

MAE
平均绝对误差(Mean Absolute Error)
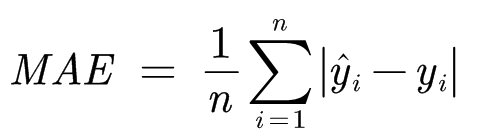

MSE
均方误差(Mean Squared Error)
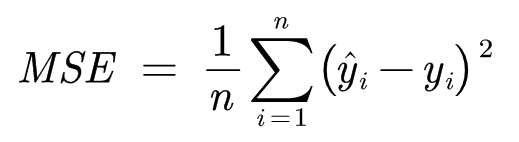
RMSE
均方根误差(Root Mean Square Error)
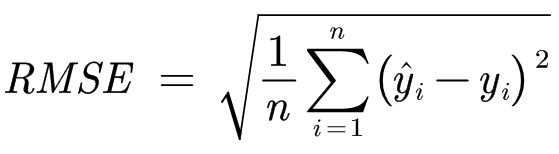
MAPE
平均绝对百分比误差(Mean Absolute Percentage Error)
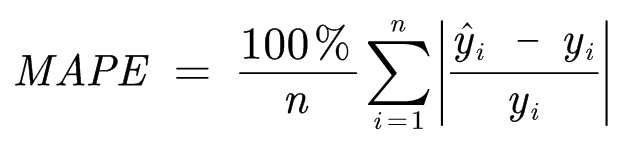
R-Squared
确定系数
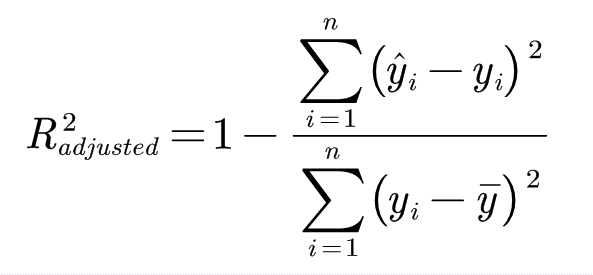
对于回归类算法而言,只探索数据预测是否准确是不足够的。除了数据本身的数值大小之外,我们还希望我们的模型能够捕捉到数据的”规律”,比如数据的分布规律,单调性等等,而是否捕获了这些信息并无法使用MSE来衡量。
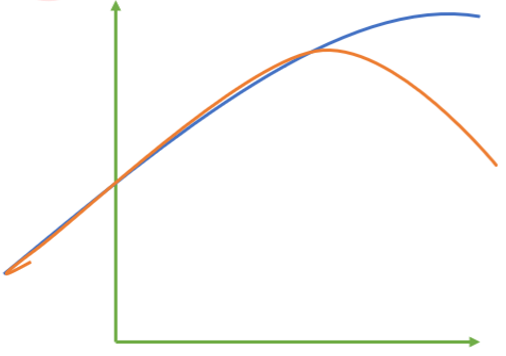
- 上图中红色线是我们的真实标签,而蓝色线是我们的拟合模型。这是一种比较极端,但的确可能发生的情况。这张图像上,前半部分的拟合非常成功,看上去我们的真实标签和我们的预测结果几乎重合,但后半部分的拟合却非常糟糕,模型向着与真实标签完全相反的方向去了。对于这样的一个拟合模型,如果我们使用MSE来对它进行判断,它的MSE会很小,因为大部分样本其实都被完美拟合了,少数样本的真实值和预测值的巨大差异在被均分到每个样本上之后,MSE就会很小。但这样的拟合结果必然不是一个好结果,因为一旦新样本是处于拟合曲线的后半段的,预测结果必然会有巨大的偏差,而这不是我们希望看到的。所以,我们希望找到新的指标, 除了判断预测的数值是否正确之外,还能够判断我们的模型是否拟合了足够多的,数值之外的信息。
- 方差的本质是任意一个值和样本均值的差异,差异越大,这些值所带的信息越多。在中,分子是真实值和预测值的差值平方和,也就是我们的模型没有捕获到的信息总量,分母是真实标签所带的信息量,所以两者衡量了 1 – 我们的模型没有捕获到的信息量占真实标签中所带的信息量的比例。
- 的计算结果越接近1,说明模型拟合的效果越好。
Adjusted R-Squared
调整后的
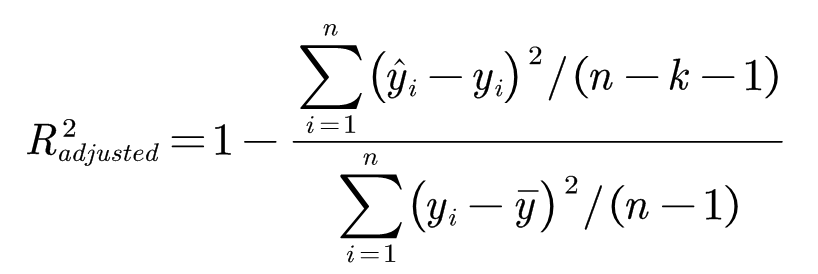
- 上式中 n 是样本数量,k 是特征数量。Adjusted R-Squared 抵消特征数量对 R-Squared 的影响,真正的做到了计算结果越接近1,模型拟合的效果越好。
- 因为在模型中,增加多个变量,即使事实上是无关的变量,也会小幅度提高 R-Squared 的值,这是没有意义的,所有我们要对其值进行降低调整了。
- 简单地说就是,用 R-Squared 的时候,不断添加变量能让模型的效果提升,而这种提升是虚假的。利用 Adjusted R-Squared,能对添加的非显著变量给出惩罚,也就是说随意添加一个变量不一定能让模型拟合度上升。
今天天气不错,心情也不错。
Original: https://blog.csdn.net/weixin_46803857/article/details/122782375
Author: 拟禾
Title: 回归评价指标:MAE、MSE、RMSE、MAPE和R-Squared
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/639004/
转载文章受原作者版权保护。转载请注明原作者出处!