



点击关注,桓峰基因
桓峰基因
生物信息分析,SCI文章撰写及生物信息基础知识学习:R语言学习,perl基础编程,linux系统命令,Python遇见更好的你
122篇原创内容
公众号
这期讲讲单样本基因富集分析,这个也蛮有意思的之前我已经介绍过基因集富集分析(GSEA),但是当时是用差异基因来分析,这期我们就通过单基因免疫浸润的方法来介绍一下。

; 前言
single sample Gene Set Enrichment Analysis (ssGSEA) 是针对单个样本进行 GSEA 分析,其基因列表的排序方式和 ES 的计算方式都是依赖于样本中基因的表达值,而不再是依赖基因与表型的相关度。
基本原理
对于一个基因表达矩阵,ssGSEA首先对样本的所有基因的表达水平进行排序获得其在所有基因中的秩次rank。然后对于输入的基因集,从基因集中寻找表达数据里存在的基因并计数,并将这些基因的表达水平求和。接着基于上述求值,计算通路中每个基因的富集分数,并进一步打乱基因顺序重新计算富集分数,重复一千次,最后根据基因富集分数的分布计算p值整合基因集最终富集分数。
1.single sample GSEA 是通过扩展GESA扩展实现的,ssGSEA允许定义一个富集分数,该分数表示给定数据集内每个样本中基因集的绝对富集程度;
2.对给定样本的基因表达值进行排序归一化,并使用签名中的基因和其余基因的经验累积分布函数(ECDF)生成富集分数
3.ssGSEA过程类似于GSEA,但是在ssGSEA列表是根据absolute expression进行排序的;
4.浓缩分数(ES)是通过对ECDFs之间的差值进行积分得到的。对于单个样本的N个基因以及给定大小为signature (假设是条通路的基因)数据集的,根据它们的absolute expression .L={r1, r2,…,rN},用它们的秩替换它们。然后将列表从最高的N排列到最低的1。富集分数ES(G,S)是由一个加权的基因的ECDF和其余基因的ECDF之间的差值之和(积分)得到的:
1.如果基因属于 ,则是该基因的表达量/表达量的总和;
- 如果基因不属于 ,则就等于;
- 计算每个基因的ES,然后根据最大差异来得到这条通路的ES(绝对值最大的ES作为通路的ES);
- 指数(α)设置为¼,并添加一个适中的重量等级。在常规的GSEA中使用了类似的浓缩分数,但是权重通常设置为1。
实例分析
1. 软件安装
这里我们安装GSVA的软件包,另外在数据处理时安装几个其他的包,如下:
if (!requireNamespace("BiocManager", quietly = TRUE)) install.packages("BiocManager")
if (!requireNamespace("GSVA", quietly = TRUE)) BiocManager::install("GSVA")
if (!requireNamespace("limma", quietly = TRUE)) BiocManager::install("limma")
if (!require("GSEABase", quietly = TRUE)) {
BiocManager::install("GSEABase")
}
if (!require(TCGAbiolinks)) {
BiocManager::install("TCGAbiolinks")
}
if (!require(clusterProfiler)) {
BiocManager::install("clusterProfiler")
}
library(limma)
library(GSVA)
library(GSEABase)
library(clusterProfiler)
library(reshape2)
library(TCGAbiolinks)
library(pheatmap)
library(clusterProfiler)
2. 数据读取
数据要求
1、特定感兴趣的基因集(如信号通路,GO条目,免疫基因等),列出基因集中基因
2、基因表达矩阵,为经过log2标准化的芯片数据或者RNA-seq count数数据(基因名形式与基因集对应)
我们仍然使用的是 TCGA-COAD的数据集,表达数据的读取以及临床信息分组的获得我们上期已经提过.
表达矩阵
下载后,需要转换一下基因名称,如下:
exp = data.frame(read.csv("COAD_dataPrep.csv", check.names = F, header = T))
exp[1:3, 1:3]
## Var.1 TCGA.3L.AA1B.01A.11R.A37K.07 TCGA.4N.A93T.01A.11R.A37K.07
## 1 ENSG00000000003 7280 7164
## 2 ENSG00000000005 23 67
## 3 ENSG00000000419 2065 2632
colnames(exp) = gsub("[.]", "-", colnames(exp))
eg <- 1 2 3 4 5 6 23 41 67 89 478 848 2065 2632 2927 7164 7280 bitr(exp$var-1, fromtype="ENSEMBL" , totype="c("ENTREZID"," "ensembl", "symbol"), orgdb="org.Hs.eg.db" ) mergedata <- merge(eg, exp, by.x="ENSEMBL" by.y="Var-1" mergedata[!duplicated(mergedata$symbol), ] expmatrix mergedata[, 4:ncol(mergedata)] rownames(expmatrix)="mergedata[," 3] expmatrix[1:3, 1:3] ## tcga-3l-aa1b-01a-11r-a37k-07 tcga-4n-a93t-01a-11r-a37k-07 tspan6 tnmd dpm1 tcga-4t-aa8h-01a-11r-a41b-07 group read.table("deg-group.xls", sep="\t" check.names="F," header="T)" table(group$group) nt tp head(group) sample tcga-d5-6530-01a-11r-1723-07 tcga-g4-6320-01a-11r-1723-07 tcga-ad-6888-01a-11r-1928-07 tcga-ck-6747-01a-11r-1839-07 tcga-aa-3975-01a-01r-1022-07 tcga-a6-6780-01a-11r-1839-07 < code></->
免疫浸润基因集
免疫浸润基因集需要我们在文章中下载,发表在Cell的一篇文章,如下:
下载地址如下:
http://cis.hku.hk/TISIDB/data/download/CellReports.txt
现在之后需要改一下格式,变成list格式,如下:
gene.set = read.table("mmc3.txt", stringsAsFactors = F, sep = "\t", header = T, check.names = F)[,
1:2]
head(gene.set)
## Metagene Cell type
## 1 ADAM28 Activated B cell
## 2 CD180 Activated B cell
## 3 CD79B Activated B cell
## 4 BLK Activated B cell
## 5 CD19 Activated B cell
## 6 MS4A1 Activated B cell
library(reshape2)
geneSets = split(1:dim(gene.set)[1], gene.set$Cell type) %>%
lapply(function(x) {
gene.set[unlist(x), 1]
})
head(geneSets, 2)
## $Activated B cell
## [1] "ADAM28" "CD180" "CD79B" "BLK" "CD19" "MS4A1"
## [7] "TNFRSF17" "IGHM" "GNG7" "MICAL3" "SPIB" "HLA-DOB"
## [13] "IGKC" "PNOC" "FCRL2" "BACH2" "CR2" "TCL1A"
## [19] "AKNA" "ARHGAP25" "CCL21" "CD27" "CD38" "CLEC17A"
## [25] "CLEC9A" "CLECL1"
##
## $Activated CD4 T cell
## [1] "AIM2" "BIRC3" "BRIP1" "CCL20" "CCL4" "CCL5" "CCNB1" "CCR7"
## [9] "DUSP2" "ESCO2" "ETS1" "EXO1" "EXOC6" "IARS" "ITK" "KIF11"
## [17] "KNTC1" "NUF2" "PRC1" "PSAT1" "RGS1" "RTKN2" "SAMSN1" "SELL"
## [25] "TRAT1"
3. 例子实操
kcdf的方法选择根据自己的数据情况不同,选择不同的计算方法,比如我们的数据是Read Counts,那么我们就选择 “Poisson”。
kcdf:Character string denoting the kernel to use during the non-parametric estimation of the cumulative distribution function of expression levels across samples when method=”gsva”. By default, kcdf=”Gaussian” which is suitable when input expression values are continuous, such as microarray fluorescent units in logarithmic scale, RNA-seq log-CPMs, log-RPKMs or log-TPMs. When input expression values are integer counts, such as those derived from RNA-seq experiments, then this argument should be set to kcdf=”Poisson”.
ssgsea<-gsva(as.matrix(expmatrix), genesets, method="ssgsea" , min.sz="10)" ssgsea[1:3, 1:2]## tcga-3l-aa1b-01a-11r-a37k-07 tcga-4n-a93t-01a-11r-a37k-07## activated b cell 0.4251134 0.3742325## cd4 t 0.5324122 0.5193579## cd8 0.6129071 0.5807931 < code></-gsva(as.matrix(expmatrix),>
4. 结果展示
我们可以对数据进一步的通过图形展示,包括火山图和热图,清晰的看到免疫细胞的分组。
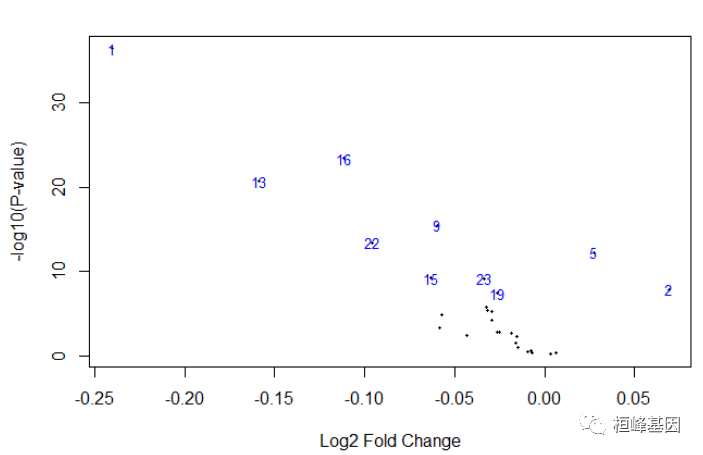
免疫浸润火山图
对免疫细胞做差异分析,由于我们获得的矩阵是非整数型的,所以我们选择limma计算差异,如下:
DEA.ssgsea <- tcgaanalyze_dea(mat1="ssgsea[," group[group$group="=" "nt", ]$sample], mat2="ssgsea[," "tp", metadata="FALSE," pipeline="limma" , cond1type="NT" cond2type="TP" fdr.cut="0.05," logfc.cut="2," ) < code></->
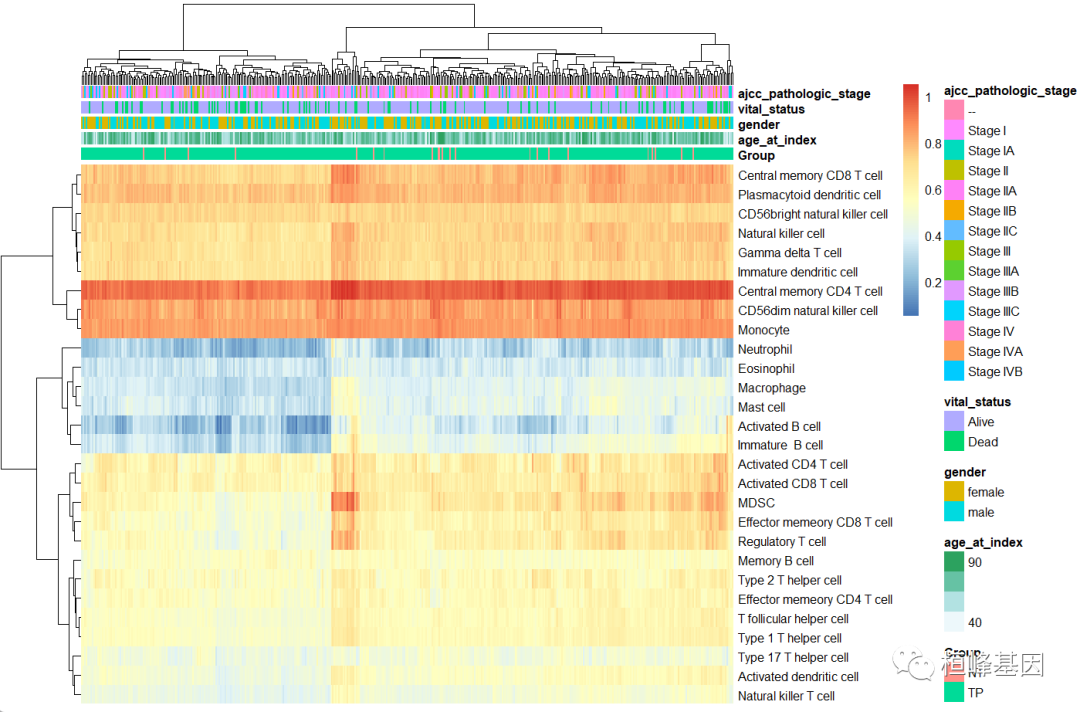
免疫浸润热图
读取临床数据,并选择有效的临床信息,如下:
rowclin <- 1 2 3 4 5 6 7 9 11 37 40 41 42 51 61 64 67 72 74 76 80 469 read.table("clinical.tsv", header="1," check.names="F," sep="\t" ) clin <- data.frame(rowclin[, c(2, 4, 12, 16, 28)]) clin[!duplicated(clin$case_submitter_id), ] head(clin) ## case_submitter_id age_at_index gender vital_status ajcc_pathologic_stage tcga-g4-6307 female alive stage iiib tcga-aa-3522 male iia tcga-aa-3530 i tcga-aa-3511 ii tcga-aa-3842 iiia tcga-aa-3561 colnames(ssgsea)="substr(colnames(ssgsea)," 1, 12) group$sample="substr(group$Sample," head(group) sample group tcga-d5-6530 tp tcga-g4-6320 tcga-ad-6888 tcga-ck-6747 tcga-aa-3975 tcga-a6-6780 clin_group="merge(group," clin, by.x="Sample" , by.y="case_submitter_id" head(clin_group) tcga-3l-aa1b tcga-4n-a93t tcga-4t-aa8h tcga-5m-aat4 dead iv tcga-5m-aat6 tcga-5m-aate table(clin_group$group) nt clin_group[!duplicated(clin_group$sample), ann_col clin_group[, 2:6] rownames(ann_col) clin_group$sample # names(ann_col)="c('TNM" stage','cluster') head(ann_col) < code></->
绘制火山图,并添加临床信息,如下:
pheatmap(
ssgsea[,clin_group$Sample],
show_colnames = F,
# 不展示行名
cluster_rows = T,
# 不对行聚类
cluster_cols = T,
# 不对列聚类
annotation_col = ann_col,
# 加注释
# cellwidth = 5,
#cellheight = 5,
# 设置单元格的宽度和高度
fontsize = 8
)
结果解读
从差异分析的结果图上我们能看到28种免疫细胞的差异,而热图中可将28种细胞分为三大类。
桓峰基因公众号,可以做RNA系列分析,都是SCI级别分析方法,今天刚好整理了一下:
RNA 1. 基因表达那些事–基于 GEO
RNA 2. SCI文章中基于GEO的差异表达基因之 limma
RNA 3. SCI 文章中基于T CGA 差异表达基因之 DESeq
RNA 4. SCI 文章中基于TCGA 差异表达之 edgeR
RNA 5. SCI 文章中差异基因表达之 MA 图
RNA 6. 差异基因表达之– 火山图 (volcano)
RNA 7. SCI 文章中的基因表达——主成分分析 (PCA)
RNA 8. SCI文章中差异基因表达–热图 (heatmap)
RNA 9. SCI 文章中基因表达之 GO 注释
RNA 10. SCI 文章中基因表达富集之–KEGG
RNA 11. SCI 文章中基因表达富集之 GSEA
RNA 12. SCI 文章中肿瘤免疫浸润计算方法之 CIBERSORT
RNA 13. SCI 文章中差异表达基因之 WGCNA
RNA 14. SCI 文章中差异表达基因之 蛋白互作网络 (PPI)
RNA 15. SCI 文章中的融合基因之 FusionGDB2
RNA 16. SCI 文章中的融合基因之可视化
RNA 17. SCI 文章中的筛选 Hub 基因 (Hub genes)
RNA 18. SCI 文章中基因集变异分析 GSVA
RNA 19. SCI 文章中无监督聚类法 (ConsensusClusterPlus)
RNA 20. SCI 文章中单样本免疫浸润分析 (ssGSEA)
我们每周都会推出1-2篇可以直接使用公众号生信分析方法进行文章的复现,关注桓峰基因,科研路上不迷路,想做科研没思路,加我微信获得最快的资讯!
References:
-
Bindea C, Mlecnik B,Tosolini M, Kirilovsky A, Waldner M, Obenauf AC, et al. Spatiotemporal dynamics of intratumoral immune cells reveal the immune landscape in human cancer. lmmunity. 2013;39(4):782-95.
-
Charoentong P, Finotello F, Angelova M, et al. Pan-cancer Immunogenomic Analyses Reveal Genotype-Immunophenotype Relationships and Predictors of Response to Checkpoint Blockade. Cell Rep. 2017;18(1):248-262. doi:10.1016/j.celrep.2016.12.019
- Barbie DA, Tamayo P, Boehm JS, et al. Systematic RNA interference reveals that oncogenic KRAS-driven cancers require TBK1. Nature. 2009;462(7269):108-112. doi:10.1038/nature08460
- Xiao B, Liu L, Li A, et al. Identification and Verification of Immune-Related Gene Prognostic Signature Based on ssGSEA for Osteosarcoma. Front Oncol. 2020;10:607622. Published 2020 Dec 15. doi:10.3389/fonc.2020.607622
Original: https://blog.csdn.net/weixin_41368414/article/details/125419875
Author: 桓峰基因
Title: RNA 20. SCI 文章中单样本免疫浸润分析 (ssGSEA)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/638630/
转载文章受原作者版权保护。转载请注明原作者出处!