

最近做作业看到了一篇挺有意思的文章《Pose-Controllable Talking Face Generation by Implicitly Modularized Audio-Visual Representation》。文章开发了一个说话人脸生成工具,可以由视频和音频共同驱动
Zhou, H., Sun, Y., Wu, W., Loy, C. C., Wang, X., & Liu, Z. (2021). Pose-controllable talking face generation by implicitly modularized audio-visual representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4176-4186).
简单记录一下
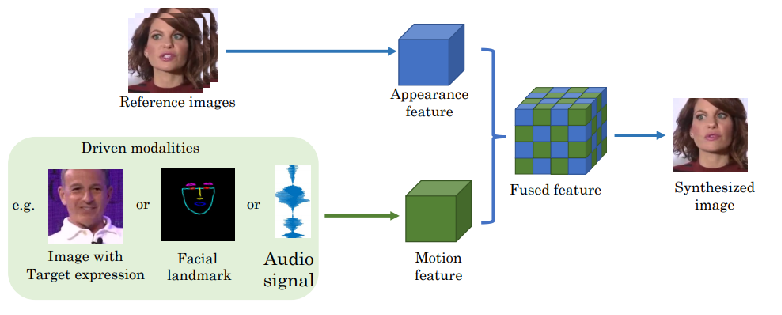
说话人脸合成的基本框架

Chen, L., Cui, G., Kou, Z., Zheng, H., & Xu, C. (2020). What comprises a good talking-head video generation?: A survey and benchmark. arXiv preprint arXiv:2005.03201.
- 由静态人脸生成一个人脸特征(向量或矩阵)
- 由驱动源(人脸特征或者音频特征)生成动作特征(向量或矩阵)
- 将两个特征融合,再送给某生成式模型(通常是GAN)合成人像
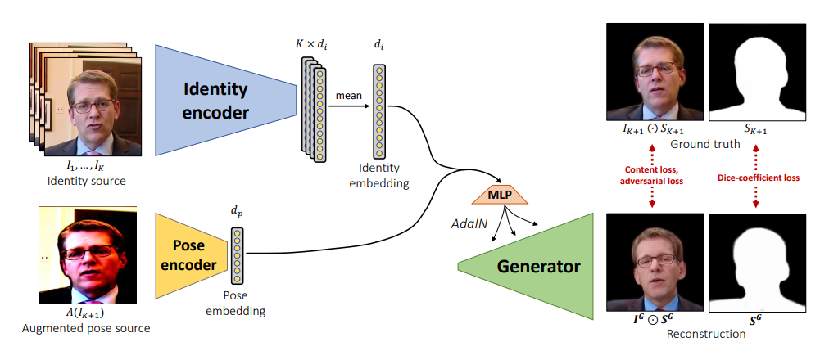
; 由动态姿态控制静态图片姿态的方法
Burkov, E., Pasechnik, I., Grigorev, A., & Lempitsky, V. (2020). Neural head reenactment with latent pose descriptors. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 13786-13795).
- 将人脸特征嵌入到一个Identity embedding向量,将姿态信息嵌入到Pose embedding向量,
- 两个向量利用一个MLP融合
- 将融合向量送入StyleGAN重建具有姿态信息的人像
由音频和姿态共同驱动的说话人脸生成
这部分就是开头那篇文章《Pose-Controllable Talking Face Generation by Implicitly Modularized Audio-Visual Representation》
动机
- 针对任意人的、以其音频驱动的说话人脸生成研究方向,已实现了较准确的唇形同步,但头部姿势的对齐问题依旧不理想
- 此前的方法依赖于预先估计的结构信息,例如关键点和3D参数。但极端条件下这种估计信息不准确则效果不佳
贡献
- 提供了一种由音频控制嘴唇,由视频控制姿态的说话人脸生成方式
示例
环境配置

从左到右依次是
- 静态人脸
- 生成结果
- 姿态信息
- 语音源
; 方法框架
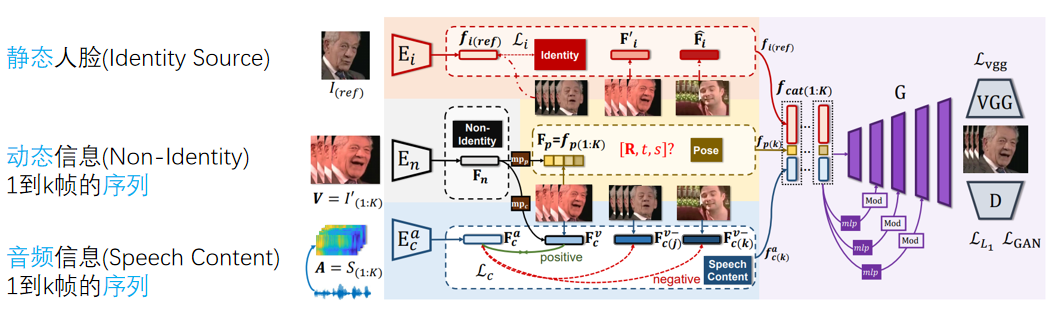
- 对于每个固定的帧,将三种特征向量(Embedding)顺序拼接(concate)为一个长特征(上图中的fcat部分)
- 由MLP融合后送入GAN重建人脸
Original: https://blog.csdn.net/qq_42138454/article/details/123884887
Author: 此方家的空腹
Title: 一种由视频和音频共同驱动的说话人脸合成方法简介
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/640406/
转载文章受原作者版权保护。转载请注明原作者出处!