

目录
- 前言
- 一、相关分析
* - 1、概念
- 2、数据来源及处理
- 3、分析
– - 二、回归分析
* - 1、概念
- 2、一元线性回归
- 3、多元回归
- 三、逻辑回归
* - 1、概念
- 2、逻辑回归
- 3、拟合效果
- 四、时间序列分析
* - 1、概念
- 结语
前言
之前的一篇文章【实战】——基于机器学习回归模型对广州二手房价格进行分析及模型评估中,主要分享了数据处理和模型评估两大部分内容
今天,我们接着这一部分内容,深入了解数据的属性以及模型的建立
一、相关分析
1、概念
研究各个因素之间是否存在相互影响以及找出这种影响的数学描述方法,是数据挖掘的重要工作之一。判定或量化各因素之间联系的强弱,就是属于 相关分析的范畴。
2、数据来源及处理
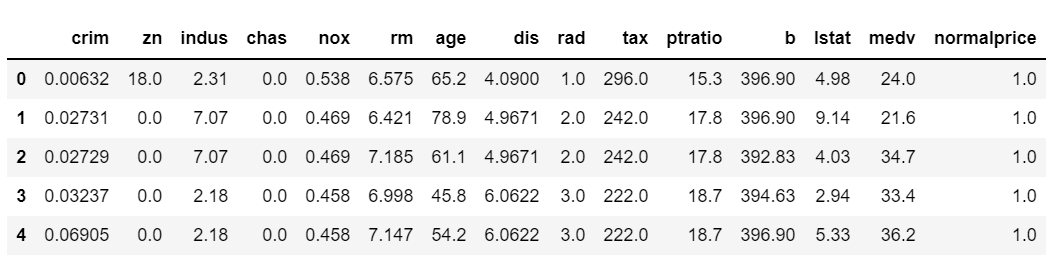
数据采集了美国波士顿地区房价与周边环境因素的量化值,共有14个字段:
字段名含义crim地区人均犯罪率zn住宅用地>25000英尺比例indus非零售商业用地比例chas查尔斯河空变量(地区边界是河,值取1,否则为0)nox一氧化氮浓度rm每套住宅平均房间数age1940年后建成自用房比例dis与波士顿中心区距离rad与主要公路的接近指数tax财产税率ptratio师生比b1000*(
B k B_k B k
-0.63)
2 ^2 2
,B
k _k k
为非洲裔美国人比例lstat低地位人口比例medv自住房平均房价,以千美元计
import numpy as np
import pandas as pd
from sklearn.datasets import load_boston
boston = load_boston()
col = ['crim','zn','indus','chas','nox','rm','age','dis','rad','tax','ptratio','b','lstat']
bostondf = pd.DataFrame(boston.data,columns=col)
bostondf['medv']=boston.target
bostondf.head()

3、分析
3.1、协方差
协方差是衡量两个变量的总体误差
设(X,Y)是二元随机变量,随机变量X与Y的协方差记为: cov(X,Y)=E{[X-E(X)][Y-E(Y)]},其中E(X)为X的均值。协方差是没有单位的量,具有以下数学性质:
- cov(X,Y)=cov(Y,X)
- 如果cov(X,Y)>0,则称随机变量X和Y之间存在正相关;如果cov(X,Y)
bostondf.cov()

对于DataFrame数据对象,可以直接调用pandas提供的
cov函数,进行简便的协方差计算。其中字段相同的是方差,不同的则是协方差。
3.2、相关系数
相关系数是研究变量之间线性相关程度的量
相关系数记为: p(X,Y)=cov(X,Y)/(var(X)*var(Y))^0.5,其中var(X)为X的方差。相关系数是没有单位的量,,具有以下数学性质:
- |p|
bostondf.corr()
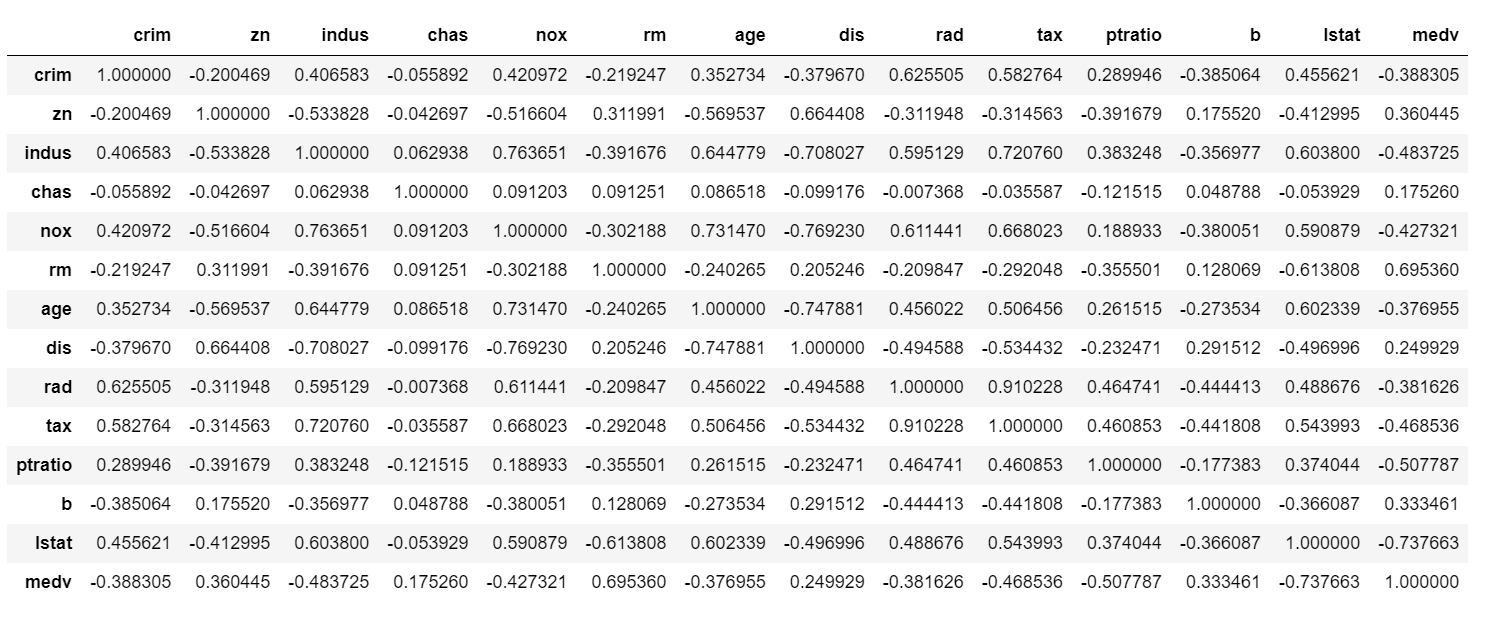
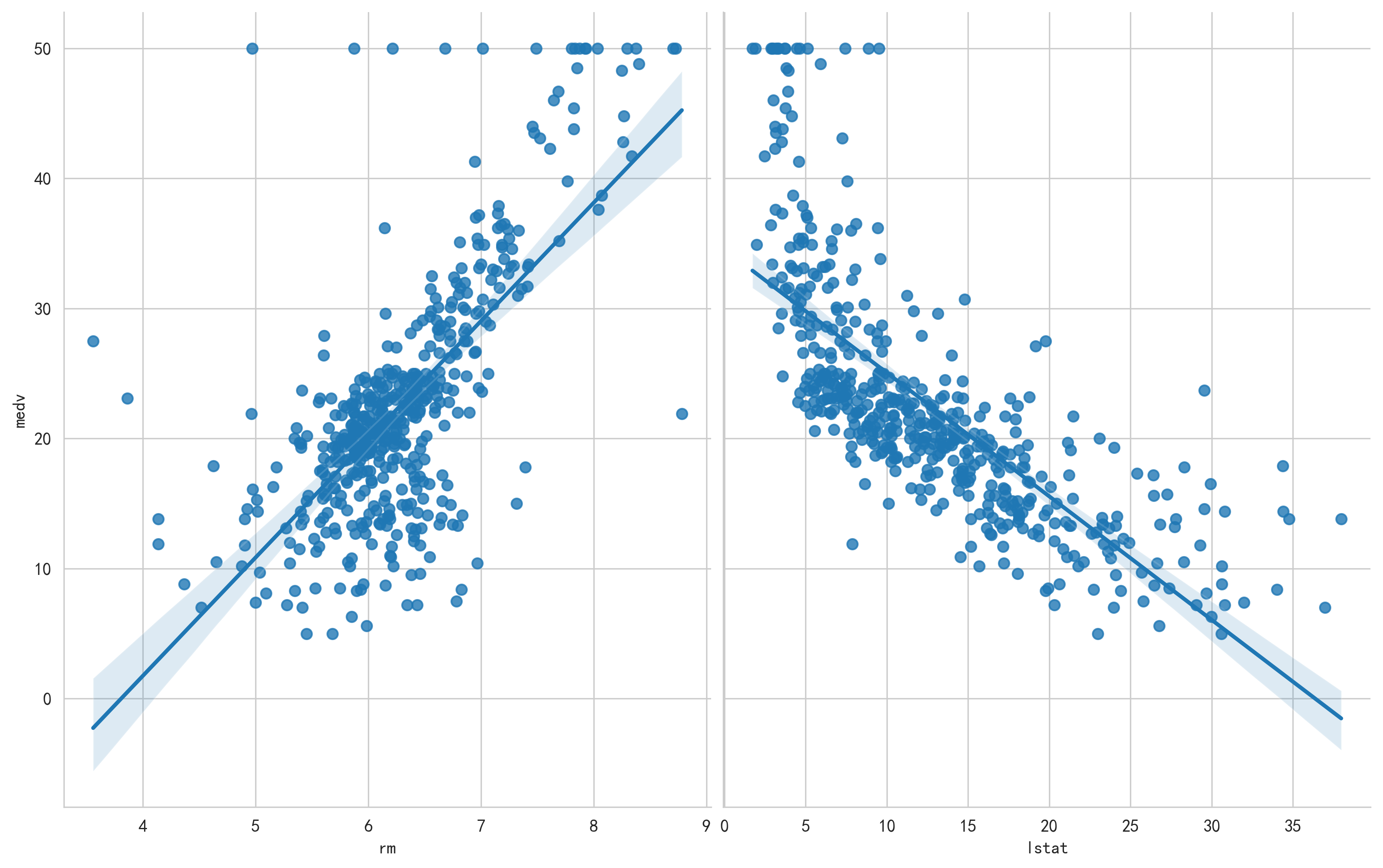
从表中可以看出,自变量rm与因变量medv的相关系数为0.695360,正的线性关系比较强;而自变量lstat与因变量medv的相关系数为-0.737663,负的线性关系比较明显。
即可得出结论:每套住宅平均房间数越多,房屋均价越高;该地区的低地位人口比例越大,房屋均价越低。
二、回归分析
1、概念
基于大量数据观察,利用数理统计方法建立因变量与自变量之间的回归关系函数(也称回归方程),属于 回归分析的范畴。
2、一元线性回归
以一元线性方程来讨论回归的数学内涵:如现有k个观察数据对(x i _i i ,y i _i i ),求一元线性方程,且希望方程与观测值数据尽可能地重合
假设拟合方程为 y = a*x + b,将观察数据中的x代入,得到 y1 = a*x + b,与观察数据中的y的误差为 error = y - y1 = y - (a*x + b)
设目标函数为:

为了使error更小,即C取极小值时,对a、b偏导为0:
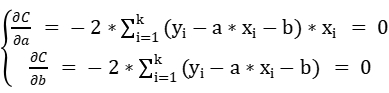
解得:
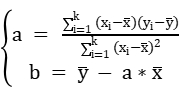
由此,可以得到回归方程:
y = a*x + b
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
sns.set_style('whitegrid',{'font.sans-serif':['simhei','Arial']})
sns.pairplot(bostondf,x_vars=['rm','lstat'],y_vars='medv',height=7,aspect=0.8,kind='reg')
plt.savefig('回归分析.png',dpi=300,bbox_inches='tight')
plt.show()
from sklearn.linear_model import LinearRegression
bostonrm = pd.DataFrame()
modelrm = LinearRegression()
modelrm.fit(bostondf['rm'].values.reshape(-1,1),bostondf['medv'].values.reshape(-1,1))
print("系数:",modelrm.coef_)
print("截距:",modelrm.intercept_)
print("rm与medv的线性回归方程:")
print('y = %+.4f*x% + .4f'%(modelrm.coef_[0][0],modelrm.intercept_[0]))

以rm为自变量的一元回归方程:
medv = 9.1021 * (rm) - 34.6706
modellstat = LinearRegression()
modellstat.fit(bostondf['lstat'].values.reshape(-1,1),bostondf['medv'].values.reshape(-1,1))
print("系数:",modellstat.coef_)
print("截距:",modellstat.intercept_)
print("lstat与medv的线性回归方程:")
print('y = %+.4f*x% + .4f'%(modellstat.coef_[0][0],modellstat.intercept_[0]))

同理,以lstat为自变量的一元回归方程:
medv = -0.9500 * (lstat) + 34.5538
3、多元回归
进一步,可以以rm、lstat为自变量计算得出多元回归方程
modelmulti = LinearRegression()
modelmulti.fit(bostondf[['lstat','rm']].values,bostondf['medv'].values.reshape(-1,1))
print("系数:",modelmulti.coef_)
print("截距:",modelmulti.intercept_)
print("lstat与medv的线性回归方程:")
print('y = %+.4f*(lstat)%+.4f*(rm)% +.4f'%(modelmulti.coef_[0][0],modelmulti.coef_[0][1],modelmulti.intercept_[0]))

如上,多元回归方程为:
y = -0.6424 * (lstat) + 5.0948 * (rm) - 1.3583
三、逻辑回归
1、概念
逻辑回归是一种广义的线性回归分析方法,回归方程输出的不是连续值,而是离散的分类结果,本质上是一种分类的方法。
逻辑回归问题虽然采用同样的线性方程作为数学描述,但输出的y是在线性方程结果上加工而来的,是离散值,一般是0或1:
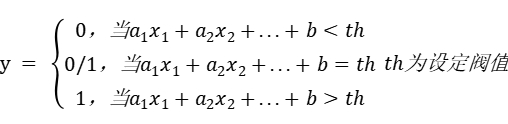
但经研究,直接用线性方程的值作为阀值存在一些不足,进而发展出一个应用广泛的阀值表示函数 Sigmoid函数:f(x) = 1/(1 + e-x)
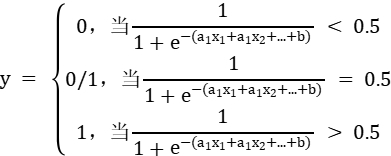
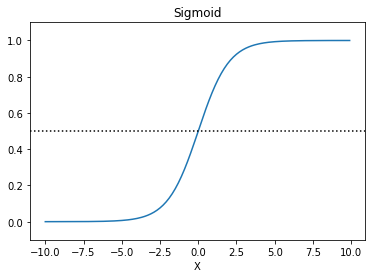
; 2、逻辑回归
以上节数据为例
bostondf['medv'].describe()

假设当房价高于17.025(1/4分位数)时,为贵价房屋;反之为平价房屋
bostondf['normalprice']=bostondf['medv'].apply(lambda s:np.float(s>=17.025))
bostondf.head()
模型代码就不细讲了,在前言提到的那一篇中已经写得比较清楚了
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
X = bostondf.drop(labels=['medv','normalprice'],axis=1)
Y = bostondf['normalprice']
x_train,x_test,y_train,y_test = train_test_split(X,Y,test_size=0.1)
scaler = StandardScaler().fit(x_train)
x_train = pd.DataFrame(scaler.transform(x_train),columns=x_train.columns)
x_test = pd.DataFrame(scaler.transform(x_test),columns=x_test.columns)
houselr = LinearRegression()
houselr.fit(x_train,y_train)
print("系数:",houselr.coef_)
print("截距:",houselr.intercept_)
最终得出结果:

结合Sigmoid函数就可以得出逻辑回归方程了
3、拟合效果
print('R值(训练集准确率):',houselr.score(x_train,y_train))
print('R值(测试集准确率):',houselr.score(x_test,y_test))
Out: R值(训练集准确率): 0.5804979485121928
R值(测试集准确率): 0.5804471010809136
y_pred = houselr.predict(x_test)
x = range(len(x_test))
plt.figure(figsize=(14,7),facecolor='w')
plt.ylim(-0.1,1.5)
plt.axhline(y=0.5,ls='dotted',color='k')
plt.plot(x,y_test,'ro',marker='*',markersize=16,label='真实值')
plt.plot(x,y_pred,'go',markersize=14,label='预测值,$R^2$=%.3f'%houselr.score(x_test,y_test))
plt.legend(loc='best')
plt.xlabel('训练集样本编号',fontsize=18)
plt.ylabel('是否平价房屋',fontsize=18)
plt.title('Logistic算法对数据进行分类',fontsize=20)
plt.savefig('Logistic算法.png',dpi=300,bbox_inches='tight')
plt.show()
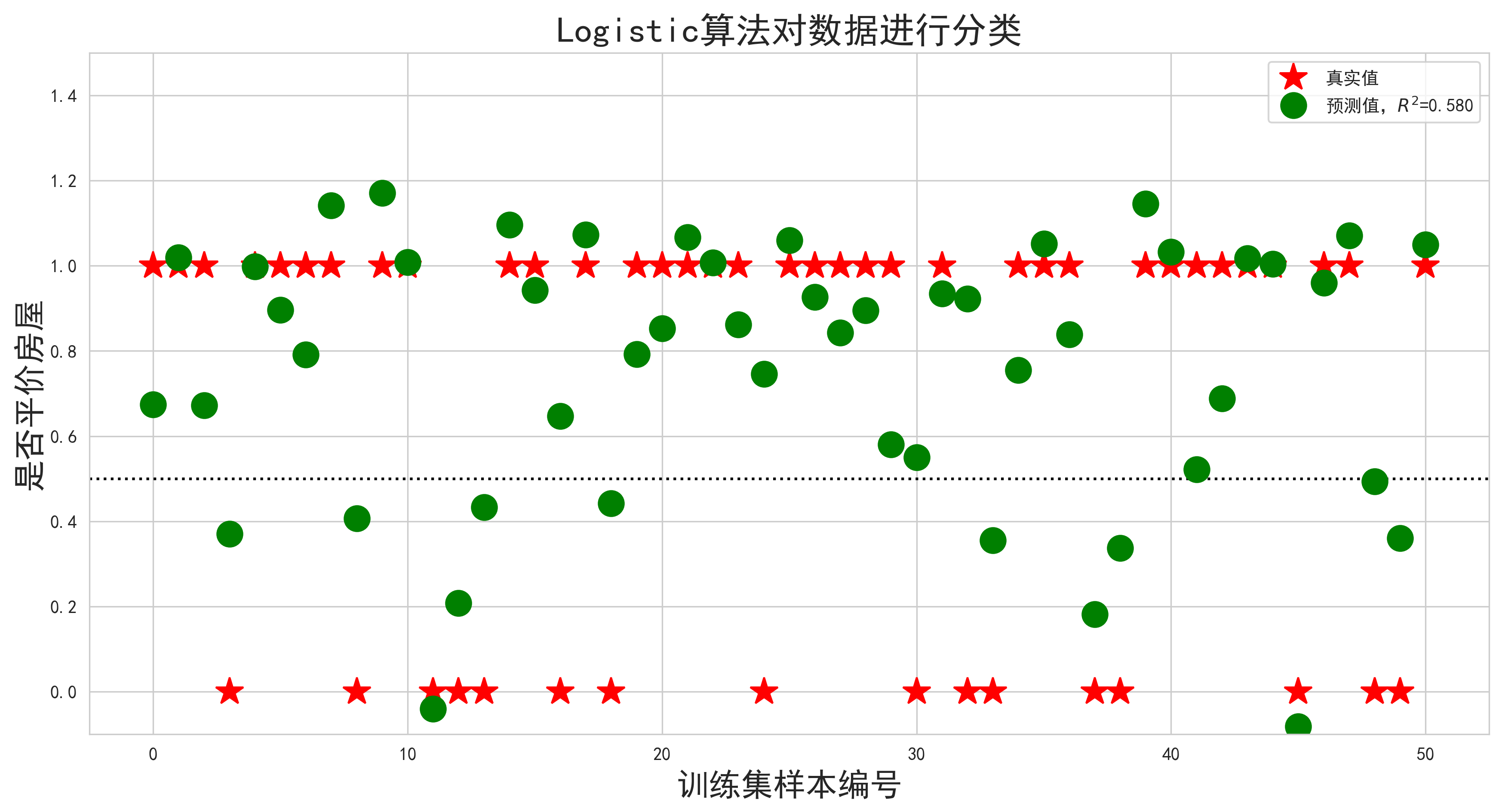
这样看起来也许不是很明显,我们以0.5为界,将预测值也改为0和1的值:
y_pred1 = y_pred
for i,x in enumerate(y_pred1):
if x>0.5:
y_pred1[i]=1
if x<0.5:
y_pred1[i]=0
x = range(len(x_test))
plt.figure(figsize=(14,7),facecolor='w')
plt.ylim(-0.1,1.1)
plt.plot(x,y_test,'ro',marker='*',markersize=16,label='真实值')
plt.plot(x,y_pred1,'go',markersize=14,label='bool预测值',alpha=0.4)
plt.legend(loc='best')
plt.xlabel('训练集样本编号',fontsize=18)
plt.ylabel('是否平价房屋',fontsize=18)
plt.title('Logistic算法对数据进行分类',fontsize=20)
plt.savefig('Logistic算法1.png',dpi=300,bbox_inches='tight')
plt.show()
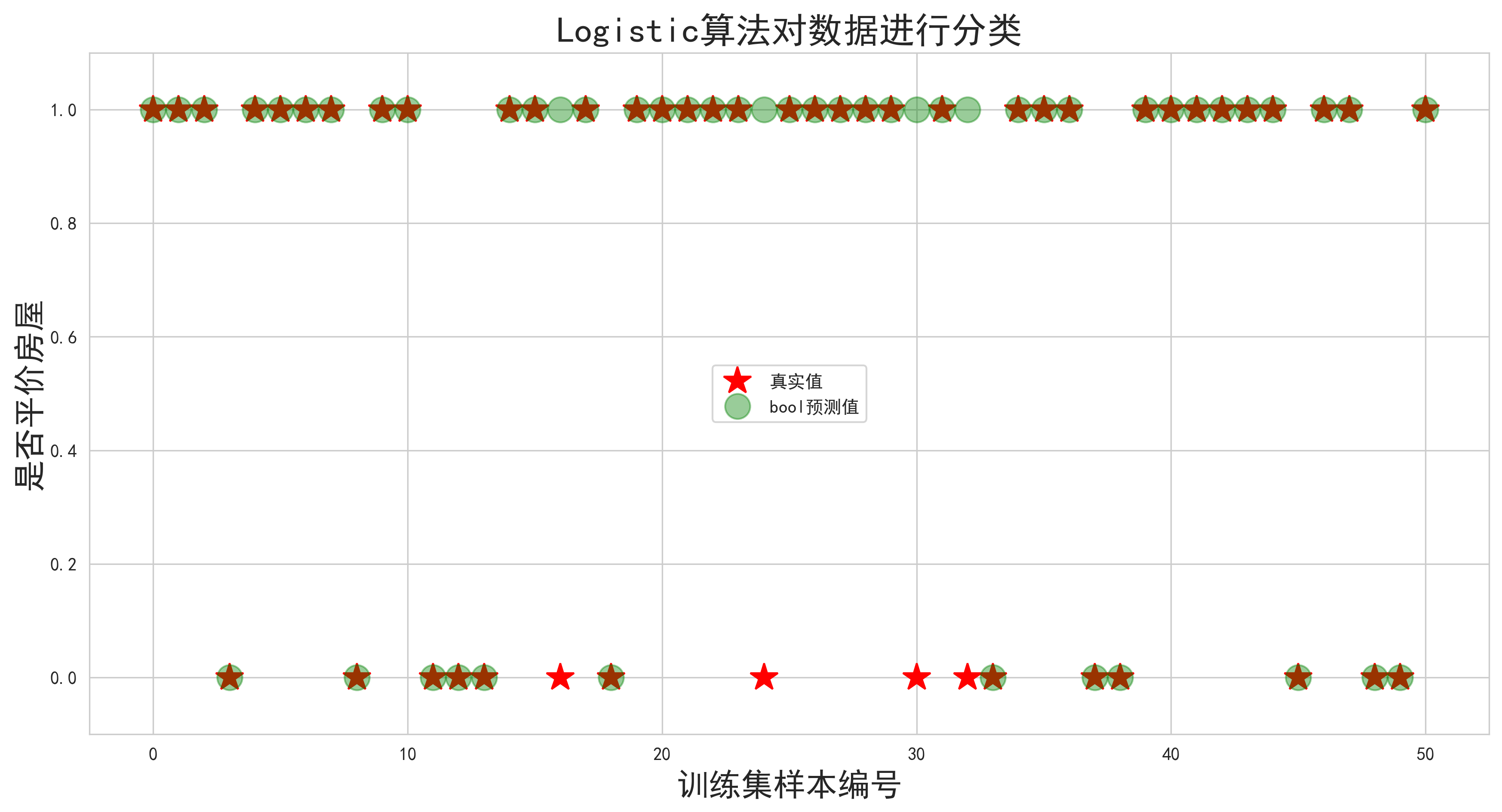
可以看出结果是不错的!
四、时间序列分析
1、概念
在回归分析中,专门有一类研究将时间、周期作为自变量,其他数据作为因变量的问题,称之为 时间序列分析。
股票数据可以说是典型的时间序列数据,之前已经写过了,在这里就不过多的赘述python金融数据分析及可视化
结语
以上所有内容就是关于利用python进行相关分析和回归分析的基本方法。通常情况下,相关分析属于数据挖掘的前期准备工作,通过它可以初步发现和研究对象关系比较密切的影响因素。在此基础上,选择合适的模型进行回归分析。
大家如果觉得文章不错的话,记得收藏、点赞、关注三连~
Original: https://blog.csdn.net/weixin_47974364/article/details/124019624
Author: 貮叁
Title: 【实战】——以波士顿房价为例进行数据的相关分析和回归分析
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/638387/
转载文章受原作者版权保护。转载请注明原作者出处!