

文章目录
- 笔记:Pytorch-geometric: GAT代码超详细解读 | source node | target node | source_to_target
* - 前言
- Torch geometric官方的GAT实现
- 源码解读
– - 总结
笔记:Pytorch-geometric: GAT代码超详细解读 | source node | target node | source_to_target
知识分享求点赞QAQ,能力有限,如有错误欢迎诸位大佬指正。
不想读源码又想了解torch-geometric库利用message-passing实现GAT的机理,找遍博文也没有满意的,看了官方的文档也不能完全理解(大概还是自己理解能力不太行),于是有了这篇源码解读。
前言
- 什么是GAT?是Graph Attention Networks,图注意网络,具体参考其他人的文章

- 什么是Pytorch-geometric?是目前常用的实现图神经网络方法的依赖库,本文详述的GAT的torch实现方法,可见官方文档torch-geometric GAT
- 什么是message passing?是torch geometric为了方便用户构建图神经网络实现的类,GAT的实现即继承了message passing类
; Torch geometric官方的GAT实现
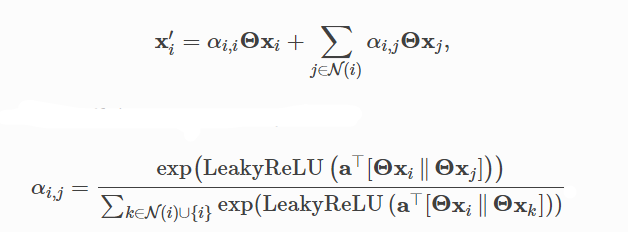
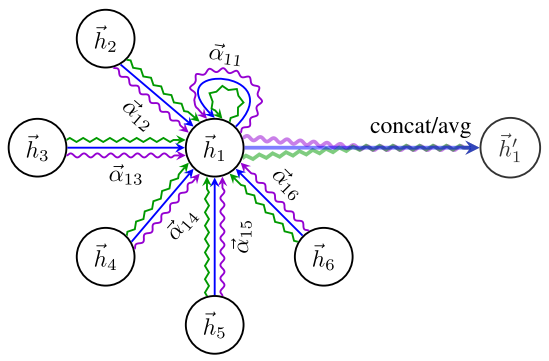
其中Θ \Theta Θ是参数,α i j \alpha_{ij}αi j 是注意力系数,其中说明:
i代表target node, j代表source node。从公式或者GAT的示意图很容易得出消息的流向是从source node到target node。* 官方的GATConv源码:
class GATConv(MessagePassing):
def __init__(self, in_channels: Union[int, Tuple[int, int]],
out_channels: int, heads: int = 1, concat: bool = True,
negative_slope: float = 0.2, dropout: float = 0.,
add_self_loops: bool = True, bias: bool = True, **kwargs):
kwargs.setdefault('aggr', 'add')
super(GATConv, self).__init__(node_dim=0, **kwargs)
self.in_channels = in_channels
self.out_channels = out_channels
self.heads = heads
self.concat = concat
self.negative_slope = negative_slope
self.dropout = dropout
self.add_self_loops = add_self_loops
if isinstance(in_channels, int):
self.lin_l = Linear(in_channels, heads * out_channels, bias=False)
self.lin_r = self.lin_l
else:
self.lin_l = Linear(in_channels[0], heads * out_channels, False)
self.lin_r = Linear(in_channels[1], heads * out_channels, False)
self.att_l = Parameter(torch.Tensor(1, heads, out_channels))
self.att_r = Parameter(torch.Tensor(1, heads, out_channels))
if bias and concat:
self.bias = Parameter(torch.Tensor(heads * out_channels))
elif bias and not concat:
self.bias = Parameter(torch.Tensor(out_channels))
else:
self.register_parameter('bias', None)
self._alpha = None
self.reset_parameters()
def reset_parameters(self):
glorot(self.lin_l.weight)
glorot(self.lin_r.weight)
glorot(self.att_l)
glorot(self.att_r)
zeros(self.bias)
def forward(self, x: Union[Tensor, OptPairTensor], edge_index: Adj,
size: Size = None, return_attention_weights=None):
H, C = self.heads, self.out_channels
x_l: OptTensor = None
x_r: OptTensor = None
alpha_l: OptTensor = None
alpha_r: OptTensor = None
if isinstance(x, Tensor):
assert x.dim() == 2, 'Static graphs not supported in GATConv.'
x_l = x_r = self.lin_l(x).view(-1, H, C)
alpha_l = (x_l * self.att_l).sum(dim=-1)
alpha_r = (x_r * self.att_r).sum(dim=-1)
else:
x_l, x_r = x[0], x[1]
assert x[0].dim() == 2, 'Static graphs not supported in GATConv.'
x_l = self.lin_l(x_l).view(-1, H, C)
alpha_l = (x_l * self.att_l).sum(dim=-1)
if x_r is not None:
x_r = self.lin_r(x_r).view(-1, H, C)
alpha_r = (x_r * self.att_r).sum(dim=-1)
assert x_l is not None
assert alpha_l is not None
if self.add_self_loops:
if isinstance(edge_index, Tensor):
num_nodes = x_l.size(0)
if x_r is not None:
num_nodes = min(num_nodes, x_r.size(0))
if size is not None:
num_nodes = min(size[0], size[1])
edge_index, _ = remove_self_loops(edge_index)
edge_index, _ = add_self_loops(edge_index, num_nodes=num_nodes)
elif isinstance(edge_index, SparseTensor):
edge_index = set_diag(edge_index)
out = self.propagate(edge_index, x=(x_l, x_r),
alpha=(alpha_l, alpha_r), size=size)
alpha = self._alpha
self._alpha = None
if self.concat:
out = out.view(-1, self.heads * self.out_channels)
else:
out = out.mean(dim=1)
if self.bias is not None:
out += self.bias
if isinstance(return_attention_weights, bool):
assert alpha is not None
if isinstance(edge_index, Tensor):
return out, (edge_index, alpha)
elif isinstance(edge_index, SparseTensor):
return out, edge_index.set_value(alpha, layout='coo')
else:
return out
def message(self, x_j: Tensor, alpha_j: Tensor, alpha_i: OptTensor,
index: Tensor, ptr: OptTensor,
size_i: Optional[int]) -> Tensor:
alpha = alpha_j if alpha_i is None else alpha_j + alpha_i
alpha = F.leaky_relu(alpha, self.negative_slope)
alpha = softmax(alpha, index, ptr, size_i)
self._alpha = alpha
alpha = F.dropout(alpha, p=self.dropout, training=self.training)
return x_j * alpha.unsqueeze(-1)
def __repr__(self):
return '{}({}, {}, heads={})'.format(self.__class__.__name__,
self.in_channels,
self.out_channels, self.heads)
源码解读
输入图
为了方便的解读源码 ,我们建立一个简单的图用于输入,图中包含三个标号0,1,2的节点,节点特征是二维的。
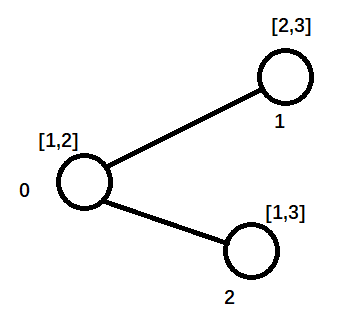
建立图代码如下
import torch
from torch_geometric.nn import GATConv
from torch_geometric.data import Data
from torch_geometric.utils import to_undirected
x=torch.tensor([[1.,2],[2,3],[1,3]])
edge_index=torch.LongTensor([[0,0],[1,2]])
edge_index = to_undirected(edge_index)
graph = Data(x=x,edge_index=edge_index)
__init__部分
self.in_channels = in_channels
self.out_channels = out_channels
self.heads = heads
self.concat = concat
self.negative_slope = negative_slope
self.dropout = dropout
self.add_self_loops = add_self_loops
if isinstance(in_channels, int):
self.lin_l = Linear(in_channels, heads * out_channels, bias=False)
self.lin_r = self.lin_l
else:
self.lin_l = Linear(in_channels[0], heads * out_channels, False)
self.lin_r = Linear(in_channels[1], heads * out_channels, False)
self.att_l = Parameter(torch.Tensor(1, heads, out_channels))
self.att_r = Parameter(torch.Tensor(1, heads, out_channels))
这一部分非常简单,见注释。注意 Message passing有可选参数 flow,可以选择为 source_to_target或者是 target_to_source。很明显GAT是前者,且与默认值相同,不做修改。
forward部分
def forward(self, x: Union[Tensor, OptPairTensor], edge_index: Adj,
size: Size = None, return_attention_weights=None):
H, C = self.heads, self.out_channels
输入特征向量矩阵 x和 edge_index。
此处输入的
x=[
[1,2],
注意 edge_index出现了变化,原因是建图中 to_undirected的操作
x_l: OptTensor = None
x_r: OptTensor = None
alpha_l: OptTensor = None
alpha_r: OptTensor = None
if isinstance(x, Tensor):
assert x.dim() == 2, 'Static graphs not supported in GATConv.'
x_l = x_r = self.lin_l(x).view(-1, H, C)
alpha_l = (x_l * self.att_l).sum(dim=-1)
alpha_r = (x_r * self.att_r).sum(dim=-1)
else:
x_l, x_r = x[0], x[1]
assert x[0].dim() == 2, 'Static graphs not supported in GATConv.'
x_l = self.lin_l(x_l).view(-1, H, C)
alpha_l = (x_l * self.att_l).sum(dim=-1)
if x_r is not None:
x_r = self.lin_r(x_r).view(-1, H, C)
alpha_r = (x_r * self.att_r).sum(dim=-1)
x_l,x_r分别计算的是左乘Θ \Theta Θ后的向量值,这里再强调(因为后面很重要), l对应source node, r对应target node, i代表target node, j代表source node。
此外 alpha_l是 x_l和 self.att_l点积之后的结果,对应a l T Θ l x a^T_l\Theta_l x a l T Θl x,同理 alpha_r。
我们假设二维到一维的映射是简单的相加(即Θ \Theta Θ左乘就是相加),同时a T a^T a T的作用是乘以0.5),那么此时的 x_l,x_r,alpha_l,alpha_r为:
x_l = x_r = [
[3],
if self.add_self_loops:
if isinstance(edge_index, Tensor):
num_nodes = x_l.size(0)
if x_r is not None:
num_nodes = min(num_nodes, x_r.size(0))
if size is not None:
num_nodes = min(size[0], size[1])
edge_index, _ = remove_self_loops(edge_index)
edge_index, _ = add_self_loops(edge_index, num_nodes=num_nodes)
elif isinstance(edge_index, SparseTensor):
edge_index = set_diag(edge_index)
接下来为 edge_index加入自环,加入自环之后的 edge_index变为:
edge_index = [
[0,0,1,2,0,1,2],
out = self.propagate(edge_index, x=(x_l, x_r),
alpha=(alpha_l, alpha_r), size=size)
调用Message passing的 propagate的方法,这是一个集成方法,调用其会依次调用 message、 aggregate、 update方法。在source_to_target的方式下, message方法负责产生source node需要传出的信息, aggregate负责为target node收集来自source node的信息,一般是 max、 add(default)等方法,GAT默认采用的是 add方法, update用于更新表示。可见实现GAT最关键的是 message方法的构造。
注意源码中调用 propagate传入的参数会等价的传入 message和 aggregate中,这里传入的x是一个元胞,例如 (x_l,x_r),元胞中第一位是用作source node信息使用的,第二位是用作target node信息使用的。
重构message方法
def message(self, x_j: Tensor, alpha_j: Tensor, alpha_i: OptTensor,
index: Tensor, ptr: OptTensor,
size_i: Optional[int]) -> Tensor:
alpha = alpha_j if alpha_i is None else alpha_j + alpha_i
alpha = F.leaky_relu(alpha, self.negative_slope)
alpha = softmax(alpha, index, ptr, size_i)
self._alpha = alpha
alpha = F.dropout(alpha, p=self.dropout, training=self.training)
return x_j * alpha.unsqueeze(-1)
x_j和 alpha_j是source node的信息, index是与source node相连的target node的标号, ptr默认值是 None,这里不考虑。这么说是不是非常的不明白?这里就需要数字举例了。
此时有:
edge_index = [
[0,0,1,2,0,1,2],
传入 message中的各变量为:
index=[1,2,0,0,0,1,2]
这样就非常清晰明了了。剩下的就是说明其softmax的实现
alpha = softmax(alpha, index, ptr, size_i)
这里的 alpha是 alpha_i和 alpha_j的和:
alpha=[[4],[3.5],[4],[3.5],[3],[5],[4]]
softmax函数先是对 alpha的内容都取 exp,得到 exp_alpha
exp_alpha=[exp(4),exp(3.5),exp(4),exp(3.5),exp(3),exp(5),exp(4)]#简单起见省略了中间的小括号
index = [1,2,0,0,0,1,2]
最后的 softmax函数是依赖 exp_alpha和 index共同得到输出 out:
out=[
exp(4)/(exp(4)+exp(5)),
exp(3.5)/(exp(4)+exp(3.5)),
exp(4)/(exp(3)+exp(4)+exp(3.5)),
exp(3.5)/(exp(3)+exp(4)+exp(3.5)),
exp(3)/(exp(3)+exp(4)+exp(3.5)),
exp(5)/(exp(4)+exp(5)),
exp(4)/(exp(4)+exp(3.5)),
]
到这一步了,我居然不知道怎么用文字解释 index和 exp_alpha产生 out的方法…就看上面的公式找规律吧,很容易观察出来,大概就是按位寻找对应 index中内容相同的,然后计算占比这样。
这样的 out就是注意力系数了,到这里GAT的讲解也就结束了。
总结
应该各部分都很好理解,除了 message部分,文中举例了数据,也列出了输入和输出,仔细观察应该不难弄明白。
Original: https://blog.csdn.net/weixin_44839047/article/details/115724958
Author: Deno_V
Title: 笔记:Pytorch-geometric: GAT代码超详细解读 | source node | target node | source_to_target
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/639892/
转载文章受原作者版权保护。转载请注明原作者出处!