

目录
刘杏瑞,女,西安工程大学电子信息学院,2021级研究生
研究方向:图形处理
电子邮件:1148155982@qq.com
吴燕子,女,西安工程大学电子信息学院,2021级研究生,张宏伟人工智能课题组
研究方向:模式识别与人工智能
电子邮件:1219428323@qq.com
- 内核岭回归介绍
2.1 岭回归介绍
岭回归的出现是为了解决线性回归出现的过拟合以及在通过正规方程方法求解θ的过程中出现的x转置乘以x不可逆这两类问题的,通过在损失函数中引入正则化项来达到目的。
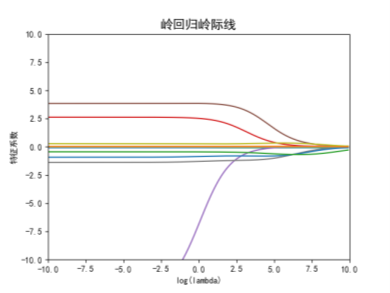
随着模型复杂度的提升,在训练集上的效果就越好,即模型的偏差就越小;但是同时模型的方差就越大。对于岭回归的λ而言,随着λ的增大,|XTX+λI|就越大,(XTX+λI)-1就越小,模型的方差就越小;而λ越大使得β的估计值更加偏离真实值,模型的偏差就越大。所以岭回归的关键是找到一个合理的λ值来平衡模型的方差和偏差。
2.2 核函数介绍
核函数首先定义一个非线性映射函数,通过非线性映射函数将低维空间数据映射到高维空间中,然后在高维空间中再使用线性的回归方法,可以很好地解决非线性回归问题。核方法将数据映射到更高维的空间,希望在这个更高维的空间中,数据可以变得更容易分离或更好的结构化。
- 实验过程
3.1 数据集介绍
数据集来源与介绍:该数据集是一个回归问题。每个类的观察值数量是均等的,共有506个观察,13个输入变量和1个输出变量。每条数据包含房屋以及房屋周围的详细信息。其中包含城镇犯罪率,一氧化氮浓度,住宅平均房间数,到中心区域的加权距离以及自住房平均房价等等。

CRIM 城镇人口犯罪率
ZN 超过25000平方英尺的住宅用地所占比例
INDUS 城镇非零售业务地区的比例
CHAS 查尔斯河虚拟变量(如果土地在河边=1;否则是0)
NOX 一氧化氮浓度(每1000万份)
RM 平均每居民房数
AGE 在1940年之前建成的所有者占用单位的比例
DIS 与五个波士顿就业中心的加权距离
RAD 辐射状公路的可达性指数
TAX 每10,000美元的全额物业税率
RTRATIO 城镇师生比例
B 1000(Bk-0.63)^2其中Bk是城镇黑人的比例
LSTAT 人口中地位较低人群的百分数
MEDV (目标变量/类别属性)以1000美元计算的自有住房的中位数
; 3.2 实验代码
1.使用岭回归找λ
train_X = x
x_train, x_test, y_train, y_test = train_test_split(train_X, y, test_size=0.3, random_state=100, shuffle=True)
def ridges(x_train, y_train): # 目的是为了选λ
alphas = np.arange(-10, 10, 0.1)
coefs = []
for alpha in alphas:
# 获取模型 设置参数
alpha = math.exp(alpha)
# print(alpha)
rr = Ridge(alpha=alpha)
rr.fit(x_train, y_train)
coefs.append(rr.coef_)
fig, ax = plt.subplots()
ax.plot(alphas, coefs)
ax.set_ylabel('特征系数', fontsize=10) # 纵坐标轴标题
ax.set_xlabel('log(lambda)', fontsize=10)
ax.set_title('岭回归岭际线', fontsize=15) # 图形标题
ax.set_xlim([-10, 10])
ax.set_ylim([-10, 10])
plt.savefig('岭回归.jpg', dpi=500, bbox_inches="tight")
plt.show()
2.使用线性核函数与多项式核函数进行拟合和对比
def LKridge(x_train, x_test, y_train, y_test):
# #for alpha in alphas:
alpha = math.exp(5)
rr = KernelRidge(alpha=alpha, kernel="linear")
rr.fit(x_train, y_train)
train_pred = rr.predict(x_train)
test_pred = rr.predict(x_test)
train_RMSE, train_mae = error(y_train, train_pred)
test_RMSE, test_mae = error(y_test, test_pred)
prob = '训练集:RMSE{:.4f} MAE{:.4f}\t测试集:RMSE{:.4f} MAE{:.4f}'.format(train_RMSE,train_mae,test_RMSE,test_mae)
fig, ax = plt.subplots()
ax.plot(range(y_test.shape[0]), y_test, 'b', label='训练集:{:.4f} MAE{:.4f}'.format(train_RMSE,train_mae), linewidth=1)
ax.plot(range(y_test.shape[0]), test_pred, 'cyan', label='测试集:{:.4f} MAE{:.4f}'.format(test_RMSE,test_mae), linewidth=1)
ax.legend(loc="lower right", fontsize=10)
ax.tick_params(axis='both', which='major', size=5, top=False, bottom=True, labelbottom=True, direction='out')
plt.savefig('线性核函.jpg', dpi=500, bbox_inches="tight")
plt.show()
print(prob)
3.选取gamma和degree,使用R2作为模型的评价指标,使用根均方误差(RMSE)和平方绝对误差(MAE)作为模型训练的评价指标。
def Optimizing(x_train, y_train):
param_test1 = {'gamma':[1, 2, 3, 4, 5], 'degree': [1, 2]}
alpha = math.exp(5)
gsearch1 = GridSearchCV(estimator=KernelRidge(alpha=alpha, kernel="poly"),
param_grid=param_test1,
scoring='r2',
cv=5)
gsearch1.fit(x_train, y_train)
print('最好的参数', gsearch1.best_params_, gsearch1.best_score_)
print('最优的R2分数', gsearch1.best_score_)
def error(y_true,y_pred):
Rmse = np.sqrt(mean_squared_error(y_true, y_pred))# 根均方误差(RMSE)
mse = mean_absolute_error(y_true, y_pred) # 平均绝对误差(MAE)
return Rmse, mse
4.结果可视化
def comparison(y_true,y_pred):# 绘制对比折线图
fig, ax = plt.subplots()
ax.plot(y_true.shape[0], y_true, 'b', label='原始值', linewidth=2, linestyle='-')
ax.plot(y_true.shape[0], y_pred, 'b', label='预测值', linewidth=2, linestyle='-.')
# ax.set_ylabel('特征系数', fontsize=10) # 纵坐标轴标题
# ax.set_xlabel('log(lambda)', fontsize=10)
ax.set_title('原始值与预测值比较图', fontsize=15) # 图形标题
#ax.set_xlim([0, 60])
ax.set_ylim([0, 60])
5.最后结果图需要将以下代码注释重新运行
if __name__ == '__main__':
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False # 这两行代码解决 plt 中文显示的问题
images_shows(boston)
ridges(x_train, y_train)
LKridge(x_train, x_test, y_train, y_test)
PKridge(x_train, x_test, y_train, y_test)
Optimizing(x_train, y_train)
finish(x_train, x_test, y_train, y_test)
6.完整代码
from sklearn.kernel_ridge import KernelRidge
from plotly import offline
from tables import Description
from sklearn.datasets import load_boston, load_digits
from sklearn.linear_model import Ridge
from sklearn.model_selection import train_test_split, cross_val_score, GridSearchCV
import numpy as np
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from sklearn.preprocessing import StandardScaler
import math
import matplotlib.pyplot as plt
from matplotlib.pyplot import MultipleLocator
np.random.seed(42)
boston = load_boston()
digits = load_boston()
x = digits.data
y = digits.target
def images_shows(xinxi):
# plt.style.use('seaborn')
x = xinxi['data']
y = xinxi['target']
fig, ax = plt.subplots(ncols=4, nrows=4)
ax = ax.flatten()
plt.ylim(0, 51)
name = xinxi['feature_names']
for i in range(13):
ax[i].scatter(x[:, i], y, s=0.5, c='#006400') # 横纵坐标和点的大小
ax[i].set_title(str(name[i]), fontsize=8)
ax[i].set_xlabel(name[i], fontsize=6)
ax[i].set_ylabel('price', fontsize=6)
ax[i].set_xticks([])
ax[i].set_yticks([])
for i in range(len(y)):
ax[13].scatter(i, y[i], s=0.5, c='red')
ax[13].set_xticks([])
ax[13].set_yticks([])
ax[14].set_xticks([])
ax[14].set_yticks([])
ax[15].set_xticks([])
ax[15].set_yticks([])
plt.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()
plt.savefig('data.png', dpi=100, bbox_inches='tight')
train_X = x
x_train, x_test, y_train, y_test = train_test_split(train_X, y, test_size=0.3, random_state=100, shuffle=True)
def ridges(x_train, y_train): # 目的是为了选λ
alphas = np.arange(-10, 10, 0.1)
coefs = []
for alpha in alphas:
# 获取模型 设置参数
alpha = math.exp(alpha)
# print(alpha)
rr = Ridge(alpha=alpha)
rr.fit(x_train, y_train)
coefs.append(rr.coef_)
fig, ax = plt.subplots()
ax.plot(alphas, coefs)
ax.set_ylabel('特征系数', fontsize=10) # 纵坐标轴标题
ax.set_xlabel('log(lambda)', fontsize=10)
ax.set_title('岭回归岭际线', fontsize=15) # 图形标题
ax.set_xlim([-10, 10])
ax.set_ylim([-10, 10])
plt.savefig('岭回归.jpg', dpi=500, bbox_inches="tight")
plt.show()
def LKridge(x_train, x_test, y_train, y_test):
# #for alpha in alphas:
alpha = math.exp(5)
rr = KernelRidge(alpha=alpha, kernel="linear")
rr.fit(x_train, y_train)
train_pred = rr.predict(x_train)
test_pred = rr.predict(x_test)
train_RMSE, train_mae = error(y_train, train_pred)
test_RMSE, test_mae = error(y_test, test_pred)
prob = '训练集:RMSE{:.4f} MAE{:.4f}\t测试集:RMSE{:.4f} MAE{:.4f}'.format(train_RMSE,train_mae,test_RMSE,test_mae)
fig, ax = plt.subplots()
ax.plot(range(y_test.shape[0]), y_test, 'b', label='训练集:{:.4f} MAE{:.4f}'.format(train_RMSE,train_mae), linewidth=1)
ax.plot(range(y_test.shape[0]), test_pred, 'cyan', label='测试集:{:.4f} MAE{:.4f}'.format(test_RMSE,test_mae), linewidth=1)
ax.legend(loc="lower right", fontsize=10)
ax.tick_params(axis='both', which='major', size=5, top=False, bottom=True, labelbottom=True, direction='out')
plt.savefig('线性核函.jpg', dpi=500, bbox_inches="tight")
plt.show()
print(prob)
def PKridge(x_train, x_test, y_train, y_test):
# #for alpha in alphas:
alpha = math.exp(5)
rr = KernelRidge(alpha=alpha, kernel="poly") # 多项式核函数
rr.fit(x_train, y_train)
train_pred = rr.predict(x_train)
test_pred = rr.predict(x_test)
train_RMSE, train_mae = error(y_train, train_pred)
test_RMSE, test_mae = error(y_test, test_pred)
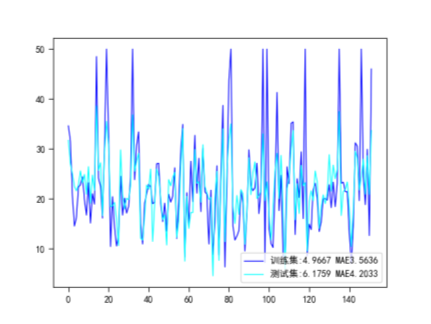
prob = '训练集:RMSE{:.4f} MAE{:.4f}\t测试集:RMSE{:.4f} MAE{:.4f}'.format(train_RMSE,train_mae,test_RMSE,test_mae)
fig, ax = plt.subplots()
ax.plot(range(y_test.shape[0]), y_test, 'b', label='训练集:{:.4f} MAE{:.4f}'.format(train_RMSE,train_mae), linewidth=1)
ax.plot(range(y_test.shape[0]), test_pred, 'cyan', label='测试集:{:.4f} MAE{:.4f}'.format(test_RMSE,test_mae), linewidth=1)
ax.legend(loc="lower right", fontsize=10)
ax.tick_params(axis='both', which='major', size=5, top=False, bottom=True, labelbottom=True, direction='out')
plt.savefig('多项式核函数.jpg', dpi=500, bbox_inches="tight")
plt.show()
print(prob)
def Optimizing(x_train, y_train):
param_test1 = {'gamma':[1, 2, 3, 4, 5], 'degree': [1, 2]}
alpha = math.exp(5)
gsearch1 = GridSearchCV(estimator=KernelRidge(alpha=alpha, kernel="poly"),
param_grid=param_test1,
scoring='r2',
cv=5)
gsearch1.fit(x_train, y_train)
print('最好的参数', gsearch1.best_params_, gsearch1.best_score_)
print('最优的R2分数', gsearch1.best_score_)
def error(y_true,y_pred):
Rmse = np.sqrt(mean_squared_error(y_true, y_pred))# 根均方误差(RMSE)
mse = mean_absolute_error(y_true, y_pred) # 平均绝对误差(MAE)
return Rmse, mse
def comparison(y_true,y_pred):# 绘制对比折线图
fig, ax = plt.subplots()
ax.plot(y_true.shape[0], y_true, 'b', label='原始值', linewidth=2, linestyle='-')
ax.plot(y_true.shape[0], y_pred, 'b', label='预测值', linewidth=2, linestyle='-.')
# ax.set_ylabel('特征系数', fontsize=10) # 纵坐标轴标题
# ax.set_xlabel('log(lambda)', fontsize=10)
ax.set_title('原始值与预测值比较图', fontsize=15) # 图形标题
#ax.set_xlim([0, 60])
ax.set_ylim([0, 60])
def finish(x_train, x_test, y_train, y_test):
alpha = math.exp(5)
rr = KernelRidge(alpha=alpha, kernel="poly", gamma=1, degree=2) # 多项式核函数
rr.fit(x_train, y_train)
train_pred = rr.predict(x_train)
test_pred = rr.predict(x_test)
train_RMSE, train_mae = error(y_train, train_pred)
test_RMSE, test_mae = error(y_test, test_pred)
prob = '训练集:RMSE{:.4f} MAE{:.4f}\t测试集:RMSE{:.4f} MAE{:.4f}'.format(train_RMSE,train_mae,test_RMSE,test_mae)
fig, ax = plt.subplots()
ax.plot(range(y_test.shape[0]), y_test, 'b', label='训练集:{:.4f} MAE{:.4f}'.format(train_RMSE,train_mae), linewidth=1)
ax.plot(range(y_test.shape[0]), test_pred, 'cyan', label='测试集:{:.4f} MAE{:.4f}'.format(test_RMSE,test_mae), linewidth=1)
ax.legend(loc="lower right", fontsize=10)
ax.tick_params(axis='both', which='major', size=5, top=False, bottom=True, labelbottom=True, direction='out')
plt.savefig('最终的图.jpg', dpi=500, bbox_inches="tight")
plt.show()
print(prob)
if __name__ == '__main__':
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False # 这两行代码解决 plt 中文显示的问题
images_shows(boston)
ridges(x_train, y_train)
LKridge(x_train, x_test, y_train, y_test)
PKridge(x_train, x_test, y_train, y_test)
Optimizing(x_train, y_train)
finish(x_train, x_test, y_train, y_test)
3.3 运行结果
1.岭回归岭际线
2.多项式核函数
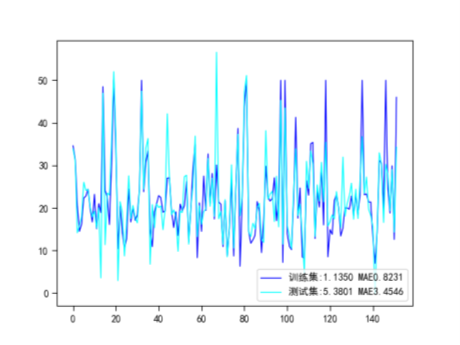
3.线性核函数
4.最终结果图
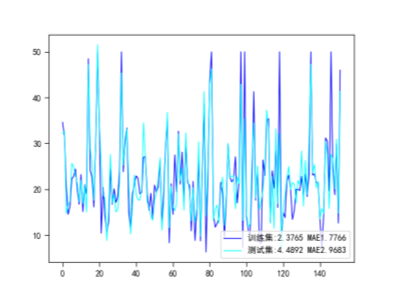
5.模型评价

Original: https://blog.csdn.net/m0_37758063/article/details/123806511
Author: ZHW_AI课题组
Title: 基于内核岭回归的手写数字数据集回归问题
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/635272/
转载文章受原作者版权保护。转载请注明原作者出处!