

百度飞桨2021李宏毅机器学习特训营学习笔记之回归及作业PM2.5预测
- 前言
- 回归
* - 什么是回归(Regression)?
- 怎么做回归?
- 线性回归(Linear Regression)
- 训练集与验证集
- 损失函数
- 搜索算法
* - 随机梯度下降法
- 模型评估与选择
- 作业1-PM2.5预测
* - 项目描述
- 数据集介绍
- 项目要求
- 作业分析
* - 数据处理
– - 训练模型
– - 验证模型
- 总结
- 感想
- 参考
前言
偶然在百度飞桨公众号了解到李宏毅机器学习特训营开营仪式,从此开始了百度组织的李宏毅机器学习特训营。该特训营虽然是李宏毅老师的录播,但有百度的助教互动,班级QQ群管理,作业被批阅打分,比赛等环节,特别是每周6晚的两小时答疑和班助的作业评讲直播,催人向上。另外aistudio提供的在线编程环境及算力,提供了实践的基础。总的来讲,百度飞桨提供了在线学习的好环境。这些都是不用交钱、免费的,体现了百度大厂的社会责任。学习网址:
https://aistudio.baidu.com/aistudio/course/introduce/1978
下面言归正传,说说学习回归的心得。由于是笔记,加入了一些个人之见,多偏颇,读者需注意。
回归
什么是回归(Regression)?
通俗地讲,就是预测的结果是数值、标量的称为回归(Regression)。


粗俗地讲,机器学习就是做预测的,以预测的输出结果分类,其中结果为实值的,叫做回归。
; 怎么做回归?
或者说回归要做哪些工作?简单地,就是
1、 设置一个模型也叫函数集(Function Set)。比如f(x1,x2)=w1x1+w2x2+b,(w1,w2,b)属于R实数,则只要将w1、w2和b的值确定下来,就确定了一个函数,如f(x1,x2)=5×1+7×2+3。以下的任务就是通过用已有的(x1,x2,y= f(x1,x2))一部分(称为训练集train set)在函数集中训练出一个最好的或可接受的函数f(x1,x2)=w1’x1+w2’x2+b’, (w1′,w2′)为最优函数的系数或权重(weight),b’为最优截距或偏移(bias)。

2、 设置一个判断函数集中最好的或可接受的函数的准则,通常采用损失函数(Loss Function),即将训练集的各组x1x2代入函数集中的某一个函数,将计算出的y与训练集中的y求差异,再求所有组的平均值,以该值作为此函数的效果,并与函数集中其他函数效果比较,以差异(欧氏距离)最小的函数为最优。通常差异由均方差来计算,这种。这样回归操作的这部分就变成了一个优化问题,即在给定的(w1,w2,b)中求出使得计算值f(x1,x2)=w1x1+w2x2+b与训练集中y差异最小的(w1′,w2′,b’)。



3、 采用一种快速的搜索算法在(w1,w2,b)中找最优的(w1′,w2′,b’)。有了优化模型,还需合适的搜索算法。通常采用梯度下降法。即求当前(w1,w2,b)对损失函数的梯度(由偏导得),然后在梯度变小的方向取下一个(w1,w2,b),再计算损失值。这样一直重复下去,直到符合停止条件而终止。将此时的(w1,w2,b)作为(w1′,w2′,b’),得到最优函数。


4、 验证训练所得的最优函数。将验证集(与训练集的值不同,通常将已有数据一部分作为训练集,另一部分作为验证集或测试集test set)的x1x2代入最优函数求的f(x1,x2),并与验证集中的y求差异,取平均称为精度accurate。若精度可接受,则该函数即为学习的结果。

5、 预测。将预测集的x1x2代入函数,求出结果。
以上为回归的概念及工作流程。影响结果的因素也都在这流程中。只有将以上各环节都做好,才能得到一个好结果。
线性回归(Linear Regression)
对回归设置的函数集来说,若都是线性的则称为线性回归(Linear Regression)。此时函数的阶数为,即一元一次函数或多元一次函数。如f(x1,x2)=w1x1+w2x2+b
若函数集的阶数大于等于2则为非线性回归。如f(x1,x2)=w1x12+w2x2+b

函数的阶数过低,会造成欠拟合;而阶数过高,则会造成过拟合。二者都不好。怎样设置阶数是需要多方考虑,或进行变阶搜索。



; 训练集与验证集
有了数据,在训练前还得进行处理。包括训练集和验证集的划分、归一化处理等。有留出法(hold-out)、交叉验证法(cross validation)、自助法(bootstrapping)等。

损失函数
通常以损失函数作为优化模型,故合适的损失函数有助于快速获得合适的最优解。损失函数也是模型的性能度量(performance measure)。回归最常用的是”均方误差”(mean squared error)

更一般的,对于数据分布Ð 和概率密度函数p(.) , 均方误差可描述为

; 搜索算法
一个有效的算法能快速搜索到全局最优解。




随机梯度下降法

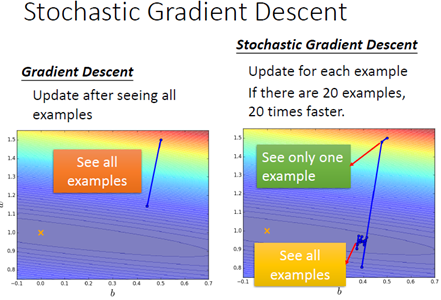
; 模型评估与选择
所得函数需进行评估。通常以验证集进行评估。
错误率与精度是最常用的两种性能度量,对于数据分布Ð 和概率密度函数p(.) , 错误率与精度可分别描述为


作业1-PM2.5预测
项目描述
• 本次作业的资料是从行政院环境环保署空气品质监测网所下载的观测资料。
• 希望大家能在本作业实现 linear regression 预测出 PM2.5 的数值。
数据集介绍
• 本次作业使用丰原站的观测记录,分成 train set 跟 test set,train set 是丰原站每个月的前 20 天所有资料。test set 则是从丰原站剩下的资料中取样出来。
• train.csv: 每个月前 20 天的完整资料。
• test.csv : 从剩下的资料当中取样出连续的 10 小时为一笔,前九小时的所有观测数据当作 feature,第十小时的 PM2.5 当作 answer。一共取出 240 笔不重複的 test data,请根据 feature 预测这 240 笔的 PM2.5。
• Data 含有 18 项观测数据 AMB_TEMP, CH4, CO, NHMC, NO, NO2, NOx, O3, PM10, PM2.5, RAINFALL, RH, SO2, THC, WD_HR, WIND_DIREC, WIND_SPEED, WS_HR。
项目要求
• 请手动实现 linear regression,方法限使用 gradient descent。
• 禁止使用 numpy.linalg.lstsq
作业分析
数据处理
train.csv:每个月前20天的完整资料
test.csv:从剩下的资料当中取样出连续的10小时为一组,前九个小时的所有观测数据当中feature,第十个小时的PM2.5当中answer。一共取出240组不重复的test data,然后根据feature去预测出第十小时的PM2.5的值。
Data中含有18项观测数据:AMB_TEMP,CH4,CO,NHMC,NO,NO2,NOx,O3,PM10,PM2.5,RAINFALL,RH,SO2,THC,WD_HR,WIND_DIREC,WIND_SPEED,WS_HR。

Training Data展示:

Testing Data展示:

train.csv当中保存的是丰原市一年当中每个月前20天的观测数据,由于每次输入的数据为前9个小时的PM2.5的数值,第10个小时的数值用来做label,所以一天当中的PM2.5的观测数据可以分为15组(15=24-10+1)。因此,train.csv当中的数据可以分为3600组(3600=122015)。当然为了增加数据量,也可以将数据分为5652组(5652=12(2024-10+1)),这是因为我们是连续取出前9个小时的PM2.5的值作为输入,第10个小时的数据值作为label。这里我只是将train.csv分为了3600组。
; 数据处理参考代码
def dataProcess(df):
x_list, y_list = [], []
df = df.replace(['NR'], [0.0])
array = np.array(df).astype(float)
for i in range(0, 4320, 18):
for j in range(15):
mat = array[i:i+18][9][j:j+9]
lable = array[i:i+18][9][j+9]
x_list.append(mat)
y_list.append(lable)
x = np.array(x_list)
y = np.array(y_list)
return x, y, array
因为train.csv文件当中RAINFALL这一项给的是NR,由于这一项对本次任务没有太多的联系,所以将它全部替换成0值表示。
数据预处理得到的x,y的shape为:

训练模型
本次任务的模型选择为:

i从0到8是因为选取前九个小时作为输入,每个输入都有一个w与之相乘,然后加上一个偏置b,通过这个模型去预测第十个小时的PM2.5的值。
这里可以将运算转换成向量运算,具体如下:

选择的Loss Function为:

在Loss当中,加入了Regularization选项,都乘以1/2是为了对Loss求导后能够把2约掉。
Loss对wj求偏导为:

Loss对b求偏导为:

参数更新:


这里可以将wj的更新转换成向量运算,具体如下:

Optimizer的选择:
本次任务主要选择Adagrad来优化模型,在Adagrad中,不同参数更新所使用的学习率在不停的变化。Adagrad的更新参数的方式如下:

其中,gt为wt的梯度值,而

所以得到:

; 训练模型参考代码
做成一个函数,代码为
def trainModel(x_data, y_data, epoch):
bias = 0
weight = np.ones(9)
learning_rate = 1
reg_rate = 0.001
bias_sum = 0
weight_sum = np.zeros(9)
for i in range(epoch):
b_g = 0
w_g = np.zeros(9)
for j in range(3200):
b_g += (y_data[j] - weight.dot(x_data[j]) - bias) * (-1)
for k in range(9):
w_g[k] += (y_data[j] - weight.dot(x_data[j]) - bias) * (-x_data[j, k])
b_g /= 3200
w_g /= 3200
for k in range(9):
w_g[k] += reg_rate * weight[k]
bias_sum += b_g ** 2
weight_sum += w_g ** 2
bias -= learning_rate / (bias_sum ** 0.5) * b_g
weight -= learning_rate / (weight_sum ** 0.5) * w_g
if i % 200 ==0:
loss = 0
for j in range(3200):
loss += (y_data[j] - weight.dot(x_data[j]) - bias) ** 2
loss /= 3200
for j in range(9):
loss += reg_rate * (weight[j] ** 2)
print('after {} epoch, the loss on the train_set is {:.2f}'.format(i, loss / 2))
return weight, bias
训练结果如下:

验证模型
代码为
def testModel(x_test, weight, bias):
f = open("ouput.csv", 'w', encoding='utf-8', newline="")
csv_write = csv.writer(f)
csv_write.writerow(["id", "value"])
for i in range(len(x_test)):
output = weight.dot(x_test[i]) + bias
csv_write.writerow(["id_" + str(i), str(output)])
f.close()
测试结果保存在output.csv当中,结果如下:

总结
由于本次任务选择的模型较为简单,而且训练数据集也并没有按照正规方法分为training data和validation data,只是简单地将前3200项作为training data,后400项作为validation data;此外,本次训练只考虑了PM2.5作为输入,其他观测信息并未使用,所以可能并没有达到很好的效果。在这个模型当中,感觉增加Regularization并未起多大的作用。
完整代码和结果可参考https://aistudio.baidu.com/aistudio/projectdetail/1663697
感想
百度飞桨与台大李宏毅老师合作,直接使用李老师在网上广为流传的视频课程进行特训营的教学,然后自己再添砖加瓦,补充答疑及作业指导的直播,不失为一个很好的方案。李老师的讲解深入浅出,是目前网友认同的最浅显易懂的课程。百度飞桨的助教通过答疑解决了学员学习过程中的疑问,达到老师学员一对一互动,获得较好的教学效果。班级管理也很负责,营造很好的群体学习氛围,督促学员坚持完成学习任务。
参考
参考了以下内容
Original: https://blog.csdn.net/yinboh/article/details/115979665
Author: yinboh
Title: 百度飞桨2021李宏毅机器学习特训营学习笔记之回归及作业PM2.5预测
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/635893/
转载文章受原作者版权保护。转载请注明原作者出处!