

一、基于实例的学习方法:
a.已知一系列的训练样例,许多学习方法为目标函数建立起明确的一般化描述;
b.基于实例的学习方法只是简单地把训练样本存储起来,从这些实例中泛化的工作被推迟到必须分类新的实例时;
c.每当学习器遇到一个新的查询实例时,它分析这个新实例与以前存储的实例的关系,并据此把一个目标函数赋给新实例;
基于实例的学习方法包括:
1.假定实例可以表示成欧式空间中的点:最近邻法KNN(K- Nearest Neighbor);局部加权回归法;
2.对实例采用更复杂的符号表示:基于案例的推理;
二、
最近邻法KNN(K- Nearest Neighbor):
如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别 [2] 。
局部加权回归法:
参数学习方法:
参数学习方法是用一组训练得到一系列训练参数,然后确定出预测函数h,之后就可以根据新的输入来输出新的预测值,不再依赖之前的训练集了,参数值求解出来后一直是确定的。
非参数学习方法:
非参数学习方法是在预测新样本值时候每次都会根据预测样本附近的训练集求解新的参数值,即每次预测新样本是都会依赖训练集求解新的参数,所以每次得到的参数值是不确定的。
以之前提到的房价为例:
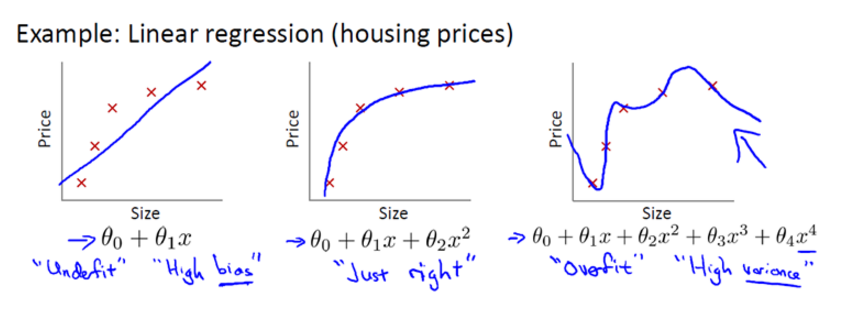

采用第一种线性拟合不能很好地预测所有的值,因为它容易导致欠拟合(under fitting)。
而采用图三多项式拟合能拟合所有数据,但是在预测新样本的时候又会变得很糟糕,因为它导致数据的
过拟合(overfitting),不符合数据真实的模型。
局部加权回归是一种非参数学习方法,它的主要思想就是只对预测样本附近的一些样本进行选择,根据这些样本得到回归方程,那么此时我们得到的回归方程就比较拟合样本数据,不会存在欠拟合和过拟合的现象。
以上述房价为例解释 局部加权回归方法的思路:
1、加入一个加权因子:
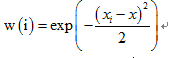
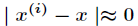
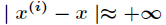
2、重新构造新的j(θ):
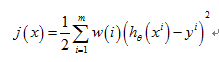
局部加权回归的弊端:
(1)当数据规模比较大的时候计算量很大,学习效率很低。
(2)并不一定能避免欠拟合。
基于案例的推理:
一种基于实际经验或经历的推理,求解问题时从案例库中找出与当前问题最相似的案例,并将该案例的结论部分作为当前问题的解。
基于实例的学习方法有时被称为消极学习法,即他把处理新实例的工作延迟到必须分类新的实例时;
这种延迟的学习方法有一个优点:不是在整个实例空间上一次性地估计目标函数,而是针对每个待分类新实例作出局部的和相异的估计;
三、
最基本的基于实例的学习方法是:K-近邻算法。
基于实例的方法的不足:
1、分类新实例的开销可能很大。这是因为几乎所有的计算都发生在分类之时,而不是第一次遇到训练样本时。所以,如何有效地索引训练样本,以减少搜索时所需计算是一个重要的实践问题。
2.当从存储器中检索相似的训练样本时,它们一般考虑实例的所有属性。如果目标概念仅依赖于很多属性中的几个时,那么真正最”相似”的实例之间很可能相距甚远。
Original: https://blog.csdn.net/fu_jian_ping/article/details/111591010
Author: 傅华涛Fu
Title: 基于实例的学习方法
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/635966/
转载文章受原作者版权保护。转载请注明原作者出处!