

缺失值识别
数据缺失分为两种:一是行记录的缺失;二是列值的缺失。
不同的数据存储和环境中对于缺失值的表示不同,例如数据库中是Null、Python返回对象是None、Pandas或Numpy中是NaN。
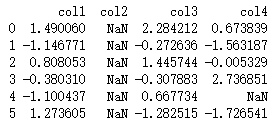
构造数据:
#导入相关库
import pandas as pd
import numpy as np
生成缺失数据
df = pd.DataFrame(np.random.randn(6, 4),
columns=['col1', 'col2', 'col3', 'col4'])
df.iloc[:, 1] = np.nan
df.iloc[4, 3] = np.nan
print(df)

查看缺失值:
查看哪些值缺失,缺失值返回True
nan_all = df.isnull()
print(nan_all)
print()
查看哪些列缺失
nan_col1 = df.isnull().any() # 含有NA的列返回True
nan_col2 = df.isnull().all() # 全部为NA的列返回True
print(nan_col1)
print(nan_col2)
print()
查看哪些行缺失
nan_row1 = df.isnull().any(axis=1) # 含有NA的行返回True
nan_row2 = df.isnull().all(axis=1) # 全部为NA的行返回True
print(nan_row1)
print(nan_row2)
print()

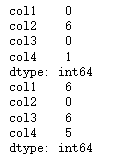
查看每列缺失值个数
print(df.isnull().sum())
查看每列未缺失值个数,等价于df.count()
print(df.notnull().sum())
缺失值处理方式
通常有四种思路:
1.丢弃
直接丢弃带有缺失值的行记录(整行删除)或者列字段(整列删除)。优点:方法简单明了,减少缺失数据对总体数据的影响。缺点:会消减数据特征。
以下任意一种场景都不宜丢弃缺失值:
- 数据集总体中存在大量的数据记录不完整情况且比例较大,例如超过10%,删除这些带有缺失值的记录意味着将会损失过多有用信息。
- 带有缺失值的数据记录存在着明显的数据分布规律或特征,例如带有缺失值的数据记录的目标标签主要集中于某一类或几类,如果删除这些数据记录将使对应分类的数据样本丢失大量特征信息,导致模型过拟合或分类不准确。
丢弃缺失值
print(df.dropna()) # 直接丢弃含有NA的行记录,默认axis=0,how='any'
print(df.dropna(how='all')) # 直接丢弃全部值为NA的行记录
print(df.dropna(axis=1)) # 直接丢弃含有NA的列记录
print(df.dropna(axis=1,how='all')) # 直接丢弃全部值为NA的列记录

2.补全
相对丢弃而言,补全是更加常用的缺失值处理方式,通过一定的方法将缺失的数据补上,从而形成完整的数据记录,对于后续的数据处理、分析和建模至关重要。
常用的补全方法包括:
- 统计法:对于数值型的数据,使用均值、加权均值、中位数等方法补足;对于分类型数据,使用众数等方法补足。
- 模型法:可以基于已有的其他字段,将缺失字段作为目标变量进行预测,从而得到较为可能的补全值。如果带有缺失值的列是数值变量,采用回归模型补全;如果是分类变量,则采用分类模型补全。
- 专家补全:对于少量且具有重要意义的数据记录,专家补足也是非常重要的一种途径。
- 其他方法:例如随机法、特殊值法、多重填补等。
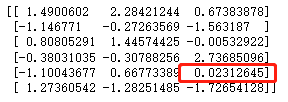
引入sklearn包
from sklearn.impute import SimpleImputer
建立模型规则:strategy默认mean,也可设置为median或most_frequent
nan_model = SimpleImputer(missing_values=np.nan, strategy='mean')
nan_result = nan_model.fit_transform(df)
print(nan_result)
#由于col2列全部为nan值,无法应用模型规则,col4列缺失值可以应用模型规则
使用pandas替换缺失值
用后面的值替换缺失值,或者用bfill
print(df.fillna(method='backfill'))
用后面的值替代缺失值,限制每列只能替代一个缺失值
print(df.fillna(method='backfill', limit=1))
用前面的值替换缺失值,或者用ffill
print(df.fillna(method='pad'))
用特定值替换缺失值,比如0,也可直接使用df.replace(np.nan,0)
print(df.fillna(0))
fillna函数传入字典,用不同值替换不同列的缺失值
print(df.fillna({'col2': 1.1, 'col4': 1.2}))
用平均数mean代替,选择各自列的均值替换缺失值,也可用中位数median或众数mode
print(df.fillna(df.mean()))
插值填充,默认线性填充
print(df.interpolate())
3.真值转换法
某些情况下,我们可能无法得知缺失值的分布规律,并且对于缺失值无法采用上述任何一种方法做处理;或者我们认为数据缺失也是一种规律,不应该轻易对缺失值随意处理,那么还有一种缺失值处理思路——真值转换。
数据缺失也是数据分布规律的一部分,将变量的实际值和缺失值都作为输入维度参与后续数据处理和模型计算中,然而缺失值通常无法参与直接运算,因此需要将缺失值进行真值转换。
4.不处理
在数据预处理阶段,对于具有缺失值的数据记录不作任何处理,也是一种思路。很多模型对于缺失值有容忍度或灵活的处理方法,因此在预处理阶段可以不做处理。
常见的能够自动处理缺失值的模型包括:KNN、决策树和随机森林、神经网络和朴素贝叶斯、DBSCAN等。这些模型对于缺失值的处理思路是:
- 忽略,缺失值不参与距离计算,例如KNN。
- 将缺失值作为分布的一种状态,并参与到建模过程,例如各种决策树及其变体。
- 不基于距离做计算,因此基于值的距离计算,本身的影响就消除了,例如DBSCAN。
说明:在数据建模前的特征选择阶段,假如我们通过一定方法确定带有缺失值的字段对于模型的影响非常小,那么我们根本就不需要对缺失值进行处理。因此,后期建模时的字段或特征的重要性判断也是决定是否处理字段缺失值的重要参考因素之一。
参考资料:《Python数据分析与数据化运营》宋天龙
Original: https://blog.csdn.net/sinat_41928169/article/details/124417344
Author: 大哇唧
Title: 数据清洗:缺失值识别和处理方法
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/640090/
转载文章受原作者版权保护。转载请注明原作者出处!