

免疫浸润也是近几年肿瘤研究的一个重要方向。通过表达数据即可推算出这个整体样本中究竟有哪些免疫细胞。下面我们就基于数据库数据来看下整个流程分析!
前言
我们介绍了CIBERSORT,一种从其基因表达谱表征复杂组织的细胞组成的方法。当应用于计数来自新鲜、冷冻和固定组织(包括实体肿瘤)的RNA混合物中的造血亚群时,CIBERSORT在噪声、未知混合物含量和密切相关的细胞类型方面优于其他方法。CIBERSORT将使细胞生物标志物和治疗靶标的RNA混合物大规模分析成为可能。
从事免疫相关工作的研究人员,目前只需常规普通的转录组测序数据,就能拿到该样本中各类免疫细胞如DC细胞、NK细胞、CD4+ T细胞等所占比例。
例如肿瘤微环境主要由肿瘤细胞、成纤维细胞、免疫细胞、各种信号分子和细胞外基质及特殊的理化特征等共同组成,肿瘤微环境显著影响着肿瘤的诊断、生存结局和临床治疗敏感性。其中免疫浸润也是近几年肿瘤研究的一个重要方向。
所以我们要清楚一个概念那就是肿瘤组织中并不是100%的细胞是肿瘤细胞,不同肿瘤组织的微环境都有着各自的特点。
那么简单肿瘤组织中存在着那么多不同类型的细胞,但是传统的转录组混池测序方法(也叫Bulk RNA-seq)是将组织整体的RNA表达水平进行检测,我们并不能有效区分究竟哪些细胞表达了哪些基因。
实例解析
1. 数据读取
在R语言中运行Cibersort共需要三个文件,分别是:
1)官方提供的22种细胞基因集”LM22.txt”;
2)基因表达矩阵;
3)Cibersort代码。
下面我们就仔细述说一下这三个文件如何来获得,如下:
1)LM22.txt获取方法:
在Cibersort论文中(https://www.nature.com/articles/nmeth.3337#MOESM207)下载Supplementry table 1,得到如下矩阵,另存为制表符分割的txt(”LM22.txt”)
2)基因表达矩阵
表达矩阵必须如下:
- 第一列是基因名,并且基因名必须为 SYMBOL 号模式;
- 第一行是样品名,不能有重复基因名;
- 第一列列名不能空白。
对于矩阵中表达量输入数据的要求,如下:
1.不可以有负值和缺失值
2.不要取log
3.如果是芯片数据,昂飞芯片使用RMA标准化,Illumina 的Beadchip 和Agilent的单色芯片,用limma处理。
4.如果是RNA-Seq表达量,使用FPKM和TPM都合适。
3)Cibersort代码
在R中新建R Script,复制以下网址中代码,保存为”Cibersort.R”
https://rdrr.io/github/singha53/amritr/src/R/supportFunc_cibersort.R
数据的读取我们仍然使用的是 TCGA-COAD 的数据集,表达数据的读取以及临床信息分组的获得我们上期已经提过,我们使用的是edgeR 软件包计算出来的差异表达结果,提取上调基因 2832 的 ENSEMBL 号,
###########基因列表
DEG=read.table("DEG-resdata.xls",sep="\t",check.names=F,header = T)
geneList<-deg[deg$sig=="up",]$row.names 1296 2832 table(deg$sig) ## down up < code></-deg[deg$sig=="up",]$row.names>
直接用之前的转录组差异分析后的数据来演示,数据格式如下
mergedataTP<-deg[,8:ncol(deg)] 6 13 15 20 48 49 55 59 89 102 108 153 175 259 rownames(mergedatatp)="DEG$Row.names" mergedatatp[1:5,1:3] ## tcga-3l-aa1b-01a-11r-a37k-07 tcga-4n-a93t-01a-11r-a37k-07 ensg00000142959 ensg00000163815 ensg00000107611 ensg00000162461 ensg00000163959 tcga-4t-aa8h-01a-11r-a41b-07 < code></-deg[,8:ncol(deg)]>
Count 转 TPM
首先,提取基因长度,经过一波操作之后,得到每个基因的长度,如下:
##########提取基因长度
library(GenomicFeatures)
txdb <- 1207 1610 4535 5967 6883 maketxdbfromgff("f: demo script gencode.v22.annotation.gtf.gz",format="gtf" ) exons <- exonsby(txdb,by="gene" exons_length<-lapply(exons,function(x){sum(width(reduce(x)))}) exons_length<-as.data.frame(exons_length) exons_length1<-t(exons_length) exons_length1<-as.data.frame(exons_length1) colnames(exons_length1)="Length" gene<-gsub("\\.(\\.?\\d*)","",rownames(exons_length1)) exons_length1$gene="as.data.frame(Gene)[,1]" exons_length1[1:5,1:2] ## length gene ensg00000000003.13 ensg00000000003 ensg00000000005.5 ensg00000000005 ensg00000000419.11 ensg00000000419 ensg00000000457.12 ensg00000000457 ensg00000000460.15 ensg00000000460 < code></->
计算 TPM,同样经过一波操作,我们计算得到TPM的矩阵,如下:
##############计算FPKM/RPKM/TPM
le = exons_length1[match(rownames(mergedataTP),exons_length1$Gene),"Length"]
head(le)
## [1] 2047 1105 13168 3195 5293 1209
#这个函数是现成的。
countToTpm <- 1 2 3 4 5 function(counts, efflen) { rate <- log(counts) - log(efflen) denom log(sum(exp(rate))) exp(rate + log(1e6)) } #install.packages("tibble") library(tibble) tpms apply(mergedatatp,2,counttotpm,le) tpms[1:3,1:3] ## tcga-3l-aa1b-01a-11r-a37k-07 tcga-4n-a93t-01a-11r-a37k-07 ensg00000142959 13.540046 11.98080 ensg00000163815 219.474345 159.79893 ensg00000107611 5.156847 1.61412 tcga-4t-aa8h-01a-11r-a41b-07 61.137762 136.370688 1.163758 exp2="as.data.frame(tpms)" exp2[1:5,1:3] rowname ensg00000162461 23.856120 ensg00000163959 40.058762 45.54404 80.00373 < code></->
但是由于我们下载是Count 矩阵基因ID 是 ENSEMBL 号,所以我们需要将其转换为SYMBOL的标识,如下:
############ENSEMBL to SYMBOL
library(org.Hs.eg.db)
library(clusterProfiler)
genes<-exp2$rowname 1 2 3 4 5 6 7123 8029 130749 200931 266675 284723 eg <- bitr(genes, fromtype="ENSEMBL" , totype="c("ENTREZID","ENSEMBL",'SYMBOL')," orgdb="org.Hs.eg.db" ) head(eg) ## ensembl entrezid symbol ensg00000142959 best4 ensg00000163815 clec3b ensg00000107611 cubn ensg00000162461 slc25a34 ensg00000163959 slc51a ensg00000144410 cpo < code></-exp2$rowname>
合并数据,并且去掉重复的基因行,最后获得第一列为基因symbol, 第一行为样本编号,中间数值为TPM,如下:
exp3<-merge(eg,exp2,by.x="ensembl",by.y="rowname",all.x=true) 1 2 3 4 5 exp4<-exp3[,3:ncol(exp3)] exp5<-exp4[!duplicated(exp4$symbol),] exp5[1:5,1:4] ## symbol tcga-3l-aa1b-01a-11r-a37k-07 tcga-4n-a93t-01a-11r-a37k-07 dbndd1 145.7848372 932.6654 hspb6 463.5507914 125.3295 pdk4 199.3329095 223.2314 abcb5 0.7485274 0.0000 prss22 441.2341966 1428.1244 tcga-4t-aa8h-01a-11r-a41b-07 477.12059 35.59667 241.33307 0.00000 247.16721 write.table(exp5,file="exp.txt" ,row.names="F,quote" = f,sep="\t" ) < code></-merge(eg,exp2,by.x="ensembl",by.y="rowname",all.x=true)>
2. CIBERSORT 分析结果
我们必要保证 ‘Cibersort.R’,’LM22.txt’ 和 ‘exp.txt’ 三个文件必须在同一个目录下,并且在同一文件夹下可以得到运算结果(”CIBERSORT-Results.txt”)。Cibersort结果的默认文件名为CIBERSORT-Results.txt,在同一文件夹下进行第二次运算会覆盖第一次得到的文件,建议在每一次运算之后对文件重命名。如果表达矩阵中基因不能完全覆盖LM22.txt中的基因,Cibersort 同样可以正常运行,但不能少于 “LM22.txt” 中所需基因的一半。
一条命令计算完毕,如下:
source('Cibersort.R')
CIBERSORT('LM22.txt','exp.txt', perm = 1000, QN = T) #perm置换次数=1000,QN分位数归一化=TRUE
读取结果文件 “CIBERSORT-Results.txt”,我们看下获得的结果,如下:
results<-read.table("cibersort-results.txt",header=true,row.names 0 = 1,check.names="FALSE,sep="\t")" results[1:5,] ## b cells naive memory plasma tcga-3l-aa1b-01a-11r-a37k-07 0.01395401 0.03348333 tcga-4n-a93t-01a-11r-a37k-07 0.03180062 0.11197878 tcga-4t-aa8h-01a-11r-a41b-07 0.02393778 0.11489327 tcga-5m-aat4-01a-11r-a41b-07 0.01961242 0.01678773 tcga-5m-aat5-01a-21r-a41b-07 0.03367153 0.10927705 t cd8 cd4 0.6226358 0.4945048 0.5156207 < code></-read.table("cibersort-results.txt",header=true,row.names>
我们看到后面几列的解释,如下:
- Sample:样本
- T Cell…:细胞浸润比例
- P-value : 置换检验(蒙特卡罗方法),越小越可信
- Correlation :原表达矩阵乘以细胞占比后的数据矩阵与原表达矩阵的相关性
- RMSE:均方根误差(Root Mean Squared Error),越小效果越好。
3. 结果展示
对于肿瘤的免疫浸润分析结果,有多种表现形式,我们这里主要说几种 SCI 文件中常见的图形,如热图,直方图,箱线图等。
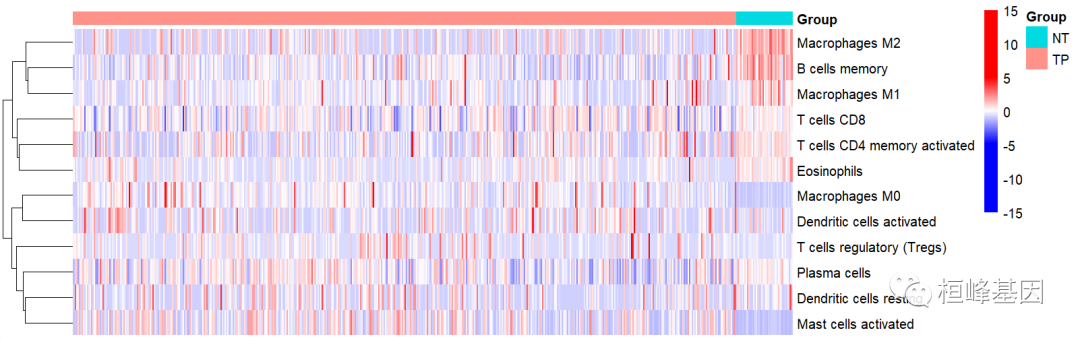
2.1 经典的免疫细胞丰度热图
library(pheatmap)
re <- results[,-(23:25)] k <- apply(re,2,function(x) {sum(x="=" 0) < nrow(results) 2}) re2 as.data.frame(t(re[,k])) ##########构造注释文件 an="data.frame(Group" = group$group, row.names="group$Sample)" ### #####修改色带,breaks bk c(seq(-15,-5,by="1),seq(-4.9,4.9,by=0.2),seq(5,15,by=1))" pheatmap(re2,scale="row" , show_colnames="F," cluster_cols="F," annotation_col="an," drop_levels="TRUE," color="c(rep("blue",11),colorRampPalette(colors" c("blue","white","red"))(50), rep("red",11)), breaks="bk," #legend_breaks="c(-5,-2,0,2,5)" ) code></->

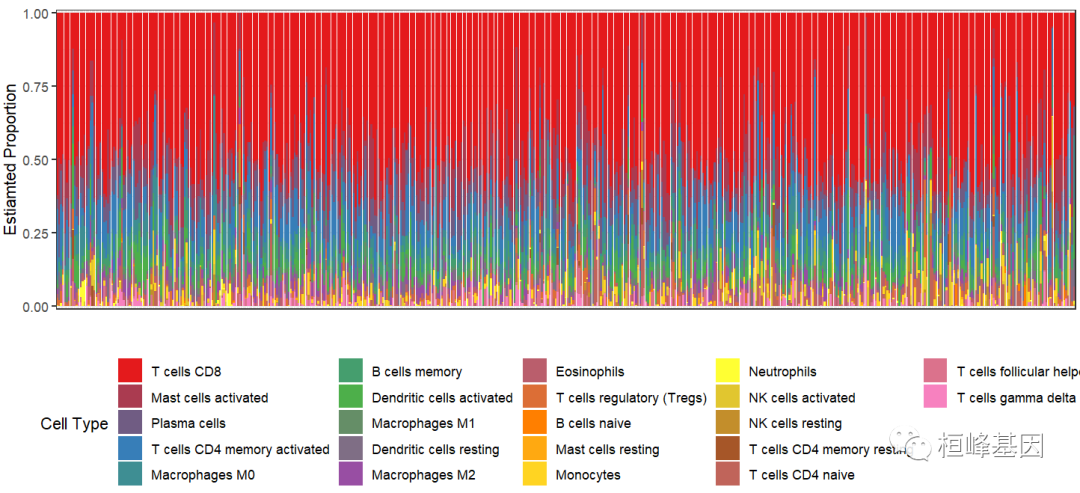
2.2 直方图
##########直方图
library(RColorBrewer)
library(tidyr)
mypalette <- colorramppalette(brewer.pal(8,"set1")) dat <- re %>% as.data.frame() %>%
rownames_to_column("Sample") %>%
gather(key = Cell_type,value = Proportion,-Sample)
ggplot(dat,aes(Sample,Proportion,fill = Cell_type)) +
geom_bar(stat = "identity") +
labs(fill = "Cell Type",x = "",y = "Estiamted Proportion") +
theme_bw() +
theme(axis.text.x = element_blank(),
axis.ticks.x = element_blank(),
legend.position = "bottom") +
scale_y_continuous(expand = c(0.01,0)) +
scale_fill_manual(values = mypalette(22))
</->
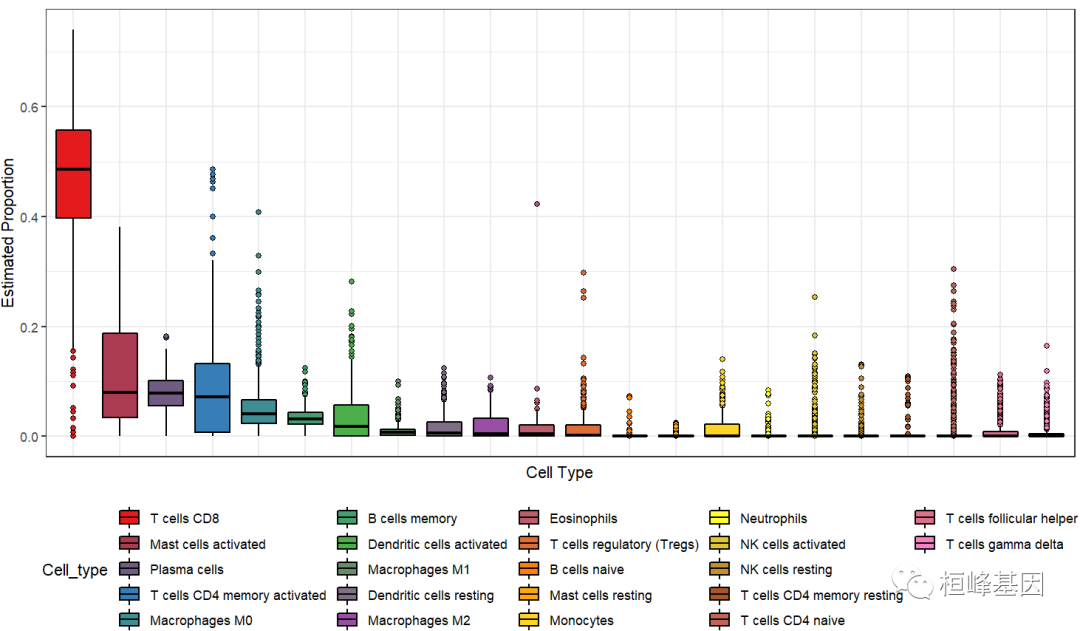
2.3 箱式图
#####箱式图
ggplot(dat,aes(Cell_type,Proportion,fill = Cell_type)) +
geom_boxplot(outlier.shape = 21,color = "black") +
theme_bw() +
labs(x = "Cell Type", y = "Estimated Proportion") +
theme(axis.text.x = element_blank(),
axis.ticks.x = element_blank(),
legend.position = "bottom") +
scale_fill_manual(values = mypalette(22))
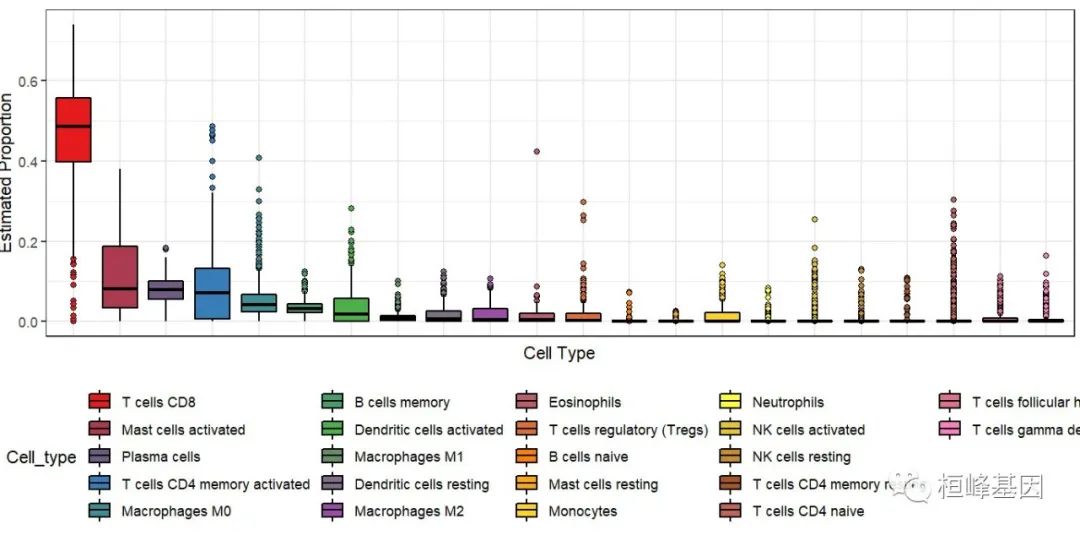
2.4 排序的箱式图
###########排序
library(dplyr)
a = dat %>%
group_by(Cell_type) %>%
summarise(m = median(Proportion)) %>%
arrange(desc(m)) %>%
pull(Cell_type)
dat$Cell_type = factor(dat$Cell_type,levels = a)
ggplot(dat,aes(Cell_type,Proportion,fill = Cell_type)) +
geom_boxplot(outlier.shape = 21,color = "black") +
theme_bw() +
labs(x = "Cell Type", y = "Estimated Proportion") +
theme(axis.text.x = element_blank(),
axis.ticks.x = element_blank(),
legend.position = "bottom") +
scale_fill_manual(values = mypalette(22))
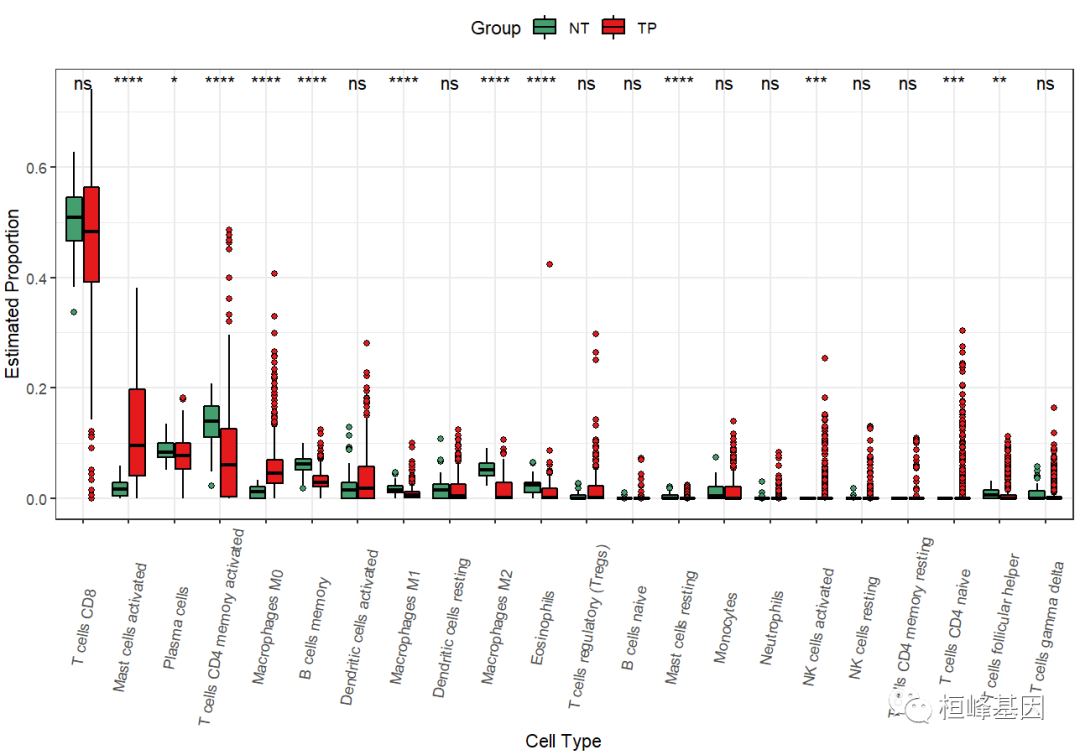
2.5 添加分组显著性
############tumor -vs- normal
library(stringr)
library(ggpubr)
dat$Group = ifelse(as.numeric(str_sub(dat$Sample,14,15))<10,"tp","nt") ggplot(dat,aes(cell_type,proportion,fill="Group))" + geom_boxplot(outlier.shape="21,color" = "black") theme_bw() labs(x="Cell Type" , y="Estimated Proportion" ) theme(legend.position="top" theme(axis.text.x="element_text(angle=80,vjust" 0.5))+ scale_fill_manual(values="mypalette(22)[c(6,1)])+" stat_compare_means(aes(group="Group,label" ..p.signif..),method="kruskal.test" < code></10,"tp","nt")>
个人感觉总结的已经很全面了,不足的地方请大家指正。
关注公众号,每日更新,扫码进群交流不停歇,马上就出视频版,关注我,您最佳的选择!

桓峰基因
生物信息分析,SCI文章撰写及生物信息基础知识学习:R语言学习,perl基础编程,linux系统命令,Python遇见更好的你
49篇原创内容
公众号
References:
-
Newman AM, Alizadeh AA. Determining cell type abundance and expression from bulk tissues with digital cytometry. Nat Biotechnol. 2019 Jul;37(7):773-782. doi: 10.1038/s41587-019-0114-2. Epub 2019 May 6. PMID: 31061481; PMCID: PMC6610714.
-
Chen B, Khodadoust MS, Liu CL, Newman AM, Alizadeh AA. Profiling Tumor Infiltrating Immune Cells with CIBERSORT. Methods Mol Biol. 2018;1711:243-259. doi: 10.1007/978-1-4939-7493-1_12. PMID: 29344893; PMCID: PMC5895181.
-
Li B, Cui Y, Nambiar DK, Sunwoo JB, Li R. The Immune Subtypes and Landscape of Squamous Cell Carcinoma. Clin Cancer Res. 2019 Jun 15;25(12):3528-3537. doi: 10.1158/1078-0432.CCR-18-4085. Epub 2019 Mar 4. PMID: 30833271; PMCID:
- Newman, A., Liu, C., Green, M. et al. Robust enumeration of cell subsets from tissue expression profiles. Nat Methods 12, 453–457 (2015).
Original: https://blog.csdn.net/weixin_41368414/article/details/123318745
Author: 桓峰基因
Title: RNA 12. SCI 文章中肿瘤免疫浸润计算方法之 CIBERSORT
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/639020/
转载文章受原作者版权保护。转载请注明原作者出处!