

爬取某家网二手房数据(详细教程)
今天分享一篇爬虫教程,文章比较细致,适合刚上手的小白,老读者可以酌情加速阅读
文中涉及的代码已经测试过,可以正常跑通,文章案例的所有数据也已经成功爬取。
项目描述:
今天要分享的教程是爬取各大城市的二手房数据,实现这篇爬虫也可融汇贯通到其他相关项目。
项目实施:
1. 确定目标
我们的目标官网链接是:https://www.lianjia.com/
对应的某个城市的二手房页面应该是:https://sz.lianjia.com/ershoufang/
JN 代表城市济南的简写,对应的青岛是 QD。
⚠️⚠️⚠️:有两个页面需要注意,第一个页面是打开某个地区二手房链接之后显示的列表页面,第二个页面是点击某个二手房的链接之后跳转的房屋详细数据页面
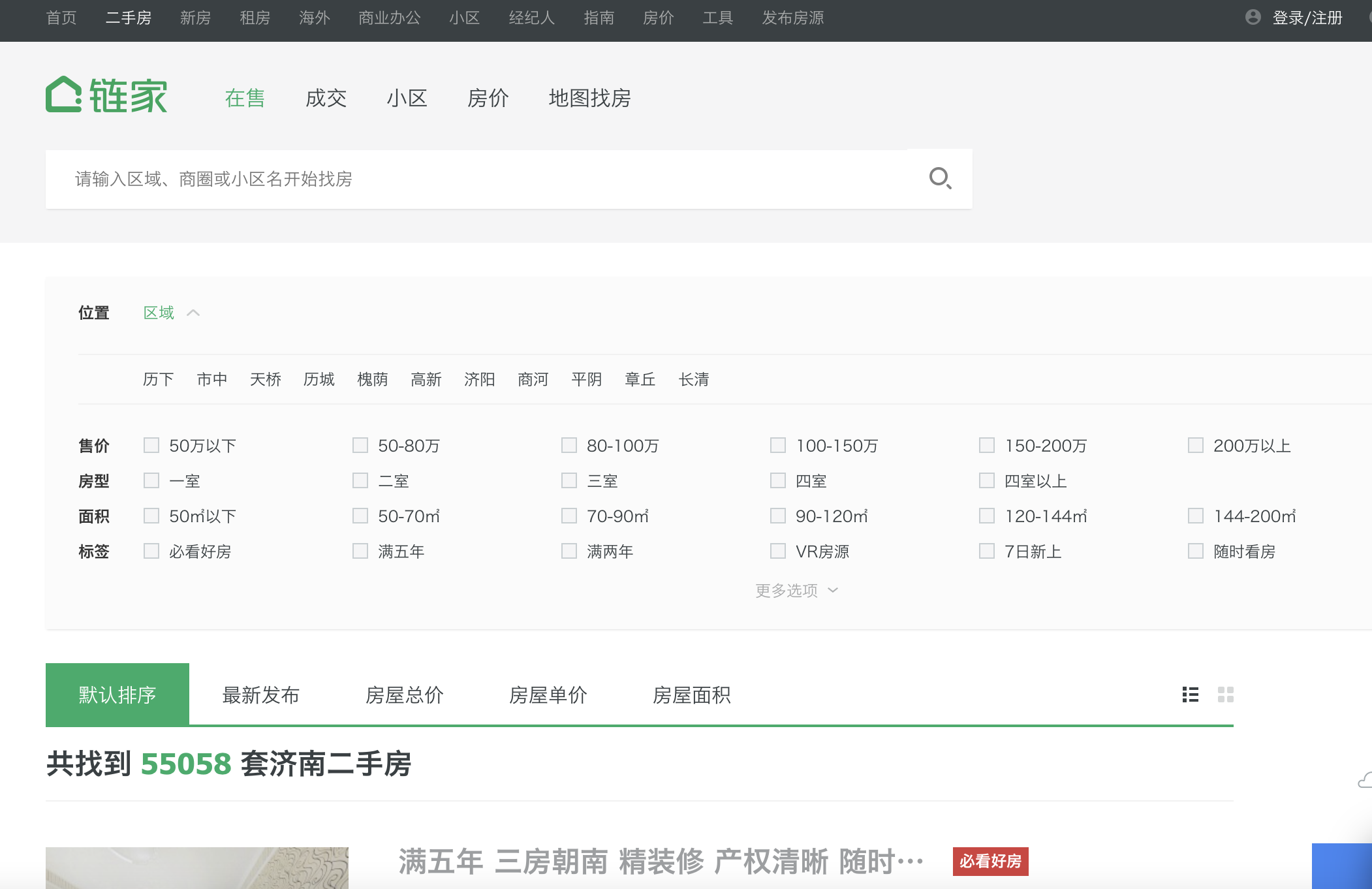
列表页面

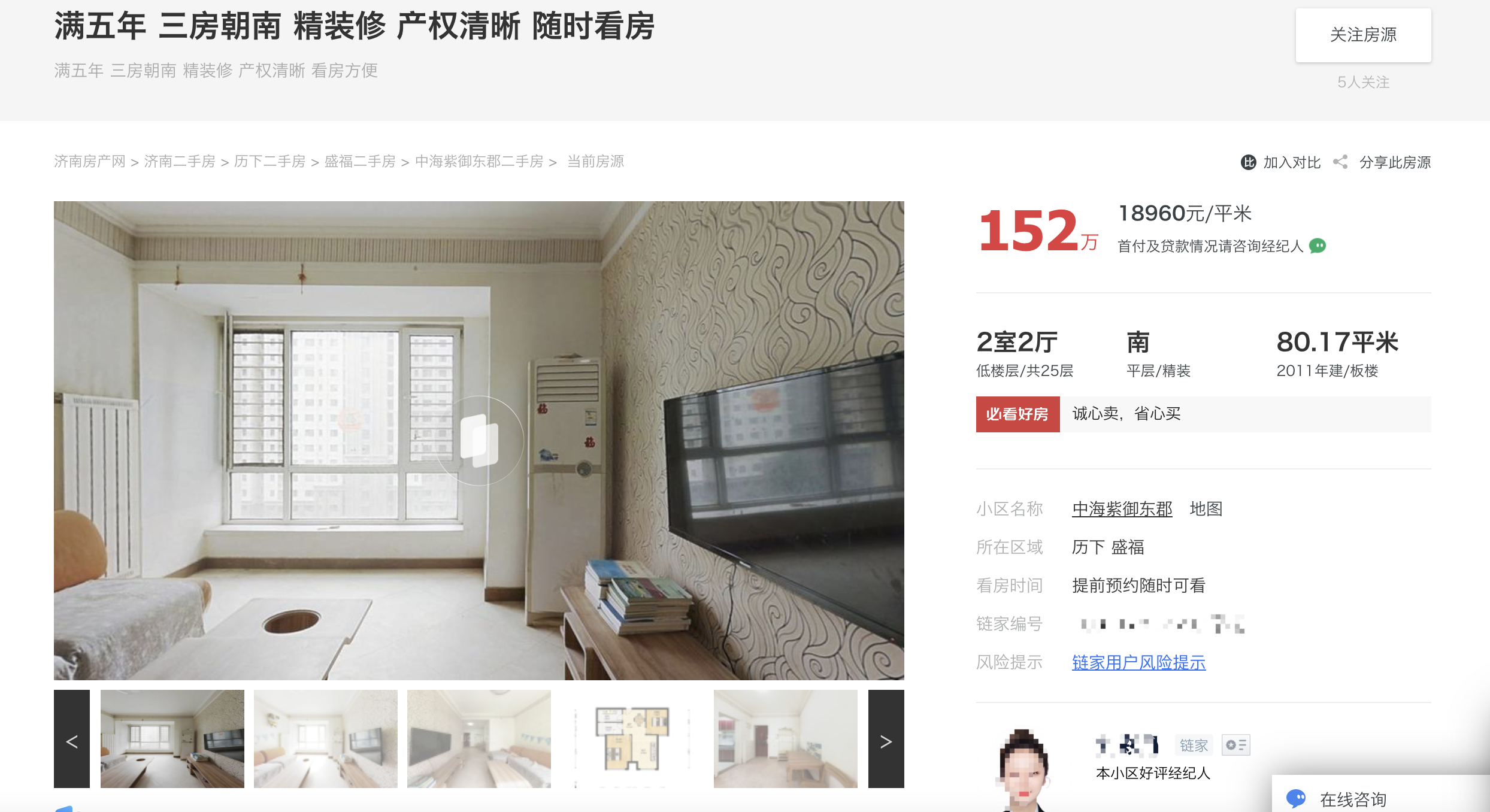
房屋详细信息页面
; 1.1 先来说第一个页面
这个页面包括三部分,最上面的搜索部分、中间的列表部分、下面的翻页部分。
上面的搜索部分看似无用,但也暗藏玄机。
举个最直观的例子:在某个搜索条件下,例如济南,对应的清单中有 55809 条记录
而你将页面拉到最下面进行翻页,发现实际只有 100 页可供操作
根据每一页只有 30 条数据的官方设置,如果不设置搜索条件,只能拿到 3000 条数据
所以,要想获取全部数据,第一个搜索功能就派上用场了。
但是,添加搜索必然会提高整个程序的复杂度,特别是现在有如此多的搜索条件
综上,我们可以选择的解决方式是筛选出重要且能完美区分的搜索条件,例如:区域+户型+朝向
上述设置的目的是:
通过条件设置之后,通过筛选 xx区 的数据,发现数据大于 3000条,则利用户型是 x居室 的进行二次筛选,如果发现仍大于 3000条,再次通过朝x向进行第三次筛选,基本上到了第三次筛选之后,我们可以拿到我们想要的数据。
筛选条件除了每个城市的区域没法固定外,居室和朝向都是固定的
通过F12查看源码可以看到居室和朝向对应的定位如下:

; 所以我们可以在代码中这样呈现:
self.rooms_number = ['l1', 'l2', 'l3', 'l4', 'l5', 'l6']
self.orientation = ['f1', 'f2', 'f3', 'f4', 'f5']
1.2中间的列表部分
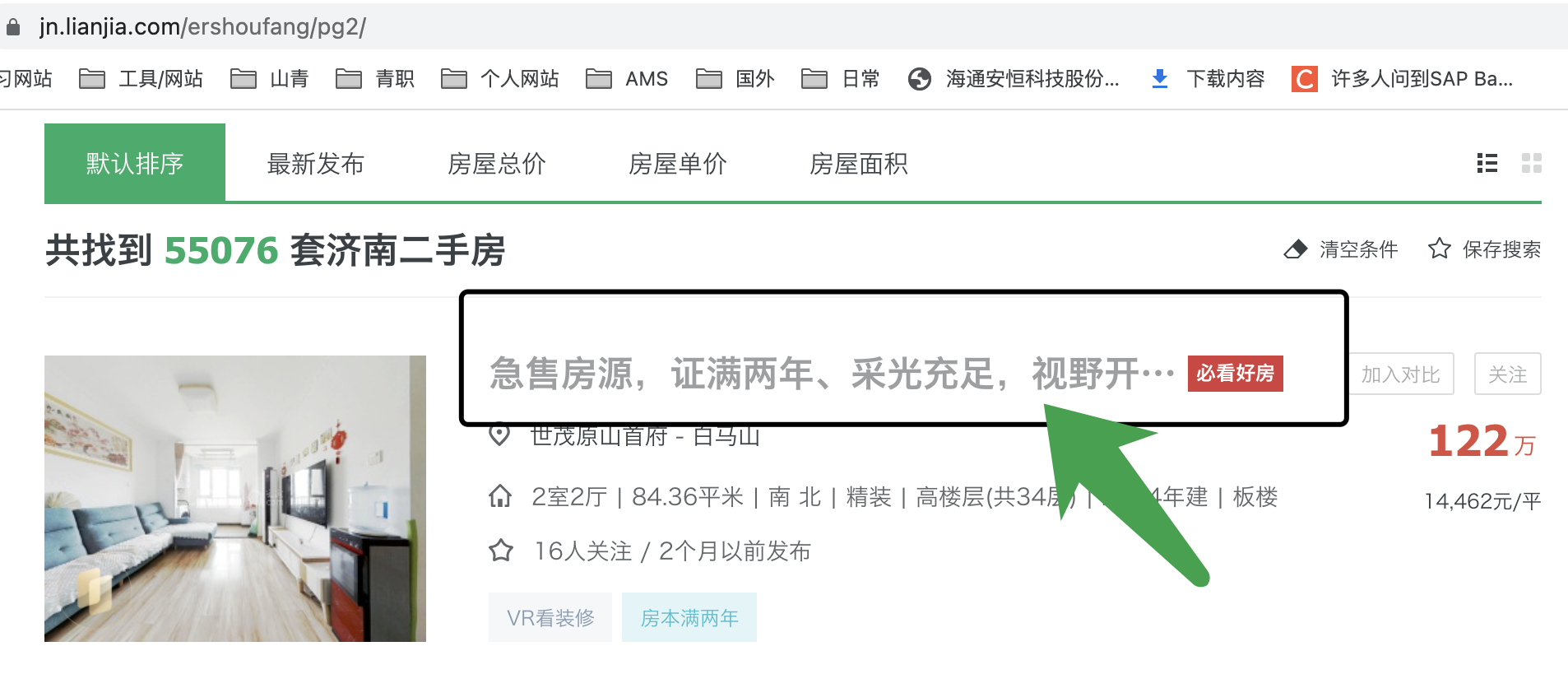
列表部分有 3 个信息需要注意,如下图:
分别是:小区名+区域、价格以及其他标签
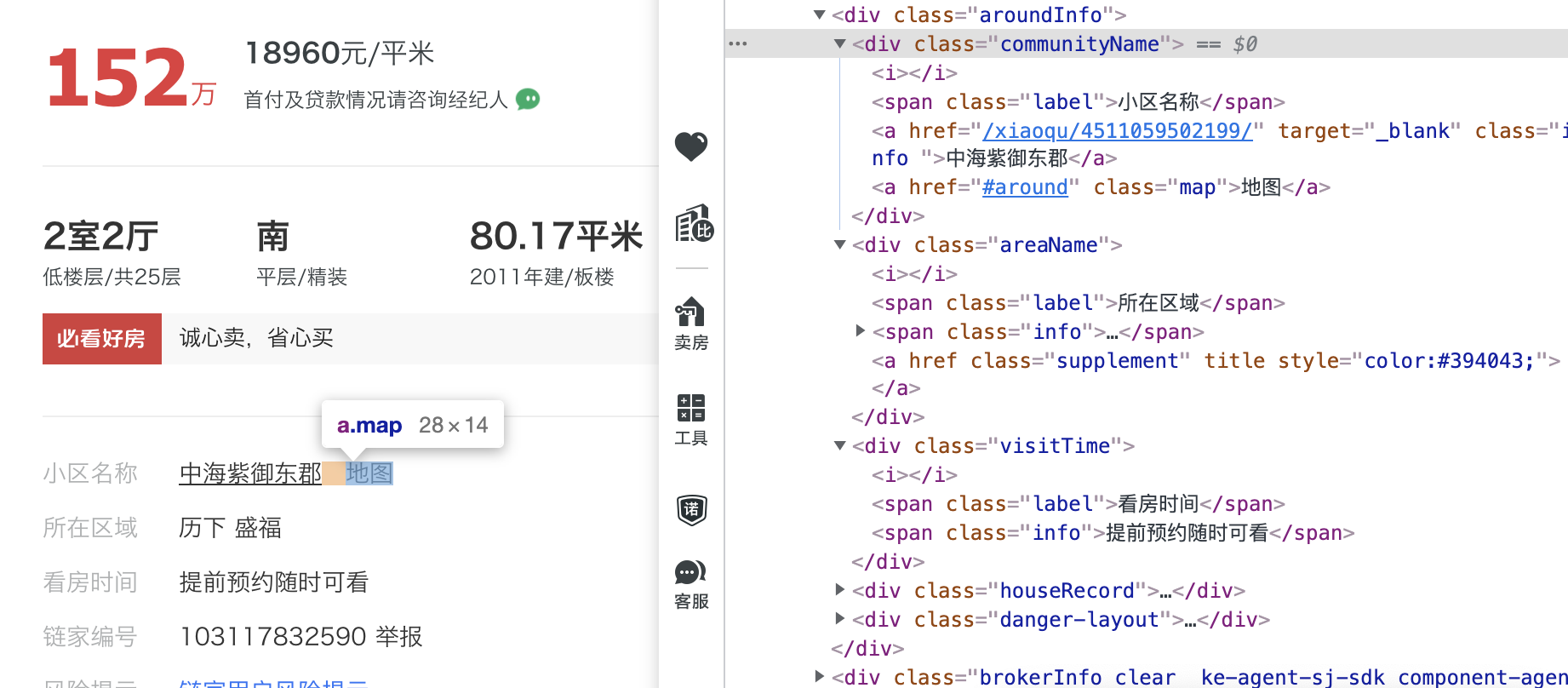
如果这些信息已经可以满足数据需求,那对应的爬虫只需要获取这个页面的数据,不需要分析第二个页面了,工作难度就下降了
如果还需要更详细的二手房指标,例如:挂牌时间、抵押情况、产权等数据,那就需要分析第二个页面了
; 下面的翻页部分:
翻页部分原理比较简单,通过多次点击下一页按钮,观察新页面的 url 链接就能发现规律
例如:https://sz.lianjia.com/ershoufang/luohuqu/pg2l1/ 中的 pg2 对应的是第二页的数据而 l1 在前面我们已经知道是一居室的意思,所以对应的翻页页面的 url 规则应该是:
主网页+区域+pg页码+居室
在翻页遍历的过程中只需要更改 pg页码 即可。
1.3 第二个页面
第二个页面是通过第一个页面点击跳转的:
通过点击图中的标签,会跳转到下面链接对应的新页面
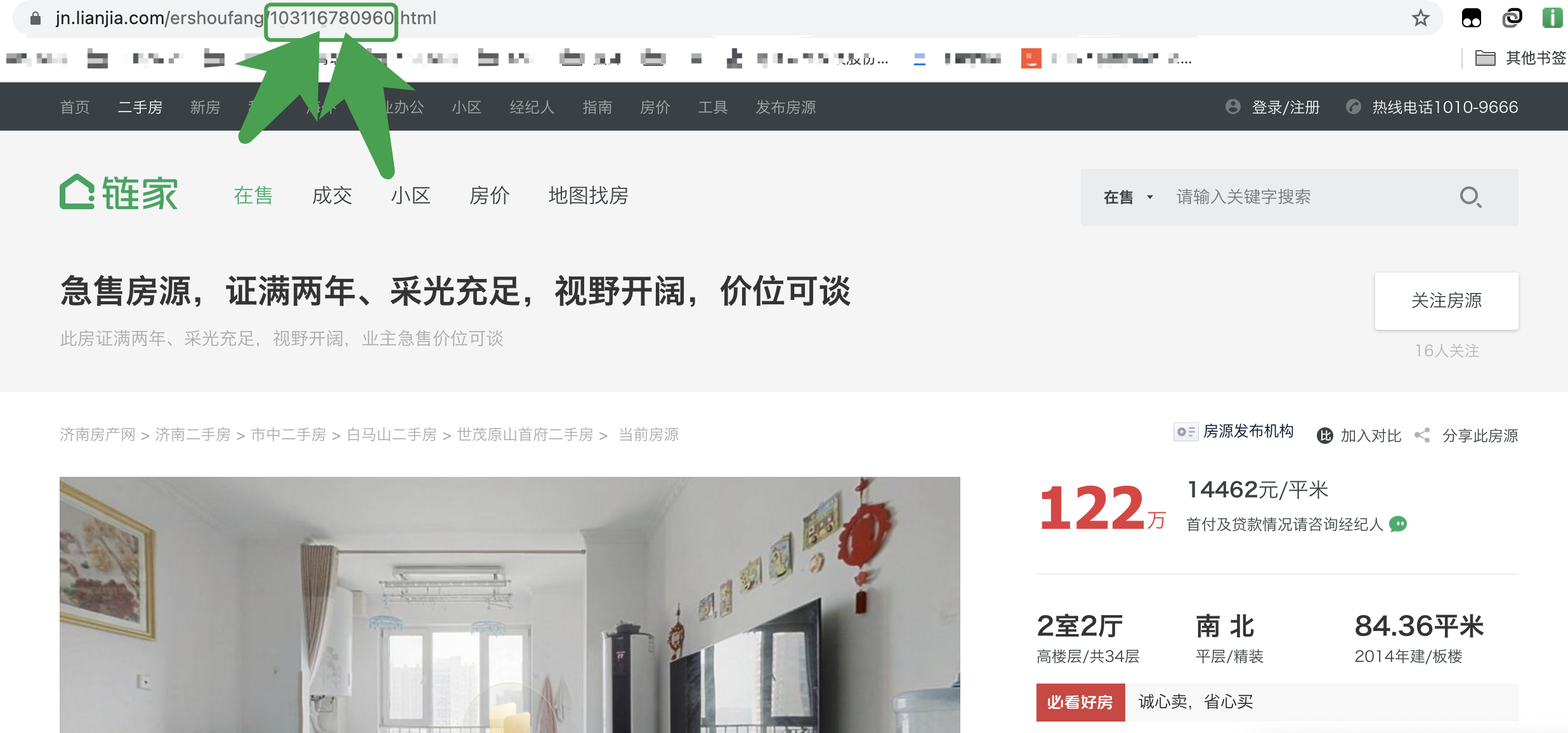
链接中后面的数字编号对应的是该二手房的编码id。例如:https://jn.lianjia.com/ershoufang/103116780960.html 中 103116780960 是对应ID
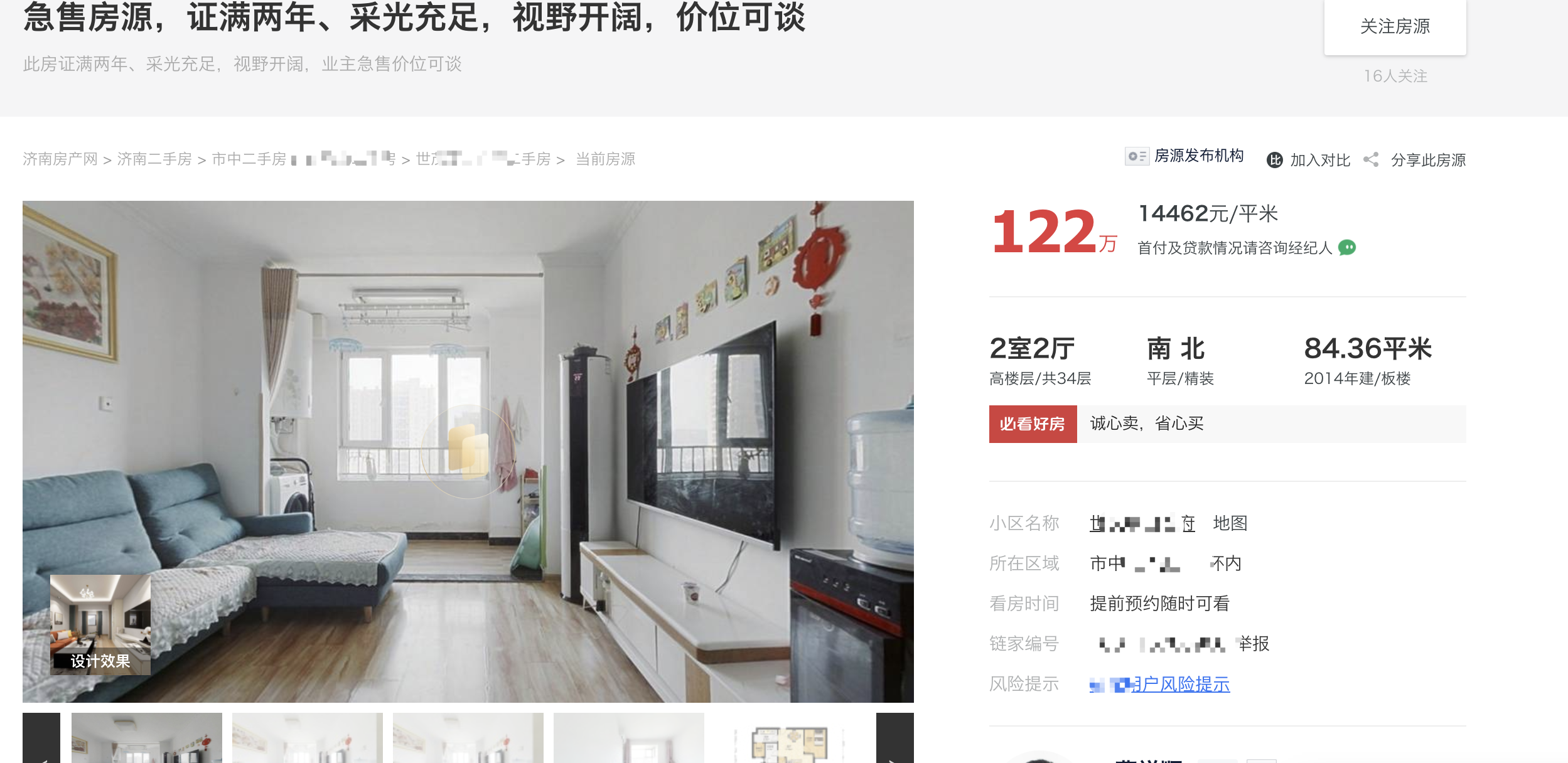
第二个页面有三个部分,分别是:价格+位置、基本信息+交易信息、地图价格+位置部分数据如下图:
; 从价格部分可以获取到:参考总价、单价
从所在区域可以获取到:小区名称、大区域+小区域
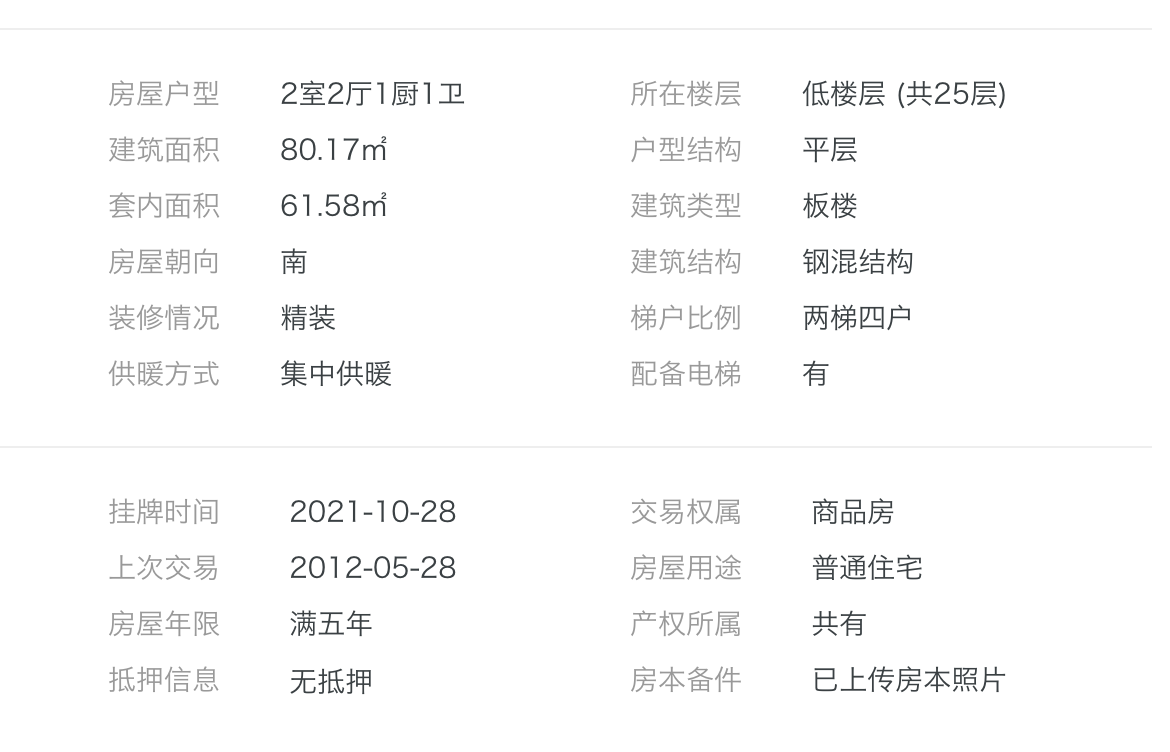
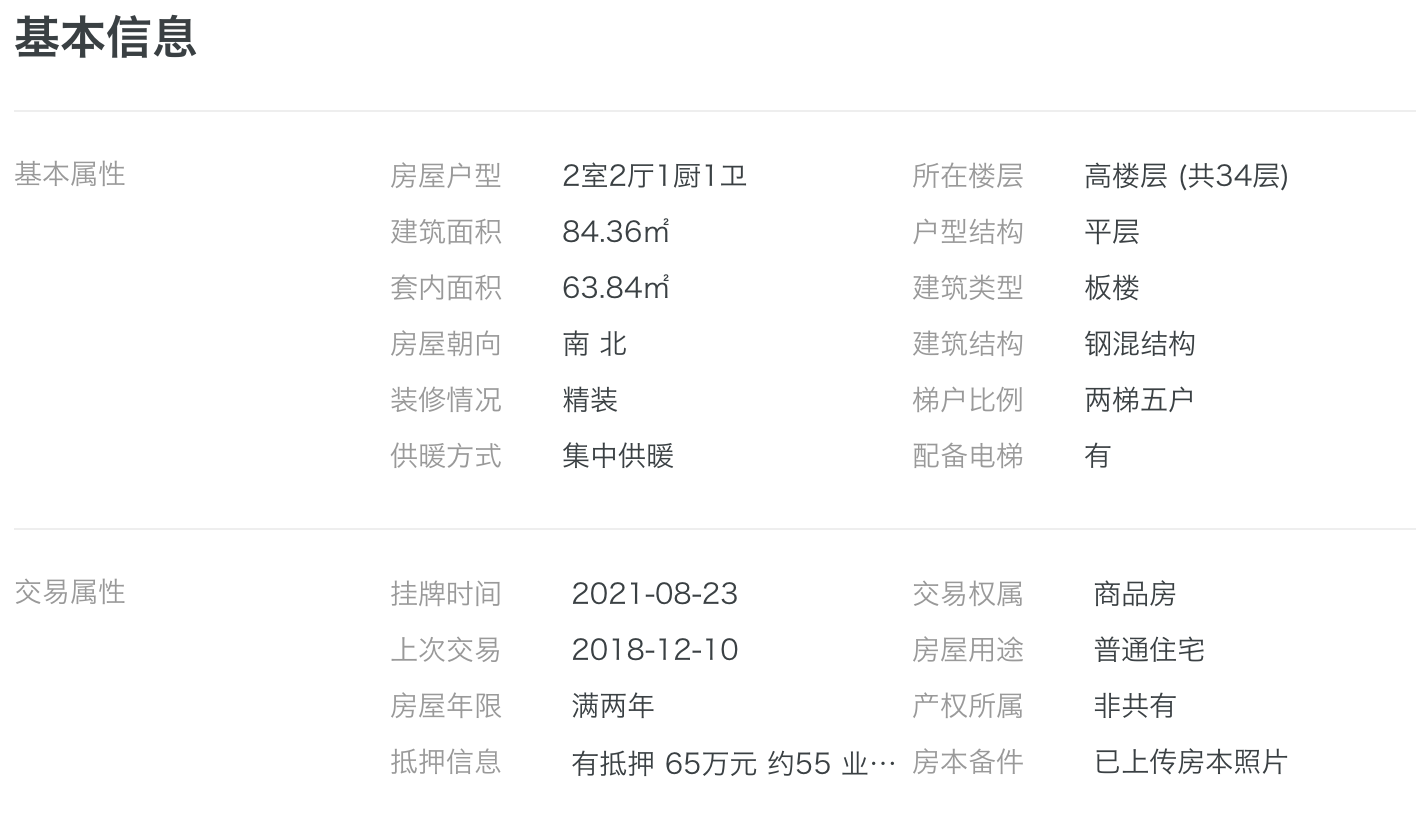
; 基本信息+交易信息数据如下图:
最后是地图部分的数据:
这部分数据比较多,例如:最近的地铁站点、公交站点等以及在地图插件中隐藏的房屋经纬度数据,这里只获取了经纬度数据
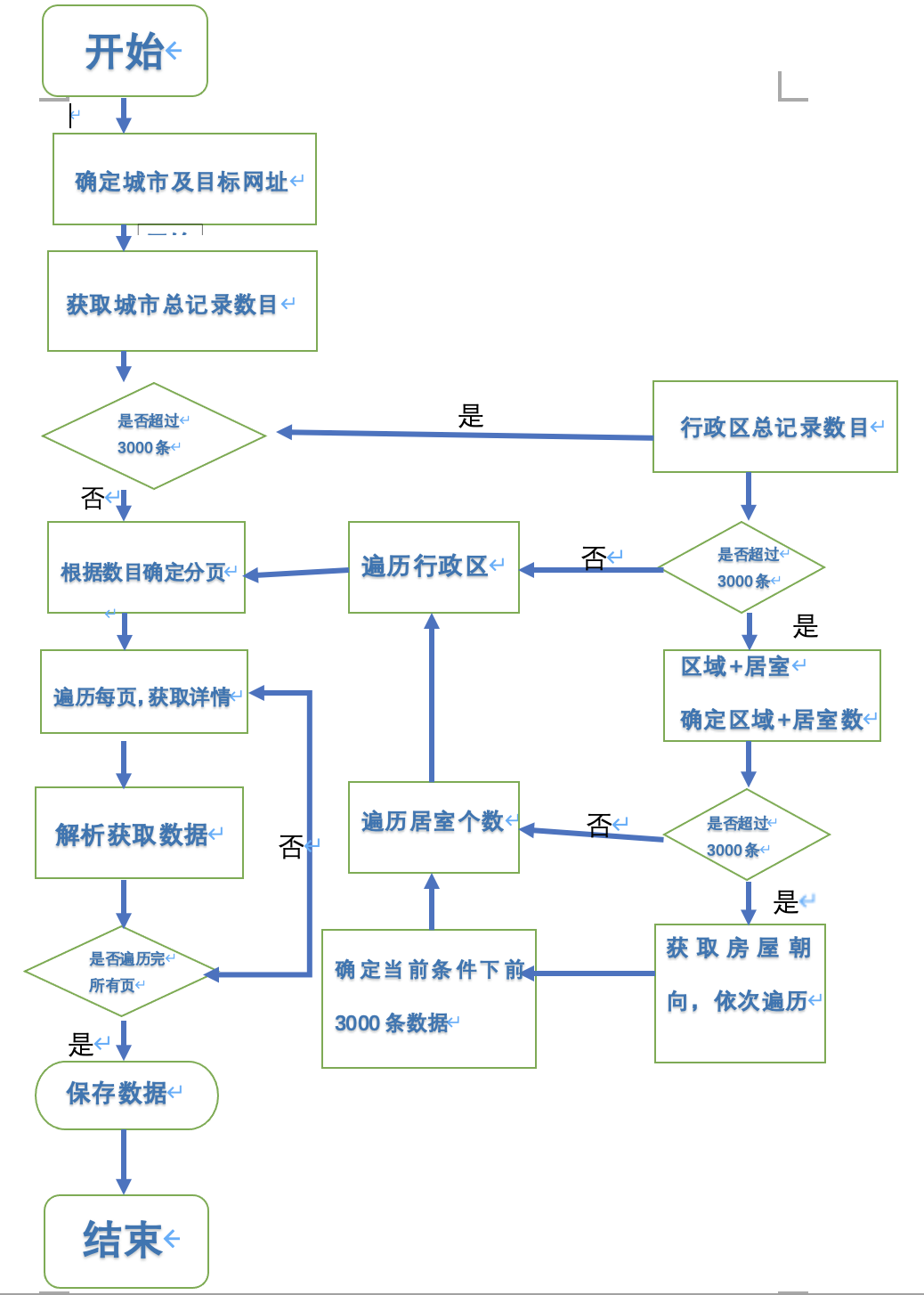
; 2. 流程设计
目标已经明确,总结一下我们需要注意的地方:
首先,判断该城市的总数据是否超过 3000 条,若超过则设置筛选条件。先通过区域进行筛选,其次通过居室进行筛选,最后通过朝向进行筛选
上述筛选过程中任一过程若存在数据小于 3000条,则停止往下筛选。
然后,在确定筛选条件之后,通过解析每一页的二手房链接跳转到详情页。翻页操作只需要根据页码重新构造 url
最后,对二手房详情页进行解析,保存数据到本地文件中。
3. 主要代码复现
核心代码分析,完整代码看链接:
获取当前条件下的房屋数据个数:
def get_house_count(self):
"""
获取当前筛选条件下的房屋数据个数
"""
response = requests.get(url=self.current_url, headers=self.headers)
soup = BeautifulSoup(response.text, 'html.parser')
count = soup.find('h2', class_='total fl').find('span').string.lstrip()
return soup, count
判断是否超过3000,若超过则进行第二级筛选,若未超过则直接获取数据
def get_main_page(self):
soup, count_main = self.get_house_count()
if int(count_main) > self.page_size*self.max_pages:
soup_uls = soup.find('div', attrs={'data-role': 'ershoufang'}).div.find_all('a')
self.area = self.get_area_list(soup_uls)
for area in self.area:
self.get_area_page(area)
else:
self.get_pages(int(count_main), '', '', '')
self.data_to_csv()
对应的在确定区域的条件下,继续判断并筛选居室
在确定区域和居室的条件下,继续判断并筛选朝向
在确定区域、居室和朝向的条件下,直接获取 前3000条数据
在代码执行的过程中,建议每获取到 n条 数据保存一次,避免中途程序出错而前功尽弃
'''超过n条数据,保存到本地'''
if len(self.data_info) >=n:
self.data_to_csv()
在保存到本地 csv 的时候,采用追加的方式进行保存
也就是在 data_to_csv 函数中:
def data_to_csv(self):
"""
保存/追加数据到本地
@return:
"""
df_data = pd.DataFrame(self.data_info)
if os.path.exists(self.save_file_path) and os.path.getsize(self.save_file_path):
df_data.to_csv(self.save_file_path, mode='a', encoding='utf-8', header=False, index=False)
else:
df_data.to_csv(self.save_file_path, mode='a', encoding='utf-8', index=False)
self.data_info = []
另外,考虑到大多时候需要运行好几次程序才能获取到所有数据
在每次运行程序的时候先统计已经爬到的房屋数据,跳过已经爬到的数据
可以这样写:
self.house_id = self.get_exists_house_id()
def get_exists_house_id(self):
"""
通过已经爬取到的房屋信息,并获取房屋id
@return:
"""
if os.path.exists(self.save_file_path):
df_data = pd.read_csv(self.save_file_path, encoding='utf-8', )
df_data['house_id'] = df_data['house_id'].astype(str)
return df_data['house_id'].to_list()
else:
return []
最后,在主函数中只需要设置城市名称和数据保存路径即可
代码如下:
if __name__ == '__main__':
city_number = 'JN'
city_name = '济南'
url = 'https://{0}.lianjia.com/ershoufang/'.format(city_number)
page_size = 30
save_file_path = '二手房数据-JN.csv'
house = House(city_name, url, page_size, save_file_path)
house.get_main_page()
4. 运行
如果是第一次运行程序,设置好相关参数后,运行截图如下:

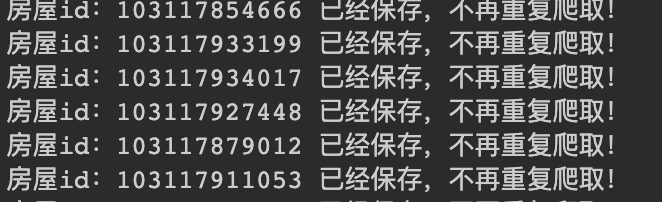
如果之前有运行过程序,中途退出了。
再次运行时无需设置参数,直接运行即可,截图如下:
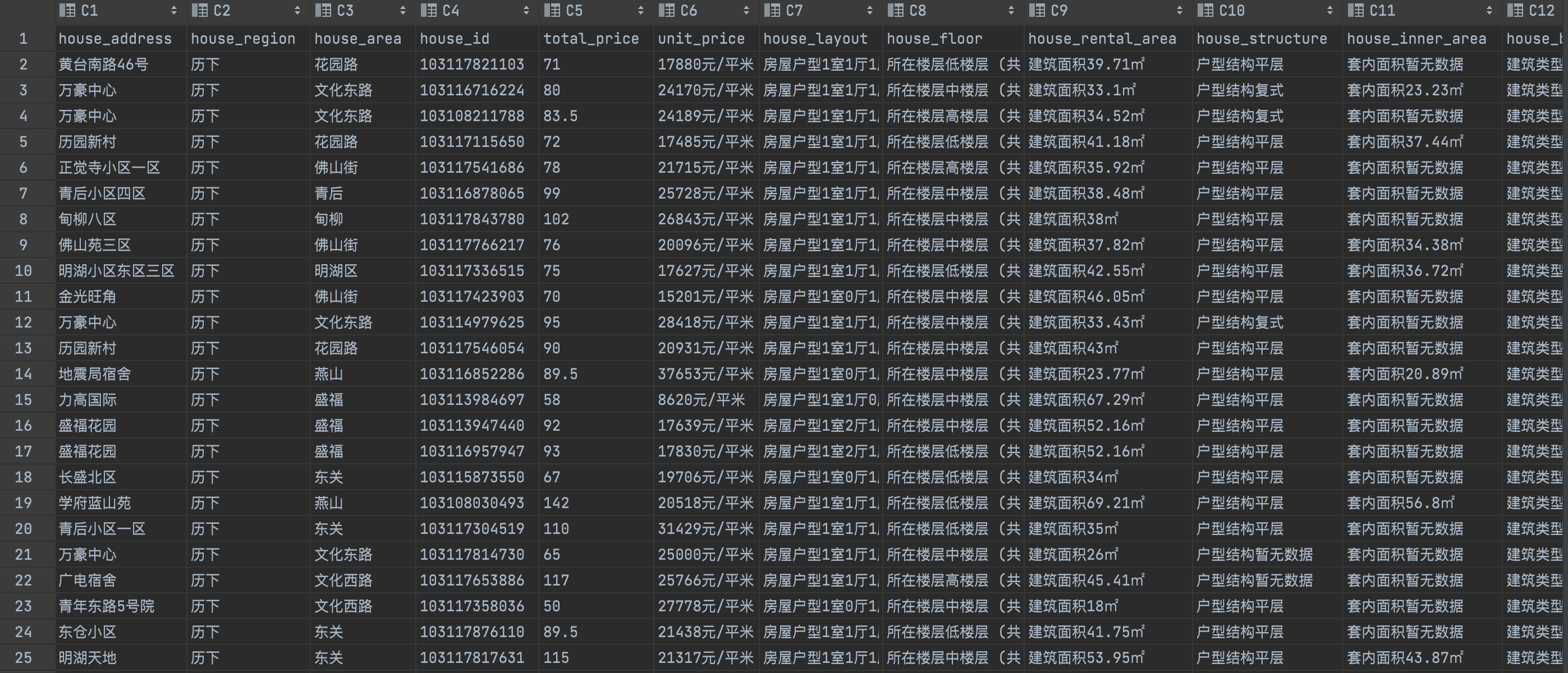
最终爬取到的部分数据如下:
; 完整代码:
总结:
整体来说,流程的设计比较繁琐,但是是很基础的一篇内容
另外,建议大家在运行的过程中,适当的设置程序休眠,理性爬虫
以上代码仅用于交流学习,不可用于商业用途
Authors 杜小白
Original: https://blog.csdn.net/qq_43412080/article/details/121182528
Author: 杜小白iu
Title: 爬取某家网二手房数据(详细教程)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/639914/
转载文章受原作者版权保护。转载请注明原作者出处!