


一、案例背景
案例说明与研究目的
研究调查100家公司2010-2013年关于财务方面的具体数据,这些财务指标维度分别为盈利能力、偿债能力、运营能力、发展能力以及公司治理。其中每个维度分别有几个分析项,但是有些指标是越大越好,有些指标是越小越好。 需要在研究前进行数据处理。
想要调查的数据进行主成分分析,判断主成分与分析项之间的关系得到相应维度,对于二级指标使用熵值法进行求取权重,一级指标由主成分分析得到的相应维度利用方差解释率进行计算权重,最后汇总总结。
二、数据处理与SPSSAU操作
主成分的目的就是用少数几个成分去描述许多指标或因素之间的联系,即将相关比较密切的几个变量归在同一类中,每一类变量就成为一个成分(之所以称其为成分,是因为它是不可观测的,即不是具体的变量),以最少的信息丢失为前提,以较少的几个成分反映原资料的大部分信息。
在进行主成分之前,由于所选取的指标体系中每个指标都有自己的量纲和变动差异性,这样给综合分析建模带来不便,于是我们需要对收集得到的数据进行预处理,以消除量纲和变动差异性的影响。通常对数据进行的处理包括标准化处理(Z-score 法)、正向处理、均值化处理等。
此案例中有些指标需要提前处理,具体指标隶属维度以及指标性质如下,比如资产负责率是逆向指标可以进行逆向化处理或者取倒数;但是取倒数需要分析项的数据大于0,其他指标需要正向化处理,公司治理的2个指标可以做正向化处理也可以做适度化,比如认为指标不是越大越好也不是越小越好,接近于某个值或某个范围内认为更好那就使用适度化,此案例中认为越大越好处理为正向化(也有参考文献做适度化处理,建议以参考文献为主)。
指标指标性质净资产收益率正向指标资产报酬率正向指标主营业务利润率正向指标流动比率正向指标速动比率正向指标资产负债率逆向指标应收账款周转率正向指标存货周转率正向指标总资产周转率正向指标净利润增长率正向指标主营业务收入增长率正向指标总资产现金回收率正向指标销售现金比率正向指标每股经营性现金流量正向指标第一大股东持股比适度指标前十大股东持股比适度指标
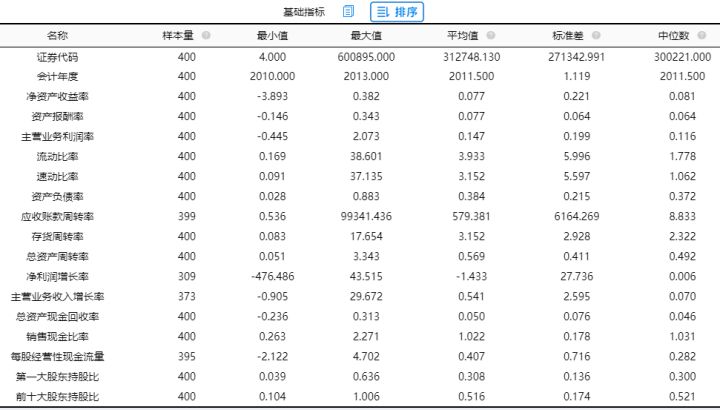
1.描述分析
首先用SPSSAU将分析项进行”描述分析”观察数据的基本情况。发现资产负债率所有数据均大于0,所以进行处理时可以直接”取倒数”。
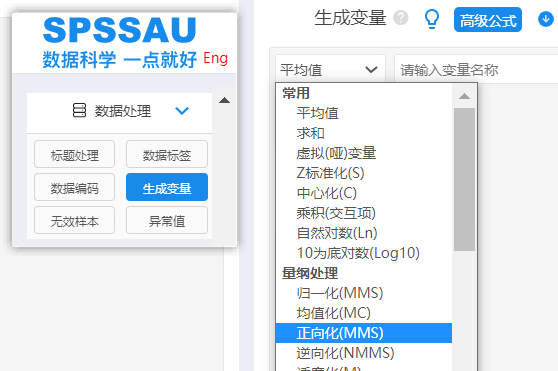
2.数据处理
然后利用SPSSAU”数据处理”中的”生成变量”进行指标处理(一般正逆向化处理后不需要在进行标准化处理,因为已经正逆向化已经处理了量纲问题,但是取倒数后需要进行标准化处理)。
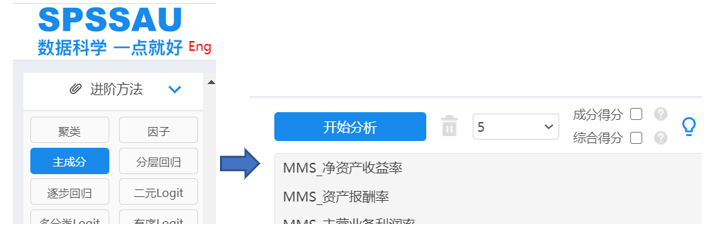
3.主成分分析
因为案例的预设维度为5所以将分析项拖拽到右侧分析框后,下拉选择成分个数为5。
三、主成分结果
1.判断主成分与分析项对应关系

使用主成分分析进行信息浓缩研究,首先分析研究数据是否适合进行主成分分析,从上表可以看出:KMO为0.642,大于0.6,满足主成分分析的前提要求,意味着数据可用于主成分分析研究。以及数据通过Bartlett 球形度检验(p
Original: https://blog.csdn.net/m0_37228052/article/details/125546483
Author: spssau
Title: 主成分计算权重
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/636076/
转载文章受原作者版权保护。转载请注明原作者出处!