

🌠 『精品学习专栏导航帖』
- 🐳最适合入门的100个深度学习实战项目 🐳
- 🐙【PyTorch深度学习项目实战100例目录】项目详解 + 数据集 + 完整源码 🐙
- 🐶【机器学习入门项目10例目录】项目详解 + 数据集 + 完整源码 🐶
- 🦜【机器学习项目实战10例目录】项目详解 + 数据集 + 完整源码 🦜
- 🐌Java经典编程100例 🐌
- 🦋Python经典编程100例 🦋
- 🦄蓝桥杯历届真题题目+解析+代码+答案 🦄
- *🐯【2023王道数据结构目录】课后算法设计题C、C++代码实现完整版大全 🐯
文章目录


简 介:下面是我在学习时候的记录并加上自己的理解。本文意在记录自己近期学习过程中的所学所得,如有错误,欢迎大家指正。
关键词:Python、机器学习、K-Means聚类
; 一、K-Means聚类
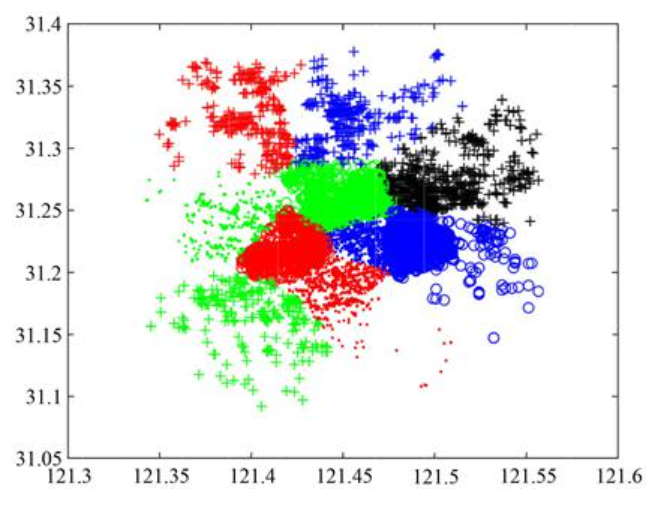
其实它是一种基于质心的聚类,为什么这么说呢?因为它的设计思想就是从总样本中找到几个标志性的数据,将其定为每个簇的数据中心,然后分别判断每个数据的距离状况,然后进行更新每个簇内的质心。
对于样本集 D = { x 1 , x 2 . . . x n } D={x_1,x_2…x_n}D ={x 1 ,x 2 …x n } 来说,我们要将其分成k个数据簇,也就是对应 C = { C 1 , C 2 , . . . C k } C={C_1,C_2,…C_k}C ={C 1 ,C 2 ,…C k } ,如果是这样,那么我们的目标优化函数就是:
E = ∑ i = 1 k ∑ x ∈ C i ∣ ∣ x − μ i ∣ ∣ 2 2 E=\sum_{i=1}^k\sum_{x\in C_i}||x-\mu_i||_2^2 E =i =1 ∑k x ∈C i ∑∣∣x −μi ∣∣2 2
我们就是要优化该函数,也就是要E越小越好,但是该函数我们是很难进行优化的,因为如果我们要想计算出它的最优解,那么就要穷举出所有的簇分类可能,但是这在实际中是很难进行的,所以就要考虑局部最优采用贪心算法进行优化,我们每次只是进行更新该簇内的质心,然后不断迭代此过程。
二、算法详细流程
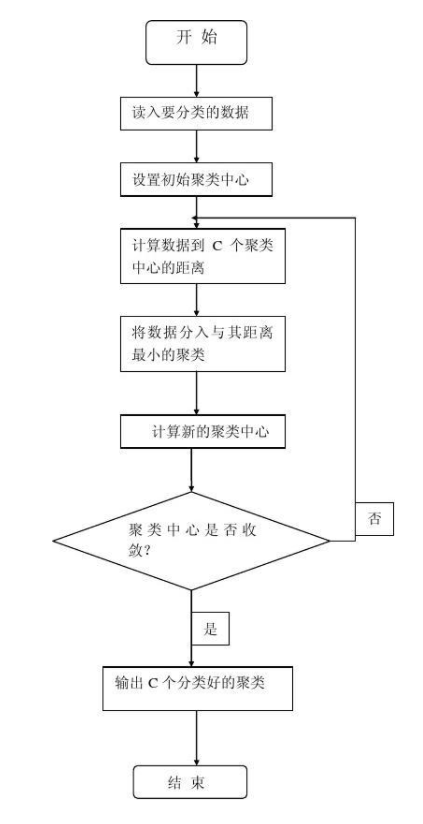
- 首先确定样本集和待划分的簇类数k
- 从样本集中随机初始k个数据中心点
- 迭代每一个样本,计算每一个样本对k个数据中心的距离
- 标记样本为距离该样本最近的类别簇中
- 第一轮遍历数据完成,所有的样本已经找到了自己所属的簇,但这还不是最终的类别,所以还要进行第二轮迭代
- 在第二轮迭代之前,需要更新每个簇内的质心
- 计算每个簇内的质心μ = 1 C ∑ x ∈ C x \mu=\frac{1}{C}\sum_{x\in C}x μ=C 1 ∑x ∈C x
- 然后重复3-7的步骤,知道达到预期迭代次数或者两次迭代结果,簇内数据不发生任何变化

算法实现需要注意的几个问题:
- 类中心向量的初值一般是采用随机初始化的,所以这可能导致每一次的模型聚类效果不同,因为算法内部使用了采用贪心,所以可能导致每次的效果分类不一样。
- 簇的个数的确定,因为簇的个数事先是无法确定的,我们也不清楚到底将数据分为几个类别,所以我们需要不断地调整k的个数,来判断聚类的效果
- 迭代终止原则,一般是会定义一个阈值,如果我们两次迭代后发现每个簇的类中心的变化距离小于我们设定的阈值,就说明本次迭代没有发生较大的数据变动,则迭代终止。
写在最后
大家好,我是阿光,觉得文章还不错的话,记得”一键三连”哦!!!
以上是我在读这本书的时候的记录并加上自己的理解。本文意在记录自己近期学习过程中的所学所得,如有错误,欢迎大家指正。

Original: https://blog.csdn.net/m0_47256162/article/details/118831353
Author: 雷 神
Title: 【机器学习】聚类算法——K-Means算法(理论+图解)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/639974/
转载文章受原作者版权保护。转载请注明原作者出处!