention = torch.bmm(q, k.transpose(1, 2))
if scale:
attention = attention * scale
if attn_mask:
# 给需要mask的地方设置一个负无穷
attention = attention.masked_fill_(attn_mask, -np.inf)
# 计算softmax
attention = self.softmax(attention)
# 添加dropout
attention = self.dropout(attention)
# 和V做点积
context = torch.bmm(attention, v)
return context, attention
softmax 以及 bmm函数说明
import torch
import torch.nn as nn
生成 2x4 tensor
x = torch.arange(1,9).view(2,4)*1.0
net1 = nn.Softmax(dim=0) # 函数初始化
net2 = nn.Softmax(dim=1)
y1 = net1(x)
y2 = net2(x)

可以看到,当指定沿着某一维度进行softmax的时候,会计算其他维度的一个平均值,然后使用softmax 函数进行计算;
x = torch.arange(1,25).view(2,3,4)*1.0
map = torch.ones(2,4,1)*0.5
y = torch.bmm(x,map)
print(x)
print(y)

可以看到,torch.bmm这个操作是将3维的一个tensor保留第0维度,在第一维度和第二维度构成的矩阵上进行矩阵乘法;
Multi-head attention
所谓多头注意力是指,作者发现将线性变换后得到的Q,K,V分成h份,然后对每一份内部实施自注意力机制效果更好;
先将Q,K,V进行分组,经过scaled dot-product attention 之后,将不同的head得到的Outputs concatenate在一起,得到Multi-head 输出;
维度变换
b, m, n, heads = 3, 2, 3, 2
x = torch.arange(1,b*m*n+1).view(b,m,n)*1.0
dim_per_heads = n
x_heads = x.view(b*heads,-1,dim_per_heads)
print(x)
print(x_heads)

总体上保证了view后所有元素都被保留了,三个维度可能都会有所变化;
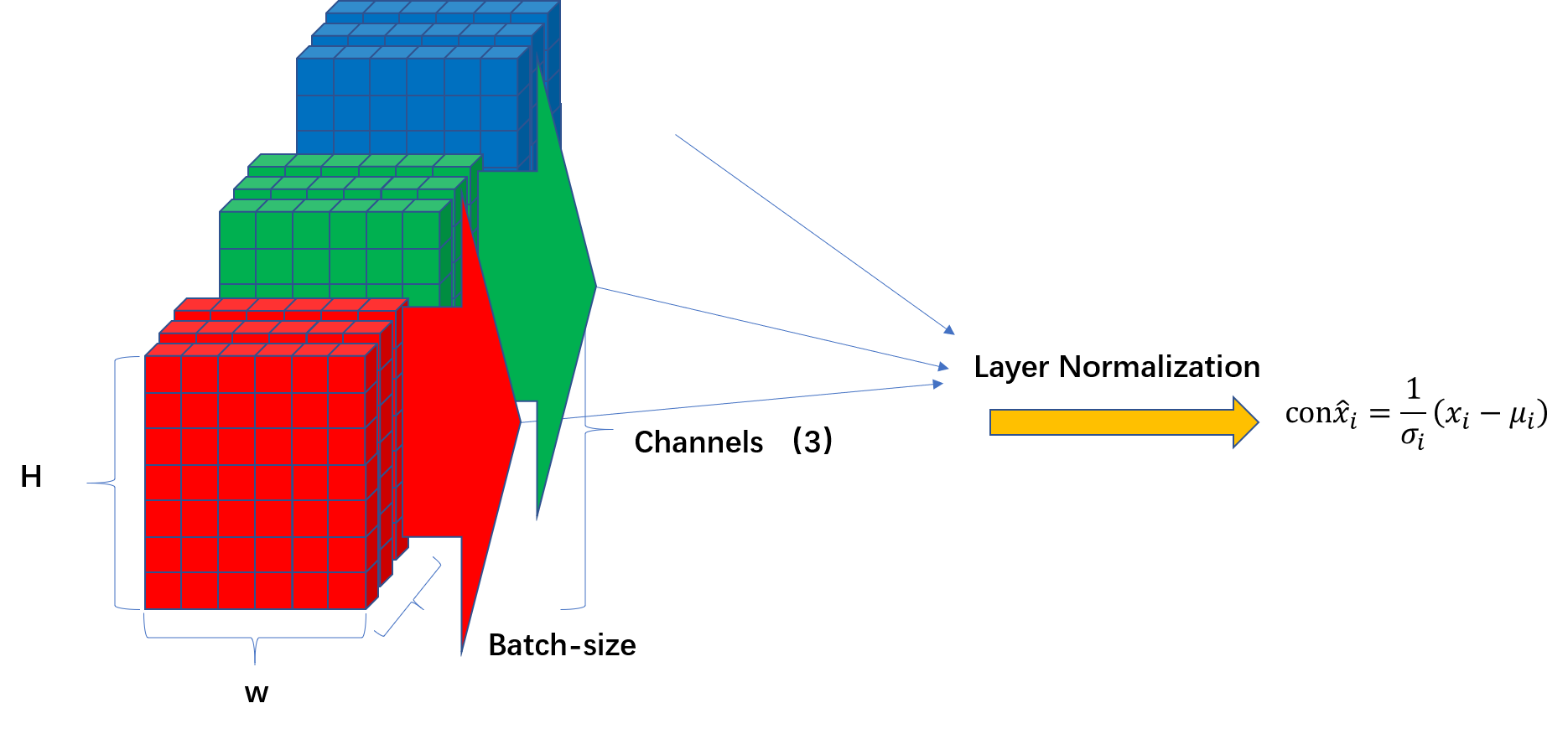
Layer Normalization & Residual connection
多头注意力得到的输出concatenate在一起之后,会经过一个线性映射,然后加上原始的输入,再进行一个layer normalization;
import torch
import torch.nn as nn
class LayerNorm(nn.Module):
"""实现LayerNorm。其实PyTorch已经实现啦,见nn.LayerNorm。"""
def __init__(self, features, epsilon=1e-6):
"""Init.
Args:
features: 就是模型的维度。论文默认512
epsilon: 一个很小的数,防止数值计算的除0错误
"""
super(LayerNorm, self).__init__()
# alpha
self.gamma = nn.Parameter(torch.ones(features))
# beta
self.beta = nn.Parameter(torch.zeros(features))
self.epsilon = epsilon
def forward(self, x):
"""前向传播.
Args:
x: 输入序列张量,形状为[B, L, D]
"""
# 根据公式进行归一化
# 在X的最后一个维度求均值,最后一个维度就是模型的维度
mean = x.mean(-1, keepdim=True)
# 在X的最后一个维度求方差,最后一个维度就是模型的维度
std = x.std(-1, keepdim=True)
return self.gamma * (x - mean) / (std + self.epsilon) + self.beta

FFN
经过layer normalization 之后,需要再经过一个Feed Forward Network;
F F N ( x ) = m a x ( 0 , 𝑥 𝑊 1 + 𝑏 1 ) 𝑊 2 + 𝑏 2 FFN (x)=max(0,𝑥𝑊_1+𝑏_1)𝑊_2+𝑏_2 F F N (x )=m a x (0 ,x W 1 +b 1 )W 2 +b 2
import torch
import torch.nn as nn
class PositionalWiseFeedForward(nn.Module):
def __init__(self, model_dim=512, ffn_dim=2048, dropout=0.0):
super(PositionalWiseFeedForward, self).__init__()
self.w1 = nn.Conv1d(model_dim, ffn_dim, 1)
self.w2 = nn.Conv1d(model_dim, ffn_dim, 1)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(model_dim)
def forward(self, x):
output = x.transpose(1, 2)
output = self.w2(F.relu(self.w1(output)))
output = self.dropout(output.transpose(1, 2))
# add residual and norm layer
output = self.layer_norm(x + output)
return output
reference
Transformer的PyTorch实现
深度学习attention机制中的Q,K,V分别是从哪来的?
Original: https://blog.csdn.net/weixin_46257458/article/details/124308251
Author: M宝可梦
Title: Encoder in Vision Transformer
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/641682/
转载文章受原作者版权保护。转载请注明原作者出处!