

多元线性回归模型statsmodelsols
- 前言
* - 什么是多元线性回归分析预测法
- 一、多元线性回归
- 二、多元线性回归模型求解
* - 2.1最小二乘法实现参数估计—估计自变量X的系数
- 2.2决定系数:R² 与调整后 R²
- 2.3F检验参数
- 2.4对数似然、AIC与BIC
- 2.5回归系数标准差
- 2.6回归系数的显著性t检验
- 三、多元线性回归问题TensorFlow实践(波士顿房价预测)
- 总结
前言
什么是多元线性回归分析预测法
在市场的经济活动中,经常会遇到某一市场现象的发展和变化取决于几个影响因素的情况,也就是一个因变量和几个自变量有依存关系的情况。而且有时几个影响因素主次难以区分,或者有的因素虽属次要,但也不能略去其作用。例如,某一商品的销售量既与人口的增长变化有关,也与商品价格变化有关。这时采用一元回归分析预测法进行预测是难以奏效的,需要采用多元回归分析预测法。
多元回归分析预测法,是指通过对两个或两个以上的自变量与一个因变量的相关分析,建立预测模型进行预测的方法。当自变量与因变量之间存在线性关系时,称为多元线性回归分析。
一、多元线性回归
一元线性回归是一个主要影响因素作为自变量来解释因变量的变化,但是在现实问题研究中,因变量的变化往往受几个重要因素的影响,此时就需要用两个或两个以上的影响因素作为自变量来解释因变量的变化,这就是多元回归亦称多重回归。 当多个自变量与因变量之间是线性关系时,所进行的回归分析就是多元线性回归。





在建立多元性回归模型时,为了保证回归模型具有优秀的解释能力和预测效果,应首先 注意自变量的选择,其准则是:
- (1)自变量对因变量必须有 显著的影响,并呈密切的线性相关;
- (2)自变量与因变量之间的线性相关必须是 真实的,而不是形式上的;
- (3)自变量之间 具有一定的互斥性,即自变量之间的相关程度不能高于自变量与因变量之间的相关程度;
- (4)自变量应具有 完整的统计数据,其预测值容易确定。

用二元线性回归模型来求解回归参数的标准参数方程组为:
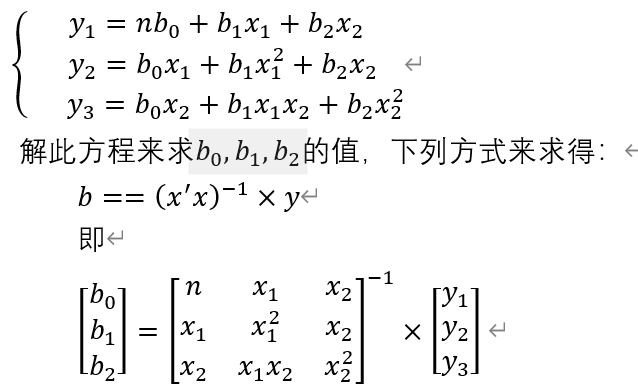
; 二、多元线性回归模型求解
多元线性回归模型的主要作用:(主要用于预测)通过建模来拟合我们所提供的或是收集到的这些因变量和自变量的数据,收集到的数据拟合之后来进行参数估计。参数估计的目的主要是来估计出模型的偏回归系数的值。估计出来之后就可以再去收集新的自变量的数据去进行预测,也称为样本量。
多元线性回归模型:

回归模型算法实现:
import pandas as pd
import numpy as np
import statsmodels.api as sm
import statsmodels.stats.api as sms
import statsmodels.formula.api as smf
import scipy
np.random.seed(991)
x1 = np.random.normal(0,0.4,100)
x2 = np.random.normal(0,0.6,100)
x3 = np.random.normal(0,0.2,100)
eps = np.random.normal(0,0.05,100)
X = np.c_[x1,x2,x3]
beta = [0.1,0.2,0.7]
y = np.dot(X,beta) + eps
X_model = sm.add_constant(X)
model = sm.OLS(y,X_model)
results = model.fit()
results.summary()
OLS 回归结果:

2.1最小二乘法实现参数估计—估计自变量X的系数
回归系数的计算:X转置(T)乘以X,对点积求逆后,再点乘X转置,最后点乘y 。
beta_hat = np.dot(np.dot(np.linalg.inv(np.dot(X_model.T,X_model)),X_model.T),y)
print('回归系数:',np.round(beta_hat,4))
print('回归方程:Y_hat=%0.4f+%0.4f*X1+%0.4f*X2+%0.4f*X3' % (beta_hat[0],beta_hat[1],beta_hat[2],beta_hat[3]))
输出为:
回归系数: [-0.0097 0.0746 0.2032 0.7461]
回归方程:Y_hat=-0.0097+0.0746*X1+0.2032*X2+0.7461*X3
代码讲解:

2.2决定系数:R² 与调整后 R²
决定系数R² 主要作用是:检验回归模型的显著性
y_hat = np.dot(X_model,beta_hat)
y_mean = np.mean(y)
sst = sum((y-y_mean)**2)
ssr = sum((y_hat-y_mean)**2)
sse = sum((y-y_hat)**2)
R_squared =1 - sse/sst
print('R²:',round(R_squared,3))
adjR_squared =1- (sse/(100-3-1))/(sst/(100-1))
print('调整后R²:',round(adjR_squared,3))
输出为:
R²: 0.931
调整后R²: 0.929
说明:

2.3F检验参数
F显著性检验:

F = (ssr/3)/(sse/(100-3-1));
print('F统计量:',round(F,1))
F_p = scipy.stats.f.sf(F,3,96)
print('F统计量的P值:', F_p)
输出为:
F统计量: 432.6
F统计量的P值: 1.2862966484214766e-55
说明:
- 若假设的检验的P值越小,表示的显著性水平就越高。也就是说拒绝原假设H0,接受备选假设H1。
2.4对数似然、AIC与BIC
res = results.resid
sigma_res = np.std(res)
var_res = np.var(res)
L = -(100/2)*np.log(2*np.pi)-(100/2)*np.log(var_res)-100/2
print('对数似然为:', round(ll,2))
AIC = -2*L + 2*(3+1)
print('AIC为:',round(AIC,1))
BIC = -2*L+np.log(100)*(3+1)
print('BIC为:',round(BIC,1))
输出为:
对数似然为: 152.69
AIC为: -297.4
BIC为: -287.0
- AIC和BIC越小越好。
2.5回归系数标准差
回归系数标准差为:

from scipy.stats import t,f
C = np.linalg.inv(np.dot(X_model.T,X_model))
C_diag = np.diag(C)
sigma_unb= (sse/(100-3-1))**(1/2)
'''
回归系数标准差std err的计算:
计算方式:残差标准差(无偏估计)乘以(C矩阵对角线上对应值的平方根)
'''
stdderr_const = sigma_unb*(C_diag[0]**(1/2))
print('常数项(截距)的标准差:',round(stdderr_const,3))
stderr_x1 = sigma_unb*(C_diag[1]**(1/2))
print('beta1的标准差:',round(stderr_x1,3))
stderr_x2 = sigma_unb*(C_diag[2]**(1/2))
print('beta2的标准差:',round(stderr_x2,3))
stderr_x3 = sigma_unb*(C_diag[3]**(1/2))
print('beta3的标准差:',round(stderr_x3,3))
print('C矩阵:\n', C)
print('\nC矩阵的对角线元素:',C_diag)
输出标准差为:
常数项(截距)的标准差: 0.005
beta1的标准差: 0.015
beta2的标准差: 0.009
beta3的标准差: 0.03
输出矩阵为:
C矩阵:
[[ 1.02054345e-02 1.95714789e-03 -8.54037508e-05 -6.90581790e-03]
[ 1.95714789e-03 7.92625905e-02 -3.13550686e-03 -3.64832485e-04]
[-8.54037508e-05 -3.13550686e-03 2.84951362e-02 -8.72645509e-03]
[-6.90581790e-03 -3.64832485e-04 -8.72645509e-03 3.05673367e-01]]
C矩阵的对角线元素: [0.01020543 0.07926259 0.02849514 0.30567337]
2.6回归系数的显著性t检验
回归系数显著性检验:

t_const = beta_hat[0]/stdderr_const
print('截距项的t值:',round(t_const,3))
p_const = 2*t.sf(t_const,96)
print("P>|t|:",round(p_const,3))
t_x1 = beta_hat[1]/stderr_x1
print('x1系数的t值:',round(t_x1,3))
p_t1 = 2*t.sf(t_x1,96)
print("P>|t|:",round(p_t1,3))
输出为:
截距项的t值: -1.798
P>|t|: 1.925
x1系数的t值: 4.941
P>|t|: 0.0
- t值足够小就可以认为回归方程的系数是具有显著性的,显著性水平是比较高的,否则就可以认为这个回归系数的显著性不高。
三、多元线性回归问题TensorFlow实践(波士顿房价预测)
数据下载方法:
- 波士顿房价数据
- 使用从sklearn库中导出数据集
首先需要用到sklearn里面的数据集以及调用pandas库
from sklearn import datasets
import pandas as pd
boston = datasets.load_boston()
再用pandas库中的DataFrame函数,这个函数可以指定data,columns,index等,若不指明columns,则每列数据的标签会以1、2、3等标记,这里我们每列数据的标签用数据集里面的。
data =pd.DataFrame(data=boston.data,columns=boston.feature_names)
print(data)
最后把数据导入csv文件中。
data.to_csv('./boston.csv', index=None)
- 原数据中有14列数据,由于data=pd.DataFrame(data=boston.data,columns=boston.feature_names) 这里的feature_names指的是特征的名字,也就是13个自变量,至于MEDV,你再用target即可(把boston.feature_names改成boston.target),而且运行boston.keys() 你也可以看到关于这个数据集的介绍(包括目标、特征、描述)
波士顿房价数据:
波士顿房价数据集包括506个样本,每个样本包括12个特征变量和该地区的平均房价。房价(单价)显然和多个特征变量相关,不是单变量线性回归(- 元线性回归)问题。选择多个特征变量来建立线性方程,这就是多变量线性回归(多 元线性回归)问题。
字段字段说明CRIM城镇人均犯罪率ZN占地面积超过25,000平方英尺的住宅用地比例。INDUS每个城镇非零售业务的比例。CHASCharles River虚拟变量(如果是河道,则为1;否则为0)NOX一氧化氮浓度(每千万份)RM每间住宅的平均房间数AGE1940年以前建造的自住单位比例DIS加权距离波士顿的五个就业中心RAD径向高速公路的可达性指数TAX每10,000美元的全额物业税率PTRATIO城镇的学生与教师比例B1000(Bk – 0.63)^ 2其中Bk是城镇黑人的比例LSTAT人口状况下降%MEDV自有住房的中位数报价, 单位1000美元
- 对波士顿房价数据用pandas来处理:
import tensorflow.compat.v1 as tf
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.utils import shuffle
df_data = pd.read_csv('boston.csv')
df_data

对于下载tensorflow 可以参考这篇文章:Win10下用Anaconda安装TensorFlow 按照里面所有步骤完成后还是用不了tensorflow 的话,就在Anaconda Prompt中启动tensorflow环境并进入ipython环境中,再次下载:
pip install tensorflow
就可以使用了。
df_data.head(3)

- 数据准备(相关操作)
ds=df_data.values
print(ds.shape)
输出为:(506, 13)
print(ds)
输出为:

- 划分特征数据和标签数据
x_data = ds[:,:12]
y_data = ds[:,12]
print('x_data shape=',x_data.shape)
print('y_data shape=',y_data.shape)
输出为:

- 特征数据归一化
for i in range(12):
df[:,i] = (df[:,i]-df[:,i].min())/(df[:,i].max()-df[:,i].min())
df

- 模型定义
5.1 定义特征数据和标签数据的占位符
x = tf.placeholder(tf.float32,[None,12],name = "X")
y = tf.placeholder(tf.float32,[None,1],name = "Y")
5.2 定义模型函数
with tf.name_scope("Model"):
w = tf.Variable(tf.random_normal([12,1],stddev=0.01),name="W")
b = tf.Variable(1.0,name="b")
def model(x,w,b):
return tf.matmul(x,w) + b
pred = model(x,w,b)
- 模型训练
6.1 设置训练超参数
train_epochs = 50
learning_rate = 0.01
6.2 定义均方差损失函数
with tf.name_scope("LossFunction"):
loss_function = tf.reduce_mean(tf.pow(y-pred,2))
6.3 创建优化器
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_function)
6.4 会话
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
6.5 训练
for epoch in range(train_epochs):
loss_sum = 0.0
for xs,ys in zip(x_data,y_data):
xs = xs.reshape(1,12)
ys = ys.reshape(1,1)
_,loss = sess.run([optimizer,loss_function],feed_dict={x:xs,y:ys})
loss_sum = loss_sum + loss
x_data,y_data = shuffle(x_data,y_data)
b0temp = b.eval(session=sess)
w0temp = w.eval(session=sess)
loss_average = loss_sum/len(y_data)
print("epoch=",epoch+1,"loss=",loss_average,"b=",b0temp,"w=",w0temp)
输出为:
epoch= 1 loss= 28.082918898316105 b= 3.952297 w= [[ 0.51253736]
[-0.9672818 ]
[ 2.1312068 ]
[-0.21723996]
[ 1.6660578 ]
[-1.8813397 ]
[ 4.6080937 ]
[ 0.3415178 ]
[ 0.8034863 ]
[ 1.5301441 ]
[ 2.754847 ]
[ 1.4393961 ]]
epoch= 2 loss= 26.376526752740993 b= 4.887504 w= [[ 1.5641255 ]
[-1.1011099 ]
[ 3.9318624 ]
[-0.53754747]
[ 3.4213843 ]
[-4.5665426 ]
[ 7.1060243 ]
[ 0.17595242]
[ 1.6169361 ]
[ 2.7584982 ]
[ 3.626495 ]
[ 0.01978375]]
epoch= 3 loss= 24.173813558376537 b= 5.395661 w= [[ 2.1237833 ]
[-0.54208773]
[ 3.853566 ]
[-1.1139921 ]
[ 3.4763796 ]
[-6.7673526 ]
[ 7.363592 ]
[ 0.9175515 ]
[ 0.79786545]
[ 2.145488 ]
[ 3.542476 ]
[-0.7713235 ]]
... ...后面还有47条数据就不展示。
- 模型应用
n = np.random.randint(506)
print(n)
x_test = x_data[n]
x_test = x_test.reshape(1,12)
predict = sess.run(pred,feed_dict={x:x_test})
print("预测值:%f"%predict)
target = y_data[n]
print("标签值:%f"%target)
输出为:

进一步可视化:
- 根据波士顿房价信息进行预测,多元线性回归+特征数据归一化+可视化
添加loos_list值列表,并且输出可视化plt.plot(loss_list)

输出为:

- 根据波士顿房价信息进行预测,多元线性回归+特征数据归一化+可视化+TensorBoard可视化
TensorBoard可视化准备数据
logdir='d:/log'
sum_loss_op = tf.summary.scalar("loss",loss_function)
merged = tf.summary.merge_all()
输出为:

总结
对于数据集划分还可以继续优化:
划分数据集的方法:
一种方法是将数据集分成两个子集:
- 训练集 – 用于训练模型的子集
- 测试集 – 用于测试模型的子集
通常,在测试集上表现是否良好是衡量能否在新数据上表现良好的有用指标,前提是:
测试集足够大,不会反复使用相同的测试集来作假。
拆分数据:将单个数据集拆分为一个训练集和一个测试集
确保测试集满足以下两个条件:
- (1)规模足够大,可产生具有统计意义的结果
- (2)能代表整个数据集,测试集的特征应该与训练集的特征相同
但是在每次迭代时,都会对训练数据进行训练并评估测试数据,并以基于测试数据的评估结果为指导来选择和更改各种模型超参数,例如学习速率和特征。所以在新数据基础上将数据集划分为三个子集,可以大幅降低过拟合的发生几率: 划分训练集、验证集和测试集

- 在模型”通过”验证集之后,使用测试集再次检查评估结果。
train_num = 300
valid_num = 100
test_num = len(x_data) - train_num - valid_num
x_train = x_data[:train_num]
y_train = y_data[:train_num]
x_valid = x_data[train_num:train_num+valid_num]
y_valid = y_data[train_num:train_num+valid_num]
x_test = x_data[train_num+valid_num:train_num+valid_num+test_num]
y_test = y_data[train_num+valid_num:train_num+valid_num+test_num]
- 数据类型的转换
x_train = tf.cast(x_train,dtype=tf.float32)
x_valid = tf.cast(x_valid,dtype=tf.float32)
x_test = tf.cast(x_test,dtype=tf.float32)
- 构建模型
def model(x,w,b):
return tf.matmul(x,w)+b
- 优化变量的创建
W = tf.Variable(tf.random.normal([12,1],mean=0.0,stddev=1.0,dtype=tf.float32))
B= tf.Variable(tf.zeros(1),dtype = tf.float32)
print(W)
print(B)
输出为:

- 模型训练
training_epochs = 50
learning_rate = 0.001
batch_size = 10
def loss(x,y,w,b):
err = model(x, w,b) - y
squared_err = tf.square(err)
return tf.reduce_mean(squared_err)
def grad(x,y,w,b):
with tf.GradientTape() as tape:
loss_= loss(x,y,w,b)
return tape.gradient(loss_,[w,b])
optimizer = tf.keras.optimizers.SGD(learning_rate)
loss_list_train = []
loss_list_valid = []
total_step = int(train_num/batch_size)
for epoch in range(training_epochs):
for step in range(total_step):
xs = x_train[step*batch_size:(step+1)*batch_size,:]
ys = y_train[step*batch_size:(step+1)*batch_size]
grads = grad(xs,ys,W,B)
optimizer.apply_gradients(zip(grads,[W,B]))
loss_train = loss(x_train,y_train,W,B).numpy()
loss_valid = loss(x_valid,y_valid,W,B).numpy()
loss_list_train.append(loss_train)
loss_list_valid.append(loss_valid)
print("epoch={:3d},train_loss={:.4f},valid_loss={:.4f}".format(epoch+1,loss_train,loss_valid))
输出为:迭代50次,但是由于训练集和验证集损失都为nan就没有继续下去了。
可以参考一下:https://itcn.blog/p/1026265732.html
epoch= 1,train_loss=nan,valid_loss=nan
epoch= 2,train_loss=nan,valid_loss=nan
epoch= 3,train_loss=nan,valid_loss=nan
epoch= 4,train_loss=nan,valid_loss=nan
epoch= 5,train_loss=nan,valid_loss=nan
epoch= 6,train_loss=nan,valid_loss=nan
epoch= 7,train_loss=nan,valid_loss=nan
epoch= 8,train_loss=nan,valid_loss=nan
epoch= 9,train_loss=nan,valid_loss=nan
epoch= 10,train_loss=nan,valid_loss=nan
epoch= 11,train_loss=nan,valid_loss=nan
epoch= 12,train_loss=nan,valid_loss=nan
epoch= 13,train_loss=nan,valid_loss=nan
epoch= 14,train_loss=nan,valid_loss=nan
epoch= 15,train_loss=nan,valid_loss=nan
epoch= 16,train_loss=nan,valid_loss=nan
epoch= 17,train_loss=nan,valid_loss=nan
epoch= 18,train_loss=nan,valid_loss=nan
epoch= 19,train_loss=nan,valid_loss=nan
epoch= 20,train_loss=nan,valid_loss=nan
epoch= 21,train_loss=nan,valid_loss=nan
epoch= 22,train_loss=nan,valid_loss=nan
epoch= 23,train_loss=nan,valid_loss=nan
epoch= 24,train_loss=nan,valid_loss=nan
epoch= 25,train_loss=nan,valid_loss=nan
epoch= 26,train_loss=nan,valid_loss=nan
epoch= 27,train_loss=nan,valid_loss=nan
epoch= 28,train_loss=nan,valid_loss=nan
epoch= 29,train_loss=nan,valid_loss=nan
epoch= 30,train_loss=nan,valid_loss=nan
epoch= 31,train_loss=nan,valid_loss=nan
epoch= 32,train_loss=nan,valid_loss=nan
epoch= 33,train_loss=nan,valid_loss=nan
epoch= 34,train_loss=nan,valid_loss=nan
epoch= 35,train_loss=nan,valid_loss=nan
epoch= 36,train_loss=nan,valid_loss=nan
epoch= 37,train_loss=nan,valid_loss=nan
epoch= 38,train_loss=nan,valid_loss=nan
epoch= 39,train_loss=nan,valid_loss=nan
epoch= 40,train_loss=nan,valid_loss=nan
epoch= 41,train_loss=nan,valid_loss=nan
epoch= 42,train_loss=nan,valid_loss=nan
epoch= 43,train_loss=nan,valid_loss=nan
epoch= 44,train_loss=nan,valid_loss=nan
epoch= 45,train_loss=nan,valid_loss=nan
epoch= 46,train_loss=nan,valid_loss=nan
epoch= 47,train_loss=nan,valid_loss=nan
epoch= 48,train_loss=nan,valid_loss=nan
epoch= 49,train_loss=nan,valid_loss=nan
epoch= 50,train_loss=nan,valid_loss=nan
Original: https://blog.csdn.net/ex_6450/article/details/126419010
Author: 存在~~
Title: 机器学习10—多元线性回归模型
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/635980/
转载文章受原作者版权保护。转载请注明原作者出处!