

Logistic回归
最近面试的朋友有被要求现场手写logistic模型,再加上本身有些厂面试爱手撕logistic公式,再加上有些面试会让你介绍一个自己最熟悉的机器学习模型,我寻思这会了一个logistic不就齐活了,话不多说,直接开整!
逻辑回归被广泛应用于估算某个实例属于某个特定类别的概率
1.公式推导(不想编辑公式就手写了友友们):
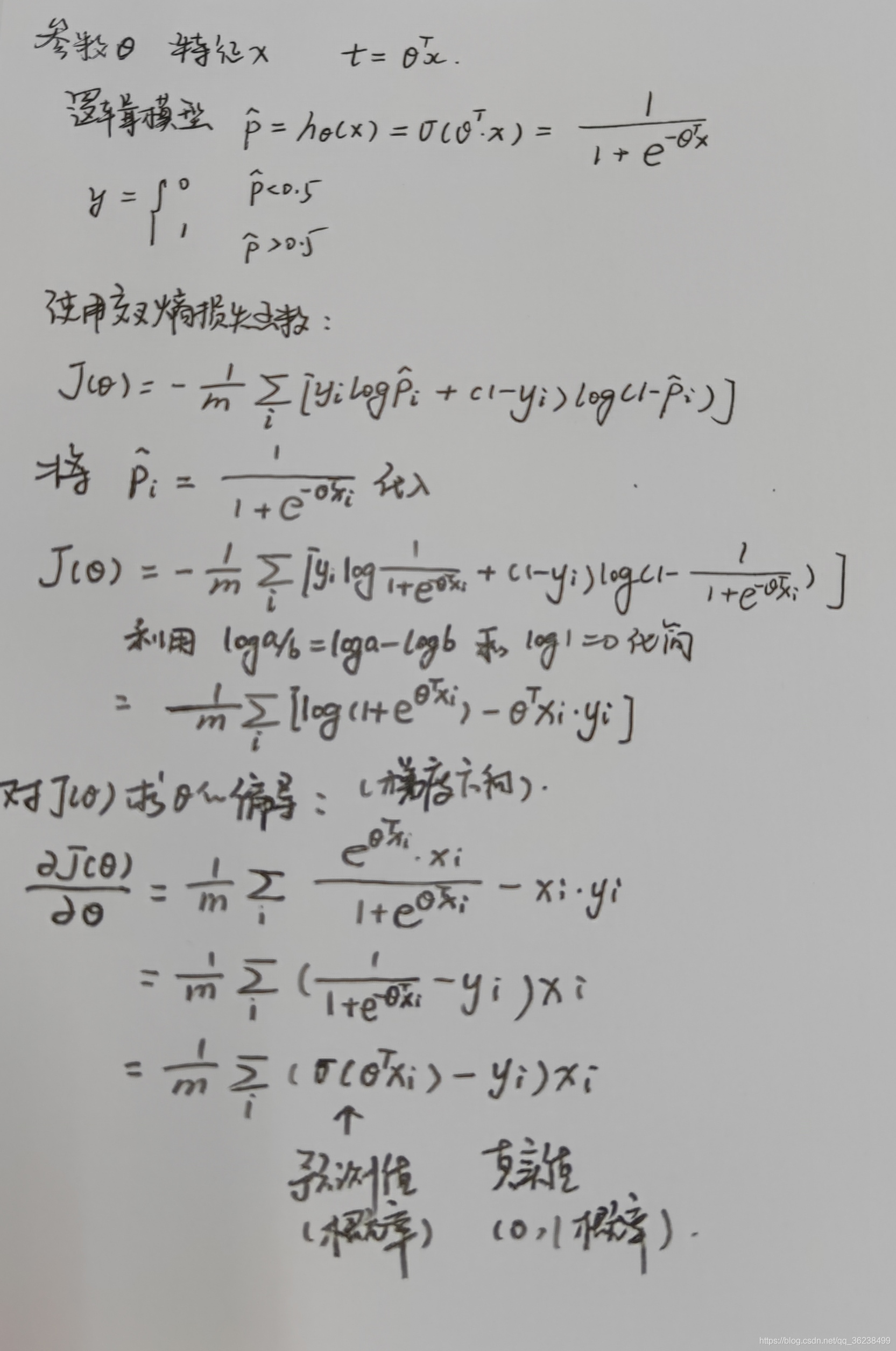

使用梯度下降的方向作为参数θ更新的方向,一般在训练时会设置学习率α作为学习的步长,参数更新的公式即为:
θi+1 = θi – α*(y_pre – y)·x
2.逻辑回归的优缺点:
优点:
1)实现简单,计算量小
2)概率推导得到,理论可靠
3)值域为[0,1],具有概率意义
4)参数代表每个特征对输出的影响,可解释性强
缺点:
1)容易欠拟合,一般准确度不是特别高
2)本质来说是一个线性分类器,对于线性不可分的问题处理的不好
3)特征空间很大的时候,性能不好
3.比较
1)与线性回归的比较:
线性回归的目标变量是连续变量,逻辑回归是类别型变量
线性回归模型的目标变量和自变量之间的关系假设是线性相关的,逻辑回归中则是非线性的
线性回归通常基于正态分布,逻辑回归则是基于二项分布或者多项分布
线性回归的参数估计使用最小二乘,逻辑回归使用最大似然
2)与朴素贝叶斯的比较:
朴素贝叶斯则是直接求出权重,逻辑回归是通过loss最优化求出分类概率
朴素贝叶斯基于条件独立假设,逻辑回归没有这个假设
朴素贝叶斯是生成模型,逻辑回归是判别模型
3)与SVM比较
SVM只输出类别,逻辑回归输出概率
二者的损失函数不同
逻辑回归的可解释性强
SVM自带有约束的正则化
4.代码
代码是找的本站其他帖子手撕的代码做了一些注释和一点点修改参考如下:
from math import exp
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
def create_data():
iris = load_iris()
X, y = np.array(iris.data), np.array(iris.target)
return X[:100, 0:2], y[:100]
X, y = create_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
class LogisticRegressionClassifier:
def __init__(self, max_iter=200, learning_rate=0.01):
self.max_iter = max_iter
self.learning_rate = learning_rate
self.loss = []
def sigmoid(self, x):
return 1 / (1 + exp(-x))
def data_matrix(self, X):
data_mat = []
for d in X:
data_mat.append([1.0, *d])
return data_mat
def fit(self, X, y):
data_mat = self.data_matrix(X)
self.weights = np.zeros((len(data_mat[0]), 1), dtype=np.float32)
for iter_ in range(self.max_iter):
errors = 0.0
for i in range(len(X)):
result = self.sigmoid(np.dot(data_mat[i], self.weights))
error = result - y[i]
errors += error
self.weights -= self.learning_rate * error * np.transpose(
[data_mat[i]])
self.loss.append(errors / len(X))
print('LogisticRegression Model(learning_rate={},max_iter={})'.format(
self.learning_rate, self.max_iter))
def score(self, X_test, y_test):
right = 0
X_test = self.data_matrix(X_test)
for x, y in zip(X_test, y_test):
result = np.dot(x, self.weights)
if (result > 0 and y == 1) or (result < 0 and y == 0):
right += 1
return right / len(X_test)
lr_clf = LogisticRegressionClassifier()
lr_clf.fit(X_train, y_train)
lr_clf.score(X_test, y_test)
plt.figure(1)
plt.scatter(X[:50, 0], X[:50, 1], label='0')
plt.scatter(X[50:, 0], X[50:, 1], label='1')
plt.legend()
plt.figure(2)
plt.plot(lr_clf.loss)
plt.show()
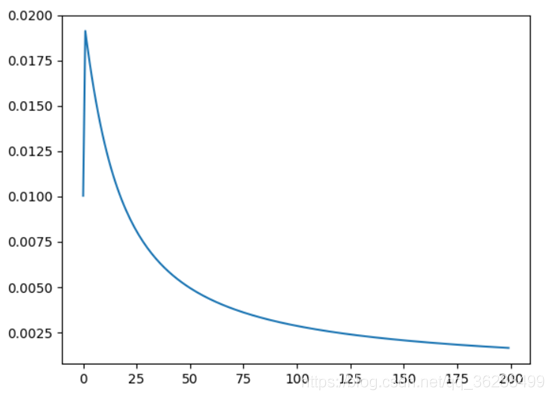
结果展示:
loss:
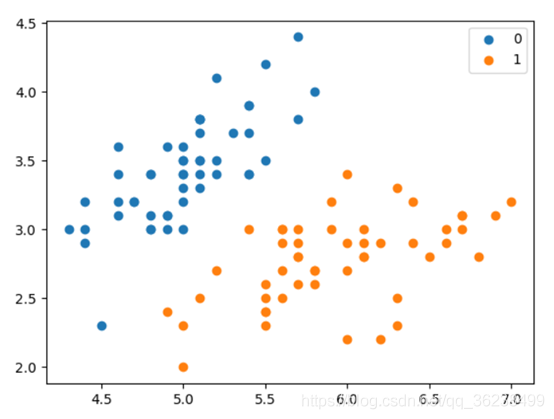
分类结果:
Original: https://blog.csdn.net/qq_36238499/article/details/119596766
Author: 北向晴
Title: 逻辑斯蒂(logistic)回归学习+手撕代码
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/635528/
转载文章受原作者版权保护。转载请注明原作者出处!